- 信息熵(Information Entropy)
所谓熵也就是信息的不确定性,也就是混乱程度,举个例子便于理解。
我们玩一个大转盘,有32个格子,分别标了1-32的数字,格子大小都一样,那么转动以后每个格子被指针指到的概率也是一样的。那么在转盘转动之前我们要下注的话就很纠结了,随便下哪一个都一样。这时候整个系统的信息是非常混乱无序的。
我现在转好了让你猜是哪个数字,你会怎么猜?我会问,是1-16里面的么?如果不是,那么我会猜:是17到28里的么?最坏情况我需要猜五次,才能确定到底是哪个数字。
如果每次猜对是1,猜错是0,那么表达出来就可能是10101,一共五个数字可以表示最后的结果,我们说这个数字的信息量是5
5 = log32(这里的log都是以2为底)
我们变化一下,假如其中数字1的格子占了31份,那么我们要猜是不是1,那么第一个问题肯定会问,是不是1啊,有31/32的几率会猜对,这时候整个系统就没有那么混乱了。
为了衡量这个混乱程度,信息学里引入了熵的概念, H(xi)表示某个变量的熵
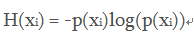
整个系统的熵:
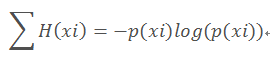
如果每个数字的概率都是1/32的话,整个系统的熵是5, 也是最大值,某个数字概率变大都会使得整个系统的熵减少->变的更有序和好猜。
为了方便后面引入其他熵的概念,再看一个列子
我们有10个球,5个白的,5个黑的,那么设随机变量X为取一个球,颜色的概率分布
P(白) = p(黑) = 0.5
H(X) = -0.5log(0.5) - 0.5log(0.5) = 1
- 联合熵(Joint Entropy)
两个随机变量X,Y的联合分布,可以形成联合熵(Joint Entropy),用H(X, Y)表示。
即:H(X, Y) = -Σ p(x, y) log(x, y)
还是上面的列子,这次我们弄A和B两个盒子,把10个球先放进去。记随机变量X为取到某种颜色球的概率分布,随机变量Y为取到某个盒子的概率分布
第一次我们把5个黑球放进A盒子,5个白球放进B盒子,联合概率分布如下:

第二次我们把2个黑球3个白球放入A盒,3个黑球2个白球放入B盒,联合概率分布如下:

根据熵和联合熵的公式计算一下:
第一次的:
H(X,Y) = -0.5log(0.5) - 0.5log(0.5) - 0log(0) - 0log(0)= 1
H(X) = -0.5log(0.5) - 0.5log(0.5)= 1
H(Y) = -0.5log(0.5) - 0.5log(0.5)= 1
第二次的,不管取的哪个盒子,取到黑球和白球的概率还是一样的0.5:
H(X,Y) = -0.2log(0.2) - 0.3log(0.3) -0.2log(0.2) - 0.3log(0.3)= 1.97
H(X) = -0.5log(0.5) - 0.5log(0.5)= 1
H(Y) = -0.5log(0.5) - 0.5log(0.5)= 1
于是可以看出来,单论X和Y的不确定性,其实两种分类是一样的,信息熵都是1,但是联合熵就不同了,一个是1,一个是1.97。第一个分类为什么是1呢,因为我们确定了盒子就确定了球的颜色,整个系统是非常有序的,需要表达的信息量和表达盒子的信息量是一样的。但第二种分法,我们抽出一个盒子以后,对球的颜色还是不太知道,不过已经比原来不分盒子要好点,最少我们知道哪种颜色多一个,于是联合熵就没有等于两个随机变量的信息熵之和,而是小了一点。
这里再说联合熵所表达的物理含义是,对一个两个随机变量组成的随机系统,我们可以先观察一个随机变量获取信息量,观察完后,我们可以在拥有这个信息量的基础上观察第二个随机变量的信息量。如果两个随机变量毫无关系,那么H(X, Y) = H(X) + H(Y)
- 条件熵(Conditional entropy)
条件熵 H(Y|X) 表示在已知随机变量 X 的条件下随机变量 Y 的不确定性。条件熵 H(Y|X) 定义为 X 给定条件下 Y 的条件概率分布的熵对 X 的数学期望:
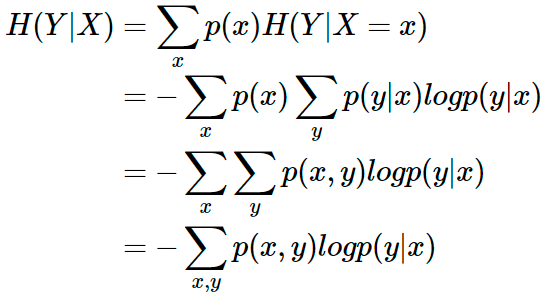
我们再对上面的两种分类计算一下条件熵:
第一次的:
H(Y|X) = -0.5log(1) - 0log(0) - 0log(0) - 0.5log(1) = 0
第二次的:
H(Y|X) = -0.2log(0.4) - 0.3log(0.6) - 0.3log(0.6) - 0.2log(0.4) = 0.97
惊奇的发现:
H(Y|X) = H(X,Y) - H(X)
其实条件熵就是在X确定了的情况下,我们要知道Y还需要多少信息量,第一种分法,盒子一确定我们就知道球的颜色了,于是条件熵是0,第二种分法,确定了盒子我们还是得接着猜,于是条件熵接近于H(Y),第一次分类没啥用。。。这里就回想起了之前看得决策树算法ID3,其实就是做了一次分类之后,再看确定分类还需要多少信息量——条件熵
https://blog.csdn.net/weixin_43909872/article/details/85206009
条件熵H(Y|X) = H(X,Y) - H(X)的证明:
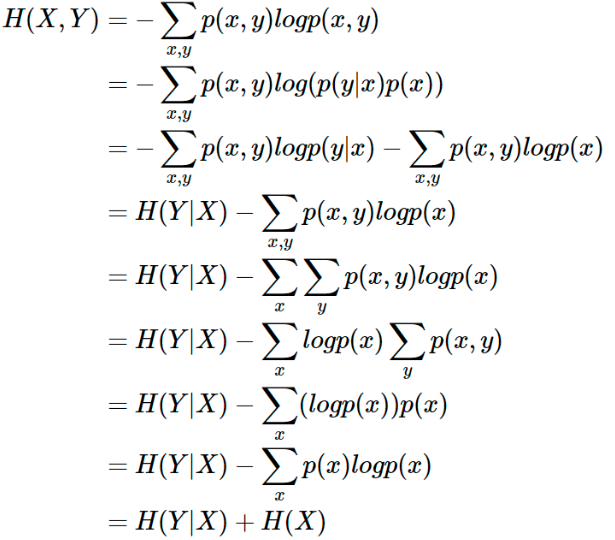
- 交叉熵(Cross Entropy)
其实交叉熵应该放在相对熵前面讲。
相对熵用来衡量在给定的真实分布下,使用非真实分布所指定的策略消除系统的不确定性所需要付出的努力的大小,也就是需要的信息量。
最低的交叉熵就是原分布的信息熵,此时p(x) = q(x)
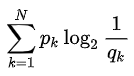
那么这个交叉熵到底好不好呢,得跟原来的真实分布做比较,于是有了下面的相对熵。
具体例子也在下面一起说。
- 相对熵 (Relative entropy),也称KL散度 (Kullback–Leibler divergence)
设 p(x)、q(x) 是 离散随机变量 X 中取值的两个概率分布,则 p 对 q 的相对熵是:
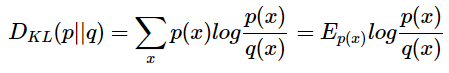
相对熵用来衡量在给定的真实分布下,使用非真实分布所指定的策略消除系统的不确定性所需要付出的努力的大小。
回到前面32数字转盘的列子,假设一个数字占了16格,其他的31个数字平分剩下的16格,那么真实分布就是:1/2,1/62,1/62.。。。。
如果我们要玩这个转盘,肯定要下重注在数字1上,其他的策略都不太聪明
那么如何来衡量这个“不太聪明”的程度呢?用相对熵!
先来看下上面的公式,p(x)是真实分布,q(x)为非真实分布,如果我们按照真实分布去猜,那么这个公式结果就是0, 因为p(x) = q(x)
但是我们现在用的策略是平均下注,也就是认为一个数字占一格,那么q(x1) = 1/32,而p(x1) = 1/2,很明显p(x)/q(x) = 16,其他的因为p(x)占比较少,算出来的交叉熵肯定是大于1的,说明选择的策略不符合真实分布。
再对相对熵的公式做一些变形:
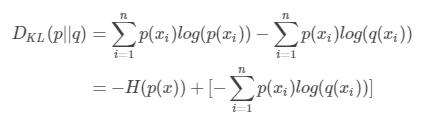
DKL(p||q)=H(p,q)−H§(当用非真实分布 q(x) 得到的平均码长比真实分布 p(x) 得到的平均码长多出的比特数就是相对熵)
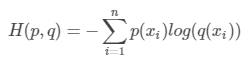
因为H(p)是固定的,所以在机器学习里我们一般用交叉熵做loss函数
最后
以上就是苹果发带最近收集整理的关于信息熵,联合熵,条件熵,交叉熵,相对熵+例子的全部内容,更多相关信息熵内容请搜索靠谱客的其他文章。








发表评论 取消回复