一 什么是RDD,有什么特点?
RDD: Resilient Distributed Dataset,弹性分布式数据集。
特点:
# 它是一种数据的集合
# 它可以被分区,每一个分区分布在不同的集群中节点,从而使得RDD可以被并行处理,所以它是分布式的
# 提供容错性,它将计算转换一个成一个有向无环图(DAG)的任务集合,方便利用血缘关系进行数据恢复
# 中间计算结果缓存在内存
二 RDD与MapReduce比较
2.1 迭代计算
MapReduce在进行迭代计算的时候,都需要读写磁盘,如果涉及到多个作业流程,那么意味着多次读写HDFS,所以MapReduce在迭代式计算的时候,会进行大量的磁盘I/O操作
RDD: RDD会将计算转换成一个DAG的任务集,每次处理完后的数据缓存到内存中,并且可以作为下一次计算的输入数据,所以只需要一次读写操作,避免了大量的I/O操作
2.2 容错机制
基于YARN的MapReduce的Task执行过程产生异常和和JVM的意外终止,会汇报给Application Master,任务失败一次,并不意味着任务的完全失败,它有重试机制,当达到重试次数限制还没有成功,则认为该任务运行失败
如果ApplicationMaster失败,那么Resource Manager进行失败检测然后重新启动一个新的Container,然后在这个Container中启动新的Application Master进程。对于新创建的Application Master,它能够检测到之前失败的Application Master已经运行完成的任务,因此,新的Application Master无需重头开始已经执行过的任务。
Node Manager挂了,那么运行于其上的Task和Application Master都会失败,那么就会按照ApplicationMaster和Task的恢复机制来处理
Resource Manager挂了,那么Yarn的各个组件,包括正在执行的作业、任务都会受到影响。Resource Manager的作用如此重要,因此Hadoop提供了检查点不定时的将它的状态持久化到存储系统,以便在它失败后,能够从失败的状态中恢复过来。
Resource Manager挂了之后,系统管理员重新启动一个新的Resource Manager,然后从上个失败的Resource Manager保存的检查点进行状态恢复。保存的状态信息包括包括集群的Node Managers以及正在运行的作业,Task和Application Master不在要恢复的状态中,因为Application Master是由Node Manager管理,Task是由Application Master管理。
RDD: 有两种容错方式,数据检查点和记录数据的更新。
面向大规模数据分析,数据检查点操作成本很高,需要通过数据中心的网络连接在机器之间复制庞大的数据集,而网络带宽往往比内存带宽低得多,同时还需要消耗更多的存储资源。
因此,Spark选择记录更新的方式。但是,如果更新粒度太细太多,那么记录更新成本也不低。
因此,RDD只支持粗粒度转换,即只记录单个块上执行的单个操作,然后将创建RDD的一系列变换序列(每个RDD都包含了他是如何由其他RDD变换过来的以及如何重建某一块数据的信息。因此RDD的容错机制又称“血统(Lineage)”容错)记录下来,以便恢复丢失的分区。
2.3 编程范式不同
MapReduce: 将整个计算过程分为Map和Reduce阶段
RDD: 将计算过程转换成有向无环图(DAG),主要就是进行转换和算子操作,即(transformation+action)
2.4 中间数据的落地
MapReduce: 中间结果数据需要存储在HDFS
RDD: 中间结果数据缓存在内存
2.5Task的运行方式不同
MapReduce: Task以进程的方式运行,任务启动时间较长
RDD: RDD对应的Task是以线程的方式维护,启动时间较短
三 RDD有哪些类型
RDD主要分为三类:创建操作(creation)、转换操作(transformation)、
行动操作(action)
创建操作: 用于创建RDD, RDD的创建有2种方法,第一:来自于内存和外部存储系统;第二:来自于转换操作生成的RDD
转换操作: 将RDD通过一定的操作转换成新的RDD,比如map,flatMap,reduce,groupBy,union等
行动操作:能够出发Spark运行的操作,比如foreach,saveAsTextFile,
collect,count
四 RDD的分区和分区函数
我们知道,RDD会进行分区,然后将每一个分区分布到集群中的节点上,分区的多少决定了RDD并行计算的粒度。我们可以在创建RDD的时候指定分区数目,如果没有指定,且是从HDFS读取文件,那么分区数默认为block数量;如果不是HDFS文件读取,默认是该程序所分配到的CPU核数
scala> val lines =sc.textFile("/user/hadoop/input/user.txt")
lines: org.apache.spark.rdd.RDD[String] = /user/hadoop/input/user.txtMapPartitionsRDD[1] at textFile at <console>:24
scala> lines.partitions.size
res0: Int = 2
//显示设置分区数为6
scala> val lines =sc.textFile("/user/hadoop/input/user.txt",6)
lines: org.apache.spark.rdd.RDD[String] =/user/hadoop/input/user.txt MapPartitionsRDD[3] at textFile at<console>:24
scala> lines.partitions.size
res1: Int = 6
五 什么是RDD首选位置
Preferred Locations: spark形成的有向无环图DAG时候,会尽可能的把计算分配到靠近数据的位置,减少数据的网络传输。当RDD产生的时候存在首选位置,比如HadoopRDD分区的首选位置就是HDFS block所在节点;当RDD分区被缓存,则计算应该发送到缓存分区所在节点进行,再不然回溯到血缘关系中一直找到位置属性的父RDD,并据此决定子 RDD的位置
六 RDD的依赖关系
RDD的分区依赖关系 区分为窄依赖(Narrow Dependency)和宽依赖(Wide Dependency):
窄依赖: 父RDD的某一个分区只有一个子RDD的某一个分区使用,或者说子RDD的某一个分区只依赖于一个父RDD的某一个分区,即父RDD的分区和子RDD的分区是一一对应关系
宽依赖:父RDD的某一个分区可以被一个或多个子RDD的分区使用,或者说一个或者多个子RDD的分区依赖于父RDD的某一个分区,它们并不是一一对应的关系,而且这种依赖还涉及到跨节点
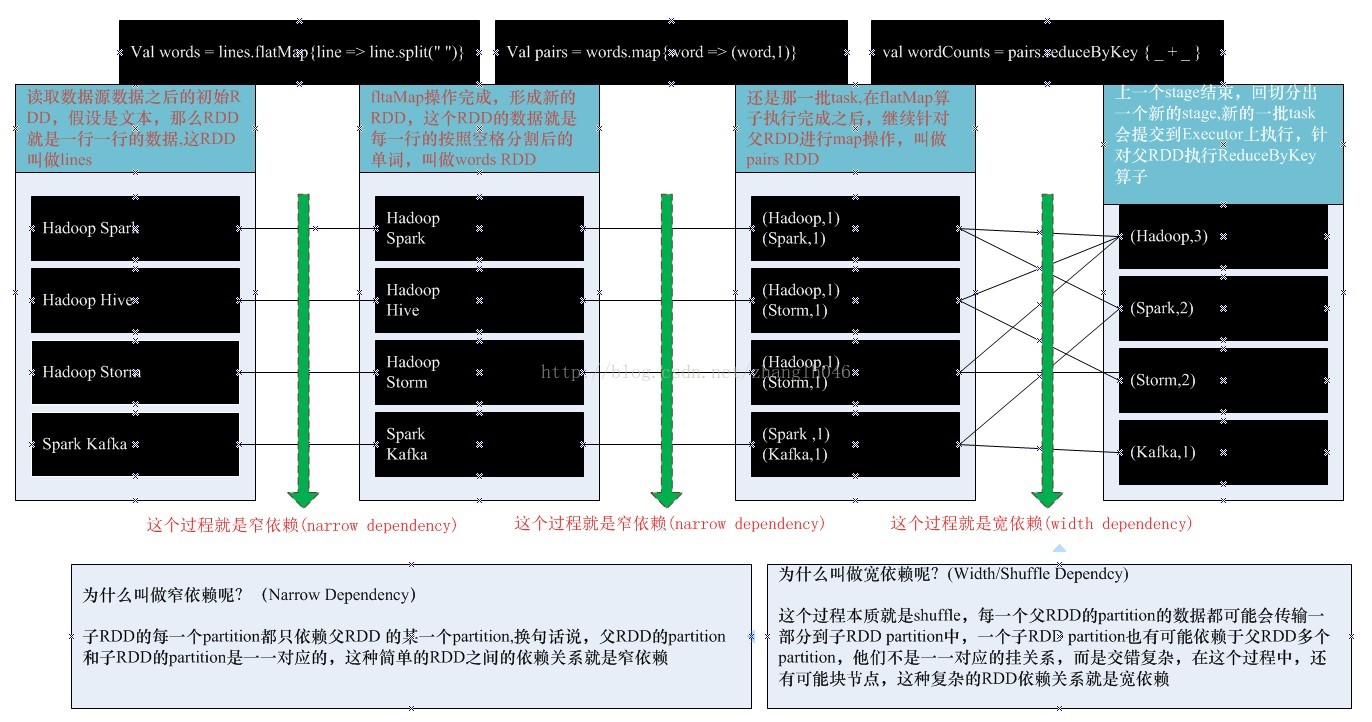
窄依赖和宽依赖的区别:
第一:窄依赖允许在单个节点上流水线般的执行,在该节点可以计算所有父RDD分区,比如map和filter操作;宽依赖需要所有的父RDD数据可用,并且涉及到shuffle操作
第二:窄依赖的特点决定了节点失败后的恢复效率更高,因为只有丢失的父RDD的分区需要重新计算,并且这些丢失的父RDD分区数据可以并行的在不同节点重新计算;宽依赖单个节点失败可能导致一个RDD所有父或者祖先RDD的分区数据丢失,导致计算重新执行
七 RDD的操作
7.1 创建操作
目前有两种类型的基础RDD:一种是并行集合(Parallelized Collections),接收一个已经存在的scala集合,然后进行各种并行计算;另外一种是从外部存储创建的RDD,外部存储可以是文本文件或者HDFS,也可以是Hadoop的接口API
7.1.1 并行化集合创建操作
通过SparkContext的parallelize方法,在一个已经存在的scala集合上创建的Seq对象,集合的对象将会被复制,创建出一个可以被并行操作的分布式数据集。
val conf = new SparkConf().setAppName("Parallelize Test").setMaster("local[1]")
val sc = new SparkContext(conf)
// parallelize
val rdd = sc.parallelize(1 until 20,4)
val resultsRDD = rdd.collect()
println(rdd.partitions.size)
// makeRDD 具有parallelize相同的功能,但是他还可以指定每一个分区的首选位置
sc.makeRDD(1 to 100)
val collections = Seq((1 to 50,Seq("hadoop-all-01","hadoop-all-02")),(50 to 100,Seq("hadoop-all-03")))
val mRDD = sc.makeRDD(collections)
println(mRDD.preferredLocations(mRDD.partitions(0)))
println(mRDD.preferredLocations(mRDD.partitions(1)))
7.1.2 外部存储创建操作
Spark可以将Hadoop所支持的存储资源转化成RDD,如本地文件,HDFS,Cassandra, HBase等,Spark支持文本文件,Sequence Files以及Hadoop InputFormat格式
# textFile 可以将本地文件或者HDFS文件转换成RDD,该操作支持整个文件目录读取,文件可以是文本或者压缩文件;用于可以指定分区数,但是不能小于HDFS的block数量
def textFile(path: String, minPartitions: Int =
defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat],classOf
[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)}
# wholeTextFile 处理整个文件夹里的数据,返回(文件名,内容)元组
val lines = sc.wholeTextFiles("/user/hadoop/whole",3)
val dirs = lines.collect()
for (i <- 0 until dirs.length) {
val tuple = dirs(i)
val filename = tuple._1
val data = tuple._2
val linesRDD = sc.parallelize(data.split(","),3)
val results = linesRDD.map(word => (word,1)).reduceByKey(_+_)
results.collect.foreach(data => println(data))
}
# sequenceFile[K,V] 可以将sequenceFile转换成RDD,它是hadoop用来存储二进制形式的key-value对而设计的一种文件格式
#hadoopFile,hadoopRDD,newAPIHadoopRDD都可以将其他Hadoop输入类型转换成RDD使用操作
7.2 转换操作
7.2.1 基础转换操作
# map对数据集每一条记录进行映射,执行一个指定的函数,
会将映射结果形成新的RDD
val lines = List(1,2,3,4,5)
vala rdd = sc.parallelize(lines)
val sqrtRdd = rdd.map(e=> e*e)
sqrtRdd.foreach(d => println(d))
# distinct 去重复
val lines = List(1,2,3,4,5,1,1,2)
val rdd = sc.parallelize(lines)
val distinctRdd = rdd.distinct
distinctRdd.foreach(d => println(d))
# flatMap 首先进行flat扁平化然后在进行map操作
val lines = List("hadoop followspain","spark hadoop china england",
"hadoop spain italy")
val rowRdd = sc.parallelize(lines,3)
val elementRdd = rowRdd.flatMap(line =>line.split(" "))
elementRdd.foreach(d=>println(d))
# coalesce 对RDD根据指定的分区数进行重分区,第二参数指定是否进行shuffle;注意:如果指定分区数小于原分区,则可以顺利进行,但是如果大于原分区数,必须指定shuffle参数为true,否则分区不会改变
# repartition也是对根据指定的分区数进行重分区,但是第二个参数默认就是true,也就是默认就需要shuffle操作
val lines = List(1,2,3,4,5,6,7,8,9,10,11,12)
val lineRDD = sc.parallelize(lines,3)
val x = lineRDD.coalesce(2)
x.partitions.size
res1: Int = 2
val x = lineRDD.coalesce(4)
x.partitions.size
res2: Int = 3
val x = lineRDD.coalesce(4,true)
x.partitions.size
res3: Int = 4
val y = lineRDD.repartition(6)
y.partitions.size
res4: Int = 6
# randomSplit(weights:Array[Double],seed:Long=Utils.random.nextLong)
:Array[RDD[T]] 根据weights权重将一个RDD分割为多个RDD
val sparkConf = new SparkConf().setAppName("Word Count").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(1 to 10,10)
// 该结果是一个RDD数组
val splitRDD = rdd.randomSplit(Array(0.3,0.2,0.1,0.4))
println(splitRDD.size) // 4
// 由于randomSplit的第一个参数weigjhts中传入的值有4个,因此会切分成4个RDD,把之前的RDD按照权重
// 0.3,0.2,0.1,0.4随机划分到4个RDD中,权重高的RDD划分到的几率大一些,注意权重总和加起来为1,否则不正常
splitRDD(0).collect // Array(1, 2, 3, 8)
splitRDD(1).collect // Array(4)
splitRDD(2).collect // Array(7)
splitRDD(3).collect // Array(5, 6, 9, 10)
# glom():RDD[Array[T]] RDD中每一个分区所有类型为T的数据转变成为元素类型为T的数组
val srcRdd = sc.makeRDD(1 to 12,3)
srcRdd.glom().collect
//Array[Array[Int]] = Array(Array(1, 2, 3, 4), Array(5, 6, 7, 8),Array(9, 10, 11, 12))
# union(other:RDD[T]):RDD[T] RDD进行联合,返回两个RDD的并集
# intersection(other:RDD[T]):RDD[T] 返回两个RDD的交集,类似于SQL的inner join
#intersection(other:RDD[T],numPartitions:Int):RDD[T]
#intersection(other:RDD[T],partitioner:Partitioner):RDD[T]
# subtract(other:RDD[T]):RDD[T] 返回在RDD中出现但是不在other RDD中出现的元素,有多少是多少不去重复
# subtract (other:RDD[T],numPartitions:Int):RDD[T]
# subtract(other:RDD[T],partitioner:Partitioner):RDD[T]
scala> val rdd1 = sc.makeRDD(1 to 2,1)
rdd1: org.apache.spark.rdd.RDD[Int] =ParallelCollectionRDD[11] at makeRDD at <console>:24
scala> val rdd2 = sc.makeRDD(2 to 5,1)
rdd2: org.apache.spark.rdd.RDD[Int] =ParallelCollectionRDD[12] at makeRDD at <console>:24
scala> val rdd3 = rdd1.union(rdd2).collect
rdd3: Array[Int] = Array(1, 2, 2, 3, 4, 5)
scala> val rdd3 =rdd1.intersection(rdd2).collect
rdd3: Array[Int] = Array(2)
scala> val rdd3 = rdd1.subtract(rdd2).collect
rdd3: Array[Int] = Array(1)
# mapPartitions[U](f: (Iterator[T]) =>Iterator[U],preserversPartitions:Boo
Lean = false):RDD[U] 和map操作类似,只不过映射的参数由RDD中的每一个元素变成了RDD中每一个分区的迭代器,其中preserversPartitions表示是否保留父RDD的的partitions分区信息。如果在映射过程中需要频繁创建的额外对象,使用mapPartitions比操作map高效的多,比如RDD所有数据通过JDBC写入数据库,如果使用map函数可能为每一个元素都创建连接
# mapPartitionsWithIndex[U](f: (Int,Iterator[T] )=> Iterator[U],
preserversPartitions:BooLean = false)):RDD[U] 类似于mapPartitions,只是输入参数多了一个分区索引
var mapPartRDD = sc.makeRDD(1 to 5,2)
var rdd3 = mapPartRDD.mapPartitions{ x => {
var result = List[Int]()
var i = 0
while(x.hasNext){
i += x.next()
}
result.::(i).iterator
}}
rdd3.collect
val rdd2 = mapPartRDD.mapPartitionsWithIndex{
(x,iter) => {
val result = List[String]()
var i = 0
while(iter.hasNext){
i += iter.next()
}
result.::(x+"|"+i).iterator
}
}
rdd2.collect
# zip[U](other:RDD[U]):RDD[(T,U)] 用于将两个RDD组合成Key/Value的形式的RDD,默认两个RDD的分区数和元素数量相同,否则抛出异常,这也是所谓的拉链操作
scala> rdd2.collect
res13: Array[String] = Array(0|3, 1|12)
scala> val rdd1 = sc.makeRDD(1 to 5,2)
rdd1: org.apache.spark.rdd.RDD[Int] =ParallelCollectionRDD[27] at makeRDD at <console>:24
scala> val rdd2 =sc.makeRDD(Seq("A","B","C","D","E"),2)
rdd2: org.apache.spark.rdd.RDD[String] =ParallelCollectionRDD[28] at makeRDD at <console>:24
scala> rdd1.zip(rdd2).collect
res14: Array[(Int, String)] = Array((1,A), (2,B),(3,C), (4,D), (5,E))
# zipPartitions:将多个RDD按照partition组合成为新的RDD,该操作需要RDD分区数相同,但是对于每一个分区内元素数量没有限制
# zipWithIndex():RDD[(T,Long)] 将RDD中的元素和这个元素在RDD的id索引号组合成键值对
scala> val rdd2 =sc.makeRDD(Seq("A","B","R","D","F"),2)
rdd2: org.apache.spark.rdd.RDD[String] =ParallelCollectionRDD[31] at makeRDD at <console>:24
scala> rdd2.zipWithIndex().collect
res15: Array[(String, Long)] = Array((A,0), (B,1),(R,2), (D,3), (F,4))
# zipWithUniqueId():RDD[(T,Long)] 将RDD的元素和一个唯一的ID组合成键值对
scala> val rdd1 =sc.makeRDD(Seq("A","B","C","D","E","F"),2)
scala> rdd1.zipWithUniqueId().collect
res16: Array[(String, Long)] = Array((A,0), (B,2),(C,4), (D,1), (E,3), (F,5))
7.2.2 键值转换操作
# partitionBy(p:Partitioner):RDD[(K,V)] 根据Partition函数生成新的ShuffleRDD,将原RDD重新分区
# mapValues[U]:(f:(V)=>U):RDD[(K,V)] 类似于map只不过是针对[K,V]中的value值进行map操作
#flatMapValues[U]:(f:(V)=>TraversableOnce[U]):RDD[(K,V)] 类似于flatMap操作,只不过是针对[K,V]中value值进行flatMap操作
val rdd1 = sc.makeRDD(Array((1,"A"),(2,"B"),(3,"C"),(4,"D"),(5,"E"),(6,"F")),2)
rdd1.partitionBy(new HashPartitioner(3))
val rdd2 = rdd1.mapValues(word => word.toLowerCase)
#combineByKey[C](createCombiner:(V)=>C,mergeValue:(C,V)=>C,
mergeCombiners:(C,C)):RDD[(K,C)]
#combineByKey[C](createCombiner:(V)=>C,mergeValue:(C,V)=>C,
mergeCombiners:(C,C),numPartitions:Int):RDD[(K,C)]
combineByKey: 用于将RDD[K,V]转换成RDD[K,C]
createCombiner: 组合器函数,用于将V类型转换成C类型,输入参数为RDD[K,V]中的V,输出为C。如果是一个新的元素,此时使用createCombiner()来创建那个键对应的累加器的初始值。(!注意:这个过程会在每个分区第一次出现各个键时发生,而不是在整个RDD中第一次出现一个键时发生。说白了就是在当前RDD某一个分区如果key是第一次出现,则调用次函数进行初始化
mergeValue: 合并值函数,将一个C类型和一个V类型的值合并成一个C类型,输入参数为(C,V),输出为C。如果这是一个在处理当前分区中之前已经遇到键,此时combineByKey()使用mergeValue()将该键的累加器对应的当前值与这个新值进行合并。说白了就是当在RDD某分区中该key已经出现过一次,第二次则调用该函数进行merge,只限于当前分区的某一key
mergeCombiners:合并组合器函数,用于将两个C类型值合并成一个C类型的值,输入参数为(C,C),输出为C。由于每个分区都是独立处理的,因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器,就需要使用用户提供的mergeCombiners()将各个分区的结果进行合并。说白了就是一个RDD可能有多个分区,分区1存在key1,分区2存在key1,那么最后结果跨区合并就使用该函数
numPartitions: RDD分区数,默认是原来的分区
scala> val rdd1 =sc.makeRDD(Array(("A",1),("B",2),("A",4),("B",3),
("A",5),("C",1)))
scala> val rdd2 = rdd1.combineByKey(
| (v:Int) => v + "_",
| (c:String,v:Int) => c +"@" +v,
| (c1:String,c2:String) => c1+"$" + c2
| )
// 打印当前RDD各个分区的数据
scala> rdd1.mapPartitionsWithIndex{
| (partIdx,iter) => {
| var part_map =scala.collection.mutable.Map[String,List[Any]]()
| while(iter.hasNext){
| var part_name ="part_" + partIdx;
| var elem = iter.next()
| if(part_map.contains(part_name)) {
| var elems = part_map(part_name)
| elems ::= elem
| part_map(part_name) =elems
| } else {
| part_map(part_name) =List[Any]{elem}
| }
| }
| part_map.iterator
| }
| }.collect
res26: Array[(String, List[Any])] =Array((part_0,List((A,4), (B,2), (A,1))), (part_1,List((C,1), (A,5), (B,3))))
scala> rdd2.collect
res27: Array[(String, String)] = Array((B,2_$3_),(A,1_@4$5_), (C,1_))
# foldByKey(zeroValue:V)(func:(V,V)=>V)
#foldByKey(zeroValue:V,numPartitions:Int)(func:(V,V)=>V)
#foldByKey(zeroValue:V,p:Partitioner)(func:(V,V)=>V)
foldByKey: 用于将RDD[K,V]根据K做将V做折叠合并处理
zeroValue: 先根据映射函数将每一个分区不同的key在进行折叠处理的时候的初始值zeroValue应用于V,进行V的初始化,再将映射函数应用于初始化之后的V。举个例子:
Array((part_0,List((A,4), (B,2), (A,1))),(part_1,List((C,1), (A,5), (B,3))))
两个分区:part_0和part_1
第一个分区对于A这个key来说在进行处理之前需要加上zeroValue,第二个分区对于A这个key也需要加上zeroValue,
如果rdd1.foldByKey(2)(_+_).collect
那么第一个分区的结果就是:
A:zeroValue(2)+4+1 = 7
B:zeroValue(2)+2 = 4
第二个分区的结果:
C: zeroValue(2)+1 = 3
B:zeroValue(2)+3 = 5
A:zeroValue(2)+5 = 7
然后两个分区结果合并:
结果就是:Array((B,9),(A,14), (C,3))
val rdd1 = sc.makeRDD(Array(("A",1),("B",2),("A",4),("B",3),
("A",5),("C",1)))
val rdd2 = rdd1.foldByKey(2)(_+_)
Array[(String, Int)] = Array((B,9), (A,14), (C,3))
# reduceByKey(func:(V,V) => V):RDD[(K,V)]
# reduceByKey(func:(V,V) => V,numPartitions:Int):RDD[(K,V)]
# reduceByKey(p:Partitioner,func:(V,V) =>V):RDD[(K,V)]
# reduceByKeyLocally(func:(V,V) => V):Map[(K,V)]
reduceByKey:用于将RDD[K,V]中每一个K对应的V值根据映射函数进行计算,说白了就对相同的key的value进行reduce操作,内部其实调用的是combineByKey,numPartitions用于指定分区;reduceByKeyLocally将运算结果映射到一个Map中,而不是RDD
val sparkConf = new SparkConf().setAppName("Client Main").
setMaster("local[*]")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.makeRDD(Array(("A",1),("B",2),("A",4),("B",3),
("A",5),("C",1)),3)
rdd1.reduceByKey((x,y) => x+y).collect
// Array[(String, Int)] = Array((B,5), (C,1), (A,10))
# groupByKey():RDD[(K,Iterable[V])]
#groupByKey(numPartitions:Int):RDD[(K,Iterable[V])]
# groupByKey(p:Partitioner):RDD[(K,Iterable[V])]
groupByKey:用于将RDD[K,V]中每一个K对应的V值合并到一个集合Iterable[V]中,也就是根据key进行分组
val sparkConf = new SparkConf().setAppName("Client Main").
setMaster("local[*]")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.makeRDD(Array(("A",1),("B",2),("A",4),("B",3),
("A",5),("C",1)),3)
rdd1.groupByKey().collect
// Array[(String, Iterable[Int])] = Array((B,CompactBuffer(2, 3)),
// (C,CompactBuffer(1)), (A,CompactBuffer(1, 4, 5)))
# cogroup :相当于SQL语句中全外关联,关联不上的为空
def cogroup():Unit = {
val sparkConf = new SparkConf().setAppName("Client Main").
setMaster("local[*]")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.makeRDD(Array(("A",1),("B",2),("C",3)),2)
val rdd2 = sc.makeRDD(Array(("A","a"),("B","b"),("D","d")),2)
val rdd3 = sc.makeRDD(Array(("A","A"),("E","E")),2)
val rdd4 = rdd1.cogroup(rdd2,rdd3).collect
/**
* Array[(String, (Iterable[Int],Iterable[String], Iterable[String]))]
* =Array((B,(CompactBuffer(2),CompactBuffer(b),CompactBuffer())),
*(D,(CompactBuffer(),CompactBuffer(d),CompactBuffer())),
* (A,(CompactBuffer(1),CompactBuffer(a),CompactBuffer(A))),
*(C,(CompactBuffer(3),CompactBuffer(),CompactBuffer())),
*(E,(CompactBuffer(),CompactBuffer(),CompactBuffer(E))))
*/
}
# 内连接,基于cogroup实现,将两个RDD之间相同的key进行连接,不同的抛弃掉
join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
join[W](other: RDD[(K, W)], numPartitions: Int):RDD[(K, (V, W))]
def join():Unit = {
val sparkConf = new SparkConf().setAppName("Client Main").
setMaster("local[*]")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.makeRDD(Array(("A","1"),("B","2"),("C","3")),2)
val rdd2 = sc.makeRDD(Array(("A","a"),("B","b"),("F","f")),2)
rdd1.join(rdd2).collect
//Array[(String, (String, String))] = Array((B,(2,b)), (A,(1,a)))
}
# 左外连接,基于cogroup实现,以左边RDD的key为准,进行连接,如果另一个RDD没有则为None
leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V,Option[W]))]
leftOuterJoin[W](other: RDD[(K, W)], numPartitions:Int): RDD[(K, (V, Option[W]))]
def leftOutJoin():Unit = {
val sparkConf = new SparkConf().setAppName("Client Main").
setMaster("local[*]")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.makeRDD(Array(("A","1"),("B","2"),("C","3")),2)
val rdd2 = sc.makeRDD(Array(("A","a"),("B","b"),("F","f")),2)
rdd1.leftOuterJoin(rdd2).collect
// Array[(String,(String, Option[String]))] = Array((B,(2,Some(b))), (A,(1,Some(a))),(C,(3,None)))
}
# 右外连接,基于cogroup实现, 以右边RDD的key为准,进行连接,如果另一个RDD没有则为None
rightOuterJoin[W](other: RDD[(K, W)]): RDD[(K,(Option[V], W))]
rightOuterJoin[W](other: RDD[(K, W)],numPartitions:Int): RDD[(K, (Option[V], W))]
def rightOuterJoin():Unit = {
val sparkConf = new SparkConf().setAppName("Client Main").
setMaster("local[*]")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.makeRDD(Array(("A","1"),("B","2"),("C","3")),2)
val rdd2 = sc.makeRDD(Array(("A","a"),("B","b"),("F","f")),2)
rdd1.rightOuterJoin(rdd2).collect
//Array[(String, (Option[String], String))] = Array((B,(Some(2),b)),(F,(None,f)), (A,(Some(1),a)))
}
# 全连接,基于cogroup实现,两个RDD所有键值对都需要连接,如果另一方没有,则是None
fullOuterJoin[W](other: RDD[(K, W)]): RDD[(K,(Option[V], Option[W]))]
fullOuterJoin[W](other: RDD[(K, W)],numPartitions:Int): RDD[(K, (Option[V], Option[W]))]
def fullOuterJoin():Unit = {
val sparkConf = new SparkConf().setAppName("Client Main").
setMaster("local[*]")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.makeRDD(Array(("A","1"),("B","2"),("C","3")),2)
val rdd2 = sc.makeRDD(Array(("A","a"),("B","b"),("F","f")),2)
rdd1.fullOuterJoin(rdd2).collect
//Array[(String, (Option[String], Option[String]))] =Array((B,(Some(2),Some(b))),
// (F,(None,Some(f))),(A,(Some(1),Some(a))), (C,(Some(3),None)))
}
# 返回第一个RDD和第二个RDD的差集,也就是第一个RDD在第二个RDD不存在的元素,比如{1,2,3,5}和{1,2,4} 由于1,2在第二个集合有,所以不反回,3和5在第二个集合没有所以返回
subtractByKey[W: ClassTag](other: RDD[(K, W)]):RDD[(K, V)]
subtractByKey[W: ClassTag](other: RDD[(K,W)],numPartitions: Int): RDD[(K, V)]
def subtractByKey():Unit = {
val sparkConf = new SparkConf().setAppName("Client Main").
setMaster("local[*]")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.makeRDD(Array(("A","1"),("B","2"),("C","3")),2)
val rdd2 = sc.makeRDD(Array(("A","a"),("B","b"),("F","f")),2)
rdd1.subtractByKey(rdd2).collect
//Array[(String, String)] = Array((C,3))
}
7.3 控制操作
Spark可以将RDD持久化到内存或者磁盘,持久化到内存可以极大的提高迭代计算以及计算模型之间的数据共享,一般情况下,执行节点60%内存用于缓存数据,剩下40%用于运行任务。Spark使用persist、cache进行操作持久化,其中cache是persist的特例
cache():RDD[T]
persist():RDD[T]
val userRDD = sc.textFile("hdfs://hadoop-all-02:8020/user/hadoop
/input/user.txt")
// 对user.txt文件的RDD进行缓存
userRDD.cache()
// 第一次计算行数,只能从HDFS读取,不是从内存读取
userRDD.count()
// 第二次计算行数,使用内存读取数据
userRDD.count()
我们可以从job中查看到:
第一次耗时0.6s,第二次从内存读取耗时39毫秒
Persist可以指定StorageLevel,当StorageLevel为MEMORY_ONLY的时候就是cache:有哪些存储类型
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY= new StorageLevel(true, false, false, false)
val DISK_ONLY_2= new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY= new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2= new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER= new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2= new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK= new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2= new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER= new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2= new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
在Spark中可以使用checkpoint操作设置检查点,相对持久化persist而言,checkpoint将切断与该RDD的之前的依赖关系。设置检查点对包含依赖关系的长血统RDD是非常有用的,可以避免占用过多的系统资源和节点失败情况下重新计算成本过高的问题
val rdd = sc.makeRDD(1 to 4,1)
val flatMapRDD = rdd.flatMap(x => Seq(x,x))
// 设置检查点HDFS存储位置
sc.setCheckpointDir("hdfs://hadoop-all-02:8020/user/hadoop
/checkpoint/")
// 使用checkpoint设置检查点,属于懒加载
flatMapRDD.checkpoint()
// 在遇到行到操作的时候,进行检查点操作,检查点前为ParallelCollectionRDD[0],而检查点后为ParallelCollectionRDD[1]
flatMapRDD.dependencies.head.rdd
flatMapRDD.collect
flatMapRDD.dependencies.head.rdd
7.4 行动操作
7.4.1 集合标量行动操作
# first: 返回RDD中第一个元素,不排序
# count: 返回RDD中元素数量
# reduce: 根据映射函数,对RDD进行计算
# collect: 将RDD转化为数组
# take(num): 获取RDD中从0到num-1下标的元素,不排序
# top(num): 按照默认降序排序的或者指定规则排序返回前num个元素
# takeOrdered(num): 和top类似,只不过它是以升序排序,返回前num个元素
val rdd =sc.makeRDD(List(("E",5),("B",2),("A",1),("D",4),("C",3),
("H",7)),2)
scala> rdd.first
res0: (String, Int) = (E,5)
scala> rdd.take(3)
res1: Array[(String, Int)] = Array((E,5), (B,2),(A,1))
scala> rdd.top(3)
res2: Array[(String, Int)] = Array((H,7), (E,5),(D,4))
scala> rdd.takeOrdered(3)
res3: Array[(String, Int)] = Array((A,1), (B,2),(C,3))
scala> rdd.count
res4: Long = 6
scala> rdd.collect
res5: Array[(String, Int)] = Array((E,5), (B,2),(A,1), (D,4), (C,3), (H,7))
scala> rdd.reduce((x,y) => (x._1 + y._1, x._2+ y._2))
res11: (String, Int) = (DCHEBA,22)
# aggregate[U: ClassTag](zeroValue: U)(seqOp: (U,T) => U, combOp: (U, U) => U): U 聚合RDD中的元素,将每个分区里面的元素通过seqOp函数进行聚合,每一个分区的值都需要和zeroValue进行combine,然后用combOp函数将每个分区的结果和初始值(zeroValue)进行combine操作
# fold(zeroValue: T)(op: (T, T) => T): T 是aggregate简化本,seqOp和combOp使用的是同一个函数op
# aggregateByKey[U: ClassTag](zeroValue: U)(seqOp:(U, V) => U,combOp: (U, U) => U): RDD[(K, U)] 按照RDD[K,V]中k进行聚合,首先各个分区聚合,得到结果,同样是需要和初始值进行combine;然后各个分区的结果在和初始值通过combOp进行聚合
scala> val rdd1 =sc.makeRDD(List(1,2,3,4,5,6,7,8,9,10),2)
rdd1: org.apache.spark.rdd.RDD[Int] =ParallelCollectionRDD[3] at makeRDD at <console>:24
scala> rdd1.aggregate(0)({(x:Int,y:Int)=> x +y},{(x:Int,y:Int) => x+y})
res12: Int = 55
scala> rdd1.mapPartitionsWithIndex{
| (partIdx,iter) => {
| var part_map =scala.collection.mutable.Map[String,List[Any]]()
| while(iter.hasNext){
| var part_name ="part_" + partIdx;
| var elem = iter.next()
| if(part_map.contains(part_name)) {
| var elems = part_map(part_name)
| elems ::= elem
| part_map(part_name) =elems
| } else {
| part_map(part_name) =List[Any]{elem}
| }
| }
| part_map.iterator
| }
| }.collect
res13: Array[(String, List[Any])] =Array((part_0,List(5, 4, 3, 2, 1)), (part_1,List(10, 9, 8, 7, 6)))
scala> rdd1.aggregate(1)({(x:Int,y:Int)=> x +y},{(a:Int,b:Int) => a+b})
res14: Int = 58
第一步:先2个分区分别通过函数{(x:Int,y:Int)=> x + y}进行计算,第一个分区:zeroValue(1)+5+4+3
+2+1=16;第二个分区:zeroValue(1)+10+9+8+7+6=41
第二步:将两个分区的数据和zeroValue进行合并,即zeroValue+16+41=58
scala> rdd1.fold(1)({(x:Int,y:Int)=> x + y})
res15: Int = 58
它是简化版的aggregate函数,即分区合并和所有分区计算结果合并都用同一个函数{(x:Int,y:Int)=> x + y}
val rdd3 =sc.makeRDD(List(("A",1),("A",4),("A",5),("B",2),("C",4),
("B",3),("D",6)),2)
val rdd4 = rdd3.aggregateByKey(0)({(x:Int,y:Int)=> math.max(x,y)},{(a:Int,b:Int) => math.min(a,b)})
rdd4.collect
Array[(String, Int)] = Array((B,3), (D,6), (A,5),(C,4))
# countByKey(): Map[K, Long] 统计RDD[K,V]中k的个数
# countByValue()(implicit ord: Ordering[T] = null):Map[T, Long] 统计RDD[K,V]中V的个数
rdd3.countByKey()
Map(B -> 2, D -> 1, A -> 3, C -> 1)
rdd3.countByValue
Map((A,5) -> 1, (C,4) -> 1, (D,6) -> 1,(B,2) -> 1, (B,3) -> 1, (A,1) -> 1, (A,4) -> 1)
# foreach(f: T => Unit): Unit 遍历每一个元素
# foreachPartition(f: Iterator[T] => Unit): Unit遍历每一个分区
val allsize = sc.accumulator(0);
rdd3.foreachPartition(x=>{println(x.size);allsize+= x.size})
# sortBy[K](f: (T) => K,ascending: Boolean =true,numPartitions: Int = this.partitions.length)(implicit ord: Ordering[K],ctag: ClassTag[K]): RDD[T] 根据指定的排序函数将RDD中的元素进行排序
scala> rdd1.sortBy(x => x).collect
res24: Array[Double] = Array(8.0, 9.0, 10.23, 45.0)
scala> rdd1.sortBy(x => x,false).collect
res25: Array[Double] = Array(45.0, 10.23, 9.0, 8.0)
# sortByKey(ascending: Boolean = true,numPartitions: Int = self.partitions.length)
val rdd1 = sc.makeRDD(List(5,1,6,9,2))
val rdd2 =sc.makeRDD(List("hadoop","spark","hive","endeca","storm"))
val rdd3 = rdd1.zip(rdd2)
rdd3.sortByKey().collect
Array((1,spark), (2,storm), (5,hadoop), (6,hive),(9,endeca))
rdd3.sortByKey(false).collect
Array((9,endeca), (6,hive), (5,hadoop), (2,storm),(1,spark))
7.4.2 存储行动操作
saveAsTextFile(path: String): Unit 以文本文件形式存储
saveAsTextFile(path: String, codec: Class[_ <:CompressionCodec]): Unit
以文本文件形式存储,并且可以指定压缩类型
saveAsObjectFile(path: String): Unit 将RDD元素序列化成对象存入文件
将RDD存在HDFS文件上并且支持老板和新版
saveAsHadoopFile(
path:String,
keyClass: Class[_],
valueClass: Class[_],
outputFormatClass: Class[_ <: OutputFormat[_, _]],
codec:Class[_ <: CompressionCodec]): Unit
saveAsNewAPIHadoopFile(
path:String,
keyClass: Class[_],
valueClass: Class[_],
outputFormatClass: Class[_ <: NewOutputFormat[_, _]],
conf:Configuration = self.context.hadoopConfiguration): Unit
最后
以上就是俏皮马里奥最近收集整理的关于spark基础之RDD详解一 什么是RDD,有什么特点?二 RDD与MapReduce比较三 RDD有哪些类型四 RDD的分区和分区函数五 什么是RDD首选位置六 RDD的依赖关系七 RDD的操作的全部内容,更多相关spark基础之RDD详解一内容请搜索靠谱客的其他文章。








发表评论 取消回复