map/reduce思想是Google的JeffDean在2008年在论文《MapReduce Simplified Data Processing on Large Clusters》中提出的,而python中沿用了这种思想并内置了map()和reduce()函数。
首先来讲讲python中这两个函数怎么使用:
1. map
map()方法会将 一个函数映射到序列的每一个元素上,生成新序列,包含所有函数返回值。
也就是说假设一个序列[x1, x2, x3, x4, x5 ...],序列里每一个元素都被当做x变量,放到一个函数f(x)里,其结果是f(x1)、f(x2)、f(x3)......组成的新序列[f(x1), f(x2), f(x3) ...]。下面这张图可以直观地说明map()函数的工作原理:
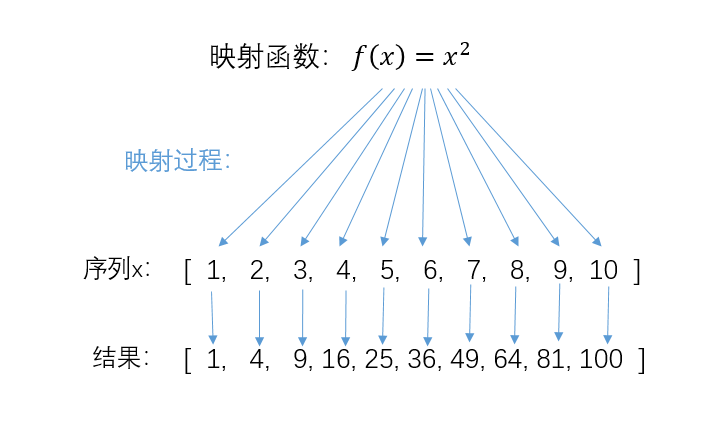
如何使用map函数?
map(function, list)
- function:代表函数
- list:代表输入序列
我们可以用python代码来实现:
>>> def f(x): ... return x * x ... >>> map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
map()传入的第一个参数是f,即函数对象本身,传入的第二个参数就是list。你可能会想,不需要map()函数,写一个循环,也可以计算出结果:
L = [] for n in [1, 2, 3, 4, 5, 6, 7, 8, 9]: L.append(f(n)) print L
的确可以,但是,从上面的循环代码,能一眼看明白“把f(x)作用在list的每一个元素并把结果生成一个新的list”吗?显然是不可以的。所以,map()作为高阶函数,事实上它把运算规则抽象了,因此,我们不但可以计算简单的f(x)=x^2,还可以计算任意复杂的函数,比如,把这个list所有数字转为字符串,只需要一行代码。:
>>> map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
['1', '2', '3', '4', '5', '6', '7', '8', '9', '10']
2.reduce
reduce相比map稍复杂点
reduce的工作过程是 :在迭代序列的过程中,首先把 前两个元素(只能两个)传给 函数,函数加工后,然后把 得到的结果和第三个元素 作为两个参数传给函数参数, 函数加工后得到的结果又和第四个元素 作为两个参数传给函数参数,依次类推。也就是说,reduce把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,其效果就是:
reduce(f, [x1, x2, x3]) = f(f(x1, x2), x3)
通过图像直观地理解:
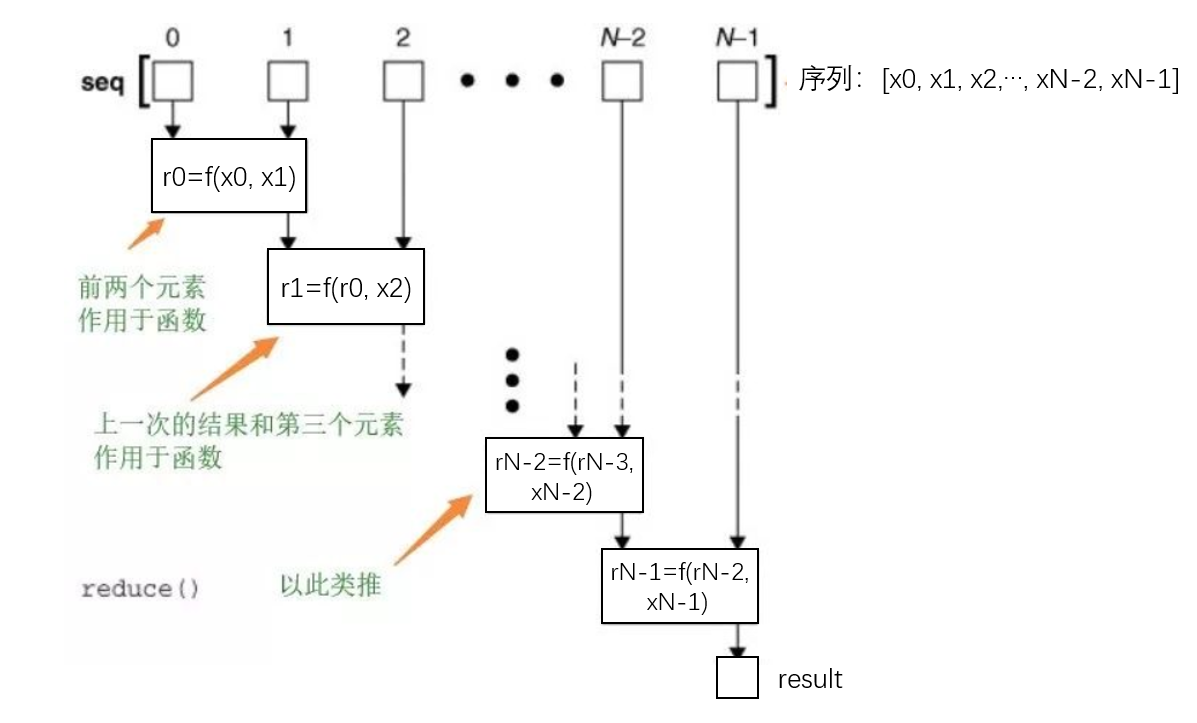
reduce函数怎么用?
reduce(function, list[, initializer])
- function:代表函数
- list:序列
- initializer:初始值(可选)
比方说对一个序列求和,就可以用reduce()实现,这里需要注意,python中使用reduce函数时,需要加上from functools import reduce这一句:
>>> from functools import reduce >>> def add(x, y): ... return x + y ... >>> reduce(add, [1, 2, 3, 4, 5]) 15
最后让我们看看原文中的map/reduce工作原理:
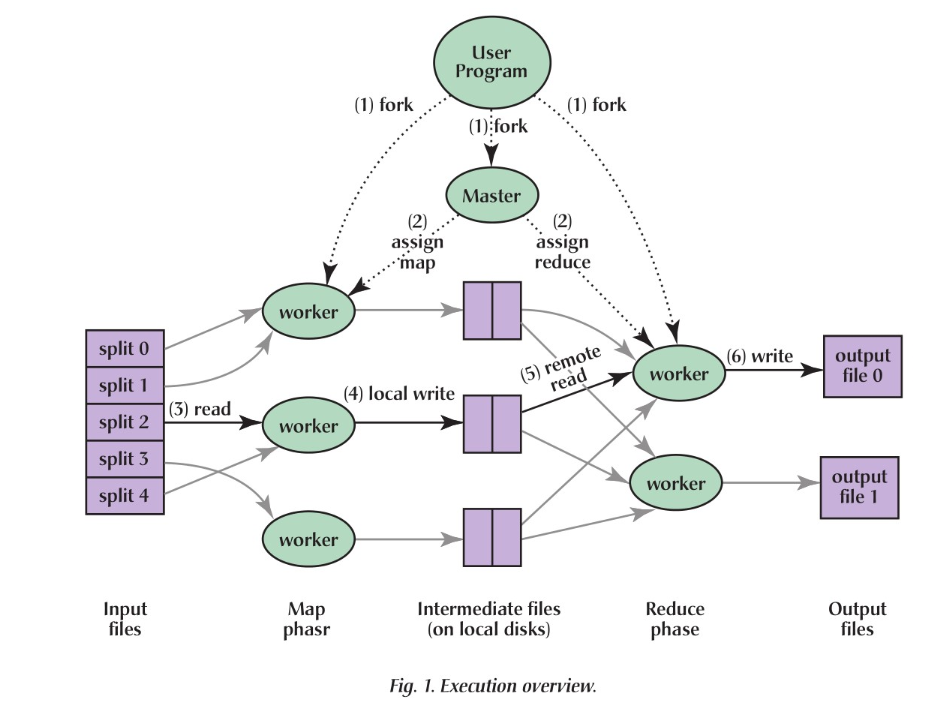
在原文中是这样描述的:
上图1展示了在我们的实现中MapReduce全部的流程。当用户程序调用MapReduce函数时,接下来的动作将按序发生(图1中标记的数字与下面的数字是一一对应的):
(1)用户程序中的MapReduce库首先将输入文件划分为M片,每片大小一般在16M到64M之间(由用户通过一个可选的参数指定)。之后,它在集群的很多台机器上都启动了相同的程序拷贝。
(2)其中有一个拷贝程序是特别的----master(主模块)。剩下的都是worker(分模块),它们接收master分配的任务。其中有M个Map任务和R个Reduce任务要分配。master挑选一个空闲的worker并且给它分配一个map任务或者reduce任务。
(3)被分配到Map任务的worker会去读取相应的输入块的内容。它从输入文件中解析出键值对并且将每个键值对传送给用户定义的Map函数。而由Map函数产生的中间键值对缓存在内存中。
(4)被缓存的键值对会阶段性地写回本地磁盘,并且被划分函数分割成R份。这些缓存对在磁盘上的位置会被回传给master(主模块),master再负责将这些位置转发给Reduce worker。
(5)当Reduce worker(Reduce分模块)从master(主模块)那里接收到这些位置信息时,它会使用远程过程调用从Map worker的本地磁盘中获取缓存的数据。当Reduce worker读入全部的中间数据之后,它会根据中间键对它们进行排序,这样所有具有相同键的键值对就都聚集在一起了。排序是必须的,因为会有许多不同的键被映射到同一个reduce task中。如果中间数据的数量太大,以至于不能够装入内存的话,还需要另外的排序。
(6)Reduce worker遍历已经排完序的中间数据。每当遇到一个新的中间键,它会将key和相应的中间值传递给用户定义的Reduce函数。Reduce函数的输出会被添加到这个Reduce部分的输出文件中。
(7)当所有的Map tasks和Reduce tasks都已经完成的时候,master(主模块)将唤醒用户程序。到此为止,用户代码中的MapReduce调用返回。
当成功执行完之后,MapReduce的执行结果被存放在R个输出文件中(每个Reduce task对应一个,文件名由用户指定)。通常用户并不需要将R个输出文件归并成一个。因为它们通常将这些文件作为另一个MapReduce调用的输入,或者将它们用于另外一个能够以多个文件作为输入的分布式应用。
原文中也举了这样一个例子:统计大量文档中每一个单词出现的次数。
对此,用户需要编写类似于如下的伪代码:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
虽然在上述的伪代码中输入输出都是字符串类型的,但事实上,用户提供的Map和Reduce函数都是有相应类型的:
map (k1, v1) -> list(k2, v2)
reduce (k2, list(v2)) -> list(v2)
需要注意的是,输入的key和value与输出的key和value是不同的类型,而中间的key和value与输出的key和value是相同的类型。
Map函数为在每一个单词出现的时候,为它加上一个计数(在这个简单的例子中就是加1)。Reduce函数对每个单词的所有计数进行叠加。最后得到文档中出现的每个单词的次数,这样就完成了一次简单的Map/Reduce过程。
以上就是关于Map和Reduce的原理和应用的浅析,希望能对大家的理解有所帮助。
最后
以上就是俏皮鸭子最近收集整理的关于python中的MapReduce函数和过程浅析的全部内容,更多相关python中内容请搜索靠谱客的其他文章。








发表评论 取消回复