SPARK
【什么是Spark】
Spark是一种快速、通用、可扩展的大数据分析引擎目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLlib等子项目,Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。
【Spark特点】
1.与Hadoop相比速度快
与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。
2.易用
Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。
3.通用
Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)
4.兼容性
Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用Spark。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具。
【Spark集群安装】
****
【spark集群运行jar】
spark-submit
--class cn.st.test.TestJDBC //主函数类的全路径
--master spark://localhost:7077
--executor-memory 1G
--total-executor-cores 2 jarpath //jarpath ,jar包所在服务器路径
arg1 arg2 //主函数可能需要参数
【Spark-Shell】
1.启动
spark-shell --master spark://localhost:7077 --executor-memory 2g --total-executor-cores 12
2.http://localhost:8080/ //spark管理界面
【RDD的计算】
RDD的计算实际上我们可以分为两大部分。
1)Driver端的计算
主要是stage划分,task的封装,task调度执行
2)Executor端的计算
真正的计算开始,默认情况下每个cpu运行一个task。一个task实际上就是一个分区,我们的方法无论是转换算子里封装的,还是action算子里封装的都是此时在一个task里面计算一个分区的数据。
【RDD特点:】
1.一系列分区
2.每一个输入切片会有一个函数作用在上面
3.RDD和RDD之间存在依赖关系
4.RDD中如果存储的是K-V,shuffle时会有一个分区器,模式hashpartitioner
5.如果是读取HDFS中的数据,那么会有一个最优位置。
【SPARK任务执行流程】
1.构建DAG(调用RDD上的方法)
2.DAGScheduler将DAG切分Stage(切分的依据是Shuffle),将Stage生成的Task以TaskSet的形式给TaskScheduler
3.TaskScheduler调度Task(根据资源情况将Task调度到相应的Executor中)
4.Excutor接收Task,然后将Task丢入到线程池中执行
DAG:有向无环图(数据执行过程,有方向,无闭环)
DAG描述多个RDD的转换过程,任务执行时,可以按照DAG的描述,执行真正的计算(数据被操作的一个过程)
DAG是有边界的:开始(通过SparkContext创建的RDD),结束(触发Action,调用Run Job就是一个完整的DAG形成了)
一个RDD知识描述了数据计算过程中的一个环节,而DAG是由一到多个RDD组成,描述了数据计算过程中的所有环节(过程)
一个Spark Application 中是有多少个DAG:一到多个(取决于触发了多少次Action)
--------------------------------------------------------------------------------------------------------------------
一个DAG中可能有产生多种不同类型和功能的Task,会有不同阶段
DAGScheduler:将一个DAG切分成一到多个Stage,DAGScheduler切分的依据是Shuffle (宽依赖)
为什么要切分Stage?
一个复杂的业务逻辑(将多台机器上具有相同属性的数据聚合到一台机器上:shuffle)
如果有shuffle,那么久意味着前面阶段产生的结果后,才能执行下一个阶段,下一个阶段的计算要依赖上一个阶段的数据。
在同一个Stage中,会有多个算子,可以合并在一起,我们称其为pipeline(流水线:严格按照流程,顺序执行)
【Shuffle的定义】
Shuffle的含义是洗牌,将数据打散,父RDD一个分区中的数据如果给了RDD的多个分区(只有存在这个可能),就是shuffle
shuffle会有网络传输数据,但是有网络传输,并不意味着就是shuffle
【SparkCore】
1.什么是RDD
①弹性分布式数据集,RDD里面并不存储真正要计算的数据集,你对RDD进行操作,他会在Driver端转换成Task,下发到Executor计算分散在多台集 群上的数据
②RDD是一个代理,你对代理进行操作,他会生成一个Task帮你计算
③你操作这个代理,就像操作一个本地集合一样,不用关心任务调度,容错等
2.创建RDD
1)由一个已经存在的Scala集合创建。
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
2)由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等
val rdd2 = sc.textFile("hdfs://node1.edu360.cn:9000/words.txt")
3.RDD编程Api
1.Transformation
|
转换
|
含义
|
|
map(func)
|
返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成
|
|
filter(func)
|
返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成
|
|
flatMap(func)
|
类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素)
|
|
mapPartitions(func)
|
类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U]
|
|
mapPartitionsWithIndex(func)
|
类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是
(Int, Interator[T]) => Iterator[U]
|
|
sample(withReplacement, fraction, seed)
|
根据fraction指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed用于指定随机数生成器种子
|
|
union(otherDataset)
|
对源RDD和参数RDD求并集后返回一个新的RDD
|
|
intersection(otherDataset)
|
对源RDD和参数RDD求交集后返回一个新的RDD
|
|
distinct([numTasks]))
|
对源RDD进行去重后返回一个新的RDD
|
|
groupByKey([numTasks])
|
在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD
|
|
reduceByKey(func, [numTasks])
|
在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置
|
|
aggregateByKey(zeroValue)(seqOp, combOp, [numTasks])
|
|
|
sortByKey([ascending], [numTasks])
|
在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD
|
|
sortBy(func,[ascending], [numTasks])
|
与sortByKey类似,但是更灵活
|
|
join(otherDataset, [numTasks])
|
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD
|
|
cogroup(otherDataset, [numTasks])
|
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的RDD
|
|
cartesian(otherDataset)
|
笛卡尔积
|
|
pipe(command, [envVars])
|
|
|
coalesce(numPartitions)
|
|
|
repartition(numPartitions)
|
|
|
repartitionAndSortWithinPartitions(partitioner)
|
2.Action
|
动作
|
含义
|
|
reduce(func)
|
通过func函数聚集RDD中的所有元素,这个功能必须是课交换且可并联的
|
|
collect()
|
在驱动程序中,以数组的形式返回数据集的所有元素
|
|
count()
|
返回RDD的元素个数
|
|
first()
|
返回RDD的第一个元素(类似于take(1))
|
|
take(n)
|
返回一个由数据集的前n个元素组成的数组
|
|
takeSample(withReplacement,num, [seed])
|
返回一个数组,该数组由从数据集中随机采样的num个元素组成,可以选择是否用随机数替换不足的部分,seed用于指定随机数生成器种子
|
|
takeOrdered(n, [ordering])
|
|
|
saveAsTextFile(path)
|
将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本
|
|
saveAsSequenceFile(path)
|
将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。
|
|
saveAsObjectFile(path)
|
|
|
countByKey()
|
针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。
|
|
foreach(func)
|
在数据集的每一个元素上,运行函数func进行更新。
|
1 0.读取和存储 2 //从hdfs读取 3 val rdd = sc.textFile("hdfs://localhost:9000/wc") 4 rdd.saveAsTextFile("hdfs://localhost:9000/testjoin") 5 6 1.并集 注意(rdd1和rdd2类型要一致) 7 val rdd1 = sc.parallelize(List(1,2,3)) 8 val rdd2 = sc.parallelize(List(3,4,5)) 9 rdd1.union(rdd2) =>Array[Int] = Array(1, 2, 3, 3, 4, 5) 10 val rdd3 = rdd1.leftOuterJoin(rdd2) 11 val rdd3 = rdd1.rightOuterJoin(rdd2) 12 2.连接 13 val rdd1 = sc.parallelize(List(("tom",1),("jack",2),("song",3))) 14 val rdd2 = sc.parallelize(List(("tom",3),("jack",4),("tao",1),("tao",2))) 15 rdd1.join(rdd2).collect => Array[(String, (Int, Int))] = Array((tom,(1,3)), (jack,(2,4))) 16 17 18 3.groupByKey 19 rdd3.collect 20 res32: Array[(String, Int)] = Array((tom,1), (jack,2), (song,6), (tao,9), (tom,1), (kitty,4), (jack,3), (song,1)) 21 rdd3.groupByKey() 22 4.mapValues 遍历元祖的key进行运算 23 24 5.#cogroup(协分组,先把rdd1和rdd2中相同key的分到一组) 25 val rdd1 = sc.parallelize(List(("tom", 1), ("tom", 2), ("jerry", 3), ("kitty", 2))) 26 val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("shuke", 2))) 27 val rdd3 = rdd1.cogroup(rdd2) //rdd3.collect => Array((tom,(CompactBuffer(1, 2),CompactBuffer(1)))) 28 val rdd4 = rdd3.map(t=>(t._1, t._2._1.sum + t._2._2.sum)) 29 30 6.分区 31 默认最小分区数量是2,如果改为最小分区数量为1,那么分区数量为输入切片数量 sc.textFile("hdfs://localhost:9000/wc",1) 32 rdd.partitions.length 33 7.reduce (Action执行就有结果返回)聚合 34 val rdd = sc.parallelize(List(1,2,3,4,5)) 35 rdd.reduce(_+_) =>15 36 8.count (Action) 计算rdd中的数据个数 37 val rdd = sc.parallelize(List(1,2,3,4,5,6)) 38 rdd.count =>6 39 9.top(n) (Action) top(n) 函数会先将数据 排序(升序:从左向右 逐渐变大),然后从右向左取的 前n 个,tuple是 按照k 进行升序。 40 val rdd = sc.parallelize(List(3,6,5,7)) 41 rdd.top(2) =>Array(3,6) 42 10.take(n) (Action) take函数从左向取n个数据 43 44 11.rdd.takeOrdered(3) 该函数为 先升序,然后从左向右依次抽取3个。 45 46 12.rdd.mapPartitionsWithIndex 一次拿出一个分区(分区中并没有数据而是记录要读取哪些数据,真正生成的Task会读取多条数据),并且可以将编号取出来) 47 分区在Driver端 ,生成的Task在excutor端 48 功能:取分区中对应的数据时,还可以将分区的编号取出来,这样就可以知道数据是属于哪个分区的(哪个分区对应的Task) 49 rdd的map方法在executor中执行时是一条一条的将数据拿出来处理 50 51 val func = (index:Int,it:Iterator[Int])=>{ 52 it.map(e=>s"part:$index,ele:$e") 53 } 54 rdd.mapParitionsWithIndex(func) 55 56 13.rdd1.aggregate(0)(_+_,_+_) 注意是Action 57 局部聚合,在全局聚合,注意初始值,如果有三个分区,那么初始值需要局部加三次,全局聚合时再加一次 58 59 14.rdd1.aggregateByKey(0)(_+_) 每个分区内部Key相同的聚合值相加,再全局聚合,注意初始值只应用在局部
15.collect方法执行过程
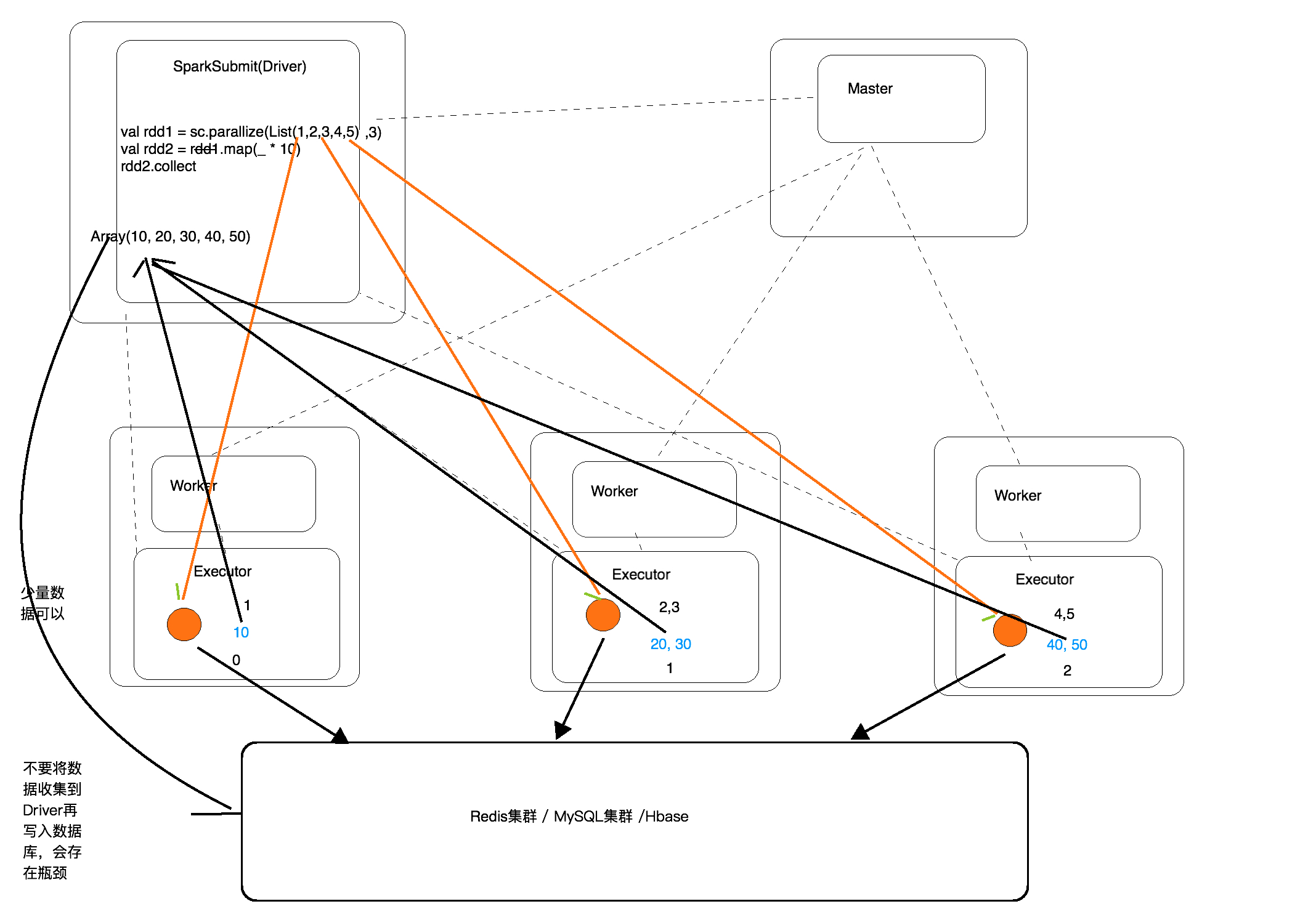
1 16.rdd.countByKey() 计算出key出现的次数 2 3 17.rdd.filterByRange("b","d") 对元祖中的key进行过滤 结果是包好 "b","c","d"key的元组 4 5 18.flatMapValues 对元祖中的values 进行flatMap, 再和原有的key组成元祖 6 7 19.reduceByKey(_+_)注意 可以使用默认分区器 reduceByKey(partitioner,_+_) partitioner为自定义分区器实现类 8 20.foldByKey(0)(_+_) 9 21.rdd1.aggregateByKey(0)(_+_) 10 每个分区内部Key相同的聚合值相加,再全局聚合,注意初始值只应用在局部 11 22.combineByKey 12 val rdd = sc.parallelize(List((1,"cat"), (2,"dog"), (1,"song"), (1,"tao"))) 13 23.foreach 和foreachPartition 14 foreach 是action 在excutor端执行,遍历每个元素进行操作 15 foreachPartition 遍历每个分区,每个分区是一个迭代器。 16 使用场景是将数据写入到数据库,应用foreachPartition比foreach更高效foreach拿一条数据建立一条连接,而foreachParttion每个分区对应一 条连接 17 24.自定义分区器 18 分区器的作用:决定了上游的数据到下游的哪个分区中 19 20 25.rdd.cache 懒加载,当执行Action算子时才会运行。缓存保存在Excutor端 21 注意:一个JAVA对象存在内存中要比对象存储空间大几倍,java对象存储不用序列化和反序列化,在读取数据时速度较快以空间换取时间 22 23 cache.unpersit(true) ---释放缓存 24 什么时候进行cache: 25 1.要求计算速度快 26 2.集群的资源要足够大 27 3.重要:cache的数据会多次出发Action 28 4.先进性过滤,然后将缩小范围的数据再cache到内存 29 26.persist(StorageLevel.MEMORY_ONLY) 持久化 ,cache底层调用 30 第一个参数:放到磁盘 31 第二个参数:放到内存 32 第三个参数:磁盘中的数据不是以java对象的方式保存 33 第四个参数:内存中的数据,以java对象的方式保存 34 第五个参数:在不同机器进行备份的个数 35 val MEMORY_AND_DISK = new StorageLevel(true, true, false, true,num) 36 OFF_HEAP:堆外内存(分布式内存存储系统) 37 27.什么时候做checkpoint 38 1.迭代计算,要求保证数据安全 39 2.对速度没有太高要求(跟cache到内存进行对比) 40 3.将中间结果保存到hdfs,防止数据丢失 41 //设置checkpoint目录,目录不存在会自动创建(分布式文件系统的目录,通常是hdfs的目录) 42 //经过复杂计算,得到中间结果 43 //将中间结果chekpoint到指定的hdfs目录 44 //后续的计算就可以使用前面checkpiint的数据 45 sc.setCheckpointDir("hdfs://localhost:9000/checkpointData") 46 rdd.check 47 28mapPartition和 foreachPartition区别 48 29.广播变量 49 //生成的广播变量引用在Driver端 50 val broadCastRef: Broadcast[Array[(Long, Long, String)]] = sparkSession.sparkContext.broadcast(rulesInDriver) 51 //从Excecutor中的广播引用获取值 52 val ipRulesInExecutor: Array[(Long, Long, String)] = broadCastRef.value 53 54 30.案例计算ip归属地 55 31.自定义排序 56 1.元祖比较,比较规则,先比第一个,再比第二个 57 2.定义类进行比较实现 58 32.操作关系型数据库 59 val jdbcRDD = new JdbcRDD( 60 sc, 61 getConn, 62 "SELECT * FROM access_log WHERE counts >=? AND counts <=?", 63 1, 64 1000, 65 2,//分区数量 66 rs =>{ 67 val province = rs.getString(1) 68 val counts = rs.getInt(2) 69 (province,counts)//结果集 70 } 71 )
3.RDD的依赖关系
RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。
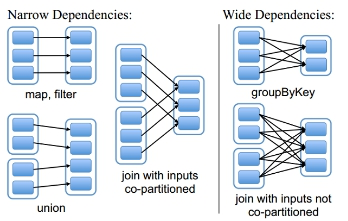
shuffle重要的依据:父RDD的一个分区的数据,要给子RDD的多个分区
①窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用
总结:窄依赖我们形象的比喻为独生子女
②宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition
总结:窄依赖我们形象的比喻为超生
4.分区
默认最小分区数量是2,如果改为最小分区数量为1,那么分区数量为输入切片数量 sc.textFile("hdfs://localhost:9000/wc",1)
5.缓存(去除重复计算)
RDD的转换操作都是在内存中进行,如果在某个环节失败, 导致某个RDD丢失, 我们根据血统, 向上回溯, 找到所依赖的RDD, 但是,内存中的转化是稍纵即逝, 是无法找到的。
解决办法:使用Cache如果我们将她的依赖RDD, 存到了cache中, 出现故障时, 可以根据血统依赖, 找到可能的最近的依赖RDD, 如:wordcount案例中, 我们将linesRDD进行了Cache, 失败的时候,不用再读取文件, 直接再cache中读取linesRDD, 这将省略了读取文件。节约了时间。
//cache是懒加载的
RDD.cache
RDD.count
RDD.unpersist()//释放缓存
6.CheckPoint
checkpoint在spark中主要有两块应用:一块是在spark core中对RDD做checkpoint,可以切断做checkpoint RDD的依赖关系,将RDD数据保存到可靠存储(如HDFS)以便数据恢复;另外一块是应用在spark streaming中,使用checkpoint用来保存DStreamGraph以及相关配置信息,以便在Driver崩溃重启的时候能够接着之前进度继续进行处理(如之前waiting batch的job会在重启后继续处理)。
Q1:RDD中的数据是什么时候写入的?是在rdd调用checkpoint方法时候吗?
首先看一下RDD中checkpoint方法,可以看到在该方法中是只是新建了一个ReliableRDDCheckpintData的对象,并没有做实际的写入工作。实际触发写入的时机是在runJob生成改RDD后,调用RDD的doCheckpoint方法来做的。
Q2:在做checkpoint的时候,具体写入了哪些数据到HDFS了?
在经历调用RDD.doCheckpoint → RDDCheckpintData.checkpoint → ReliableRDDCheckpintData.doCheckpoint → ReliableRDDCheckpintData.writeRDDToCheckpointDirectory后,在writeRDDToCheckpointDirectory方法中可以看到:将作为一个单独的任务(RunJob)将RDD中每个parition的数据依次写入到checkpoint目录(writePartitionToCheckpointFile),此外如果该RDD中的partitioner如果不为空,则也会将该对象序列化后存储到checkpoint目录。所以,在做checkpoint的时候,写入的hdfs中的数据主要包括:RDD中每个parition的实际数据,以及可能的partitioner对象(writePartitionerToCheckpointDir)。
Q3:在对RDD做完checkpoint以后,对做RDD的本省又做了哪些收尾工作?
在写完checkpoint数据到hdfs以后,将会调用rdd的markCheckpoined方法,主要斩断该rdd的对上游的依赖,以及将paritions置空等操作。
Q4:实际过程中,使用RDD做checkpoint的时候需要注意什么问题?
通过A1,A2可以知道,在RDD计算完毕后,会再次通过RunJob将每个partition数据保存到HDFS。这样RDD将会计算两次,所以为了避免此类情况,最好将RDD进行cache。即1.1中rdd的推荐使用方法如下:
sc.setCheckpointDir(checkpointDir.toString)
val rdd = sc.makeRDD(List(1,2,3,4,5,6))
rdd.cache()
rdd.checkpoint()
7.广播变量
当在Executor端用到了Driver变量,不使用广播变量,在每个Executor中有多少个task就有多少个Driver端变量副本。如果使用广播变量 在每个Executor端中只有一份Driver端的变量副本
注意:1).不能将RDD广播出去,可以将RDD的结果广播出去
2).广播变量在Driver定义,在Exector端不可改变,在Executor端不能定义
通过SparkContext的实例变量在Driver端广播:
val sc = new SparkContext(conf)
val broadcastRef = sc.broadcast(rulesDriver)
在Executor端进行获取广播变量:
broadcastRef.value
8.排序
1.非自定义排序
sortByKey:sortByKey对于key是单个元素排序很简单,如果key是元组如(X1,X2,X3.....),它会先按照X1排序,若X1相同,则在根据X2排序,依次类推
(1, 6, 3), (2, 3, 3), (1, 1, 2), (1, 3, 5), (2, 1, 2)
思路:将1,3元素组成为key,2元素为value
val array = Array((
1, 6, 3), (2, 3, 3), (1, 1, 2), (1, 3, 5), (2, 1, 2))
val rdd1 = sc.parallelize(array)
//设置元素(e1,e3)为key,value为原来的整体
val rdd2 = rdd1.map(f => ((f._1, f._3), f))
//利用sortByKey排序的对key的特性
val rdd3 = rdd2.sortByKey()
val rdd4 = rdd3.values.collect
sortBy为sortByKey加强版:
如上排序可一用sortBy: xxRDD.sortBy(f=>(f._1,f._3))
2.自定义排序
①把数据封装成类或者case class,然后类继承Ordered[类型] ,然后可以自定义排序规则。
如果是class,需要实现序列化特质,Serializable,如果是case class,可以不实现该序列化特质。
tpRDD.sortBy(tp=>Boy(tp._2,tp_.3))
class User(val name:String, val age:Int , val fv:Int) extends Order[User] with Serializable{
override def compare(that:User):Int={
}
}
②如果是case class,可以不实现该序列化特质。
tpRDD.sortBy(tp=>Boy(tp._2,tp_.3))
case class User(val name:String, val age:Int , val fv:Int) extends Order[User] {
override def compare(that:User):Int={
}
}
③定义一个样例类,不需要重写比较方法,tpRDD.sortBy(tp=>Boy(tp._2,tp_.3))
case class User(val name:String, val age:Int , val fv:Int)
④充分利用元祖的比较规则,先比较第一个,在比较第二个
tpRDD.sortBy(tp=>(-tp._3,tp._2))
9.自定义分区
Spark内部提供了
HashPartitioner和RangePartitioner两种分区策略
HashPartitioner分区弊端:可能导致每个分区中数据量的不均匀,极端情况下会导致某些分区拥有RDD的全部数据(HashCode为负数时,为了避免小于0,spark做了以下处理)。
HashPartitioner分区的原理:对于给定的key,计算其hashCode,并除于分区的个数取余,如果余数小于0,则用余数+分区的个数,最后返回的值就是这个key所属的分区ID。
RangePartitioner分区优势:尽量保证每个分区中数据量的均匀,而且分区与分区之间是有序的,一个分区中的元素肯定都是比另一个分区内的元素小或者大;
劣势: 但是分区内的元素是不能保证顺序的。简单的说就是将一定范围内的数映射到某一个分区内。
RangePartitioner作用:将一定范围内的数映射到某一个分区内,在实现中,分界的算法尤为重要。算法对应的函数是rangeBounds。
自定义分区:
①我们只需要扩展
Partitioner抽象类,然后实现里面的三个方法
②只有Key-Value类型的RDD才有分区的,非Key-Value类型的RDD分区的值是None
def numPartitions: Int:这个方法需要返回你想要创建分区的个数;
def getPartition(key: Any): Int:这个函数需要对输入的key做计算,然后返回该key的分区ID,范围一定是0到numPartitions-1;
equals():这个是Java标准的判断相等的函数,之所以要求用户实现这个函数是因为Spark内部会比较两个RDD的分区是否一样。
1 练习: 2 object GroupFavTeacher3 { 3 def main(args: Array[String]): Unit = { 4 val conf = new SparkConf().setAppName("GroupFavTeacher3").setMaster("local[4]") 5 val sc = new SparkContext(conf) 6 //读取数据 7 val lines = sc.textFile(args(0)) 8 //整理数据 9 val subjectTeacherAndOne: RDD[((String, String), Int)] = lines.map(line => { 10 val index = line.lastIndexOf("/") 11 val teacher = line.substring(index + 1) 12 val subject = line.substring(0, index) 13 ((subject, teacher), 1) 14 }) 15 //聚合数据 16 val reduced: RDD[((String, String), Int)] = subjectTeacherAndOne.reduceByKey(_+_) 17 //获取学科集合 18 val subjects: Array[String] = reduced.map(_._1._1).distinct().collect() 19 //调用自定义分区器,让一个学科一个分区,然后在每个分区中既每个学科即可进行排序取topn 20 val sbPartitioner = new SubjectPartitioner(subjects) 21 val subPartitioned: RDD[((String, String), Int)] = reduced.partitionBy(sbPartitioner) 22 //遍历每个分区 23 val sorted: RDD[((String, String), Int)] = subPartitioned.mapPartitions(it => { 24 it.toList.sortBy(x => x._2).reverse.take(3).iterator 25 }) 26 //获得结果 27 val result = sorted.collect() 28 println(result.toBuffer) 29 30 sc.stop() 31 } 32 } 33 34 35 class SubjectPartitioner(subs:Array[String]) extends Partitioner{ 36 //定义规则 37 val rules = new mutable.HashMap[String,Int]() 38 var num = 0 39 for(sb<-subs){ 40 rules(sb) = num 41 num +=1 42 } 43 override def numPartitions: Int = subs.length 44 override def getPartition(key: Any): Int = { 45 /** 46 * key RDD所映射的键值对数据的键 47 */ 48 val sub = key.asInstanceOf[(String,String)]._1 49 rules(sub) 50 } 51 }
10.RDD与mysql进行交互
1.数据存储到数据库,使用foreachPartition每次拿出一个分区进行数据存储,可以节省数据库连接打开关闭效率
1 rdd2.foreachPartition(it=>{ 2 val conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/sparktest","root","songtao0404") 3 val pstm: PreparedStatement = conn.prepareStatement("INSERT INTO t_user values(?,?,?)") 4 it.foreach(tp=>{ 5 pstm.setInt(1,tp._1.toInt) 6 pstm.setString(2,tp._2) 7 pstm.setInt(3,tp._3.toInt) 8 pstm.execute() 9 }) 10 if(pstm != null) pstm.close() 11 if(conn != null) conn.close() 12 13 })
2.从mysql读取数据
需要使用JdbcRDD来读取,JdbcRDD类如下:
1 class JdbcRDD[T: ClassTag]( 2 sc: SparkContext, 3 getConnection: () => Connection, //获得jdbc驱动函数 4 sql: String, 5 lowerBound: Long, //查询下界 6 upperBound: Long, //查询上界, 7 numPartitions: Int, //分区数 8 mapRow: (ResultSet) => T = JdbcRDD.resultSetToObjectArray _) //结果集 9 10 //读取数据 11 val getConnection =()=>{ 12 DriverManager.getConnection("jdbc:mysql://localhost:3306/sparktest","root","songtao0404") 13 } 14 val jdbcRdd = new JdbcRDD( 15 sc, 16 getConnection, 17 "select * from t_user where age >= ? and age<= ? ", 18 0, 19 90, 20 2, 21 r=>{ 22 val id = r.getInt(1) 23 val name = r.getString(2) 24 val age = r.getInt(3) 25 (id,name,age) 26 } 27 ) 28 println(jdbcRdd.collect().toBuffer)
【Spark-SQL】
1.spark 1.x SQL的基本用法(两种)
|
1.创建SparkContext
2.创建SQLContext
3.创建RDD
4.创建一个类,并定义类的成员变量
5.整理数据并关联class
6.将RDD转换成DataFrame(导入隐式转换)
7.将DataFrame注册成临时表
8.书写SQL(Transformation)
9.执行Action
| |
|
1.创建SparkContext
2.创建SQLContext
3.创建RDD
4.创建StructType(schema)
5.整理数据将数据跟Row关联
6.通过rowRDD和schema创建DataFrame
7.将DataFrame注册成临时表
8.书写SQL(Transformation)
9.执行Action
|
1 第一种代码: 2 object SQLDemo1 { 3 def main(args: Array[String]): Unit = { 4 //提交的这个程序可以连接到Spark集群 5 val conf = new SparkConf().setAppName("SQLDemo1").setMaster("local[4]") 6 //创建SparkSQL的连接(程序执行的入口) 7 val sc = new SparkContext(conf) 8 //SParkContext不能创建特殊的RDD( DataFrame ) 9 val sqlContext = new SQLContext(sc) 10 //创建特殊的RDD(DataFrame)就是有Schema信息的RDD 11 //先有一个普通的RDD然后关联上Schema进而转成DataFrame 12 13 val lines = sc.textFile("hdfs://localhost:9000/sparksql") 14 val boyRDD: RDD[Boy] = lines.map(line => { 15 val fields: Array[String] = line.split(",") 16 val id = fields(0).toLong 17 val name = fields(1) 18 val age = fields(2).toInt 19 val fv = fields(3).toDouble 20 Boy(id, name, age, fv) 21 }) 22 //该RDD装的是Boy类型的数据,但还是一个RDD 23 //将RDD转换成一个DataFrame 24 //导入隐士转换 25 import sqlContext.implicits._ 26 val bdf: DataFrame = boyRDD.toDF() 27 //编程DataFrame后就可以使用两种API进行编程了 28 //把DataFrame先注册临时表 29 bdf.registerTempTable("t_boy") 30 31 //书写sql 32 val result: DataFrame = sqlContext.sql("SELECT * FROM t_boy ORDER BY fv desc,age asc") 33 34 //查看结果(触发Action) 35 result.show() 36 sc.stop() 37 } 38 } 39 case class Boy(id:Long,name:String,age:Int,fv:Double) 40 第二种代码 41 object SQLDemo2 { 42 def main(args: Array[String]): Unit = { 43 //定义连接Spark集群 44 val conf = new SparkConf().setAppName("SQLDemo2").setMaster("local[4]") 45 //创建Spark入口 46 val sc = new SparkContext(conf) 47 48 //创建特殊的RDD DataFrame 49 val sqlContext = new SQLContext(sc) 50 51 val lines = sc.textFile("hdfs://localhost:9000/sparksql") 52 val boyRDD: RDD[Row] = lines.map(line => { 53 val fields: Array[String] = line.split(",") 54 val id = fields(0).toLong 55 val name = fields(1) 56 val age = fields(2).toInt 57 val fv = fields(3).toDouble 58 Row(id, name, age, fv) 59 }) 60 61 //定义Schema,不需要用样例类来约束数据了 62 val schema = StructType(List( 63 StructField("id", LongType, true), 64 StructField("name", StringType, true), 65 StructField("age", IntegerType, true), 66 StructField("fv", DoubleType, true) 67 )) 68 //创建DataFrame 69 val bdf: DataFrame = sqlContext.createDataFrame(boyRDD,schema) 70 71 //注册临时表 72 bdf.registerTempTable("t_boy") 73 74 //写sql 75 val result: DataFrame = sqlContext.sql("SELECT * FROM t_boy order by fv desc,age asc") 76 77 //查看结果,触发Action 78 result.show() 79 80 sc.stop() 81 } 82 }
2.spark 2.x SQL的基本用法
1.RDD,DataFrame,DataSet
RDD:RDD是Spark建立之初的核心API。RDD是不可变分布式弹性数据集,在Spark集群中可跨节点分区,并提供分布式low-level API来操作RDD,包括transformation和action。
DataFrame:与RDD相同之处,都是不可变分布式弹性数据集。不同之处在于,DataFrame的数据集都是按指定列存储,即结构化数据。类似于传统数据库中的表。
DataSet:在Spark2.0中,DataFrame API将会和Dataset API合并,统一数据处理API。
DataFrame是一种特殊的RDD,处理结构化数据集时需要使用DataFrame和DataSet。
2.创建SparkSession(SparkSession包含了SparkContext,和sqlContext兼容了老版本的调用)
val sparkSession = SparkSession
.builder()
.appName("Spark2SQL")
.master("local[4]")
.getOrCreate()
3.使用DataFrame api + SQL操作数据
1 object Spark2SQL { 2 def main(args: Array[String]): Unit = { 3 val sparkSession = SparkSession 4 .builder() 5 .appName("Spark2SQL") 6 .master("local[4]") 7 .getOrCreate() 8 9 //注意这里使用SparkSession.read读取的结果类型是 DataSet[String] 10 val lines: Dataset[String] = sparkSession.read.textFile("hdfs://localhost:9000/stu") 11 import sparkSession.implicits._ 12 val userDataSet: Dataset[User] = lines.map(line => { 13 val fields: Array[String] = line.split(",") 14 val id = fields(0).toInt 15 val name = fields(1) 16 val age = fields(2).toInt 17 User(id, name, age) 18 }) 19 //使用DataSet api 进行查询 20 val ds: Dataset[User] = userDataSet.where($"age" > 14) 21 println("使用DataSet api进行查询") 22 ds.show() 23 24 //使用SQL进行查询 25 //先注册成临时表 26 ds.createTempView("t_user") 27 val df: DataFrame = sparkSession.sql("select * from t_user where age > 14") 28 df.show() 29 30 } 31 } 32 33 /** 34 * 定义实体类信息 35 * @param id 36 * @param name 37 * @param age 38 */ 39 case class User(id:Int,name:String,age:Int)
4.使用DataSet API + SQL操作数据
1 object Spark2SQL2 { 2 def main(args: Array[String]): Unit = { 3 val sparkSession = SparkSession 4 .builder() 5 .appName("Spark2SQL2") 6 .master("local[4]") 7 .getOrCreate() 8 //注意这里使用的是SparkContext读取的结果数据类型是RDD[String] 9 val lines: RDD[String] = sparkSession.sparkContext.textFile("hdfs://localhost:9000/stu") 10 val userRDD: RDD[Row] = lines.map(line => { 11 val fields: Array[String] = line.split(",") 12 val id = fields(0).toInt 13 val name = fields(1) 14 val age = fields(2).toInt 15 Row(id, name, age) 16 }) 17 18 //构建Schema信息 19 val schema = StructType(List( 20 StructField("id", IntegerType, true), 21 StructField("name", StringType, true), 22 StructField("age", IntegerType, true) 23 )) 24 25 26 //创建DataFrame 27 val dataFrame: DataFrame = sparkSession.createDataFrame(userRDD,schema) 28 //使用DataFrameApi查询 29 import sparkSession.implicits._ 30 val df: DataFrame = dataFrame.where($"age" > 14) 31 println("使用DataFrame的API进行查询") 32 df.show() 33 34 //使用SQL 35 dataFrame.createTempView("t_user") 36 val sqldf: DataFrame = sparkSession.sql("select * from t_user where age > 14") 37 println("使用SQL进行查询") 38 sqldf.show() 39 40 sparkSession.stop() 41 } 42 }
5.sparkSession读数据库
1 //第一种 2 val sparkSession: SparkSession = SparkSession 3 .builder() 4 .appName("SparkSQL2JDBC") 5 .master("local[4]") 6 .getOrCreate() 7 val df: DataFrame = sparkSession.read.format("jdbc").options( 8 Map("url" -> "jdbc:mysql://localhost:3306/sparktest", 9 "driver" -> "com.mysql.jdbc.driver", 10 "user" -> "root", 11 "password" -> "songtao0404" 12 ) 13 ).load() 14 df.printSchema() 15 16 //第二种 17 val props = new Properties() 18 val url = "jdbc:mysql://localhost:3306/sparktest" 19 val tname = "t_user" 20 props.put("user","root") 21 props.put("password","songtao0404") 22 props.put("driver","com.mysql.jdbc.Driver") 23 val df2: DataFrame = sparkSession.read.format("jdbc").jdbc(url,tname,props) 24 df2.printSchema() 25 26 //第三种 27 val df3: DataFrame = sparkSession.read.jdbc(url,tname,props) 28 df3.printSchema()
6.写数据库
1 //第一种写,存在该表就直接报错(默认模式) 2 df1.write.jdbc(url,"t_user1",props) 3 //第二种写 4 filted.write.mode(SaveMode.Ignore).jdbc("jdbc:mysql://localhost:3306/bigdata","access_log1",props) 5 SaveMode.Ignore:表不存在,则创建,存在,则什么事都不做 6 SaveMode.ErrorIfExists: 7 SaveMode.Append:表存在情况下,在后面追加 8 SaveMode.Overwrite:存在该表情况下,覆盖里面数据 9
转载于:https://www.cnblogs.com/thesongtao/p/10642518.html
最后
以上就是知性凉面最近收集整理的关于Spark(1)-笔记整理的全部内容,更多相关Spark(1)-笔记整理内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复