系列文章目录
(一)从零开始设计RISC-V处理器——指令系统
(二)从零开始设计RISC-V处理器——单周期处理器的设计
(三)从零开始设计RISC-V处理器——单周期处理器的仿真
(四)从零开始设计RISC-V处理器——ALU的优化
(五)从零开始设计RISC-V处理器——五级流水线之数据通路的设计
(六)从零开始设计RISC-V处理器——五级流水线之控制器的设计
(七)从零开始设计RISC-V处理器——五级流水线之数据冒险
(八)从零开始设计RISC-V处理器——五级流水线之控制冒险
(九)从零开始设计RISC-V处理器——五级流水线之分支计算前移
(十)从零开始设计RISC-V处理器——五级流水线之静态预测
文章目录
- 系列文章目录
- 前言
- 一、加法器的设计
- 二、移位器的设计
- 三、仿真测试
- 总结
前言
在前面的三篇文章中,我们已经完成了单周期CPU的设计,从这篇文章开始对这个单周期的CPU进行优化。
首先是对ALU部件进行优化,因为ALU是CPU最重要的部件之一,所有的运算都在这里进行。之前我们把ALU的运算部件分为算数运算单元(加法器),移位运算(移位器),小于置一(比较器),逻辑运算(逻辑门)几个部分。前面的设计中,加法器直接用verilog中的运算符“+”实现,移位器直接用verilog中的运算符“>>,<<”实现,这样相当于把加法器和移位器的设计交给综合工具自动完成,这样设计的ALU的性能是我们不可掌控的。因此,这篇文章就对加法器和移位器的优化做一个介绍。
(目前单周期处理器代码已经更新完成,点击链接直达:基于RISC-V指令集的单周期处理器的设计)
一、加法器的设计
常见的加法器有很多种,有兴趣的读者可自行学习,此处主要介绍两种加法器:行波进位加法器和超前进位加法器。
行波进位加法器,是由n个一位全加器串联而成,结构非常简单,上一级的进位输出连接到下一级的进位输入。这种加法器结构简单,使用的逻辑资源很少,但是由于是串行计算,下一级的结果依赖于上一级的进位输出,因此对于多位的加法器,计算一次加法所需要的时间非常久。
如果能够提前把每一级的进位输出计算出来,那么就可以有效缩短延时,这便是所谓的超前进位加法器。
下面开始分析。
首先列出一位全加器的真值表
| Ai | Bi | Ci | Si | Ci+1 |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 | 0 |
| 0 | 1 | 0 | 1 | 0 |
| 0 | 1 | 1 | 0 | 1 |
| 1 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 | 1 |
| 1 | 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 1 | 1 |
由真值表可以得出以下关系:
Si=Ai ^ Bi ^ Ci;
Ci+1=Bi&Ci + Ai&Ci + Ai&Bi=Ai&Bi + (Ai + Bi)&Ci=Gi + Pi&Ci;
这里定义了两个新的信号:Gi=Ai&Bi, Pi=Ai | Bi;
Gi称为进位产生信号,Pi称为进位传递信号。
Gi为1时,一定产生进位,即Ci+1一定为1;
Gi为0且Pi为1时,进位传递,即把Ci的值传递给Ci+1,Ci为0时,Ci+1为0,Ci为1时,Ci+1为1。
将每一级的进位信号表示如下:
C0=Cin;
C1=A0&B0+(A0+B0)&C0=G0+P0&C0
C2=G1+P1&C1=G1+P1&(G0+P0&C0)=G1+P1&G0+P0&P1&C0
C3=G2+P2&C2=G2+P2&G1+P2&P1&G0+P2&P1&P0&C0
C4=G3+P3&G2+P3&P2&G1+P3&P2&P1&G0+P3&P2&P1&P0&C0
……
通过上式可以看到,以这样的方式展开,每一级的进位信号仅仅依赖于Pi,Gi以及C0,这样我们就可以根据加数A和被加数B,以及进位信号C0,同时求出每一级的进位信号Ci,同时可以求出每一级的Si。
通过以上分析,可以得出结论:
行波加法器,串行计算,结构简单(面积小),延时大
超前进位加法器,并行计算,结构复杂(面积大),延时小。
想要设计一个高性能的32位加法器,理论上可以同时并行生成所有的Si和Ci,但是这样会使电路结构非常复杂,极大的增大电路的扇入和扇出,这在实际设计时也是不可行的。
因此,我们采用组内并行和组间并行的方式实现一个32位加法器,即先实现一个4位超前进位加法器,再用4个4位超前进位加法器组间并行实现16位超前进位加法器,再用2个16位超前进位加法器组间并行实现32位超前进位加法器。
其结构如下:
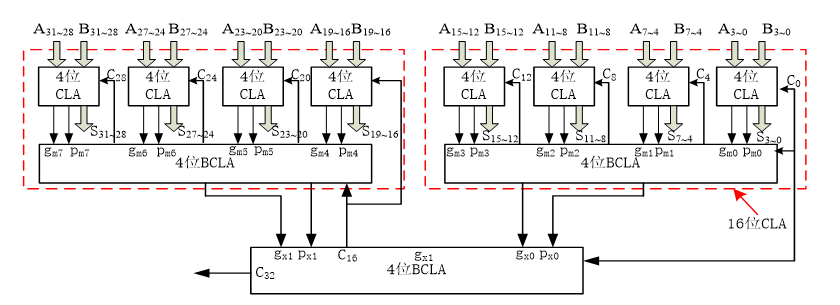
实现代码如下:
//4位CLA部件
module cla_4(p,g,c_in,c,gx,px);
input[3:0] p,g;
input c_in;
output[4:1] c;
output gx,px;
assign c[1] = p[0]&c_in | g[0];
assign c[2] = p[1]&p[0]&c_in | p[1]&g[0] | g[1];
assign c[3] = p[2]&p[1]&p[0]&c_in | p[2]&p[1]&g[0] | p[2]&g[1] | g[2];
assign c[4] = gx | px&c_in;
assign px = p[3]&p[2]&p[1]&p[0];
assign gx = g[3] | p[3]&g[2] | p[3]&p[2]&g[1] | p[3]&p[2]&p[1]&g[0];
endmodule
//32位全加器
module cla_adder32(A,B,cin,result,cout);
input [31:0] A;
input [31:0] B;
input cin;
output[31:0] result;
output cout;
进位产生信号,进位传递信号
wire[31:0] TAG,TAP;
wire[32:1] TAC;
wire[15:0] TAG_0,TAP_0;
wire[3:0] TAG_1,TAP_1;
wire[8:1] TAC_1;
wire[4:1] TAC_2;
assign result = A ^ B ^ {TAC[31:1],cin};
进位产生信号,进位传递信号
assign TAG = A&B;
assign TAP = A|B;
cla_4 cla_0_0( .p(TAP[3:0]), .g(TAG[3:0]), .c_in(cin), .c(TAC[4:1]), .gx(TAG_0[0]),.px(TAP_0[0]));
cla_4 cla_0_1( .p(TAP[7:4]), .g(TAG[7:4]), .c_in(TAC_1[1]),.c(TAC[8:5]), .gx(TAG_0[1]),.px(TAP_0[1]));
cla_4 cla_0_2( .p(TAP[11:8]), .g(TAG[11:8]), .c_in(TAC_1[2]),.c(TAC[12:9]), .gx(TAG_0[2]),.px(TAP_0[2]));
cla_4 cla_0_3( .p(TAP[15:12]),.g(TAG[15:12]),.c_in(TAC_1[3]),.c(TAC[16:13]),.gx(TAG_0[3]),.px(TAP_0[3]));
cla_4 cla_0_4( .p(TAP[19:16]),.g(TAG[19:16]),.c_in(TAC_1[4]),.c(TAC[20:17]),.gx(TAG_0[4]),.px(TAP_0[4]));
cla_4 cla_0_5( .p(TAP[23:20]),.g(TAG[23:20]),.c_in(TAC_1[5]),.c(TAC[24:21]),.gx(TAG_0[5]),.px(TAP_0[5]));
cla_4 cla_0_6( .p(TAP[27:24]),.g(TAG[27:24]),.c_in(TAC_1[6]),.c(TAC[28:25]),.gx(TAG_0[6]),.px(TAP_0[6]));
cla_4 cla_0_7( .p(TAP[31:28]),.g(TAG[31:28]),.c_in(TAC_1[7]),.c(TAC[32:29]),.gx(TAG_0[7]),.px(TAP_0[7]));
cla_4 cla_1_0(.p(TAP_0[3:0]), .g(TAG_0[3:0]), .c_in(cin),.c(TAC_1[4:1]), .gx(TAG_1[0]),.px(TAP_1[0]));
cla_4 cla_1_1(.p(TAP_0[7:4]), .g(TAG_0[7:4]), .c_in(TAC_1[4]),.c(TAC_1[8:5]), .gx(TAG_1[1]),.px(TAP_1[1]));
assign TAG_1[3:2] = 2'b00;
assign TAP_1[3:2] = 2'b00;
cla_4 cla_2_0(.p(TAP_1[3:0]), .g(TAG_1[3:0]), .c_in(1'b0), .c(TAC_2[4:1]), .gx(),.px());
assign cout = TAC_2[2];
endmodule
二、移位器的设计
移位运算不涉及到时序,用组合逻辑电路的移位器实现。
移位的原理是使用不同的接线,错位ALU_SHIFT位就实现了移动ALU_SHIFT位,所以使用数据选择器实现。
module Shifter(input [31:0] ALU_DA,
input [4:0] ALU_SHIFT,
input [1:0] Shiftctr,
output reg [31:0] shift_result);
reg[31:0] SLL_M,SRL_M,SRA_M;
always@(*)//SRL
begin
case(ALU_SHIFT)
5'b00000:SRL_M[31:0]=ALU_DA[31:0];
5'b00001:SRL_M[31:0]={1'd0 ,ALU_DA[31:1]};
5'b00010:SRL_M[31:0]={2'd0 ,ALU_DA[31:2]};
5'b00011:SRL_M[31:0]={3'd0 ,ALU_DA[31:3]};
5'b00100:SRL_M[31:0]={4'd0 ,ALU_DA[31:4]};
5'b00101:SRL_M[31:0]={5'd0 ,ALU_DA[31:5]};
5'b00110:SRL_M[31:0]={6'd0 ,ALU_DA[31:6]};
5'b00111:SRL_M[31:0]={7'd0 ,ALU_DA[31:7]};
5'b01000:SRL_M[31:0]={8'd0 ,ALU_DA[31:8]};
5'b01001:SRL_M[31:0]={9'd0 ,ALU_DA[31:9]};
5'b01010:SRL_M[31:0]={10'd0,ALU_DA[31:10]};
5'b01011:SRL_M[31:0]={11'd0,ALU_DA[31:11]};
5'b01100:SRL_M[31:0]={12'd0,ALU_DA[31:12]};
5'b01101:SRL_M[31:0]={13'd0,ALU_DA[31:13]};
5'b01110:SRL_M[31:0]={14'd0,ALU_DA[31:14]};
5'b01111:SRL_M[31:0]={15'd0,ALU_DA[31:15]};
5'b10000:SRL_M[31:0]={16'd0,ALU_DA[31:16]};
5'b10001:SRL_M[31:0]={17'd0,ALU_DA[31:17]};
5'b10010:SRL_M[31:0]={18'd0,ALU_DA[31:18]};
5'b10011:SRL_M[31:0]={19'd0,ALU_DA[31:19]};
5'b10100:SRL_M[31:0]={20'd0,ALU_DA[31:20]};
5'b10101:SRL_M[31:0]={21'd0,ALU_DA[31:21]};
5'b10110:SRL_M[31:0]={22'd0,ALU_DA[31:22]};
5'b10111:SRL_M[31:0]={23'd0,ALU_DA[31:23]};
5'b11000:SRL_M[31:0]={24'd0,ALU_DA[31:24]};
5'b11001:SRL_M[31:0]={25'd0,ALU_DA[31:25]};
5'b11010:SRL_M[31:0]={26'd0,ALU_DA[31:26]};
5'b11011:SRL_M[31:0]={27'd0,ALU_DA[31:27]};
5'b11100:SRL_M[31:0]={28'd0,ALU_DA[31:28]};
5'b11101:SRL_M[31:0]={29'd0,ALU_DA[31:29]};
5'b11110:SRL_M[31:0]={30'd0,ALU_DA[31:30]};
5'b11111:SRL_M[31:0]={31'd0,ALU_DA[31]};
default: SRL_M[31:0]=ALU_DA[31:0];
endcase
end
always@(*) //SLL
begin
case(ALU_SHIFT)
5'b00000:SLL_M[31:0]=ALU_DA[31:0];
5'b00001:SLL_M[31:0]={ALU_DA[30:0],1'd0};
5'b00010:SLL_M[31:0]={ALU_DA[29:0],2'd0};
5'b00011:SLL_M[31:0]={ALU_DA[28:0],3'd0};
5'b00100:SLL_M[31:0]={ALU_DA[27:0],4'd0};
5'b00101:SLL_M[31:0]={ALU_DA[26:0],5'd0};
5'b00110:SLL_M[31:0]={ALU_DA[25:0],6'd0};
5'b00111:SLL_M[31:0]={ALU_DA[24:0],7'd0};
5'b01000:SLL_M[31:0]={ALU_DA[23:0],8'd0};
5'b01001:SLL_M[31:0]={ALU_DA[22:0],9'd0};
5'b01010:SLL_M[31:0]={ALU_DA[21:0],10'd0};
5'b01011:SLL_M[31:0]={ALU_DA[20:0],11'd0};
5'b01100:SLL_M[31:0]={ALU_DA[19:0],12'd0};
5'b01101:SLL_M[31:0]={ALU_DA[18:0],13'd0};
5'b01110:SLL_M[31:0]={ALU_DA[17:0],14'd0};
5'b01111:SLL_M[31:0]={ALU_DA[16:0],15'd0};
5'b10000:SLL_M[31:0]={ALU_DA[15:0],16'd0};
5'b10001:SLL_M[31:0]={ALU_DA[14:0],17'd0};
5'b10010:SLL_M[31:0]={ALU_DA[13:0],18'd0};
5'b10011:SLL_M[31:0]={ALU_DA[12:0],19'd0};
5'b10100:SLL_M[31:0]={ALU_DA[11:0],20'd0};
5'b10101:SLL_M[31:0]={ALU_DA[10:0],21'd0};
5'b10110:SLL_M[31:0]={ALU_DA[9:0] ,22'd0};
5'b10111:SLL_M[31:0]={ALU_DA[8:0] ,23'd0};
5'b11000:SLL_M[31:0]={ALU_DA[7:0] ,24'd0};
5'b11001:SLL_M[31:0]={ALU_DA[6:0] ,25'd0};
5'b11010:SLL_M[31:0]={ALU_DA[5:0] ,26'd0};
5'b11011:SLL_M[31:0]={ALU_DA[4:0] ,27'd0};
5'b11100:SLL_M[31:0]={ALU_DA[3:0] ,28'd0};
5'b11101:SLL_M[31:0]={ALU_DA[2:0] ,29'd0};
5'b11110:SLL_M[31:0]={ALU_DA[1:0] ,30'd0};
5'b11111:SLL_M[31:0]={ALU_DA[0],31'd0};
default: SLL_M[31:0]=ALU_DA[31:0];
endcase
end
always@(*) //SRA
begin
case(ALU_SHIFT)
5'b00000:SRA_M[31:0]=ALU_DA[31:0];
5'b00001:SRA_M[31:0]={{1{ALU_DA[31]}},ALU_DA[31:1]};
5'b00010:SRA_M[31:0]={{2{ALU_DA[31]}},ALU_DA[31:2]};
5'b00011:SRA_M[31:0]={{3{ALU_DA[31]}},ALU_DA[31:3]};
5'b00100:SRA_M[31:0]={{4{ALU_DA[31]}},ALU_DA[31:4]};
5'b00101:SRA_M[31:0]={{5{ALU_DA[31]}},ALU_DA[31:5]};
5'b00110:SRA_M[31:0]={{6{ALU_DA[31]}},ALU_DA[31:6]};
5'b00111:SRA_M[31:0]={{7{ALU_DA[31]}},ALU_DA[31:7]};
5'b01000:SRA_M[31:0]={{8{ALU_DA[31]}},ALU_DA[31:8]};
5'b01001:SRA_M[31:0]={{9{ALU_DA[31]}},ALU_DA[31:9]};
5'b01010:SRA_M[31:0]={{10{ALU_DA[31]}},ALU_DA[31:10]};
5'b01011:SRA_M[31:0]={{11{ALU_DA[31]}},ALU_DA[31:11]};
5'b01100:SRA_M[31:0]={{12{ALU_DA[31]}},ALU_DA[31:12]};
5'b01101:SRA_M[31:0]={{13{ALU_DA[31]}},ALU_DA[31:13]};
5'b01110:SRA_M[31:0]={{14{ALU_DA[31]}},ALU_DA[31:14]};
5'b01111:SRA_M[31:0]={{15{ALU_DA[31]}},ALU_DA[31:15]};
5'b10000:SRA_M[31:0]={{16{ALU_DA[31]}},ALU_DA[31:16]};
5'b10001:SRA_M[31:0]={{17{ALU_DA[31]}},ALU_DA[31:17]};
5'b10010:SRA_M[31:0]={{18{ALU_DA[31]}},ALU_DA[31:18]};
5'b10011:SRA_M[31:0]={{19{ALU_DA[31]}},ALU_DA[31:19]};
5'b10100:SRA_M[31:0]={{20{ALU_DA[31]}},ALU_DA[31:20]};
5'b10101:SRA_M[31:0]={{21{ALU_DA[31]}},ALU_DA[31:21]};
5'b10110:SRA_M[31:0]={{22{ALU_DA[31]}},ALU_DA[31:22]};
5'b10111:SRA_M[31:0]={{23{ALU_DA[31]}},ALU_DA[31:23]};
5'b11000:SRA_M[31:0]={{24{ALU_DA[31]}},ALU_DA[31:24]};
5'b11001:SRA_M[31:0]={{25{ALU_DA[31]}},ALU_DA[31:25]};
5'b11010:SRA_M[31:0]={{26{ALU_DA[31]}},ALU_DA[31:26]};
5'b11011:SRA_M[31:0]={{27{ALU_DA[31]}},ALU_DA[31:27]};
5'b11100:SRA_M[31:0]={{28{ALU_DA[31]}},ALU_DA[31:28]};
5'b11101:SRA_M[31:0]={{29{ALU_DA[31]}},ALU_DA[31:29]};
5'b11110:SRA_M[31:0]={{30{ALU_DA[31]}},ALU_DA[31:30]};
5'b11111:SRA_M[31:0]={{31{ALU_DA[31]}},ALU_DA[31]};
default: SRA_M[31:0]=ALU_DA[31:0];
endcase
end
always@(*) //SHIFT
begin
case(Shiftctr)
2'b00:shift_result=SLL_M;
2'b01:shift_result=SRL_M;
2'b10:shift_result=SRA_M;
default: shift_result=ALU_DA;
endcase
end
endmodule
三、仿真测试
单独的加法器和移位器的仿真请读者自行完成,在此不再赘述。
将改进后的ALU模块的代码展示如下:
module alu(
ALU_DA,
ALU_DB,
ALU_CTL,
ALU_ZERO,
ALU_OverFlow,
ALU_DC
);
input [31:0] ALU_DA;
input [31:0] ALU_DB;
input [3:0] ALU_CTL;
output ALU_ZERO;
output ALU_OverFlow;
output reg [31:0] ALU_DC;
//********************generate ctr***********************
wire SUBctr;
wire SIGctr;
wire Ovctr;
wire [1:0] Opctr;
wire [1:0] Logicctr;
wire [1:0] Shiftctr;
assign SUBctr = (~ ALU_CTL[3] & ~ALU_CTL[2] & ALU_CTL[1]) | ( ALU_CTL[3] & ~ALU_CTL[2]);
assign Opctr = ALU_CTL[3:2];
assign Ovctr = ALU_CTL[0] & ~ ALU_CTL[3] & ~ALU_CTL[2] ;
assign SIGctr = ALU_CTL[0];
assign Logicctr = ALU_CTL[1:0];
assign Shiftctr = ALU_CTL[1:0];
//********************************************************
//*********************logic op***************************
reg [31:0] logic_result;
always@(*) begin
case(Logicctr)
2'b00:logic_result = ALU_DA & ALU_DB;
2'b01:logic_result = ALU_DA | ALU_DB;
2'b10:logic_result = ALU_DA ^ ALU_DB;
2'b11:logic_result = ~(ALU_DA | ALU_DB);
endcase
end
//********************************************************
//************************shift op************************
wire [4:0] ALU_SHIFT;
wire [31:0] shift_result;
assign ALU_SHIFT=ALU_DB[4:0];
Shifter Shifter(.ALU_DA(ALU_DA),
.ALU_SHIFT(ALU_SHIFT),
.Shiftctr(Shiftctr),
.shift_result(shift_result));
//********************************************************
//************************add sub op**********************
wire [31:0] BIT_M,XOR_M;
wire ADD_carry,ADD_OverFlow;
wire [31:0] ADD_result;
assign BIT_M={32{SUBctr}};
assign XOR_M=BIT_M^ALU_DB;
Adder Adder(.A(ALU_DA),
.B(XOR_M),
.Cin(SUBctr),
.ALU_CTL(ALU_CTL),
.ADD_carry(ADD_carry),
.ADD_OverFlow(ADD_OverFlow),
.ADD_zero(ALU_ZERO),
.ADD_result(ADD_result));
assign ALU_OverFlow = ADD_OverFlow & Ovctr;
//********************************************************
//**************************slt op************************
wire [31:0] SLT_result;
wire LESS_M1,LESS_M2,LESS_S,SLT_M;
assign LESS_M1 = ADD_carry ^ SUBctr;
assign LESS_M2 = ADD_OverFlow ^ ADD_result[31];
assign LESS_S = (SIGctr==1'b0)?LESS_M1:LESS_M2;
assign SLT_result = (LESS_S)?32'h00000001:32'h00000000;
//********************************************************
//**************************ALU result********************
always @(*)
begin
case(Opctr)
2'b00:ALU_DC<=ADD_result;
2'b01:ALU_DC<=logic_result;
2'b10:ALU_DC<=SLT_result;
2'b11:ALU_DC<=shift_result;
endcase
end
//********************************************************
endmodule
//********************************************************
//*************************shifter************************
//`define BEHAVOR
module Shifter(input [31:0] ALU_DA,
input [4:0] ALU_SHIFT,
input [1:0] Shiftctr,
output reg [31:0] shift_result);
`ifdef BEHAVOR
wire [5:0] shift_n;
assign shift_n = 6'd32 - Shiftctr;
always@(*) begin
case(Shiftctr)
2'b00:shift_result = ALU_DA << ALU_SHIFT;
2'b01:shift_result = ALU_DA >> ALU_SHIFT;
2'b10:shift_result = ({32{ALU_DA[31]}} << shift_n) | (ALU_DA >> ALU_SHIFT);
default:shift_result = ALU_DA;
endcase
end
`else
reg[31:0] SLL_M,SRL_M,SRA_M;
always@(*)//SRL
begin
case(ALU_SHIFT)
5'b00000:SRL_M[31:0]=ALU_DA[31:0];
5'b00001:SRL_M[31:0]={1'd0 ,ALU_DA[31:1]};
5'b00010:SRL_M[31:0]={2'd0 ,ALU_DA[31:2]};
5'b00011:SRL_M[31:0]={3'd0 ,ALU_DA[31:3]};
5'b00100:SRL_M[31:0]={4'd0 ,ALU_DA[31:4]};
5'b00101:SRL_M[31:0]={5'd0 ,ALU_DA[31:5]};
5'b00110:SRL_M[31:0]={6'd0 ,ALU_DA[31:6]};
5'b00111:SRL_M[31:0]={7'd0 ,ALU_DA[31:7]};
5'b01000:SRL_M[31:0]={8'd0 ,ALU_DA[31:8]};
5'b01001:SRL_M[31:0]={9'd0 ,ALU_DA[31:9]};
5'b01010:SRL_M[31:0]={10'd0,ALU_DA[31:10]};
5'b01011:SRL_M[31:0]={11'd0,ALU_DA[31:11]};
5'b01100:SRL_M[31:0]={12'd0,ALU_DA[31:12]};
5'b01101:SRL_M[31:0]={13'd0,ALU_DA[31:13]};
5'b01110:SRL_M[31:0]={14'd0,ALU_DA[31:14]};
5'b01111:SRL_M[31:0]={15'd0,ALU_DA[31:15]};
5'b10000:SRL_M[31:0]={16'd0,ALU_DA[31:16]};
5'b10001:SRL_M[31:0]={17'd0,ALU_DA[31:17]};
5'b10010:SRL_M[31:0]={18'd0,ALU_DA[31:18]};
5'b10011:SRL_M[31:0]={19'd0,ALU_DA[31:19]};
5'b10100:SRL_M[31:0]={20'd0,ALU_DA[31:20]};
5'b10101:SRL_M[31:0]={21'd0,ALU_DA[31:21]};
5'b10110:SRL_M[31:0]={22'd0,ALU_DA[31:22]};
5'b10111:SRL_M[31:0]={23'd0,ALU_DA[31:23]};
5'b11000:SRL_M[31:0]={24'd0,ALU_DA[31:24]};
5'b11001:SRL_M[31:0]={25'd0,ALU_DA[31:25]};
5'b11010:SRL_M[31:0]={26'd0,ALU_DA[31:26]};
5'b11011:SRL_M[31:0]={27'd0,ALU_DA[31:27]};
5'b11100:SRL_M[31:0]={28'd0,ALU_DA[31:28]};
5'b11101:SRL_M[31:0]={29'd0,ALU_DA[31:29]};
5'b11110:SRL_M[31:0]={30'd0,ALU_DA[31:30]};
5'b11111:SRL_M[31:0]={31'd0,ALU_DA[31]};
default: SRL_M[31:0]=ALU_DA[31:0];
endcase
end
always@(*) //SLL
begin
case(ALU_SHIFT)
5'b00000:SLL_M[31:0]=ALU_DA[31:0];
5'b00001:SLL_M[31:0]={ALU_DA[30:0],1'd0};
5'b00010:SLL_M[31:0]={ALU_DA[29:0],2'd0};
5'b00011:SLL_M[31:0]={ALU_DA[28:0],3'd0};
5'b00100:SLL_M[31:0]={ALU_DA[27:0],4'd0};
5'b00101:SLL_M[31:0]={ALU_DA[26:0],5'd0};
5'b00110:SLL_M[31:0]={ALU_DA[25:0],6'd0};
5'b00111:SLL_M[31:0]={ALU_DA[24:0],7'd0};
5'b01000:SLL_M[31:0]={ALU_DA[23:0],8'd0};
5'b01001:SLL_M[31:0]={ALU_DA[22:0],9'd0};
5'b01010:SLL_M[31:0]={ALU_DA[21:0],10'd0};
5'b01011:SLL_M[31:0]={ALU_DA[20:0],11'd0};
5'b01100:SLL_M[31:0]={ALU_DA[19:0],12'd0};
5'b01101:SLL_M[31:0]={ALU_DA[18:0],13'd0};
5'b01110:SLL_M[31:0]={ALU_DA[17:0],14'd0};
5'b01111:SLL_M[31:0]={ALU_DA[16:0],15'd0};
5'b10000:SLL_M[31:0]={ALU_DA[15:0],16'd0};
5'b10001:SLL_M[31:0]={ALU_DA[14:0],17'd0};
5'b10010:SLL_M[31:0]={ALU_DA[13:0],18'd0};
5'b10011:SLL_M[31:0]={ALU_DA[12:0],19'd0};
5'b10100:SLL_M[31:0]={ALU_DA[11:0],20'd0};
5'b10101:SLL_M[31:0]={ALU_DA[10:0],21'd0};
5'b10110:SLL_M[31:0]={ALU_DA[9:0] ,22'd0};
5'b10111:SLL_M[31:0]={ALU_DA[8:0] ,23'd0};
5'b11000:SLL_M[31:0]={ALU_DA[7:0] ,24'd0};
5'b11001:SLL_M[31:0]={ALU_DA[6:0] ,25'd0};
5'b11010:SLL_M[31:0]={ALU_DA[5:0] ,26'd0};
5'b11011:SLL_M[31:0]={ALU_DA[4:0] ,27'd0};
5'b11100:SLL_M[31:0]={ALU_DA[3:0] ,28'd0};
5'b11101:SLL_M[31:0]={ALU_DA[2:0] ,29'd0};
5'b11110:SLL_M[31:0]={ALU_DA[1:0] ,30'd0};
5'b11111:SLL_M[31:0]={ALU_DA[0],31'd0};
default: SLL_M[31:0]=ALU_DA[31:0];
endcase
end
always@(*) //SRA
begin
case(ALU_SHIFT)
5'b00000:SRA_M[31:0]=ALU_DA[31:0];
5'b00001:SRA_M[31:0]={{1{ALU_DA[31]}},ALU_DA[31:1]};
5'b00010:SRA_M[31:0]={{2{ALU_DA[31]}},ALU_DA[31:2]};
5'b00011:SRA_M[31:0]={{3{ALU_DA[31]}},ALU_DA[31:3]};
5'b00100:SRA_M[31:0]={{4{ALU_DA[31]}},ALU_DA[31:4]};
5'b00101:SRA_M[31:0]={{5{ALU_DA[31]}},ALU_DA[31:5]};
5'b00110:SRA_M[31:0]={{6{ALU_DA[31]}},ALU_DA[31:6]};
5'b00111:SRA_M[31:0]={{7{ALU_DA[31]}},ALU_DA[31:7]};
5'b01000:SRA_M[31:0]={{8{ALU_DA[31]}},ALU_DA[31:8]};
5'b01001:SRA_M[31:0]={{9{ALU_DA[31]}},ALU_DA[31:9]};
5'b01010:SRA_M[31:0]={{10{ALU_DA[31]}},ALU_DA[31:10]};
5'b01011:SRA_M[31:0]={{11{ALU_DA[31]}},ALU_DA[31:11]};
5'b01100:SRA_M[31:0]={{12{ALU_DA[31]}},ALU_DA[31:12]};
5'b01101:SRA_M[31:0]={{13{ALU_DA[31]}},ALU_DA[31:13]};
5'b01110:SRA_M[31:0]={{14{ALU_DA[31]}},ALU_DA[31:14]};
5'b01111:SRA_M[31:0]={{15{ALU_DA[31]}},ALU_DA[31:15]};
5'b10000:SRA_M[31:0]={{16{ALU_DA[31]}},ALU_DA[31:16]};
5'b10001:SRA_M[31:0]={{17{ALU_DA[31]}},ALU_DA[31:17]};
5'b10010:SRA_M[31:0]={{18{ALU_DA[31]}},ALU_DA[31:18]};
5'b10011:SRA_M[31:0]={{19{ALU_DA[31]}},ALU_DA[31:19]};
5'b10100:SRA_M[31:0]={{20{ALU_DA[31]}},ALU_DA[31:20]};
5'b10101:SRA_M[31:0]={{21{ALU_DA[31]}},ALU_DA[31:21]};
5'b10110:SRA_M[31:0]={{22{ALU_DA[31]}},ALU_DA[31:22]};
5'b10111:SRA_M[31:0]={{23{ALU_DA[31]}},ALU_DA[31:23]};
5'b11000:SRA_M[31:0]={{24{ALU_DA[31]}},ALU_DA[31:24]};
5'b11001:SRA_M[31:0]={{25{ALU_DA[31]}},ALU_DA[31:25]};
5'b11010:SRA_M[31:0]={{26{ALU_DA[31]}},ALU_DA[31:26]};
5'b11011:SRA_M[31:0]={{27{ALU_DA[31]}},ALU_DA[31:27]};
5'b11100:SRA_M[31:0]={{28{ALU_DA[31]}},ALU_DA[31:28]};
5'b11101:SRA_M[31:0]={{29{ALU_DA[31]}},ALU_DA[31:29]};
5'b11110:SRA_M[31:0]={{30{ALU_DA[31]}},ALU_DA[31:30]};
5'b11111:SRA_M[31:0]={{31{ALU_DA[31]}},ALU_DA[31]};
default: SRA_M[31:0]=ALU_DA[31:0];
endcase
end
always@(*) //SHIFT
begin
case(Shiftctr)
2'b00:shift_result=SLL_M;
2'b01:shift_result=SRL_M;
2'b10:shift_result=SRA_M;
default: shift_result=ALU_DA;
endcase
end
`endif
endmodule
//*************************************************************
//***********************************adder*********************
//`define ALGORITHM
module Adder(input [31:0] A,
input [31:0] B,
input Cin,
input [3:0] ALU_CTL,
output ADD_carry,
output ADD_OverFlow,
output ADD_zero,
output [31:0] ADD_result);
`ifdef ALGORITHM
assign {ADD_carry,ADD_result}=A+B+Cin;
`else
cla_adder32 cla_adder32_inst1(.A(A),
.B(B),
.cin(Cin),
.cout(ADD_carry),
.result(ADD_result));
`endif
assign ADD_zero = ~(|ADD_result);
assign ADD_OverFlow=((ALU_CTL==4'b0001) & ~A[31] & ~B[31] & ADD_result[31])
| ((ALU_CTL==4'b0001) & A[31] & B[31] & ~ADD_result[31])
| ((ALU_CTL==4'b0011) & A[31] & ~B[31] & ~ADD_result[31])
| ((ALU_CTL==4'b0011) & ~A[31] & B[31] & ADD_result[31]);
endmodule
//************************************************************************************
//***************************************cla_adder************************************
4位CLA部件
module cla_4(p,g,c_in,c,gx,px);
input[3:0] p,g;
input c_in;
output[4:1] c;
output gx,px;
assign c[1] = p[0]&c_in | g[0];
assign c[2] = p[1]&p[0]&c_in | p[1]&g[0] | g[1];
assign c[3] = p[2]&p[1]&p[0]&c_in | p[2]&p[1]&g[0] | p[2]&g[1] | g[2];
assign c[4] = gx | px&c_in;
assign px = p[3]&p[2]&p[1]&p[0];
assign gx = g[3] | p[3]&g[2] | p[3]&p[2]&g[1] | p[3]&p[2]&p[1]&g[0];
endmodule
//32位全加器
module cla_adder32(A,B,cin,result,cout);
input [31:0] A;
input [31:0] B;
input cin;
output[31:0] result;
output cout;
进位产生信号,进位传递信号
wire[31:0] TAG,TAP;
wire[32:1] TAC;
wire[15:0] TAG_0,TAP_0;
wire[3:0] TAG_1,TAP_1;
wire[8:1] TAC_1;
wire[4:1] TAC_2;
assign result = A ^ B ^ {TAC[31:1],cin};
assign TAG = A&B;
assign TAP = A|B;
cla_4 cla_0_0( .p(TAP[3:0]), .g(TAG[3:0]), .c_in(cin), .c(TAC[4:1]), .gx(TAG_0[0]),.px(TAP_0[0]));
cla_4 cla_0_1( .p(TAP[7:4]), .g(TAG[7:4]), .c_in(TAC_1[1]),.c(TAC[8:5]), .gx(TAG_0[1]),.px(TAP_0[1]));
cla_4 cla_0_2( .p(TAP[11:8]), .g(TAG[11:8]), .c_in(TAC_1[2]),.c(TAC[12:9]), .gx(TAG_0[2]),.px(TAP_0[2]));
cla_4 cla_0_3( .p(TAP[15:12]),.g(TAG[15:12]),.c_in(TAC_1[3]),.c(TAC[16:13]),.gx(TAG_0[3]),.px(TAP_0[3]));
cla_4 cla_0_4( .p(TAP[19:16]),.g(TAG[19:16]),.c_in(TAC_1[4]),.c(TAC[20:17]),.gx(TAG_0[4]),.px(TAP_0[4]));
cla_4 cla_0_5( .p(TAP[23:20]),.g(TAG[23:20]),.c_in(TAC_1[5]),.c(TAC[24:21]),.gx(TAG_0[5]),.px(TAP_0[5]));
cla_4 cla_0_6( .p(TAP[27:24]),.g(TAG[27:24]),.c_in(TAC_1[6]),.c(TAC[28:25]),.gx(TAG_0[6]),.px(TAP_0[6]));
cla_4 cla_0_7( .p(TAP[31:28]),.g(TAG[31:28]),.c_in(TAC_1[7]),.c(TAC[32:29]),.gx(TAG_0[7]),.px(TAP_0[7]));
cla_4 cla_1_0(.p(TAP_0[3:0]), .g(TAG_0[3:0]), .c_in(cin),.c(TAC_1[4:1]), .gx(TAG_1[0]),.px(TAP_1[0]));
cla_4 cla_1_1(.p(TAP_0[7:4]), .g(TAG_0[7:4]), .c_in(TAC_1[4]),.c(TAC_1[8:5]), .gx(TAG_1[1]),.px(TAP_1[1]));
assign TAG_1[3:2] = 2'b00;
assign TAP_1[3:2] = 2'b00;
cla_4 cla_2_0(.p(TAP_1[3:0]), .g(TAG_1[3:0]), .c_in(1'b0), .c(TAC_2[4:1]), .gx(),.px());
assign cout = TAC_2[2];
endmodule
此处对改进后的CPU进行测试。
测试用例是上一篇文章中的跳转指令,移位运算指令和算数运算指令。
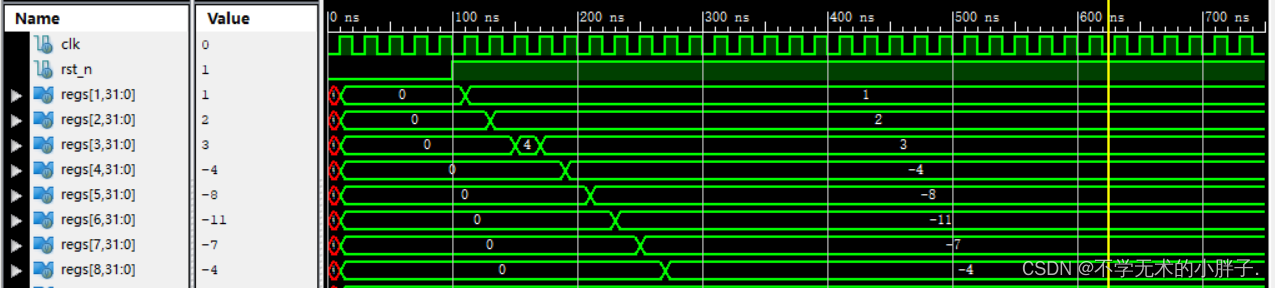
算数运算指令如下:
addi x1,x0,1
add x2,x1,x1
add x3,x2,x2
sub x3,x3,x1
addi x4,x0,-4
add x5,x4,x4
sub x6,x5,x3
sub x7,x6,x4
add x8,x7,x3
汇编器执行结果如下:
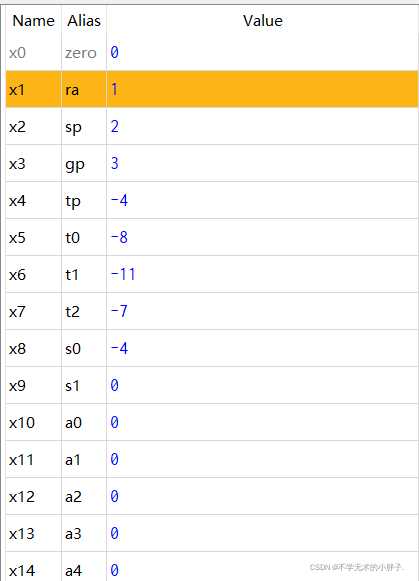
CPU执行结果如下:
移位运算指令如下:
addi x1,x0,0xff
addi x2,x0,4
sll x3,x1,x2
srl x4,x1,x2
sra x5,x1,x2
addi x6,x0,-0xff
sll x7,x6,x2
srl x8,x6,x2
sra x9,x6,x2
slli x11,x1,4
srli x12,x1,4
srai x13,x1,4
slli x11,x6,4
srli x12,x6,4
srai x13,x6,4
汇编器执行结果如下:
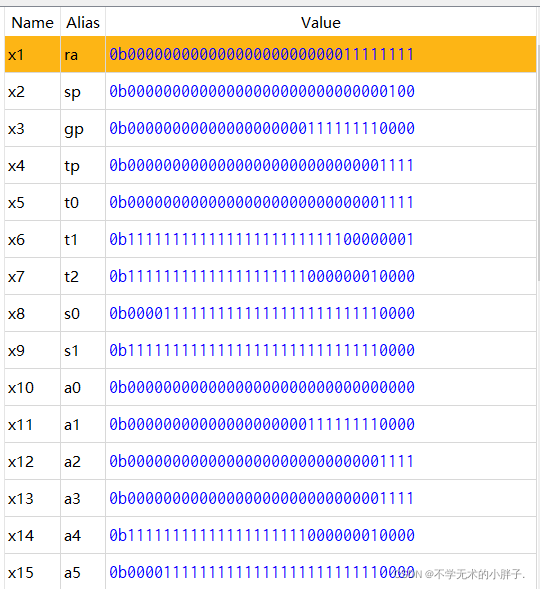

CPU执行结果如下:
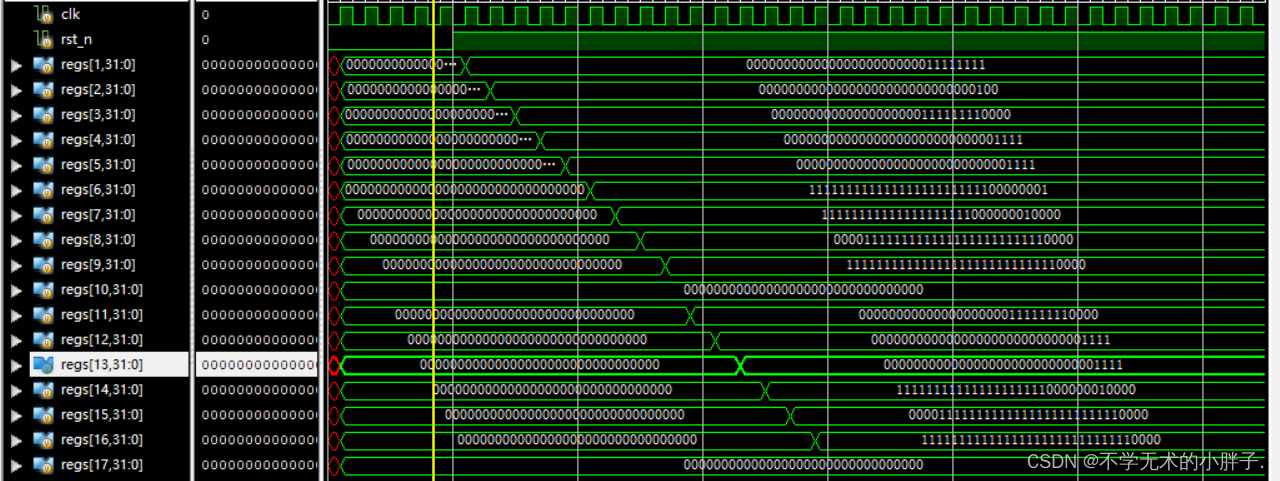
跳转指令如下:
addi x1,x0,1
addi x2,x0,2
jal x31,label1
addi x3,x0,3
label1:
addi x4,x0,4
add x5,x2,x2
beq x4,x5,label2
addi x6,x0,6
label2:
bne x4,x5,label3
addi x7,x0,7
label3:
bne x7,x6,label4
addi x8,x0,8
label4:
addi x9,x0,0x30
jalr x10,x9,12
addi x11,x0,11
addi x12,x0,-12
addi x13,x0,-13
blt x13,x12,label5
addi x14,x0,-14
label5:
bltu x13,x12,label6
addi x15,x0,-15
label6:
bltu x12,x13,label7
addi x16,x0,-16
label7:
bge x12,x13,label8
addi x17,x0,-17
label8:
bge x1,x2,label9
addi x18,x0,-18
label9:
bgeu x12,x13,label10
addi x19,x0,-19
label10:
bgeu x13,x12,label11
addi x20,x0,-20
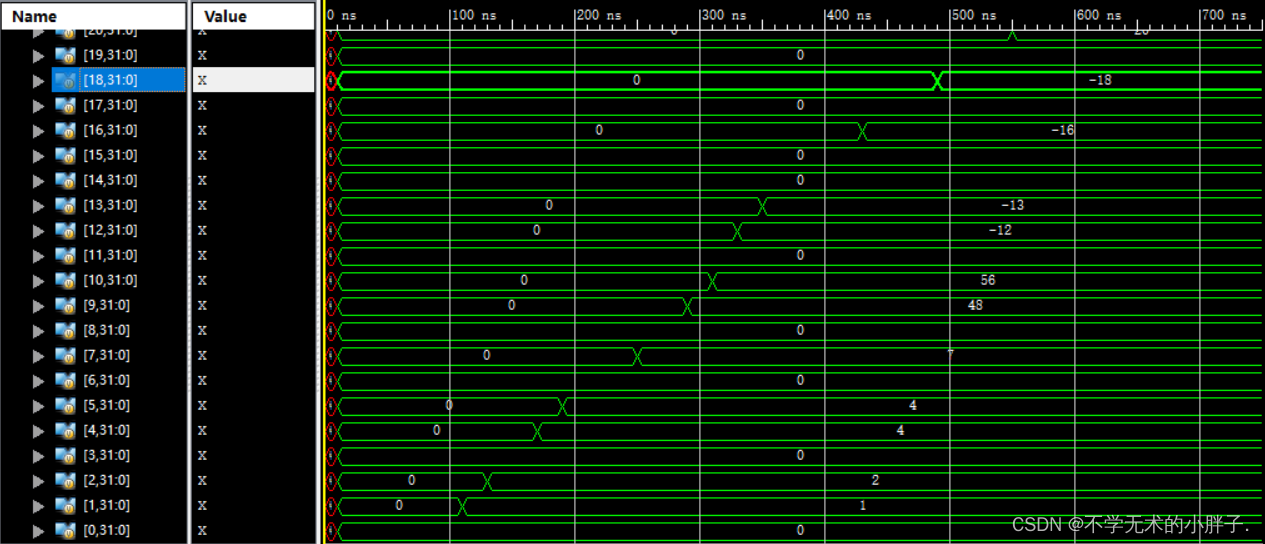
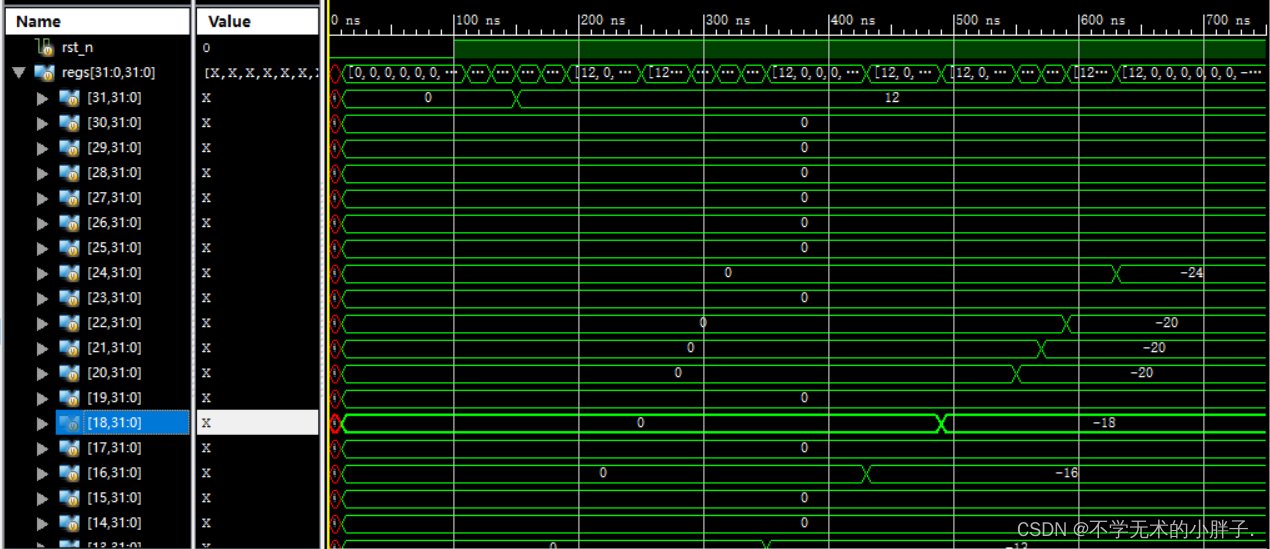
label11:
addi x21,x0,-20
addi x22,x0,-20
bge x21,x22,label12
addi x23,x0,-23
label12:
addi x24,x0,-24
汇编器执行结果如下:
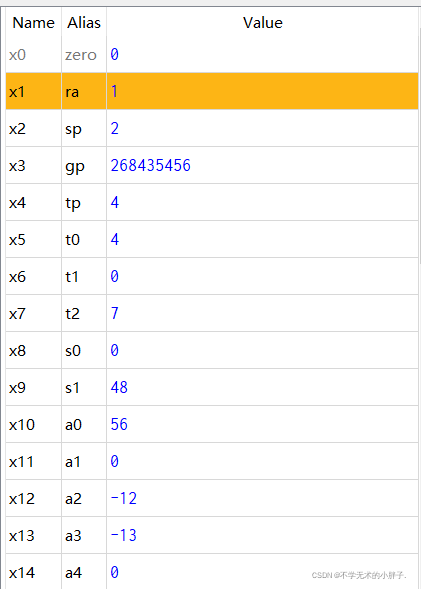
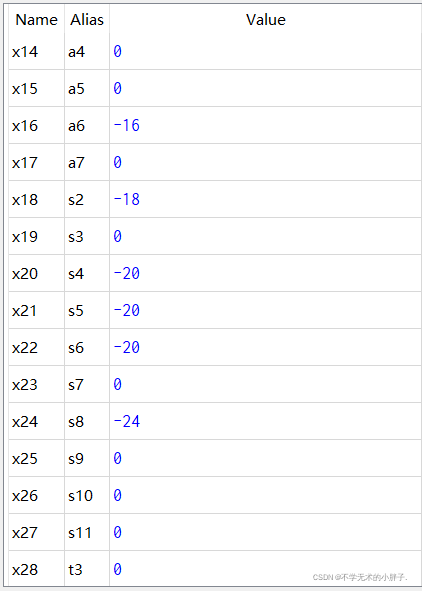
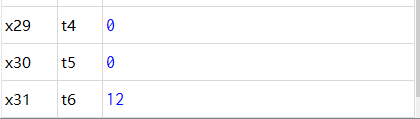
CPU执行结果如下:
总结
以上就是今天要介绍的内容,对ALU的加法器和移位两个运算部件进行了详细的设计。下一篇文章开始进行流水线处理器的设计。最后
以上就是大气小鸭子最近收集整理的关于从零开始设计RISC-V处理器——ALU的优化系列文章目录前言一、加法器的设计二、移位器的设计三、仿真测试总结的全部内容,更多相关从零开始设计RISC-V处理器——ALU内容请搜索靠谱客的其他文章。

![[Verilog]Verilog经典电路设计(二)Verilog经典电路设计(二)](https://www.shuijiaxian.com/files_image/reation/bcimg4.png)




![Verilog复杂时序逻辑电路设计实践[例1] 一个简单的状态机设计--序列检测器[例2]EEPROM读写器件的设计](https://www.shuijiaxian.com/files_image/reation/bcimg9.png)

发表评论 取消回复