在以前的文章里面我有写过人脸识别相关的项目实践,基本的路线是:
1、开发摄像头人脸数据采集模块,快速采集批量的包含人脸的图像数据
2、人脸区域切割提取,构建数据集
3、CNN模型训练,测试
4、调用摄像头加载离线模型实时人脸识别在这里其实有两块是跟OpenCV密不可分的,第二步里面的人脸区域切割提取需要借助于OpenCV的级联分类器实现人脸区域的定位,完成模型的训练之后第四步里面,调用摄像头加载离线模型实时人脸识别的时候也是需要借助于OpenCV的级联分类器才能实现人脸ROI区域的切割提取之后才能输入到模型里面进行计算分析的。
这里为什么要先拿人脸识别的项目来讲这么一堆呢?因为本文提到的两种方法,第一种的实现方式主要就是借助于OpenCV内置的级联分类器来实现的,如下:

代码实现如下:
'''
初始化加载五官检测级联分类器模型
'''
#人脸检测器
face_cascade = cv.CascadeClassifier('frontalface.xml')
face_cascade.load('models/frontalface.xml')
#眼睛检测器
eye_cascade = cv.CascadeClassifier('eye.xml')
eye_cascade.load('models/eye.xml')
#嘴巴检测器
mouth_cascade = cv.CascadeClassifier('mouth.xml')
mouth_cascade.load('models/mouth.xml')
#鼻子检测器
nose_cascade = cv.CascadeClassifier('nose.xml')
nose_cascade.load('models/nose.xml')
#耳朵检测器
leftear_cascade = cv.CascadeClassifier('leftear.xml')
leftear_cascade.load('models/leftear.xml')
rightear_cascade = cv.CascadeClassifier('rightear.xml')
rightear_cascade.load('models/rightear.xml')单个xml文件其实就是对应着OpenCV里面单个物体的检测器,这个跟我们用的YOLO的深度学习之类的检测器不同,这个更简单一点,下面是基于OpenCV的五官检测的核心代码实现,如下us所示:
def sensesDetect(pic='ldh.jpg',save_path='res.jpg'):
'''
基于OpenCV的五官检测
'''
frame=cv.imread(pic)
frame1=copy.copy(frame)
imgsmall=copy.copy(frame)
#人脸识别
gray = cv.cvtColor(frame1, cv.COLOR_BGR2GRAY)
# 脸
faces = face_cascade.detectMultiScale(gray, 1.2, 3)
for (x, y, w, h) in faces:
img = cv.rectangle(frame1, (x, y), (x + w, y + h), (255, 0, 0), 2)
roi_gray = gray[y:y + h, x:x + w]
roi_color = img[y:y + h, x:x + w]
# 眼睛
eyes = eye_cascade.detectMultiScale(roi_gray, 1.2, 3)
for (ex, ey, ew, eh) in eyes:
cv.rectangle(roi_color, (ex, ey), (ex + ew, ey + eh), (0, 255, 0), 2)
# 嘴巴
mouth = mouth_cascade.detectMultiScale(roi_gray, 1.5, 5)
for (mx, my, mw, mh) in mouth:
cv.rectangle(roi_color, (mx, my), (mx + mw, my + mh), (0, 0, 255), 2)
# 鼻子
nose = nose_cascade.detectMultiScale(roi_gray, 1.2, 5)
for (nx, ny, nw, nh) in nose:
cv.rectangle(roi_color, (nx, ny), (nx + nw, ny + nh), (255, 0, 255), 2)
# 耳朵
leftear = leftear_cascade.detectMultiScale(roi_gray, 1.01, 2)
for (lx, ly, lw, lh) in leftear:
cv.rectangle(roi_color, (lx, ly), (lx + lw, ly + lh), (0, 0, 0), 2)
rightear = rightear_cascade.detectMultiScale(roi_gray, 1.01, 2)
for (rx, ry, rw, rh) in rightear:
cv.rectangle(roi_color, (rx, ry), (rx + rw, ry + rh), (0, 0, 0), 2)
markTargets(frame)
grayEdge(frame)
cv.imshow("capture", frame)
cv.imwrite(save_path,img)接下来我们来看一下具体的实例,这里以天王刘德华为例,看下具体的效果:

再来看一位美女的效果:
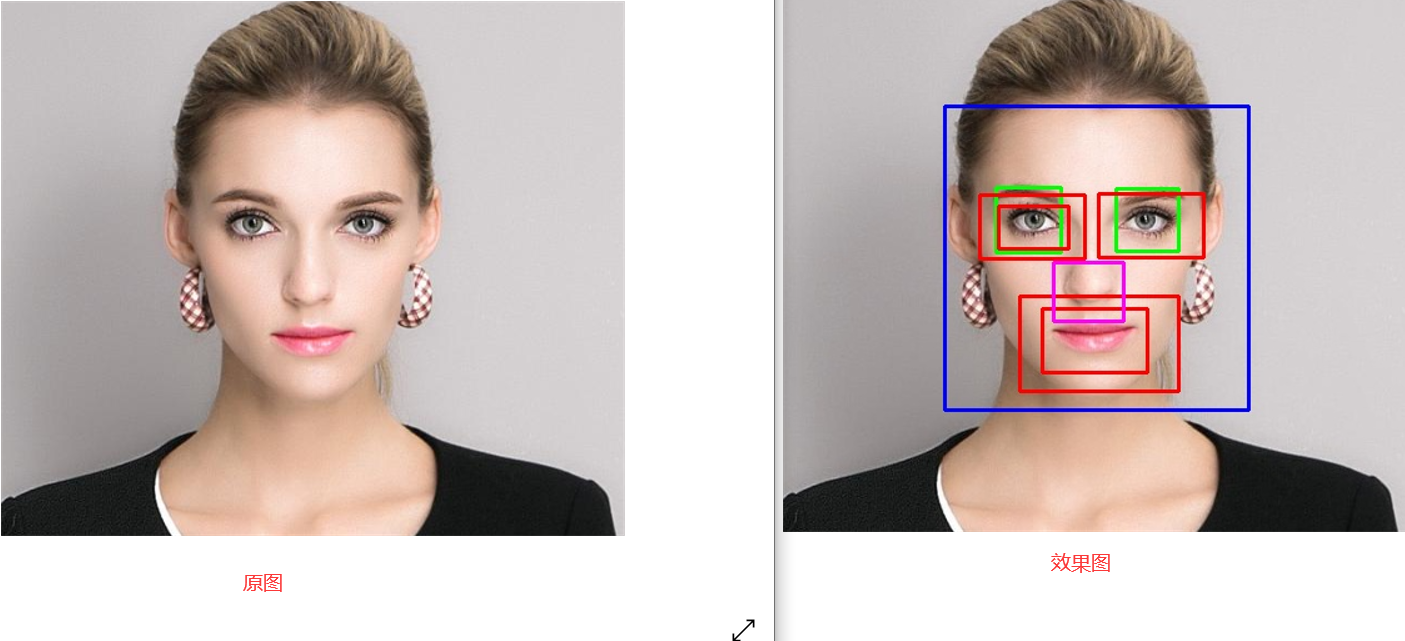
基于OpenCV的五官检测方法属于开箱即用的类型,很多时候可能由于图像的复杂性或者不同源等问题导致检测不到对应的目标,这个时候就可以自己去训练对应的模型来适应自己的数据集了,下面还有一些例子,检测的效果并不好。
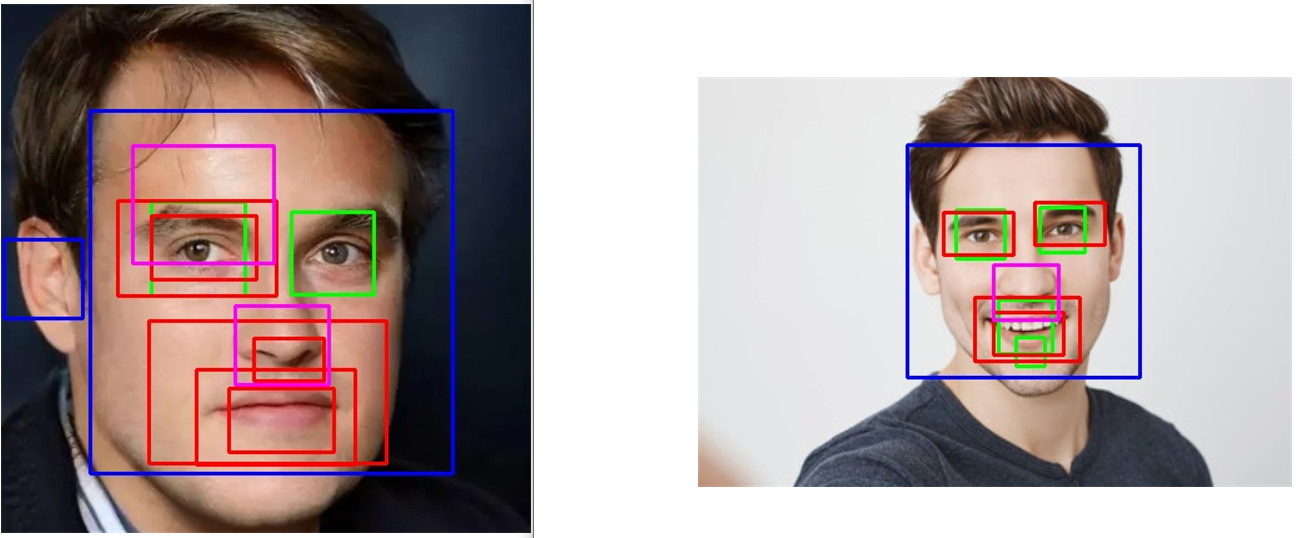
感兴趣的话可以自己亲身实践一下,到这里基于OpenCV的五官检测方法就介绍完了,接下来还有另一种方法可以实现“类似”的检测功能,为什么说是“类似”的呢?因为这个跟传统的检测得到目标坐标框的方式不同,具体我们往下看。
第二种方式主要是基于开源人脸识别库 dlib 实现检测功能的,官方地址在这里。
官方博客在这里。

这是一个由C++开发出来的强大的库,Git地址在这里。
Dlib简介如下:
Dlib简介
Dlib是一个使用现代C++技术编写的跨平台的通用库,遵守 Boost Software licence.
主要特点如下:
1.完善的文档:每个类每个函数都有详细的文档,并且提供了大量的示例代码,如果你发现文档描述不清晰或者没有文档,告诉作者,作者会立刻添加。
2.可移植代码:代码符合ISO C++标准,不需要第三方库支持,支持win32、Linux、Mac OS X、Solaris、HPUX、BSDs 和 POSIX 系统
3.线程支持:提供简单的可移植的线程API
4.网络支持:提供简单的可移植的Socket API和一个简单的Http服务器
5.图形用户界面:提供线程安全的GUI API
6.数值算法:矩阵、大整数、随机数运算等
7.机器学习算法:
8.图形模型算法:
9.图像处理:支持读写Windows BMP文件,不同类型色彩转换
10.数据压缩和完整性算法:CRC32、Md5、不同形式的PPM算法
11.测试:线程安全的日志类和模块化的单元测试框架以及各种测试assert支持
12.一般工具:XML解析、内存管理、类型安全的big/little endian转换、序列化支持和容器类推荐一个安装、实践、学习入门比较不错的教程,地址在这里。
简单的介绍就说到这里,接下来回归正文,接着我们的五官检测部分,核心代码实现如下所示:
#!usr/bin/env python
#encoding:utf-8
from __future__ import division
'''
__Author__:沂水寒城
功能: 基于开源人脸识别库 dlib 实现检测功能
'''
from FR import *
from PIL import Image, ImageDraw
from matplotlib import pyplot as plt
def sensesDetect(pic_path='ldh.jpg',save_path='res.jpg'):
'''
五官检测
'''
plt.clf()
plt.subplot(1,2,1)
image = load_image_file(pic_path)
plt.imshow(image)
plt.title('originalImage')
face_landmarks_list = face_landmarks(image)
print("{} face(s) in this photograph.".format(len(face_landmarks_list)))
pil_image = Image.fromarray(image)
d = ImageDraw.Draw(pil_image)
for face_landmark in face_landmarks_list:
for facial_feature in face_landmark.keys():
print("The {} in this face has the following points: {}".format(facial_feature, face_landmark[facial_feature]))
for facial_feature in face_landmark.keys():
d.line(face_landmark[facial_feature], width=5)
pil_image.save(save_path)
plt.subplot(1,2,2)
plt.imshow(pil_image)
plt.title('detectImage')
plt.show()
接下来我们来看下具体的效果图:


速度还是很快的,个人感觉dlib的功能还是很强大的,这里我主要是借助于dlib来实现人体的五官检测的应用了,还有很多的有趣的应用可以去开发实践,感兴趣的话都拿起来亲身实践一下吧,到这里本文的内容就结束了,欢迎交流!
最后
以上就是幸福哈密瓜最近收集整理的关于OpenCV+dlib+Python实现人体五官检测的全部内容,更多相关OpenCV+dlib+Python实现人体五官检测内容请搜索靠谱客的其他文章。








发表评论 取消回复