一、简介
* 大数据计算问题的提出:如何处理并行计算、如何分发数据、如何处理错误等等。这些问题合起来使得大数据处理变得复杂
* 为了解决这些问题,需要设计新的计算抽象模型:只要表述想要执行的运算,而屏蔽了并行计算、容错、数据分发、负载均衡等复杂细节,这些细节被封装在一个库里
* 抽象模型设计的灵感来自于函数式语言的Map和Reduce原语
- Map:对输入数据应用Map操作得出一个中间<key, value>对集合
- Reduce:对具有相同key的value集合上应用Reduce操作合并中间结果
* MapReduce框架模型:通过简单接口(用户只要实现Map和Reduce函数)实现大规模数据的分布式计算,实现在大量普通机器上的高性能计算
二、编程模型
1、例子
* 计算一个大文档集合中每个单词的出现次数(MapReduce编程的HelloWorld了),伪代码:
map(string key, string value)
for each word w in value
emitIntermediate(w, 1)
reduce(string key, Iterator values)
int result = 0
for each v in values
result += ParseInt(v);
Emit(AsString(result))
* map函数输出文档每个词(key),及这个词的出现次数(value,这里为1)
* reduce函数将每个词的出现次数累加起来输出
2、类型
* 在概念上,Map和Reduce函数有相关联的输入输出类型
map(k1, v1) => list(k2, v2)
reduce(k2, list(v2)) => list(v2)
3、更多的例子
* 分布式grep,分布式排序,计算URL访问频率,转置网络链接图等等
三、实现
* MapReduce模型有多种不同实现方式,取决于具体环境,如小型的共享内存机器、大型NUMA架构多处理器主机、大型网络连接集群等
1、执行概括
* Map阶段概括:输入数据自动分割为M个片段集合,Map调用因此分到多台机器上并行处理。
* Reduce阶段概括:使用分区函数将Map输出的key值分成R个分区(如hash(key) mod R),使得Reduce调用也被分到多台机器并行处理。这里分区数R和分区函数作为一个重要指标,由用户来指定
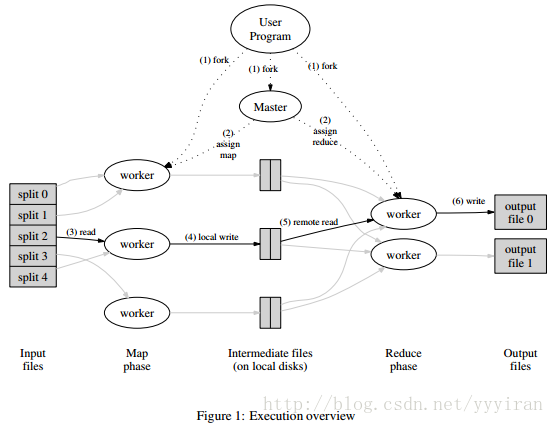
a、用户调用MapReduce库将输入文件分为M个数据片段(即split,一般为16~64MB)
b、用户程序有一个Master(即JobTracker ),其他都为Worker(即TaskTracker),由Master负责任务分配。
c、被分配了Map任务的Map Worker读取数据片段,将其解析出<key, value>对传递给用户map函数处理,最后输出中间<key, value>对到内存
d、缓存的<key, value>对通过分区函数分成R个分区,周期性写入本地磁盘,并将位置信息上传给Master。Master再将这些存储位置传给Reduce Worker
e、Reduce Worker接收到信息后,使用RPC将落地的<key, value>对读取到本地,对Key排序后聚合相同Key值的数据,然后将<key, list<value>>对传递给用户reduce函数处理,最后输出到所属分区的输出文件(故最终的MapReduce输出为R个文件)
2、Master数据结构
* Master数据结构存储信息:每个Map/Reduce任务状态、中间文件存储信息,Worker机器标识等
* Master类似一个数据管道:Map任务产生的R个中间文件存储信息,通过这个管道传递给Reduce任务
3、Worker容灾
* Master周期性Ping每个Worker维持心跳,约定时间内没收到返回信息则将Worker标为失效
* 对于失效的Map Worker:Map任务输出到本机,已不可访问,故需重新执行
* 对于失效的Reduce Worker:Reduce任务输出到全局文件系统,故不许重新执行
* MapReduce可以处理大规模Worker失效的情况,最多只需简单重新执行失效Worker未完成的任务
4、Master容灾
* 一个简单的方法为Master周期性将上面的数据结构落地,即检查点CheckPoint。如果Master挂了可用CheckPoint启动另一Master
* 失效处理机制:保证用户提供输入确定函数时,在任何情况下(各种失效)的输出都和没有出现任何错误,且顺序执行产生的输出是一样的。通过依赖对Map和Reduce任务的输出是原子提交来完成这个特性
5、存储位置
* 网络带宽为相对匮乏的资源,Master调度时,会尽量将Map任务调度在包含相关输入的机器上执行(对于大型集群,大部分输出能实现)
* 对于上述调度失败的情况,Master会选择相关输入附近的机器执行
6、任务粒度
* 任务粒度M和R:我们把Map拆分为M个片段(输入数据split决定),把Reduce拆分为R个片段(分区函数决定)
* 理想状态下,M和R应该比Worker数要多得多,有利于Worker机器执行大量不同小任务而利于集群负载均衡,以及故障恢复
* 实际上,M和R取值收到一些限制,如Master内存容纳的数据结构等
* M和R值为系统2个较关键调优参数,通常的比例为M=200000,R=5000,Worker=2000
7、备用任务
* 一个现象:影响MapReduce总执行时间常常是极少数“落伍任务”,出现“落伍”的原因很多难以避免。
* 备用任务为一种减少“落伍任务”出现几率的机制:当MapReduce总执行接近结束时,多启动一个备用任务来执行剩下的还未完成的任务。
* 添加备用任务机制的效果:多花费几个百分点的计算资源,对于减少超大MapReduce总执行时间效果显著(排序任务:优化44%时间)
四、技巧
1、分区函数
* 分区函数:使用分区函数对Map的输出进行分区,即指定Map任务的输出按key分为R个分区给Reduce任务处理
* 默认的分区函数为 hash(key) mod R,hash能产生非常平衡的分区
2、顺序保证
* 保证中间<key, value>对的处理顺序是按key值增量进行的(先排序),保证每个分区生成有序的输出文件,对于后面一些应用很有帮助
3、Combiner函数
* 由于Map产生的中间<key, value>对中key值重复的比重很大(如词数统计的例子,每个Map会产生很多的<word,1>),所以我们允许用户定义一个可选的Combiner函数,来将Map产生的本地的中间<key, value>对先进行一次合并,再通过RPC传递给Reduce
* 一般情况下,Combiner和Reduce函数是一样的,唯一的区别是MapReduce库控制函数输出不同,Combiner输出为中间文件,Reduce输出为最终结果文件
4、输入输出类型
* MapReduce库支持几种预定义好的输入类型,如文本、Mysql等等。
* 以文本作为输入数据为例,文件的偏移量作为key,每一行的内容作为value,就可将文本每一行视为<key,value>对传给Map任务
* 用户可使用Reader接口实现自己新定义的输入类型
5、副作用
* 在某些情况下,如果Map和Reduce操作增加辅助的输出文件会比较简单,故我们依靠Writer接口把这种“副作用”变成原子和幂等的(幂等:总产生相同结果的数学运算)
* 实现:首先把输出结果写到一个临时文件中,在完成输出后,再调用系统级的原子操作rename临时文件
6、跳过损坏的记录
* 当用户程序Bug导致在处理某些记录时Crash掉,惯常的做法的修复Bug后再次执行。但有时候这些Bug修复是非常困难的,然而对于一个巨大的数据集来说,忽略小部分记录是可以接受的
* 基于上述需求,我们提供一种执行模式:在这种模式下,为了保证整个处理顺利进行,MapReduce库会检查导致Crash的记录,并跳过这些记录不处理
* 实现:MapReduce库通过全局变量保存所有记录序号,每个Worker进程设置信号处理函数来捕获异常(内存段/总线等),当程序Bug导致异常错误被信号处理函数捕获,信号处理函数会通过UDP包向Master发出最后一条记录的序号
7、本地执行
* 由于Map和Reduce会分布到集群各个机器上执行,而且执行位置是Master动态调度的,所以调试Map和Reduce函数非常困难。
* 所以我们开发了一套MapReduce库的本地版本,用于使用本地调试和测试工具,如gdb等
8、状态信息
* Master使用嵌入式HTTP服务器显示一组状态信息Web界面,给用户监控任务执行状态
* 显示的内容包括:计算执行进度、各状态的任务数、输入/中间/输出的字节数、各Worker的状态等等
9、计数器
* MapReduce库使用计数器来统计各事件的发生次数,计数器当前的值也会显示在Master状态页面给用户监控
* 用户创建:用户可在程序中创建一个计数器对象,在map和reduce函数中增加计数器的值。
* 系统自动维护:MapReduce库自己也会维护一些计数器对象,比如已处理的<key, value>对数量等
* 计数器机制对MapReduce操作的完整性检查非常有用,比如监控中间key值集合必须等于输出的key值集合等
五、性能
* 这里在同个集群环境做了2个性能测试,1个为特定模式匹配,1个为数据排序,这2个程序在MapReduce的应用也是非常典型的
1、集群配置
* 1800台机器,每台机器2个2G主频Intel XeonCPU、4GB内存、2个160G硬盘、千兆以太网卡
* 集群部署在2层树形交换网络,Root节点100~200GBPS传输带宽,所有机器均对等部署,任意两点网络来回时间小于1ms
2、GREP(测试1)
* 实验设计:扫描10^10左右个100字节组成的记录(1TB),查找出概论较小的3个字符模式。输入数据拆分64MB的block(M=15000),结果输出到一个文件中(R=1,因为结果集不大)

* 实验结果如上图所示,Y轴为处理速度,处理速度随着参与MapReduce计算机器的增加而增加。整个过程用了150s,包括开始约1分钟预启动(程序上次到集群、GFS打开文件、Master获取文件位置信息等),以及80s的实际计算时间
3、排序(测试2)
* 实验设计:排序10^10左右个100字节组成的记录(1TB),模仿YeraSort排序。输入数据拆分64MB的block(M=15000),排序结果输出到4000个文件中(R=4000)
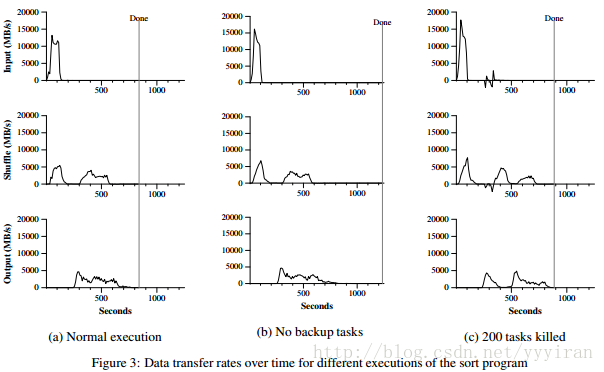
* 图的(a)栏显示排序程序正常执行的情况,对于正常执行的程序而言:
- 上图Input:显示Map输入数据读取速度,峰值达到13GB/s
- 中图Shuffle:显示从Map任务的中间数据传输给Reduce任务的网络IO情况
- 下图Output:显示Reduce最终输出文件速度
* 有一些值得注意的现象,如Map对输入数据的读取速度比Reduce对输出数据的写入速度高很多,这是因为输入数据本地优化策略的作用,使得绝大部分数据是从本地硬盘读取的原因
4、高效的备用任务
* 图的(b)栏显示了关闭备用任务的执行情况,与(a)相比,下图Output输出最终文件时间上被拖了一个长长的尾巴,而且这段时间几乎没有写入,却将任务执行时间在960s后由延时了300s(44%)。
5、失效的机器
* 图的(c)栏显示了在程序开始几分钟后kill掉200(1/9)个Worker的执行情况,集群立即调度重启新的Worker处理进程。总的执行时间为933s,只比程序正常执行的情况多用了5%的时间
六、经验
* MapReduce库能广泛应用于我们日常工作遇到的各类问题,在各个领域应用广泛,如大规模机器学习、网页信息提取、大规模图形计算等
* MapReduce的成功取决于快速写出一个简单的程序,就能在上千台机器的集群上做大规模并发处理,极大加快了设计和开发周期;而且完全可以让没有分布式/并行处理开发经验的程序员利用大量资源,开发出分布式/并行处理的应用
* MapReduce最成功的应用就是重写了Google搜索服务所使用的Index系统(大规模索引),使用MapReduce带来了代码简单小巧、高性能、操作管理更简单的优点
最后
以上就是痴情哈密瓜最近收集整理的关于论文学习笔记:MapReduce的全部内容,更多相关论文学习笔记内容请搜索靠谱客的其他文章。








发表评论 取消回复