我是靠谱客的博主 跳跃魔镜,这篇文章主要介绍【MapReduce】基础案例 ---- 自定义Partitioner分区 ( 按手机号分区 )自定义Partitioner分区,现在分享给大家,希望可以做个参考。
文章目录
- 自定义Partitioner分区
- ▪ 自定义分区基本步骤
- ▪ 案例
- 需求分析
- 代码实现
- PhoneBean封装类
- ProvincePartitioner分区类
- Mapper阶段
- Reducer阶段
- Driver阶段
- ★ 直接利用统计好的结果
自定义Partitioner分区
▪ 自定义分区基本步骤

返回顶部
▪ 案例
需求分析
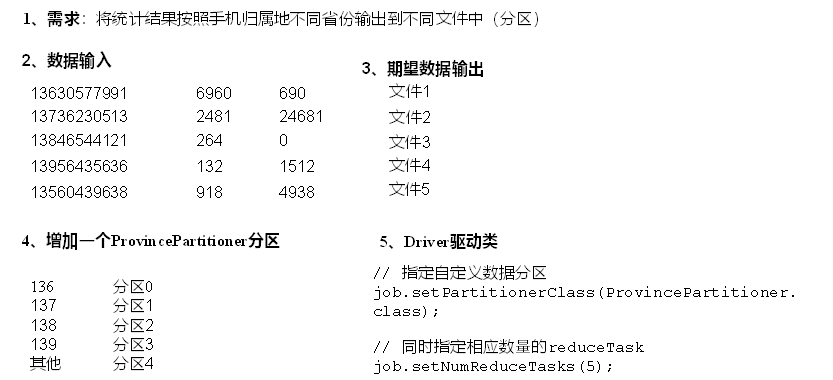
将统计结果按照手机归属地不同省份输出到不同文件中(分区)
(1)输入数据
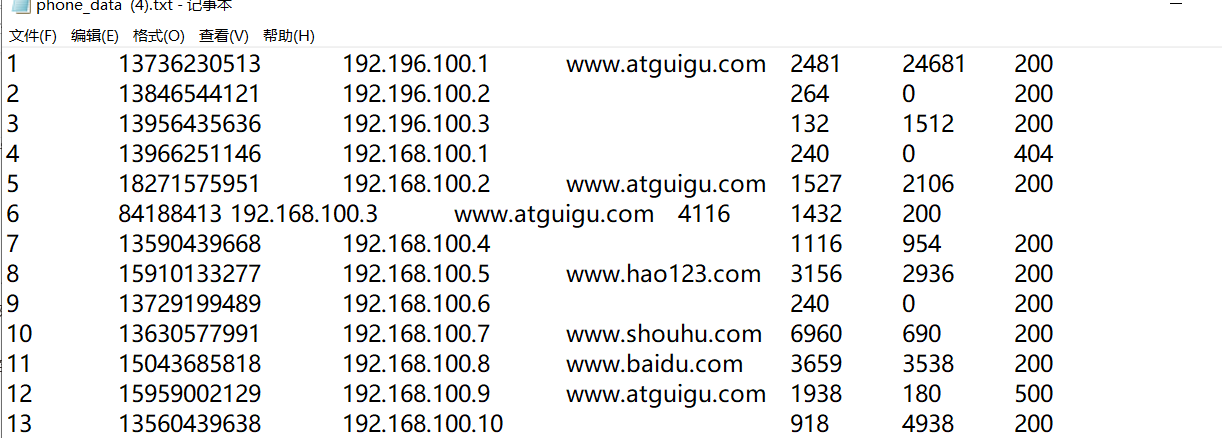
(2)期望输出数据
手机号136、137、138、139开头都分别放到一个独立的4个文件中,其他开头的放到一个文件中。
返回顶部
代码实现
PhoneBean封装类
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class PhoneBean implements Writable {
private String ip; // ip
private long upFlow; // 上行流量
private long downFlow; // 下行流量
private long sumFlow; // 总流量
public PhoneBean() {
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(ip);
dataOutput.writeLong(upFlow);
dataOutput.writeLong(downFlow);
dataOutput.writeLong(sumFlow);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
ip = dataInput.readUTF();
upFlow = dataInput.readLong();
downFlow = dataInput.readLong();
sumFlow = dataInput.readLong();
}
@Override
public String toString() {
// 方便后续切割
return ip + "t" +upFlow + "t" + downFlow + "t" + sumFlow;
}
public String getIp() {
return ip;
}
public void setIp(String ip) {
this.ip = ip;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
public void set(String ip1,long upFlow1,long downFlow1){
ip = ip1;
upFlow = upFlow1 ;
downFlow = downFlow1;
sumFlow = upFlow1 + downFlow1;
}
}
返回顶部
ProvincePartitioner分区类
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class ProvincePartitioner extends Partitioner <Text,PhoneBean> {
@Override
public int getPartition(Text text, PhoneBean phoneBean, int numPartitions) {
// key 是手机号
// value 是户主信息
// 1.获取手机号前三位
String phoneNum = text.toString().substring(0,3);
// 2.定义分区数 注意:分区数必须从0开始
int partition = 4;
if ("136".equals(phoneNum)){
partition = 0;
} else if ("137".equals(phoneNum)){
partition = 1;
} else if ("138".equals(phoneNum)){
partition = 2;
}else if ("139".equals(phoneNum)){
partition = 3;
} else {
partition = 4;
}
return partition;
}
}
返回顶部
Mapper阶段
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class PhoneMapper extends Mapper<LongWritable, Text,Text,PhoneBean> {
Text k = new Text();
PhoneBean v = new PhoneBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1. 读取一行数据
String line = value.toString();
// 2. 拆分
String[] words = line.split("t");
// 3. 封装对象
k.set(words[1]);
String ip = words[2];
long upFlow = Long.parseLong(words[words.length-3]);
long dowmFlow = Long.parseLong(words[words.length-2]);
v.setIp(ip);
v.setUpFlow(upFlow);
v.setDownFlow(dowmFlow);
// 4.写出
context.write(k,v);
}
}
返回顶部
Reducer阶段
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class PhoneReducer extends Reducer<Text,PhoneBean,Text,PhoneBean> {
String ip = "";
long sum_upFlow = 0;
long sum_downFlow = 0;
PhoneBean v = new PhoneBean();
@Override
protected void reduce(Text key, Iterable<PhoneBean> values, Context context) throws IOException, InterruptedException {
// 1.累加求和
for (PhoneBean phoneBean:values){
ip = phoneBean.getIp();
sum_upFlow += phoneBean.getUpFlow();
sum_downFlow += phoneBean.getDownFlow();
}
v.set(ip,sum_upFlow,sum_downFlow);
// 2.写出
context.write(key,v);
ip = "";
sum_upFlow = 0;
sum_downFlow = 0;
}
}
返回顶部
Driver阶段
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class PhoneDriver {
public static void main(String[] args) {
Job job = null;
Configuration conf = new Configuration();
try{
// 获取job对象
job = Job.getInstance(conf);
// 配置
job.setMapperClass(PhoneMapper.class);
job.setReducerClass(PhoneReducer.class);
job.setJarByClass(PhoneDriver.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(PhoneBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(PhoneBean.class);
// 指定自定义数据分区
job.setPartitionerClass(ProvincePartitioner.class);
// 同时指定相应数量的reduce task
job.setNumReduceTasks(5);
// 设置输入输出路径
FileInputFormat.setInputPaths(job,new Path("G:\Projects\IdeaProject-C\MapReduce\src\main\java\第三章_MR框架原理\Partition分区\dataset\phone_data .txt"));
FileOutputFormat.setOutputPath(job,new Path("G:\Projects\IdeaProject-C\MapReduce\src\main\java\第三章_MR框架原理\Partition分区\output1\"));
// 提交job
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
} catch (Exception e){
e.printStackTrace();
}
}
}
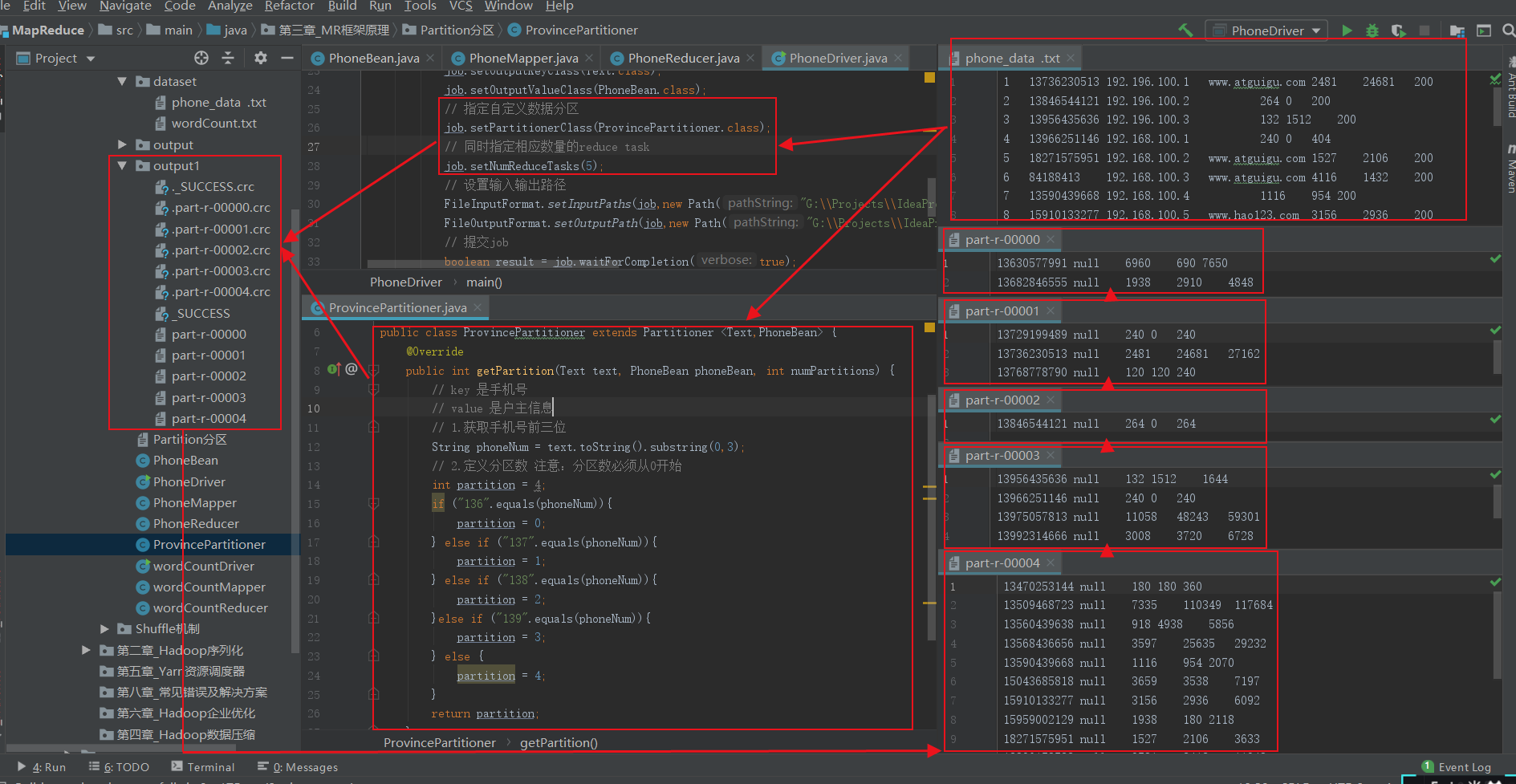
返回顶部
★ 直接利用统计好的结果
- 在上面的处理过程中,我们通过创建Bean类,处理了统计总流量的同时进行了分区处理。接下来我们也可以进行两次job。第一次处理统计流量,第二次处理统计好的结果,执行分区操作。
分区类
public class P extends Partitioner <Text,Text>{
@Override
public int getPartition(Text text, Text text2, int numPartitions) {
// key 是手机号
// value 是流量信息
// 1.获取手机号前三位
String phoneNum = text.toString().substring(0,3);
// 2.定义分区数 注意:分区数必须从0开始
int partition = 4;
if ("136".equals(phoneNum)){
partition = 0;
} else if ("137".equals(phoneNum)){
partition = 1;
} else if ("138".equals(phoneNum)){
partition = 2;
}else if ("139".equals(phoneNum)){
partition = 3;
} else {
partition = 4;
}
return partition;
}
}
Mapper阶段
- 按照制表符拆分,注意这里有的时候分隔符要注意:尽量把制表符和空格都试一遍,有时候文本格式不明显,会报错提示类似数组越界,其实就是没有拆分对。
- 这里处理的是已经统计好总流量的数据,在分区的时候是按照key来进行的,所以我们要把电话号码封装到key中,使
用split的重载方法,可以对数据按照“t”只进行一次分割,这里的2其实也可以认为是分割后行程的块数。(string.split()方法对空字符的处理)
public class PM extends Mapper<LongWritable, Text,Text,Text> {
Text k = new Text();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 13470253144 180 180 360
// 1.读取一行数据
String line = value.toString();
// 2.拆分
String[] fields = line.split("t",2);
k.set(fields[0]);
v.set(fields[1]);
// 3.写出
context.write(k,v);
}
}
Reducer阶段
- Mapper阶段已经对数据进行了拆分,封装了key,value,这里只需要读取写出即可。
public class PR extends Reducer<Text,Text,Text,Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value:values){
context.write(key,value);
}
}
}
Driver阶段
- 设置分区配置:分区关联的类,ReduceTask数目
job.setPartitionerClass(P.class);
job.setNumReduceTasks(5);
由于分区数决定了生成多少个ReduceTask来处理对应分区的数据,所以在job中要设置ReduceTask的数目。 - 由于思路的一点改动,所以这里的文件输入路径应当改为已经处理好的总流量统计数据。
public class PD {
public static void main(String[] args) {
Job job = null;
Configuration conf = new Configuration();
try {
// 获取job
job = Job.getInstance(conf);
// 配置
job.setMapperClass(PM.class);
job.setReducerClass(PR.class);
job.setJarByClass(PD.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置分区配置
job.setPartitionerClass(P.class);
job.setNumReduceTasks(5);
// 输入、出路径
FileInputFormat.setInputPaths(job,new Path("G:\Projects\IdeaProject-C\MapReduce\src\main\java\第二章_Hadoop序列化\output\part-r-00000"));
FileOutputFormat.setOutputPath(job,new Path("G:\Projects\IdeaProject-C\MapReduce\src\main\java\第七章_MR扩展案例\自定义分区\output"));
// 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0:1);
} catch (Exception e){
e.printStackTrace();
}
}
}
返回顶部
最后
以上就是跳跃魔镜最近收集整理的关于【MapReduce】基础案例 ---- 自定义Partitioner分区 ( 按手机号分区 )自定义Partitioner分区的全部内容,更多相关【MapReduce】基础案例内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复