一个简单而且有效的语法纠错分类模型
由于网上关于介绍英语语法纠错的论文介绍很少,而我本人喜欢学英语并且想做一个简单的雅思作文评分系统,所以来学习以下最近的文章。很巧的是这篇文章出自我一个非常喜欢的机构----流利说。
我主要是介绍这篇论文的方法。虽然这个方法不算最好,目前的the-state-of-art超过该方法约 15 % 15% 15%,但依然值得学习。
方法摘要
这篇论文提出了一个基于特征表示和分类的模型。该模型训练使用了大量没有人工标注的文本语料库。这个模型主要利用RNNs+Attention来表示目标单词的左右语境特征。结果显示该方法在公开的数据集CoNLL-2014上完成了 F 0.5 = 45.05 % F_{0.5}=45.05% F0.5=45.05%的结果。
引言
由于是第一次介绍改领域的论文,我个人就把论文里里提到的相关的研究也写一遍。
- CUUI分类模型,由Rozovskaya et al.(2014)提出,主要是组合了朴素贝叶斯、平均感知机和基于模式的学习。
- 2017年,wang et al.(2017)提出的使用神经网络抽取输入句子的上下文信息的深度上下文模型,而且输入不没有经过特征工程处理。
- 基于MT机器翻译,直接将错误的句子翻译成正确的句子
- 统计机器翻译模型(SMT) Moses(2016),该模型调查的了稀疏与稠密特征的交互、不同的优化算法和调参策略,最终取得很好的效果。
- 神经机器翻译模型(2018),使用多层卷积encoder-decoder神经网络以用来提取文本n-gram信息。
局限性
基于机器翻译的方法需要使用大量的平行数据,即我们需要大量的错误文本和其相对应的正确文本。
本论文方法
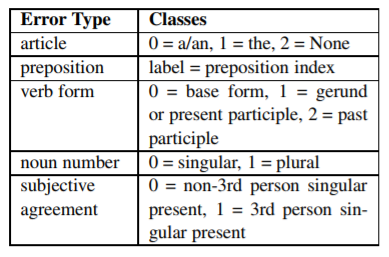
首先我们考虑五种类型的错误:冠词的使用、介词、动词形式、单复数、主谓一致。如表所示
- 冠词的使用,冠词错误有三种形式,0代表a/an,1代表the,2代表没有冠词即None。
- 介词错误,该错误是指冠词应该出现在名词短语前面(名词和形容词的组合)。介词类型考虑 i n , t o , o f , o n , b y , f o r , w i t h in, to, of, on, by, for, with in,to,of,on,by,for,with and a b o u t about about,当输入的句子包含这类词的时候,就会做前置的预测以用来的纠正错误。
- 动词形式,即时态错误。分类为三类
- 单复数,名词单复数用错,分为两类
- 主谓一致,主谓一致错误,分为两类
对于不同类型的错误,使用 stanford Corenlp工具包来定位需要被检测的目标单词,举个例子,
s
h
e
e
a
t
a
n
a
p
p
l
e
e
v
e
r
y
d
a
y
she eat an apple everyday
she eat an apple everyday,然后词性标注之后我们得到
(
P
R
P
V
B
P
D
T
N
N
N
N
)
(PRP VBP DT NN NN)
(PRP VBP DT NN NN),对于主谓一致错误(第三人称动词使用错误)的标签为 VBP即为eat。然后eat就为需要检测的目标单词。
该模型将利用改目标单词的上下文信息来预测这个目标单词位置上的单词,如果错误就替换该单词,例如对于eat,我们预测标签为1,那么相应的预测结果为eats, 然后替换它。
对于给定的句子,该方法将使用5个模型来检测5个对应错误。
模型架构
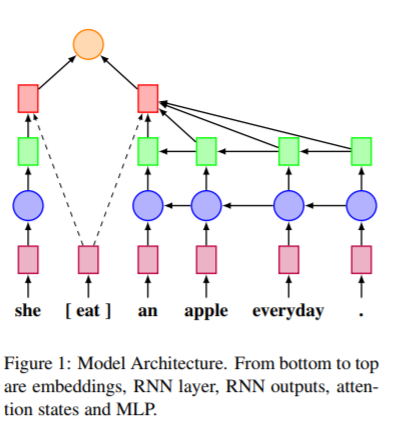
模型的第一层为一个embedding层,使用的是GloVe词向量,紧接着就使用双向GRU+attention对目标单词左右部分进行特征提取,该文章提出了两种不同attention方法(是否利用目标单词信息),为了理解方便我们给出相关符号的含义。
- 假设句子为
e
1
:
n
e_{1:n}
e1:n, 目标单词为
w
i
w_i
wi则,目标单词左边的部分为
l
o
1
:
i
−
1
lo_{1:i-1}
lo1:i−1,右边的部分为
l
o
i
+
1
:
n
lo_{i+1:n}
loi+1:n,
W
b
W_b
Wb是一个矩阵。然后在attention层我们有如下公式:
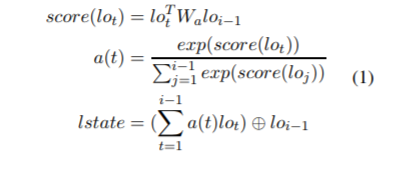
单词右边部分的attention方法与左边相同。只需要将 l o t T lo_t^{T} lotT和 l o i − 1 lo_{i-1} loi−1替换成 r o t T ro_t^{T} rotT和 l o i + 1 lo_{i+1} loi+1,attention层之后再经过线性层和MLP之后即得到预测结果。
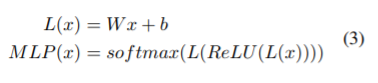
第二个模型的attention如下
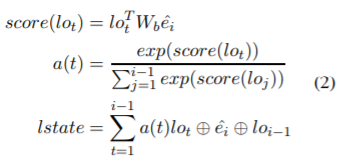
同样的有左右两部分,只是使用了包括目标单词。
最后,使用的损失函数为交叉熵,即
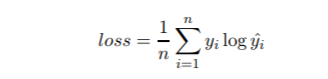
实验设置
- 使用wiki dump和COCA语料生成训练数据涵盖5种错误,所有单词都是小写的,整个词汇表的大小为 40000 40000 40000的常用单词,其他都设置为 u n k unk unk。
- 使用部分CoNLL-2014数据做为测试数据。
- 最终在CoNLL-2014上进行测试。
结果
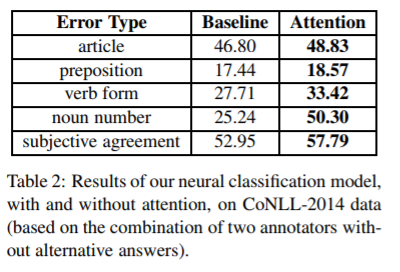
个人感受
本文介绍的方法基于单attention,相比他们2017年发表的文章来说性能但就模型而言,性能没有大的提升,但是加上公开的机器翻译模型的话性能提升了5%。最大的特点是需要的人工干预少,适合工业界。但是该文有一个地方没有说清楚。就是如何将预测出来的标签转化为正确的单词呢,例如,动词有不规则动词,和变形规则,改论文没有给出这个步骤的说明。之后我会尽量的复现这篇论文。
参考文献
论文链接
Alla Rozovskaya, Kai-Wei Chang, Mark Sammons,Dan Roth, and Nizar Habash. 2014. The illinoiscolumbia system in the conll-2014 shared task. InCoNLL Shared Task, pages 34–42.
Chuan Wang, RuoBing Li, and Hui Lin. 2017. Deep context model for grammatical error correction. InProc. 7th ISCA Workshop on Speech and Language Technology in Education, pages 167–171.
Marcin Junczys-Dowmunt and Roman Grundkiewicz. 2016. Phrase-based machine translation is state-ofthe-art for automatic grammatical error correction.arXiv preprint arXiv:1605.06353
Shamil Chollampatt and Hwee Tou Ng. 2018. A multilayer convolutional encoder-decoder neural network for grammatical error correction.
最后
以上就是仁爱火车最近收集整理的关于A Simple but Effective Classification Model for Grammatical Error Correction的全部内容,更多相关A内容请搜索靠谱客的其他文章。








发表评论 取消回复