这是一篇2019年发表在IEEE上的文章。
作者:jiangtianming
华中科技大学
Email:jiangtianming@hust.edu.cn
注:本篇论文已上传到资源Lifelong Disk Failure Prediction via GAN-based Anomaly Detection,需要的童鞋可免费下载。
数据集:BACKBLAZE
前面发的两篇论文分析访问量比较低,这一篇我希望用自己的语言来把文章的思想说清楚,层层递进,包括BASIC代码部分的理解。请君仔细阅读(读不懂来打我!)。
目录
- 0、论文方法
- 一、时序特征
- 二、数据预处理
- 1、选取特征
- 2、二维特征
- 3、正则化
- 三、模型
- 1、模型老化问题
- 2、样本标记
- 3、算法解析
- 四、实验部分
- 1、数据集
- 2、检测指标
- 3、对比实验
- 1)数据不平衡问题
- 2)模型老化问题
- 3)性能表现
- 4、2DSMART特征的有效性
- 5、模型更新的有效性
- 五、总结
- 1、论文创新点
- 2、一点愚见
- 3、整理思路
- 4、半监督学习的理解
0、论文方法

以上的方法其实也说明白了异常检测的思路。首先进行数据预处理,将SMART数据映射到类似图像的二维数据中,然后输如到SPA模型中,最后输出每个磁盘的预测结果。

一、时序特征
最终的目的是为了检测磁盘的异常,所以我们首先说一下检测异常的核心要素——SMART属性时序特征。
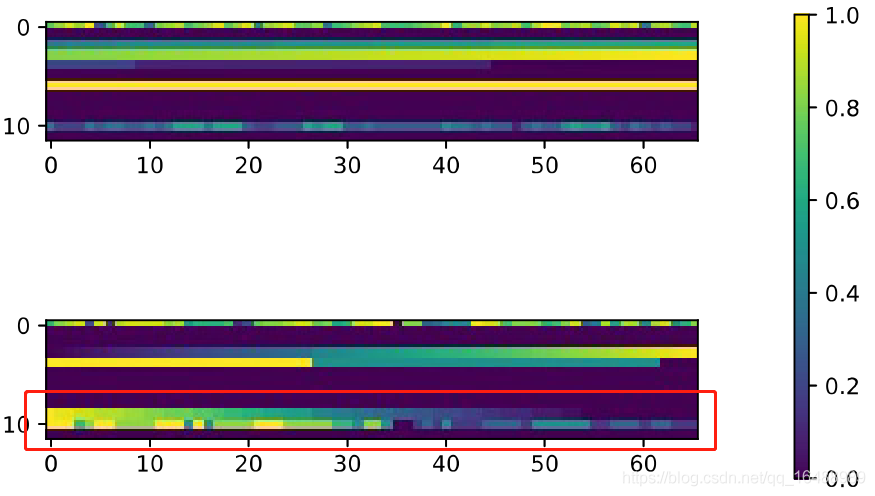
可以看到上面那个 以中间黄线分隔开的 上半部分是健康磁盘,下班部分是故障磁盘。横坐标代表天数,纵坐标代表特征,健康磁盘和故障磁盘具有不同的特征。特征是以特征值来表现的,而特征值是全局平均值和标准差。
随着时间的变化,故障磁盘的特征波动变化更大。这直接说明了时序特征的重要性,它可以用于区分健康磁盘和故障磁盘。
二、数据预处理
1、选取特征
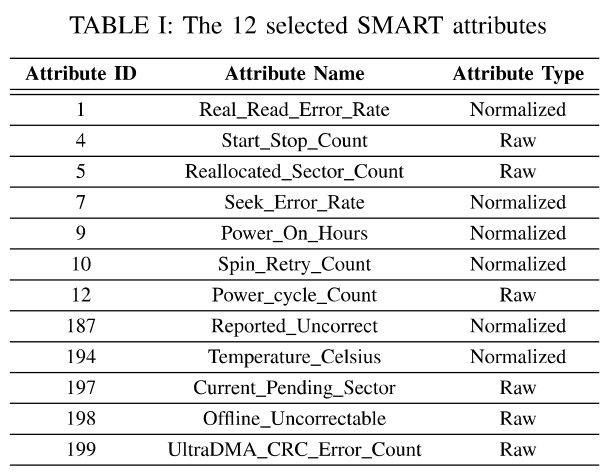
本文通过RF(随机森林)方法选取了12个特征。
2、二维特征
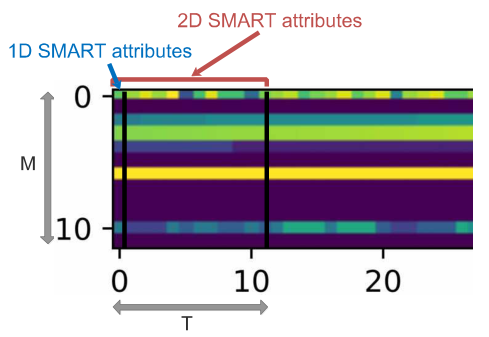
紧接着,如果要用到深度学习,必须解决的问题就是把一维的SMART数据变成类似图像的二维数据。1D的SMART特征值也就是对应某个时间点的。对于同样大小的SMART特征,以一个时间窗口T来得到2D的SMART特征。
3、正则化
因为不同特征的大小区间不同,所以采取正则化的方法统一到一个空间内。
三、模型
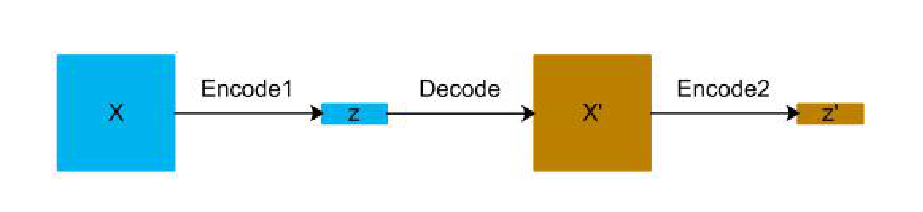
模型采用编码—解码—编码的方式来检测异常。编码器和解码器由GAN组成。
GAN模型由生成器和判别器组成。生成器努力生成类似于真实的数据。判别器对生成器生成的数据进行判别。两者相互对抗。优化采用SGD(随机梯度下降)算法。
z获得输入数据的特征表示。然后解码获得数据的重构。在通过一个编码器获得重构的特征表示z‘。以z’与z之间的差距与设定阈值的大小比较来检测异常。
1、模型老化问题
特征是随时间而变的,所以不得不面临模型老化问题。采用常用的fine-tuning(微调)的方法同时利用老数据和新数据。
2、样本标记
数据随时间而更新,所以样本的标记还需要一定的策略——自动在线标记方法。
具体来说,采用一个定长的先进先出的队列Q存储磁盘Di的样本。一旦磁盘Di故障,队列中所有的样本都标记为正类(故障)。如果磁盘Di仍在正常工作,以新样本替换老样本,并标记老样本为负类(正常)。
3、算法解析
通过这个样本标记,我们顺便来理解一下下面这段BASIC代码。
模型输入为1D的SMART特征——x箭头,当前磁盘的状态——y,1D的SMART特征数据集——S,2D的SMART特征集——S’
模型输出为预测的结果——y’
另:x箭头’代表的是出队后带标记的老样本,X代表队列转换的2D特征
——如果磁盘判为异常,那么删除整个磁盘的数据,认定这些数据为正类(异常数据)
——否则,磁盘处于工作状态,当存储磁盘Di样本的队列满时,将老样本出队将其放入数据集S中。
——若队列未满,则样本依次入队。
——当数据集S满时,将其转化到2D类似图像的特征S’中
——然后使用S’来微调老的GAN模型
——同时将数据集S置空,来重新存储1D的注释样本
——在预测阶段,将队列中的数据转换到2D类似图像的特征X中
——然后将X输入模型得到预测结果y’
——如果y’是1的话说明磁盘很快就很发生故障,发出警告。

四、实验部分
通过实验来检验这个方法是否可行。
1、数据集
数据取自2017年1月至12月BACKBLAZE的真实数据(很常用)
取用最多和最少的两种代表性的磁盘。这里的故障(failed)磁盘代表17年被换掉的磁盘。数据是真实可靠的。

2、检测指标
通过故障检测率(FDR)(正确预测为故障的磁盘占总的故障磁盘的比例)和故障误报率(FAR)(错误预报的健康磁盘占总的健康磁盘的比例)两个非常常用的指标来评估异常检测的性能。
具体怎么样来判断磁盘故障还是异常呢?
——一个磁盘的任何样本预测为异常,则整个磁盘异常。具体来说,以上一周内收集的任何样本被预测为正类为磁盘正确预测为异常的标准,以最近一周之外收集的任何样本被预测为正类为健康磁盘被错误预测为故障的标准。
每次模型更新都计算一次FDR和FAR。
3、对比实验
随机划分数据集S为7(训练集):3(测试集)
对比三种常用的方法——随机森林RF(random forests)、支持向量机SVM(support vector machines)、反向神经网络BP(background propagation neural networks)。
1)数据不平衡问题
省略三种方法的实验配置,我们直接看下SPA的实践方式。
实验将z的大小设置为100.参考以往的研究方法采用下采样的方法来解决数据不平衡的问题,调整异常样本与健康样本的比例为1:5(性能较好),不同的是,这里是只用了健康样本。
2)模型老化问题
收集最近一个月的数据来微调模型,并且每个月在同等的测试集上测试预测性能。
3)性能表现
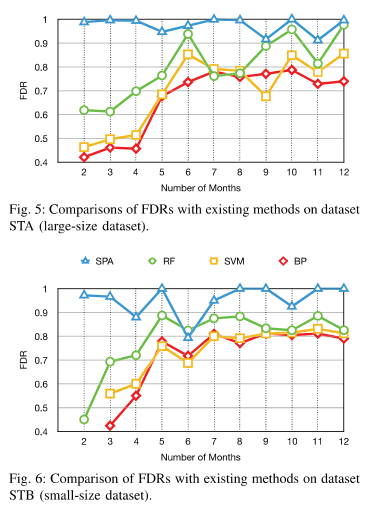
下图是在STA和STB上的表现情况相类似。
因为训练样本只采用健康样本,可以看到三种监督学习方法初始的效果就不太好,而SPA初始脱颖而出。而后续变现SPA依然非常出色,这是因为与监督学习相反,异常检测能够检测从未发生的情况。
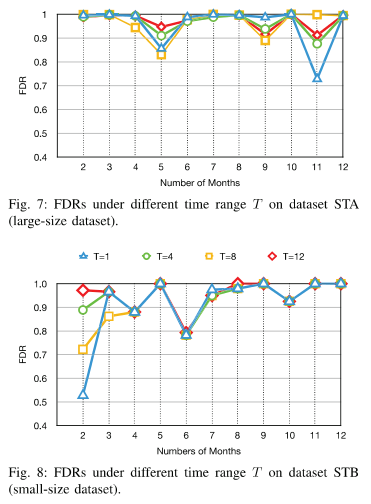
4、2DSMART特征的有效性
用不同的时间范围作为输入GAN的数据,T=1也就是单纯的1D,最后发现T=12的时候表现是最好的,故采用T=12。T在这里是天数的意思。
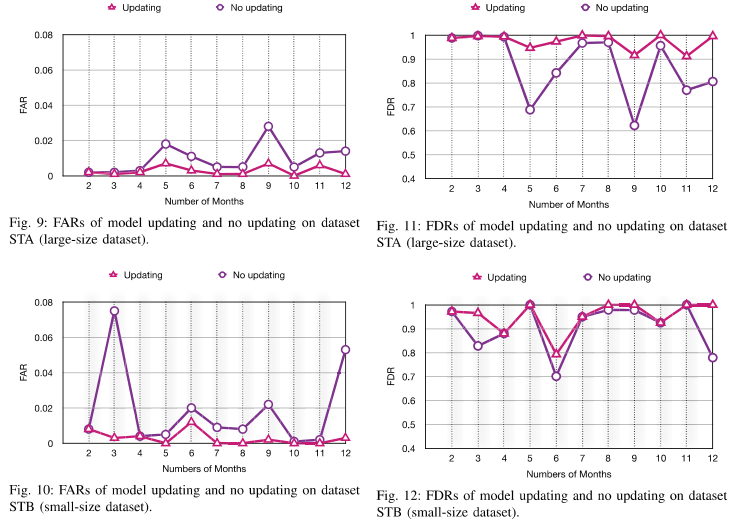
5、模型更新的有效性
在两种模型上有着相似现象。可以看到随着时间的推迟,更新的模型能够获得更高的故障检测率和更低的误报率。
五、总结
1、论文创新点
论文首先通过将磁盘的异常预测问题转化为磁盘的故障检测问题,解决了数据不平衡所带来的的冷开始问题(cold starting problem)。使用CNN优化了特征的提取。微调模型解决了模型的老化问题。
2、一点愚见
我认为这个自动在线标记算法挺好的,可以对新老数据进行更新换代。
GAN模型和编码器解码器也是当前最火的模型了。特征提取用了CNN。可以说是最大化的利用了当前的模型。
模型更新也是比较好的(采用数据集也就是更新换代的新老数据来微调模型参数)。另外还采用固定的测试数据集对更新的模型进行性能测试。实验的设置比较全面(需要学习!)。
本文是通过检测异常,使用比较常见的重构误差来判异常,当前也有根据预测来判断异常的方法(后续复习到那篇论文补充进来)
自己的理解还比较浅显啊,看完文章就觉得它哪哪都好(还是看的太少了!!)
欢迎交流~
3、整理思路
一个月的健康数据自动按照在线标记的方法转换为2D类图像数据,然后输入到GAN模型中,通过GAN形成的编码和解码器获得样本的重构(生成健康数据与判别健康数据互相对抗,尽可能的获得类似于健康数据的重构),再对重构进行编码。让其与初始样本的编码结果作差,以一周数据为基准,来判断异常(因为样本数据具有时序特征,异常样本的波动更大)。
4、半监督学习的理解
另外,一般半监督学习问题指的是利用少量标注样本和大量未标注样本进行机器学习,这里的半监督学习我认为指的是利用已有标记也就是健康磁盘进行训练,检测出异常的,同时还有一个测试集来测试性能的,测试集里应该是有部分异常样本的。
不会真有人想来打我吧?那么,请先关注我~:)
博主研究方向为时间序列的异常检测,欢迎交流。最近正在做磁盘时间序列的异常检测。正在复现一篇TrAdaBoost华中科技大的论文(采用BackBlaze磁盘数据)。知识浅薄,欢迎指正交流~
最后
以上就是义气月饼最近收集整理的关于Lifelong Disk Failure Prediction via GAN-based Anomaly Detection0、论文方法一、时序特征二、数据预处理三、模型四、实验部分五、总结的全部内容,更多相关Lifelong内容请搜索靠谱客的其他文章。








发表评论 取消回复