论文原文为:《Channel polarization: A method for constructing capacity-achieving codes for symmetric binary-input memoryless channels》本文为其翻译。
作者为:Erdal Arıkan
本文参考了些此网站上的翻译:https://marshallcomm.cn/2017/03/04/polar-code-2-encoding-principle/
摘要
提出了一种称为信道极化的方法来构造达到任意给定二进制输入离散无记忆信道(B-DMC) W W W的对称容量 I ( W ) I(W) I(W)的码序列。对称容量是使用具有相等概率的信道的输入字符可以达到的最高速率。信道极化是指可以从给定B-DMC W W W的 N N N个独立副本中合成第二组 N N N个二进制输入信道 { W N ( i ) : 1 ≤ i ≤ N } {W^{(i)}_N:1≤i≤N} {WN(i):1≤i≤N},使得当 N N N变大时, W N ( i ) W^{(i)}_N WN(i)接近1的索引 i i i的分数接近 I ( W ) I(W) I(W), W N ( i ) W^{(i)}_N WN(i)接近0的索引 i i i的分数接近 1 − I ( W ) 1-I(W) 1−I(W)。极化信道 { W N ( i ) } {W^{(i)}_N} {WN(i)}对于信道编码是条件良好的:只需要通过容量接近1的通道以速率1发送数据,其余通道以速率0发送数据。基于此思想构造的代码称为极性代码。本文证明了,给定任意 I ( W ) > 0 I(W)>0 I(W)>0的B-DMCW和任意目标码率 R < I ( W ) R<I(W) R<I(W),存在一个极化码序列{CN;n≥1},使得Cn的块长 N = 2 n N=2^n N=2n,码率 ≥ R ≥R ≥R,在与码速率无关的情况下,逐次抵消译码下块差错概率有界为 P e ( N , R ) ≤ O ( N − 14 ) Pe(N,R)≤O(N−14) Pe(N,R)≤O(N−14)。这种性能可以通过编码器和解码器来实现,每个编码器和解码器的复杂度分别为 O ( N l o g N ) O(NlogN) O(NlogN)。
I.引言与概述
香农关于有噪的信道编码定理的一个令人着迷的证明是,他使用随机编码方法来显示容量实现代码序列的存在,而不给出任何特定的这种序列[1]。从那时起,构造具有低编码和解码复杂度的可证明容量的代码序列成为了一个遥不可及的目标。 本文是针对B-DMC类的这一目标的尝试。
在这一部分中,我们将对本文的主要观点和结果进行说明。 首先,我们给出了一些定义,并陈述了通篇使用的一些基本事实。
A.前期工作
一个二进制输入离散无记忆信道(B-DMC)可表示为
W
:
X
→
Y
W:X→Y
W:X→Y表示为具有输入字母X,输出字母Y和转移概率W(y | x),x∈X,y∈Y。由于信道是二进制输入,集合
X
=
0
,
1
X={0,1}
X=0,1;
Y
Y
Y和
W
(
y
∣
x
)
W(y|x)
W(y∣x)是任意值。我们用
W
N
W^N
WN表示
N
N
N次使用
W
W
W时对应的信道。因此,
W
N
:
X
N
→
Y
N
W^N:X^N → Y^N
WN:XN→YN的转移概率为
W
N
(
y
1
N
∣
x
1
N
)
=
∏
i
=
1
N
W
(
y
i
∣
x
i
)
W^N (y^N_1 | x^N_1) = prod^N_{i = 1}W (y_i | x_i)
WN(y1N∣x1N)=∏i=1NW(yi∣xi)。
在给定B-DMCW的情况下,本文主要关注两个信道参数:对称容量
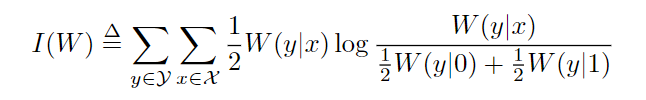
和巴氏指标参数
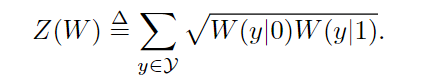
这些参数分别被用作速率和可靠性的度量。
I
(
W
)
I(W)
I(W)是信道
W
W
W在等概率输入下的进行可靠传输的最高速率,
Z
(
W
)
Z(W)
Z(W)是当W仅使用一次发送0或1时最大似然(ML)判决错误概率的上界。
很容易看到
Z
(
W
)
Z(W)
Z(W)取值于
[
0
,
1
]
[0,1]
[0,1]。 自始至终,我们将使用以2为底的对数;因此,
I
(
W
)
I(W)
I(W)也将取值于
[
0
,
1
]
[0,1]
[0,1]。 码率和信道容量的单位将是比特。
且仅当
Z
(
W
)
≈
0
Z(W)≈0
Z(W)≈0时,
I
(
W
)
≈
1
I(W)≈1
I(W)≈1;当且仅当
Z
(
W
)
≈
1
Z(W)≈1
Z(W)≈1时,
I
(
W
)
≈
0
I(W)≈0
I(W)≈0。附录中证明的以下界限可以使这一点更加精确。
命题1:对于任何B-DMCW,我们都有
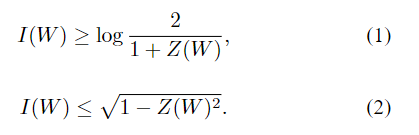
当W是对称信道时,对称容量I(W)等于香农容量,即存在输出字母
Y
Y
Y的置换
π
π
π的信道,使得(I)
π
−
1
=
π
π^{−1}=π
π−1=π和(ii)
W
(
y
∣
1
)
=
W
(
π
(
y
)
∣
0
)
W(y|1)=W(π(y)|0)
W(y∣1)=W(π(y)∣0)对于所有y∈Y。二进制对称信道(Binary Symmetric Channel,BSC)和二进制删除信道(Binary Erasure Channel,BEC)都是满足对称性的B-DMC。具体地说,对于
Y
=
{
0
,
1
}
Y={0,1}
Y={0,1},满足
W
(
0
∣
0
)
=
W
(
1
∣
1
)
W(0|0)=W(1|1)
W(0∣0)=W(1∣1)且
W
(
1
∣
0
)
=
W
(
0
∣
1
)
W(1|0)=W(0|1)
W(1∣0)=W(0∣1)的B-DMC是为BSC。对于
y
∈
Y
y∈Y
y∈Y,满足
W
(
y
∣
0
)
W
(
y
∣
1
)
=
0
W(y|0)W(y|1)=0
W(y∣0)W(y∣1)=0或
W
(
y
∣
0
)
=
W
(
y
∣
1
)
W(y|0)=W(y|1)
W(y∣0)=W(y∣1)的B-DMC是为BEC。对于BEC,符号
y
y
y称为删除符号(Erasure Symbol)所有删除符号上的总和
W
(
y
∣
0
)
W(y|0)
W(y∣0)称为BEC的删除概率。
我们用大写字母(如
X
,
Y
X,Y
X,Y)表示随机变量(RVs),用相应的小写字母(如
x
,
y
x,y
x,y)表示它们的实现(样本值)。对于
X
X
X 是RV,
P
X
P_X
PX表示X上的概率分配,对于
R
V
(
X
,
Y
)
RV(X,Y)
RV(X,Y)的联合集合,
P
X
,
Y
P_{X,Y}
PX,Y表示联合概率分配,我们用标准记号
I
(
X
;
Y
)
I(X;Y)
I(X;Y),
I
(
X
;
Y
∣
Z
)
I(X;Y|Z)
I(X;Y∣Z)分别表示互信息及其条件形式。
行向量
(
a
1
,
…
,
a
N
)
(a1,…,aN)
(a1,…,aN)在这里简写为
a
1
N
a^N_1
a1N。对于给定的行向量
a
1
N
a^N_1
a1N,其子向量表示为
a
i
j
a^j_i
aij,
1
≤
i
,
j
≤
N
1≤i,j≤N
1≤i,j≤N,且
i
≤
j
i≤j
i≤j。如果
j
<
i
j <i
j<i,
a
i
j
a^j_i
aij被视为无效。对于给定的
a
1
N
a^N_1
a1N和
A
⊂
{
1
,
…
,
N
}
A⊂{1,…,N}
A⊂{1,…,N},记
a
A
a_A
aA表示子向量
(
a
i
:
i
∈
A
)
(a_i:i∈A)
(ai:i∈A)。记
a
1
,
o
j
a^j_{1,o}
a1,oj表示奇数索引的子向量
(
a
k
:
1
≤
k
≤
j
;
k
o
d
d
)
(a_k:1≤k≤j;k odd)
(ak:1≤k≤j;k odd),记
a
1
,
e
j
a^j_{1,e}
a1,ej表示偶数索引的子向量
(
a
k
:
1
≤
k
≤
j
;
k
e
v
e
n
)
(a_k:1≤k≤j;k even)
(ak:1≤k≤j;k even)。例如,对于向量
a
1
5
=
(
5
,
4
,
6
,
2
,
1
)
a^5_1=(5,4,6,2,1)
a15=(5,4,6,2,1),有
a
2
4
=
(
4
,
6
,
2
)
a^4_2=(4,6,2)
a24=(4,6,2),
a
1
,
e
5
=
(
4
,
2
)
,
a
1
,
o
4
(
5
,
6
)
a^5_{1,e}=(4,2),a^4_{1,o}(5,6)
a1,e5=(4,2),a1,o4(5,6)。全零向量则记为
0
1
N
0^N_1
01N。
本文中的码构造将在二进制域GF(2)上的向量空间中进行。 除非另有说明,否则所有的向量、矩阵和对它们的运算都将是GF(2)上的。
特别地,对于GF(2)上的
a
1
N
a^N_1
a1N,
b
1
N
b^N_1
b1N向量,我们写
a
1
N
⊕
b
1
N
a^N_1⊕b^N_1
a1N⊕b1N表示它们的分量mod-2和。
m
×
n
m×n
m×n矩阵
A
=
[
A
i
j
]
A = [A_{ij}]
A=[Aij]和
r
×
s
r×s
r×s矩阵
B
=
[
B
i
j
]
B = [B_{ij}]
B=[Bij]的Kronecker乘积定义为
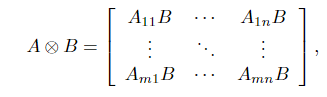
这是一个mr-by-ns矩阵。 对于所有n≥1,克罗内克积
A
⊗
n
A^{⊗n}
A⊗n被定义为
A
⊗
A
⊗
(
n
−
1
)
A⊗A^{⊗(n-1)}
A⊗A⊗(n−1)。 并定义
A
⊗
0
≜
[
1
]
A^{⊗0} triangleq [1]
A⊗0≜[1]的约定。
我们用
∣
A
∣
| A |
∣A∣来表示集合
A
A
A中元素的数目,我们用
1
A
1_A
1A来表示集合的指示函数;因此,如果
x
∈
A
x∈A
x∈A,则
1
A
(
x
)
1_{A(x)}
1A(x)等于1,否则为0。
B.信道极化
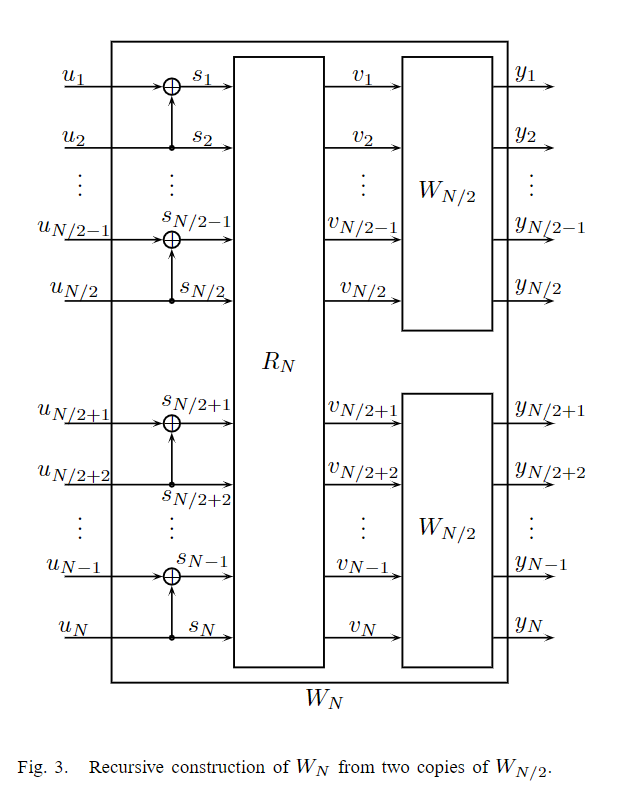
通道极化是一种操作,通过该操作,从给定B-DMC W W W的 N N N个独立副本中制造第二组N个信道 { W N ( i ) : 1 ≤ i ≤ N } {W^{(i)}_N:1≤i≤N} {WN(i):1≤i≤N},其显示极化效应的意义是,对称容量项 { W N ( i ) } {W^{(i)}_N} {WN(i)}对于除索引 i i i的消失部分之外的所有项都趋向于0或1。 该操作由信道合并阶段和信道分裂阶段组成。
1)信道合并:
此阶段以递归方式合并给定B-DMC W的副本,以产生向量通道
W
N
:
X
N
→
Y
N
W_N:X_N→Y_N
WN:XN→YN,其中
N
N
N可以是2的任意幂,
N
=
2
n
,
n
≥
0
N = 2^n,n≥0
N=2n,n≥0。 递归从第0级(
n
=
0
n = 0
n=0)开始,只有一个W副本,并且我们设置
W
1
≜
W
W_1triangleq W
W1≜W。 递归的第一级(
n
=
1
n = 1
n=1)组合了
W
1
W_1
W1的两个独立副本,如图1所示,并获得了具有转移概率的通道
W
2
:
X
2
→
Y
2
W_2:X^2→Y^2
W2:X2→Y2
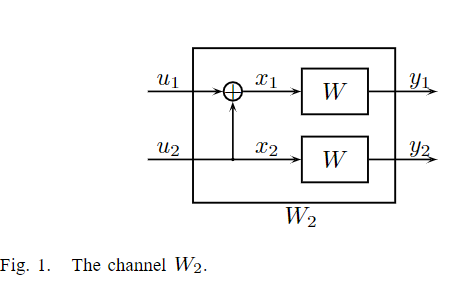
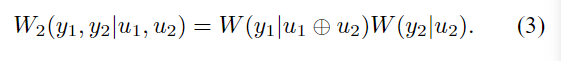
第2级(n=2)递归如图2所示,联合信道
W
2
W_2
W2的2个独立副本得到信道
W
4
:
X
4
→
Y
4
W_4:X^4→Y^4
W4:X4→Y4,其转移概率为
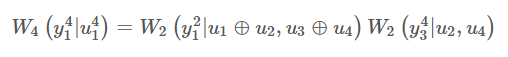
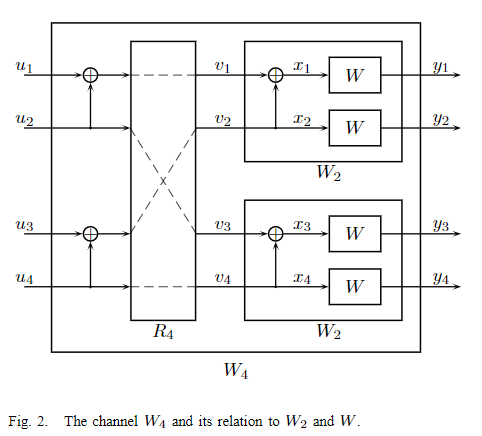
在图2中,
R
4
R_4
R4是完成从
(
s
1
,
s
2
,
s
3
,
s
4
)
(s_1,s_2,s_3,s_4)
(s1,s2,s3,s4)到
v
1
4
=
(
s
1
,
s
3
,
s
2
,
s
4
)
v^4_1=(s_1,s_3,s_2,s_4)
v14=(s1,s3,s2,s4)的置换操作(排序)。从信道
W
4
W_4
W4的输入
W
4
W^4
W4的输入的映射
u
1
4
→
x
1
4
u^4_1→x^4_1
u14→x14可用公式表示为
x
1
4
=
u
1
4
G
4
x^4_1=u^4_1G_4
x14=u14G4.
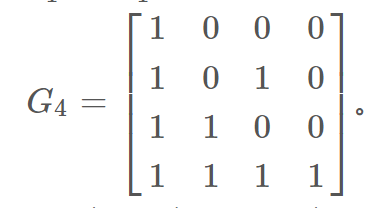
因此
W
4
W_4
W4和
W
4
W^4
W4的转移概率有关系式
W
4
(
y
1
4
∣
u
1
4
)
=
W
4
(
y
1
4
∣
u
1
4
G
4
)
W_4(y^4_1|u^4_1)=W^4(y^4_1|u^4_1G_4)
W4(y14∣u14)=W4(y14∣u14G4)。
图3所示为递归结构的一般形式。
W
N
/
2
W_{N/2}
WN/2的2个独立副本联合产生信道
W
N
W_N
WN。输入向量
u
1
N
u^N_1
u1N进入信道
W
N
W_N
WN,首先被转换为
s
1
N
s^N_1
s1N:
s
2
i
−
1
=
u
2
i
−
1
⊕
u
2
i
,
s
2
i
=
u
2
i
,
1
≤
i
≤
N
/
2
s_{2i−1}=u_{2i−1}⊕u_{2i},s_{2i}=u_{2i},1≤i≤N/2
s2i−1=u2i−1⊕u2i,s2i=u2i,1≤i≤N/2。
R
N
R_N
RN是一个排列,称为反向洗牌运算,输入为
s
1
N
s^N_1
s1N,输出为
v
1
N
=
(
s
1
,
s
3
,
…
,
s
N
−
1
,
s
2
,
s
4
,
…
,
s
N
)
v^N_1=(s_1,s_3,…,s_{N−1},s_2,s_4,…,s_N)
v1N=(s1,s3,…,sN−1,s2,s4,…,sN)。
v
1
N
v^N_1
v1N则成为2个
W
N
/
2
W_{N/2}
WN/2独立副本的输入。
映射
u
1
N
↦
v
1
N
u^N_1mapsto v^N_1
u1N↦v1N是二元域GF(2)上的线性变换。 通过归纳法得出,从合成通道
W
N
W_N
WN的输入到基础原始通道
W
N
W^N
WN的输入的总体映射
u
1
N
↦
x
1
N
u^N_1mapsto x^N_1
u1N↦x1N也是线性的,可以用矩阵
G
N
G_N
GN表示,即
x
1
N
=
u
1
N
G
N
x^N_1 = u^N_1G_N
x1N=u1NGN。
我们称
G
N
G_N
GN大小为
N
N
N的生成器矩阵
两个信道
W
N
W_N
WN和
W
N
W^N
WN的转移概率由下式关联
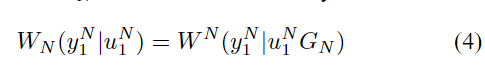
其中
y
1
N
∈
Y
N
,
u
1
N
∈
X
N
y^N_1∈ Y^N,u^N_1∈ X^N
y1N∈YN,u1N∈XN.我们将在第VII节中证明,对于任何
N
=
2
n
N=2^n
N=2n,
n
≥
0
n≥0
n≥0,
G
N
G_N
GN等于
B
N
F
⊗
n
B_NF^{⊗n}
BNF⊗n,其中
B
N
B_N
BN是称为比特反转的置换矩阵,F=
[
1
0
1
1
]
begin{bmatrix} 1 & 0 \ 1 & 1 end{bmatrix}
[1101]。 请注意,信道合并操作由矩阵
F
F
F完全指定。另请注意,
G
N
G_N
GN和
F
⊗
n
F^{⊗n}
F⊗n具有相同的行集,但顺序不同(位反转);我们将在第VII节中更详细地讨论此主题。
2) 信道分裂
从 W N W^N WN合成矢量通道 W N W_N WN之后,信道极化的下一步是将 W N W_N WN拆分为由转移概率定义的一组 N N N个二进制输入坐标信道 W N ( i ) : X → Y N × X i − 1 , 1 ≤ i ≤ N W^{(i)}_N:X→Y^N×X^{i-1},1≤i≤N WN(i):X→YN×Xi−1,1≤i≤N,已定义 由转移概率
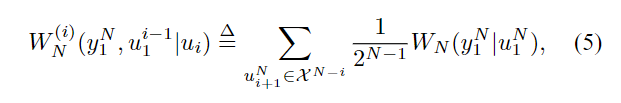
其中
(
y
1
N
,
u
1
i
−
1
)
(y^N_1,u^{i-1}_1)
(y1N,u1i−1)表示
W
N
(
i
)
W^{(i)}_N
WN(i)的输出,
u
i
u_i
ui表示其输入。
为了直观理解信道
{
W
N
(
i
)
}
{W^{(i)}_N}
{WN(i)},考虑一个genie辅助的逐次消除解码器,其中第i个判决单元在观察到
y
1
N
y^N_1
y1N和过去的信道输入
u
1
i
−
1
u^{i−1}_1
u1i−1(由genie正确地提供,而不考虑早期的任何判决错误)之后估计
u
i
u_i
ui。如果
u
1
N
u^N_1
u1N在
X
N
X^N
XN上是先验一致的,则
W
N
(
i
)
W^{(i)}_N
WN(i)是第
i
i
i个判决单元在该场景中看到的有效信道。
3)信道极化
定理1:对于任何B-DMC W信道,信道
{
W
N
(
i
)
}
{W^{(i)}_N}
{WN(i)}在某种意义上是极化的,对于任意的
δ
∈
(
0
,
1
)
δ∈(0,1)
δ∈(0,1),当
N
N
N通过2的幂变为无穷大时,索引
i
∈
{
1
,
.
.
.
,
N
}
i∈{1, ... ,N}
i∈{1,...,N},其中满足
I
(
W
N
(
i
)
)
∈
(
1
−
δ
,
1
]
I(W^{(i)}_N)∈(1-δ,1]
I(WN(i))∈(1−δ,1]的信道数占总信道数N的比例趋于
I
(
W
)
I(W)
I(W),而满足
I
(
W
N
(
i
)
)
∈
[
0
,
δ
)
I(W^{(i)}_N)∈[0,δ)
I(WN(i))∈[0,δ)的信道所占的比例趋于
1
−
I
(
W
)
1- I(W)
1−I(W)。
该定理在第IV节中得到了证明。
对于具有擦除概率
ϵ
=
0.5
epsilon= 0.5
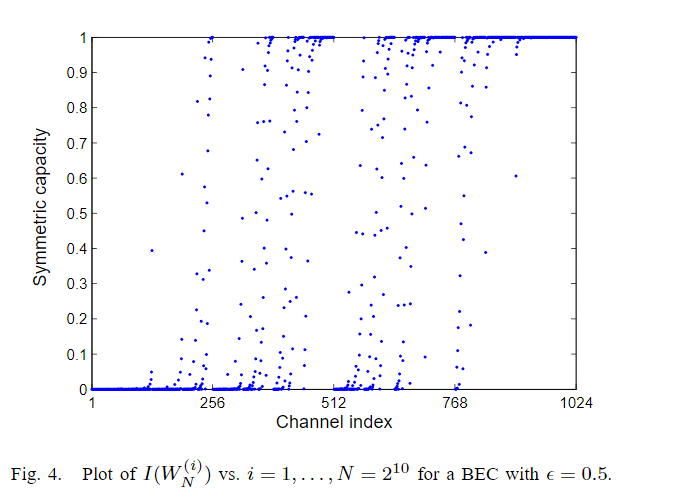
ϵ=0.5的BEC的情况,极化效应在图4中示出。 已经使用递归关系计算了数字
{
W
N
(
i
)
}
{W^{(i)}_N}
{WN(i)}
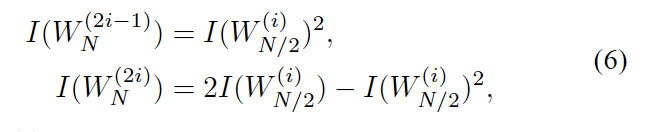
其中
i
(
W
1
(
1
)
)
=
1
−
ϵ
i(W^{(1)}_1)=1−epsilon
i(W1(1))=1−ϵ。 这种递推只对BEC有效,第III节证明了这一点。对于一般的B-DMC W,目前还没有有效的算法来计算
{
W
N
(
i
)
}
{W^{(i)}_N}
{WN(i)}。
图4显示 I ( W ( i ) ) I(W^{(i)}) I(W(i))对于小的i趋向于接近0,对于大的i趋向于接近1.然而, I ( W N ( i ) ) I(W^{(i)}_N) I(WN(i))在 i i i的中间范围内表现出不稳定的行为.对于一般的B-DMC,确定 I ( W N ( i ) ) I(W^{(i)}_N) I(WN(i))高于给定阈值的索引的子集是一个重要的计算问题,将在第IX节中讨论.
4)极化率
为了证明编码定理,极化效应随N的变化而保持极化速度是很重要的。我们在这方面的主要结果是根据参数给出的
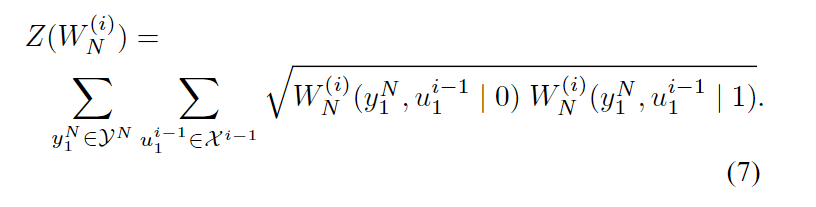
定理2:对于任何
I
(
W
)
>
0
I(W)> 0
I(W)>0且任意
R
<
I
(
W
)
R <I(W)
R<I(W)的B-DMC 信道W,都存在一个序列集
A
N
⊂
{
1
,
.
.
.
,
N
}
,
N
∈
{
1
,
2
,
.
.
.
,
2
n
,
.
.
.
}
A_N⊂{1,... ,N},N∈{1,2,... ,2^n,...}
AN⊂{1,...,N},N∈{1,2,...,2n,...},例如对于所有
i
∈
A
N
,
∣
A
N
∣
≥
N
R
i∈AN,| A_N |≥NR
i∈AN,∣AN∣≥NR并且
Z
(
W
N
(
i
)
)
≤
O
(
N
−
5
/
4
)
Z(W^{(i)}_N)≤O(N^{−5 / 4})
Z(WN(i))≤O(N−5/4)
该定理在IV-B节中得到了证明。
我们用
{
Z
(
W
N
(
i
)
)
}
{Z(W^{(i)}_N)}
{Z(WN(i))}而不是
{
I
(
W
N
(
i
)
)
}
{I(W^{(i)}_N)}
{I(WN(i))}来表示定理2中的极化结果,因为这种形式更适合我们将要开发的编码结果。 在定理1的帮助下,从定理2可以得到以
{
I
(
W
N
(
i
)
)
}
{I(W^{(i)}_N)}
{I(WN(i))}表示的偏振率结果。
C. Polar coding
我们利用极化效应来构造实现对称信道容量 I ( W ) I(W) I(W)的码,我们称之为极性编码。
极化编码的基本思想是建立一种编码系统,在该编码系统中,人们可以单独访问每个坐标信道 W N ( i ) W^{(i)}_N WN(i),并且只通过 Z ( W N ( i ) ) Z(W^{(i)}_N) Z(WN(i))接近0的那些信道发送数据。
1) G N G_N GN-coset codes 陪集编码
首先,作为特殊情况,我们描述一类包含极性代码(主要关注的代码)的分组代码。 此类的块长度N被限制为2的幂,对于
n
≥
0
,
N
=
2
n
n≥0,N = 2^n
n≥0,N=2n。 对于给定的N,该类中的每个代码都以相同的方式编码,即

其中
G
N
G_N
GN是上面定义的N阶生成矩阵。
对于{1,…,N}的任意子集A,我们可以将(8)写为
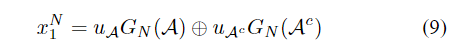
其中
G
N
(
A
)
G_N(A)
GN(A)表示由
A
A
A中具有索引的行组成的
G
N
G_N
GN的子矩阵。
如果现在固定
A
A
A和
u
A
c
u_{A^c}
uAc,并且将
u
A
u_A
uA保留为自由变量,则将获得从源块
u
A
u_A
uA到代码字块
x
1
N
x^N_1
x1N的映射。该映射是陪集编码:它是线性块码与生成器矩阵
G
N
(
A
)
G_N(A)
GN(A)的陪集,该陪集由固定向量
u
A
c
G
N
(
A
c
)
u_{Ac}G_N(A^c)
uAcGN(Ac)确定。 我们将此类代码统称为
G
N
G_N
GN-coset代码。(陪集代码)
我们将这类码统称为
G
N
G_N
GN-陪集码,单个
G
N
G_N
GN-陪集码将由一个参数向量
(
N
,
K
,
A
,
u
A
c
)
(N,K,A,u_{A^c})
(N,K,A,uAc)来标识,其中K是码的维数,指定A的大小。 比率
K
/
N
K / N
K/N称为编码率。我们将
A
A
A(我们将冗余参数K包括在参数集中,因为我们通常考虑K固定而A自由的码集。)设为信息集,将
u
A
c
∈
X
N
−
K
u_{Ac}∈X^{N−K}
uAc∈XN−K称为冻结位或向量。
例如,(4,2,{2,4},(1,0))代码具有编码映射
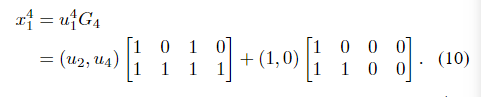
对于源块
(
u
2
,
u
4
)
=
(
1
,
1
)
(u_2,u_4)=(1,1)
(u2,u4)=(1,1),编码块是
x
1
4
=
(
1
,
1
,
0
,
1
)
x^4_1=(1,1,0,1)
x14=(1,1,0,1)。
不久将通过给出选择信息集合
A
A
A的特定规则来指定极性码。
2)A successive cancellation decoder 连续消除解码器
考虑带有参数
(
N
,
K
,
A
,
u
A
c
)
(N,K,A,u_{A^c})
(N,K,A,uAc)的
G
N
G_N
GN陪集代码。 令
u
1
N
u^N_1
u1N被编码为码字
x
1
N
x^N_1
x1N,使
x
1
N
x^N_1
x1N通过信道
W
N
W^N
WN被发送,并且使信道输出
y
1
N
y^N_1
y1N被接收。 在已知
A
,
u
A
c
和
y
1
N
A,u_{Ac}和y^N_1
A,uAc和y1N的情况下,解码器的任务是生成
u
1
N
u^N_1
u1N的估计值
u
^
1
N
hat{u}^N_1
u^1N。
由于解码器可以通过设置
u
^
A
c
=
u
A
c
hat{u}_{Ac} = u_{Ac}
u^Ac=uAc来避免冻结部分中的错误,因此真正的解码任务是生成
u
A
u_A
uA的估计
u
^
A
hat{u}_A
u^A。
除非提到其他解码器,否则本文将针对特定的连续消除(SC)解码器给出编码结果。 给定任何
(
N
,
K
,
A
,
u
A
c
)
(N,K,A,u_{{A}^ c})
(N,K,A,uAc)GN陪集码,我们将使用SC解码器,该解码器通过计算生成其决策
u
^
1
N
hat{u}^N_1
u^1N
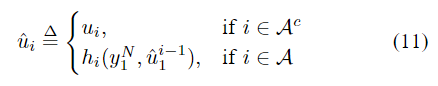
以
i
i
i从
1
到
N
1到N
1到N的顺序,其中
h
i
:
Y
N
×
X
i
−
1
→
X
,
i
∈
A
h_i:Y^N×X^{i-1}→X,i∈A
hi:YN×Xi−1→X,i∈A是定义为
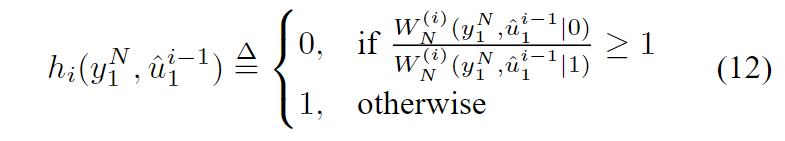
对于所有
y
1
N
∈
Y
N
y^N_1∈Y^N
y1N∈YN,
u
^
1
i
−
1
∈
X
i
−
1
hat{u}^{i-1}_1∈X^{i-1}
u^1i−1∈Xi−1。 我们将说如果
u
^
1
N
≠
u
1
N
hat{u}^N_1 neq u^N_1
u^1N=u1N或等效地如果
u
^
A
≠
u
A
hat{u}^Aneq uA
u^A=uA则发生解码器块错误。
上面定义的决策函数
h
i
{hi}
hi与ML(最大似然)决策函数相似,但并不完全一样,因为它们将冻结的未来比特
(
u
j
:
j
>
i
,
j
∈
A
c
)
(u_j:j> i,j∈A^c)
(uj:j>i,j∈Ac)视为RV(随机向量),而不是已知比特。 作为这种次优的交换,可以使用递归公式有效地计算{hi},如我们在第II节中所示。 除算法效率外,决策函数的递归结构非常重要,因为它会使解码器的性能分析变得易处理。幸运的是,由于不使用真正的ML决策函数而导致的性能损失可忽略不计:
I
(
W
)
I(W)
I(W)仍可实现。
3) Code performance代码性能
符号
P
e
(
N
,
K
,
A
,
u
A
c
)
Pe(N,K,A,u_{{A}^ c})
Pe(N,K,A,uAc)将表示
(
N
,
K
,
A
,
u
A
c
)
(N,K,A,u_{{A}^ c})
(N,K,A,uAc)码的块差错概率,假设每个数据向量
u
A
∈
X
K
u_A∈X^K
uA∈XK以概率
2
−
K
2^{−K}
2−K发送,并且解码由上述SC解码器完成。 更准确地说,
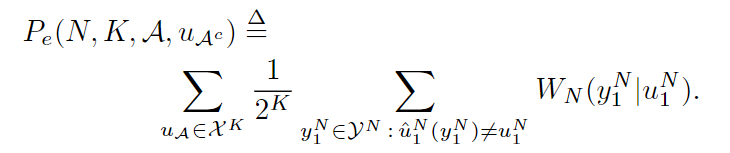
u
A
c
u_{{A}^ c}
uAc的所有选择的
P
e
(
N
,
K
,
A
,
u
A
c
)
Pe(N,K,A,u_{{A}^ c})
Pe(N,K,A,uAc)的平均值将由
P
e
(
N
,
K
,
A
)
Pe(N,K,A)
Pe(N,K,A)表示:
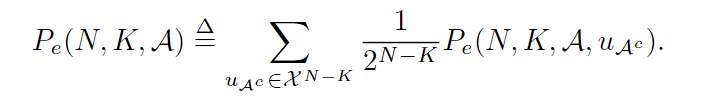
SC解码下的块错误概率的关键范围如下。
命题2:对于任何B-DMC W和参数
(
N
,
K
,
A
)
(N,K,A)
(N,K,A)的任何选择,
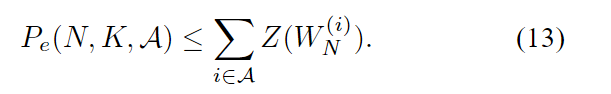
因此,对于每个
(
N
,
K
,
A
)
(N,K,A)
(N,K,A),都有一个冻结的向量
u
A
c
u_{A^c}
uAc
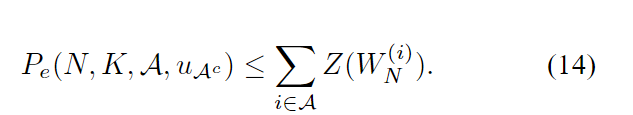
V-B节证明了这一点。 这一结果建议从{1,…,N}的所有K个子集中选择A以便最小化(13)的RHS。这个想法导致了极坐标的定义。
在这里 u A c u_{{A}^ c} uAc直接写为uAc
4) Polar codes
在给定B-DMC W的情况下,如果选择信息集A作为{1,…, N}的K元素子集,则具有参数(N,K,A,uAc)的GN陪集代码将被称为W的极化码。 对于所有
i
∈
A
,
j
∈
A
c
,
Z
(
W
N
(
i
)
)
≤
Z
(
W
N
(
j
)
)
i∈A,j∈Ac,Z(W^{(i)}_N)≤Z(W^{(j)}_N)
i∈A,j∈Ac,Z(WN(i))≤Z(WN(j))
极化码是信道特定的设计:一个信道的极化码可能不是另一个信道的极化码。 本文的主要结果是证明了极性编码可以达到任意给定B-DMCW的对称容量
I
(
W
)
I(W)
I(W)。
极化码定义的另一种规则是将A指定为
{
1
,
.
.
.
,
N
}
{1,...,N}
{1,...,N}的K个元素子集,使得对于所有
i
∈
A
,
j
∈
A
c
i∈A,j∈A^c
i∈A,j∈Ac,
I
(
W
N
(
i
)
)
≥
I
(
W
N
(
j
)
)
I(W^{(i)}_N)≥I(W^{(j)}_N)
I(WN(i))≥I(WN(j)) 。 此替代规则也将达到
I
(
W
)
I(W)
I(W)。 但是,基于Bhattacharyya参数的规则具有与块错误概率的显式界限相联系的优点。
极性代码定义未指定如何选择冻结向量uAc; 可以随意选择。 uAc选择的这种自由度通过允许对总体进行平均,从而简化了极性代码的性能分析。 但是,我们并没有为选择uAc指定精确的规则,不仅仅是为了分析方便,还因为代码性能似乎对该选择相对不敏感。 实际上,我们在VI-B节中证明,对于对称通道,任何选择的foruAcis都与其他方法一样好。
5)编码定理:
对于一个固定的B-DMC W,编号R≥0。 设 P e ( N , R ) Pe(N,R) Pe(N,R)定义为 P e ( N , ⌊ N R ⌋ , A ) Pe(N,⌊NR⌋,A) Pe(N,⌊NR⌋,A),根据W的极性编码规则选择A.因此, P e ( N , R ) Pe(N,R) Pe(N,R)是针对W上具有块长度N和速率R的极性编码的SC解码下的块差错概率,在冻结位uAc的所有选择上取平均值。 本文的主要编码结果如下:
定理3:对于任何给定的B-DMCW和固定的R <I(W),连续消除解码下极性编码的块错误概率都满足
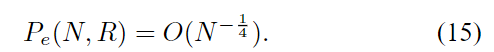
这个定理是定理2和界(13)的一个简单推论,如我们在V-B节中所示。 对于对称通道,我们有以下定理3的增强版本。
定理4:对于任何对称的B-DMC W和任何固定的
R
<
I
(
W
)
R <I(W)
R<I(W),考虑GN陪集码的任何序列
(
N
,
K
,
A
,
u
A
c
)
(N,K,A,uAc)
(N,K,A,uAc),其中N递增到无穷大,
K
=
⌊
N
R
⌋
K =⌊NR⌋
K=⌊NR⌋,
A
A
A根据W的极性编码规则选择,并且uAc取任意值。 连续消除解码后的块错误概率满足
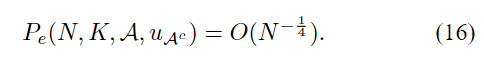
第VI-B节证明了这一点。 注意,对于对称信道,
I
(
W
)
I(W)
I(W)等于W的香农容量
6)复杂度:
极化码的一个重要问题是编码、译码和码构造的复杂性,信道极化构造的递归结构使得GN陪集码,特别是极化码的编译码算法复杂度较低。
定理5:对于GN陪集码的类别,编码的复杂度和连续消除解码的复杂度均为
O
(
N
l
o
g
N
)
O(NlogN)
O(NlogN)作为代码块长度N的函数。
这一定理在第VII节和第VIII节中得到了证明。注意,定理5中的复杂性界限与码率和冻结向量的选择方式无关。 即使在I(W)以上的利率下,这个界限仍然存在,但显然这没有实际意义。
对于码构造,我们没有发现用于构造极性代码的低复杂度算法。 一个例外是BEC,对于该BEC,我们有一个极性代码构造算法,其复杂度为O(N)。 我们将在第九节中进一步讨论代码构造问题,并提出一种用于近似精确极性代码构造的低复杂度统计算法。
D.与以前工作的关系
本文是文献[2]工作的推广,文中用通道合并和分裂的方法证明了某些特定DMC的总截止率可以得到改善。 然而,没有任何递归方法被建议达到这种改进的极限。
随着当前工作的进展,很明显极性编码与Reed-Muller(RM)编码有很多共同之处[3],[4]。 实际上,递归代码构造和SC解码是极性编码的两个基本要素,似乎已经被RM代码引入了编码理论。
根据RM代码的一种构造,对于任何
N
=
2
n
N = 2^n
N=2n,
n
≥
0
n≥0
n≥0和
0
≤
K
≤
N
0≤K≤N
0≤K≤N,将块长度为
N
N
N,尺寸为
K
K
K的RM代码(表示为
R
M
(
N
,
K
)
RM(N,K)
RM(N,K))定义为线性代码,其生成器矩阵
G
R
M
(
N
,
K
)
G_{RM}(N,K)
GRM(N,K)是通过删除
F
⊗
n
F^{⊗n}
F⊗n行的
(
N
−
K
)
(N-K)
(N−K)获得的,因此删除的行中的汉明权重(该行中的1的个数)都不比其余K行中的汉明权重大 。
例如
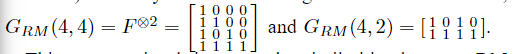
这种构造体现了RM码和极性码之间的相似性。 由于对于任意
N
=
2
n
N=2^n
N=2n,
G
N
G_N
GN和
F
⊗
n
F^{⊗n}
F⊗n具有相同的行集(只是顺序不同),显然RM码属于GN-陪集码的类,例如,
R
M
(
4
,
2
)
RM(4,2)
RM(4,2)是参数为
(
4
,
2
,
2
,
4
,
(
0
,
0
)
)
(4,2,{2,4},(0,0))
(4,2,2,4,(0,0))的G4-陪集码。 因此,RM编码和极化码可以被认为是用于选择给定大小
(
N
,
K
)
(N,K)
(N,K)的GN陪集码的信息集合A的两个可选规则。 与极化编码不同,RM编码以与信道无关的方式选择信息集;它不像极性编码那样对信道极化现象进行微调。 我们将在X节中证明,至少对于这类BEC,信息集选择的RM规则在SC译码下导致渐近不可靠的码。 因此,通过更密切地关注信道极化,极性编码以非平凡的方式超越了RM编码。
通过注意极化码是多级
∣
u
∣
u
+
v
∣
|u|u+v|
∣u∣u+v∣码,它是源于Plotkin码组合方法的一类码[5],可以建立到现有工作的另一种联系。
鉴于RM码也是多级
∣
u
∣
u
+
v
∣
|u|u+v|
∣u∣u+v∣码[6,pp.。 114-125]。
然而,与典型的多级码构造不同的是,在典型的多级码构造中,人们从特定的小码位开始以构建较大的码位,在极性编码中,多级码是通过相对于信道特定的准则清除全阶生成矩阵GN的行来获得的。 GN的特殊结构确保了无论如何删除,结果代码都是多级
∣
u
∣
u
+
v
∣
|u|u+v|
∣u∣u+v∣代码。 本质上,极性编码享有从这种编码的集合中选择多级编码的自由,以便适合手头的信道,而传统的多级编码方法没有这种程度的灵活性。
最后,我们希望提及极化码的“频谱”解释,类似于Blahut对BCH代码的处理[7,Ch。 9]; 这种相似性已经被Forney 证明[8,Ch。 11]与RM代码有关。 从频谱观点来看,编码操作(8)被视为“频率”域信息矢量uN1到“时间”域码字矢量 x 1 N x^N_1 x1N的变换。 变换是可逆的,其中 G N − 1 = G N G^{-1}_N = G_N GN−1=GN。 解码操作被视为一种频谱估计问题,其中给了一个时域观测值 y 1 N y^N_1 y1N,它是 x 1 N x^N_1 x1N的嘈杂版本,并被要求估计 u 1 N u^N_1 u1N。 为了帮助进行估算,允许冻结一定数量的uN1光谱分量。 极性编码的这种频谱解释表明,有可能在统一框架中处理极性代码和BCH代码。 频谱解释也为在极性编码中使用各种信号处理技术打开了大门。 确实,在第七节中,我们在设计极坐标编码器时采用了一些快速的变换技术。
E.论文大纲
论文的其余部分组织如下。 第二节探讨了信道分割的递归性质。 在第三节中,我们重点介绍了I(W)和Z(W)是如何通过信道合并和分离的单一步骤进行变换的。 我们将其推广到第四节的渐近分析,完成了定理1和定理2的证明,从而完成了本文关于信道极化的部分,其余部分主要是关于极性编码的。 第五节给出了SC译码下极化编码误块率的一个上界,并证明了定理3。第六节考虑了对称B-DMCS的极性编码,证明了定理4。第七节分析了编码器映射GN,从而得到了有效的编码器实现。 在第八节中,我们给出了一种复杂度为 O ( N l o g N ) O(NlogN) O(NlogN)的SC译码的实现。 在第九节中,我们讨论了码构造的复杂度,并提出了一种 O ( N l o g N ) O(NlogN) O(NlogN)统计近似码构造算法。 在十节中,我们解释了为什么RM码在SC译码下具有较差的渐近性能。 在第十一节中,我们指出了对目前工作的一些概括,给出了一些补充意见,并说明了一些有待解决的问题。
II.递归通道变换
我们通过(4)和(5)定义了逐块通道合并和拆分操作,该操作将W的N个独立副本转换为 W N ( 1 ) , . . . , W N ( N ) W^{(1)}_N,...,W^{(N)}_N WN(1),...,WN(N)。 本节的目的是表明可以将该块状通道转换递归分解为单步通道转换。
我们说一对二进制输入通道 W ′ : X → Y ~ W':X→tilde{Y} W′:X→Y~和 W ′ ′ : X → Y ~ × X W'':X→tilde{Y}×X W′′:X→Y~×X是通过二进制输入通道 W : X → Y W:X→Y W:X→Y的两个独立副本的单步变换获得的,并且 写
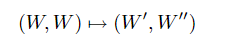
当且仅当存在一对一的映射
f
:
Y
2
→
Y
~
f:Y^2→tilde{Y}
f:Y2→Y~使得
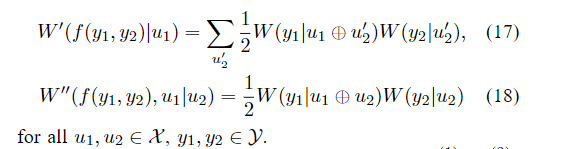
据此,我们可以为任何给定的B-DMCW写
(
W
,
W
)
↦
(
W
2
(
1
)
,
W
2
(
2
)
)
(W,W)mapsto (W^{(1)}_2,W^{(2)}_2)
(W,W)↦(W2(1),W2(2))
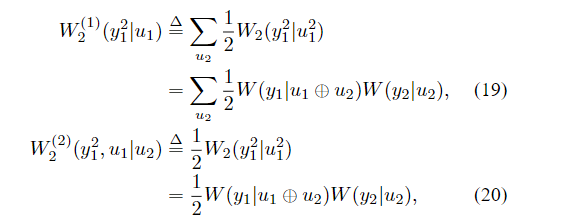
以
f
f
f为单位映射,其形式为(17)和(18)。
事实证明,更广泛地说,我们可以写,
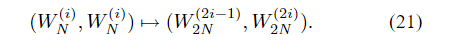
这是对以下内容的推论:
命题3:
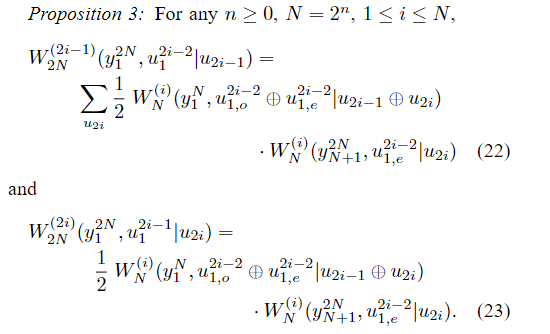
该建议在附录中得到了证明。 现在可以通过以下方式证明(21)和(23)在形式上分别与(17)和(18)相同,从而证明变换关系(21)是合理的:
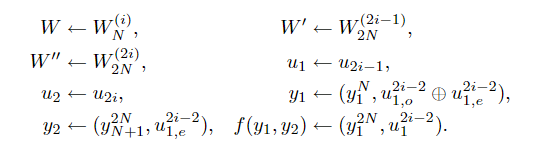
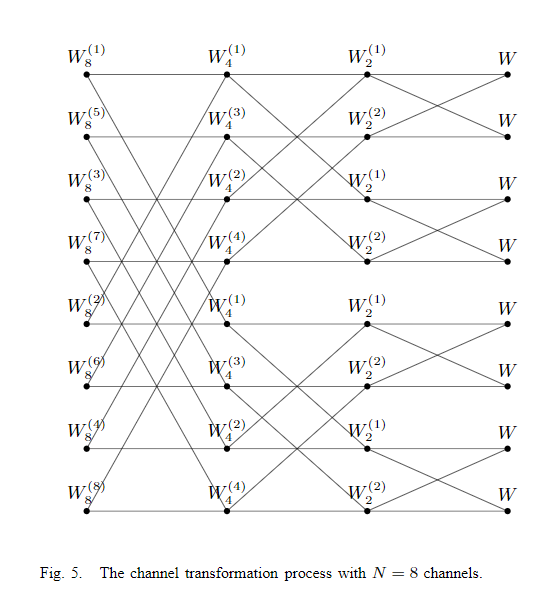
图5.N=8个信道的信道转换过程。
因此,我们已经表明,从 W N W^N WN到 ( W N ( 1 ) , . . . , W N ( N ) ) (W^{(1)}_N,...,W^{(N)}_N) (WN(1),...,WN(N))的块状通道转换在局部级别上分解为形式为(21)的单步通道转换。 对于 N = 8 N = 8 N=8,全套这样的变换形成如图5所示的结构。从右向左读取,该图从变换 ( W , W ) ↦ ( W 2 ( 1 ) , W 2 ( 2 ) ) (W,W)mapsto(W^{(1)}_2,W^{(2)}_2) (W,W)↦(W2(1),W2(2))的四个副本开始并以蝶形模式继续,每个蝶形模式表示形式为 ( W 2 i ( j ) , W 2 i ( j ) ) ↦ ( W 2 i + 1 ( 2 j − 1 ) , W 2 i + 1 ( 2 j ) ) (W^{(j)}_{2^i},W^{(j)}_{2^i})mapsto(W^{(2j−1)}_{2^{i+1}},W^{(2j)}_{2^{i+1}}) (W2i(j),W2i(j))↦(W2i+1(2j−1),W2i+1(2j)) 。 蝶形阀的右端点处的两个通道始终相同且独立。 在最右侧,有W的8个独立副本;在左边的下一个级别有4个独立的 W 2 ( 1 ) W^{(1)}_2 W2(1)和 W 2 ( 2 ) W^{(2)}_2 W2(2)副本;依此类推。 向左的每一步都会使通道类型的数量加倍,但会使独立副本的数量减半。
III. 速率与可靠性转换
现在我们研究速率和可靠性参数 I ( W N ( i ) ) I(W^{(i)}_N) I(WN(i))和 Z ( W N ( i ) ) Z(W^{(i)}_N) Z(WN(i))是如何通过局部(单步)变换(21)改变的。 通过了解局部行为,我们将能够得出从 W N W^N WN到 ( W N ( 1 ) , W N ( N ) ) (W^{(1)}_N,W^{(N)}_N) (WN(1),WN(N))的整体转换的结论。 附录中给出了本节结果的证明。
A.速率和可靠性的局部转换
命题4:假设对于某些二进制输入信道集合,
(
W
,
W
)
↦
(
W
′
,
W
′
′
)
(W,W)mapsto(W',W'')
(W,W)↦(W′,W′′)。 那么,
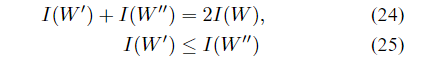
当且仅当
I
(
W
)
I(W)
I(W)等于0或1。
等式(24)表示单步通道变换保持了对称容量。 不等式(25)与(24)表明,在单步变换下,对称容量保持不变,当且仅当
W
W
W是理想信道或完全噪声信道,
I
(
W
′
)
=
I
(
W
′
′
)
=
I
(
W
)
I(W')= I(W'')= I(W)
I(W′)=I(W′′)=I(W)。如果
W
W
W既不是完全噪声也不是完全噪声,则单步变换会在
I
(
W
′
)
<
I
(
W
)
<
I
(
W
′
′
)
I(W')<I(W)<I(W'')
I(W′)<I(W)<I(W′′)的情况上使对称容量偏离中心,从而有助于极化。
命题5:假设对于某些二进制输入信道集合,
(
W
,
W
)
↦
(
W
′
,
W
′
′
)
(W,W)mapsto(W',W'')
(W,W)↦(W′,W′′)。 那么,
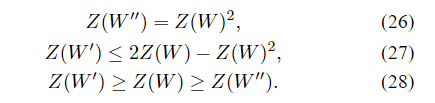
当且仅当W是 BEC,等式成立于(27)。 当且仅当 Z(W)等于0或1,我们有
Z
(
W
′
)
=
Z
(
W
′
)
Z (W ′) =Z(W ′)
Z(W′)=Z(W′),或等效地,当且仅当
I
(
W
)
I(W)
I(W)等于1或0。
这一结果表明,只有在单步信道变换下,可靠性才能在以下意义上提高
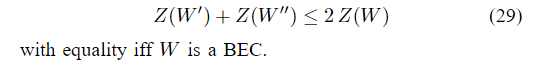
由于BEC在可靠性的w.r.t.极值行为中起着特殊的作用,因此它值得特别关注。
命题6:考虑信道变换 ( W , W ) ↦ ( W ′ , W ′ ′ ) (W,W)mapsto(W',W'') (W,W)↦(W′,W′′)。 如果W是具有一定擦除概率 ϵ epsilon ϵ的BEC,则信道 W ′ W' W′和 W ′ ′ W'' W′′分别是具有擦除概率为 2 ϵ − ϵ 2 和 ϵ 2 2epsilon-epsilon^2和epsilon^2 2ϵ−ϵ2和ϵ2的BEC。 相反,如果W’或W’'是BEC,则W是BEC。
B.速率和可靠性 W N ( i ) W^{(i)}_N WN(i)
现在我们回到第二节末尾的上下文。
命题7:对于任何B-DMC W,
N
=
2
n
,
n
≥
0
,
1
≤
i
≤
N
N=2^n,n≥0,1≤i≤N
N=2n,n≥0,1≤i≤N,变换
(
W
N
(
i
)
,
W
N
(
i
)
)
→
(
W
2
N
(
2
i
−
1
)
,
W
2
N
(
2
i
)
)
(W^{(i)}_N,W^{(i)}_N)→(W^{(2i−1)}_{2N},W^{(2i)}_{2N})
(WN(i),WN(i))→(W2N(2i−1),W2N(2i))在以下意义上是保持速率和提高可靠性的
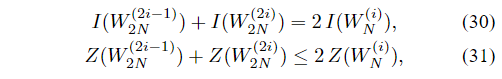
在等式(31)中,如果W是BEC。 信道分裂使速率和可靠性偏离中心,这意味着
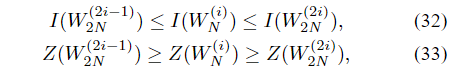
(32)和(33)中的等式(如果I(W)等于0或1)。可靠性项进一步满足
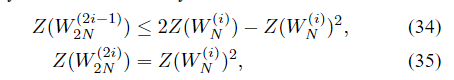
当W是BEC时,在(34)中有等式。累积率和可靠性满足
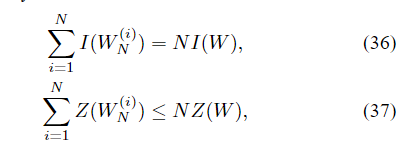
当W是BEC时,与(37)中的等式相等。
这一结果是从命题4和命题5作为特例得出的,不需要单独证明。 累积关系(36)和(37)分别分别重复使用(30)和(31)。命题4中的相等条件是用公式
W
W
W而不是
W
N
(
i
)
W^{(i)}_N
WN(i)表示的;这是可能的,因为:(i)命题4,
I
(
W
)
∈
0
,
1
I(W)∈{0,1}
I(W)∈0,1当且仅当
I
(
W
N
(
i
)
)
∈
0
,
1
I(W^{(i)}_N)∈{0,1}
I(WN(i))∈0,1;(ii)
W
W
W是BEC当且仅当
W
N
(
i
)
W^{(i)}_N
WN(i)是BEC,这是从命题6归纳而来的。
对于
W
W
W是擦除概率为
ϵ
epsilon
ϵ的BEC的特殊情况,从命题4和命题6推导出参数
{
Z
(
W
N
(
i
)
)
}
{Z(W^{(i)}_N)}
{Z(WN(i))}可以通过递归计算
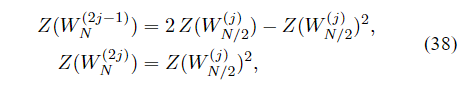
其中
Z
(
W
1
(
1
)
)
=
ϵ
Z(W^{(1)}_1)=epsilon
Z(W1(1))=ϵ。 参数
Z
(
W
N
(
i
)
)
Z(W^{(i)}_N)
Z(WN(i))等于信道
W
N
(
i
)
W^{(i)}_N
WN(i)的擦除概率。递推关系(6)遵循(38)的事实,对于W信道一个BEC
I
(
W
N
(
i
)
)
=
1
−
Z
(
W
N
(
i
)
)
I(W^{(i)}_N) = 1−Z(W^{(i)}_N )
I(WN(i))=1−Z(WN(i))。
IV.信道极化
我们在本节中证明了有关信道极化的主要结果。 该分析基于图5中所示的递归关系。 但是,将图5重新绘制为如图6所示的二叉树会更加方便。树的根节点与通道W相关联。根W产生上通道
W
2
(
1
)
W^{(1)}_2
W2(1)和下通道
W
2
(
2
)
W^{(2)}_2
W2(2),这两个通道与级别1的两个节点相关联。通道
W
2
(
1
)
W^{(1)}_2
W2(1)依次产生通道
W
4
(
1
)
W^{(1)}_4
W4(1)和
W
4
(
2
)
W^{(2)}_4
W4(2),依此类推。 通道
W
2
n
(
i
)
W^{(i)}_{2^n}
W2n(i)位于树的级别n处,节点号i,从顶部开始计数。
在图6中,按位序列对树的节点进行自然索引。根节点使用空序列进行索引。级别1的上部节点使用0进行索引,下部节点使用1进行索引。给定具有索引
b
1
b
2
…
b
n
b1b2…bn
b1b2…bn的n级节点,从其发出的上节点具有标签
b
1
b
2...
b
n
0
b1b2...bn0
b1b2...bn0和下节点
b
1
b
2...
b
n
1
b1b2...bn1
b1b2...bn1。根据该标记,信道
W
2
n
(
i
)
W^{(i)}_{2^n}
W2n(i)位于节点
b
1
b
2...
b
n
b1b2...bn
b1b2...bn处,
i
=
1
+
∑
j
=
1
n
b
j
2
n
⋅
−
j
i=1+ sum^n_{j=1}b_j2^{n·-j}
i=1+∑j=1nbj2n⋅−j。我们将位于节点
b
1
b
2...
b
n
b1b2...bn
b1b2...bn处的信道
W
2
n
(
i
)
W^{(i)}_{2^n}
W2n(i)表示为
W
b
1
…
b
n
W_{b_1…b_n}
Wb1…bn。
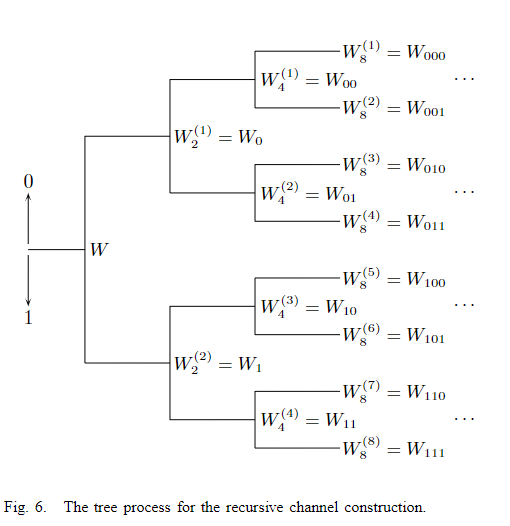
图6递归通道构建的树过程
结合图6,我们定义了一个随机树过程,表示为 K n ; n ≥ 0 {K_n;n≥0} Kn;n≥0。该过程从树的根部开始, K 0 = W K_0=W K0=W。对于任意 n ≥ 0 n≥0 n≥0,给定 K n = W b 1 . . . . b n K_n=W_{b_1....b_n} Kn=Wb1....bn, K n + 1 K_{n+1} Kn+1都等于 W b 1 ⋅ ⋅ ⋅ b n 0 W_{b_1···b_{n0}} Wb1⋅⋅⋅bn0或 W b 1 ⋅ ⋅ ⋅ b n 1 W_{b_1···b{n1}} Wb1⋅⋅⋅bn1,概率各为1/2。因此, { K n } {K_n} {Kn}通过信道树所采取的路径可以被认为是由i.i.d.伯努利RVs { B n ; n = 1 , 2 , . . . . } {B_n;n=1,2,... .} {Bn;n=1,2,....},其中 B n B_n Bn以相等的概率等于0或1。 假定 B 1 , . . . , B n B_1,...,B_n B1,...,Bn已经采用样本值 b 1 , . . . , b n b1,...,bn b1,...,bn,则随机信道过程采用值 K n = W b 1... b n K_n=W_{b1...bn} Kn=Wb1...bn。 为了跟踪信道随机序列 K n K_n Kn的速率和可靠性参数,我们定义了随机过程 I n = I ( K n ) 和 Z n = Z ( K n ) I_n=I(K_n)和Z_n=Z(K_n) In=I(Kn)和Zn=Z(Kn)。
为了更精确地描述这个问题,我们考虑了概率空间
(
Ω
,
F
,
P
)
(Ω,F,P)
(Ω,F,P),其中Ω是所有二进制序列
(
b
1
,
b
2
,
…
)
(b1,b2,…)
(b1,b2,…)的空间是由圆柱集
S
(
b
1
,
…
b
n
)
S(b1,…bn)
S(b1,…bn)生成的Borel场(BF),
S
(
b
1
,
…
b
n
)
=
{
ω
∈
Ω
:
ω
1
=
b
1
,
.
.
.
,
ω
n
=
b
n
}
,
n
≥
1
,
b
1
,
.
.
.
,
b
n
∈
{
0
,
1
}
S(b1,…bn)={ω∈Ω:ω1=b1,...,ωn=bn},n≥1,b1,...,bn∈{0,1}
S(b1,…bn)={ω∈Ω:ω1=b1,...,ωn=bn},n≥1,b1,...,bn∈{0,1},P是定义在F上的概率测度,使得
P
(
S
(
b
1
,
…
,
b
n
)
)
=
1
/
2
n
P(S(b1,…,bn))=1/2^n
P(S(b1,…,bn))=1/2n。对于每个n≥1,我们将
F
n
Fn
Fn定义为cylinder 组
S
(
b
1
,
…
,
b
i
)
,
1
≤
i
≤
n
,
b
1
,
.
.
.
,
b
i
∈
0
,
1
S(b1,…,bi),1≤i≤n,b1,...,bi∈{0,1}
S(b1,…,bi),1≤i≤n,b1,...,bi∈0,1生成的BF。我们将
F
0
F0
F0定义为仅由空集和Ω组成的无关BF。显然,
F
0
⊂
F
1
⊂
⋅
⋅
⋅
⋅
⋅
⋅
⋅
⋅
⋅
F
F0⊂F1⊂·········F
F0⊂F1⊂⋅⋅⋅⋅⋅⋅⋅⋅⋅F。
现在可以如下正式定义上述随机过程。
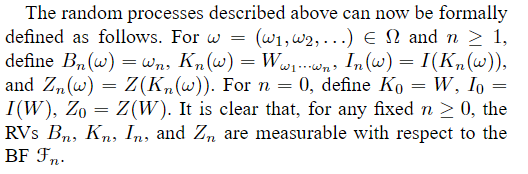
后面的以后再写吧
最后
以上就是瘦瘦小猫咪最近收集整理的关于信道极化:一种用于构造对称二进制输入无记忆信道的容量实现码的方法摘要I.引言与概述II.递归通道变换III. 速率与可靠性转换IV.信道极化的全部内容,更多相关信道极化:一种用于构造对称二进制输入无记忆信道的容量实现码的方法摘要I.引言与概述II.递归通道变换III.内容请搜索靠谱客的其他文章。








发表评论 取消回复