摘要
在本文中,我们提出了仅使用Transformer编码器的简单有效的GEC序列标注器。我们的系统在综合数据上进行了预训练,然后分两个阶段进行了微调:首先是错误的语料库,其次是有错误和无错误的平行语料库的组合。我们设计了自定义的字符级别转换,以将输入字符映射到纠正后的目标。我们最好的单模型以及联合模型GEC标注器分别在CoNLL-2014测试集上F0.5达到65.3和66.5,在BEA-2019上F0.5达到72.4和73.6。模型的推理速度是基于Transformer的seq2seq GEC系统的10倍,且代码和经过训练的模型是公开可用的(github)。
1.介绍
基于神经机器翻译(NMT)的方法已成为语法错误校正(GEC)任务的首选方法。在这种表述中,错误句子对应于源语言,而无错误句子对应于目标语言。最近,基于Transformer的序列到序列(seq2seq)模型已在标准GEC基准上实现了最先进的性能。现在,研究重点已转移到生成合成数据上,以对基于Transformer-NMT的GEC系统进行预训练。基于NMT的GEC系统存在多个问题,这些问题使它们在现实世界中的部署不方便:(i)推理速度慢;(ii)对大量训练数据的需求;以及(iii)可解释性,从而使他们需要其他功能来解释更正,例如语法错误类型分类。
在本文中,我们通过将GEC任务从序列生成简化到序列标注来解决上述问题。我们的GEC序列标注系统包括三个训练阶段:对合成数据进行预训练,对有错误的平行语料库进行微调,最后对有错误和无错误的平行语料库的组合进行微调。
LaserTagger结合了BERT编码器和自回归Transformer解码器来预测三个主要的编辑操作:保留字符,删除字符以及在字符之前添加短语。相反,在我们的系统中,解码器是softmax层。PIE是一个迭代序列标注GEC系统,可预测字符级编辑操作。尽管他们的方法与我们的方法最为相似,但我们的工作与他们的方法有所不同,如下所示:
- 我们开发自定义的g-transformations:通过字符级编辑以执行语法错误纠正。预测g-transformations而不是常规字符可改善我们的GEC序列标签系统的通用性。
- 我们将微调阶段分为两个阶段:对仅错误的句子进行微调,然后对包含有错误和无错误句子的小型高质量数据集进行进一步的微调。
- 通过在我们的GEC序列标注系统中加入预训练的Transformer编码器,我们可以实现卓越的性能。在我们的实验中,XLNet和RoBERTa的编码器的性能优于其他三个Transformer编码器(ALBERT,BERT和GPT-2)。
2.数据集
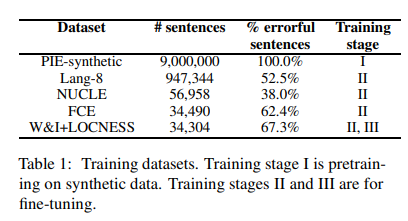
表1描述了用于不同训练阶段的数据集的详细信息。
Synthetic data。对于预训练阶段I,我们使用9M平行句子,其中包含综合生成的语法错误。
Training data。我们使用以下数据集进行第二和第三阶段的微调:新加坡国立大学学习者英语语料库(NUCLE),Lang-8学习者英语语料库(Lang-8),FCE数据集,剑桥学习者语料库和Write&Improvement + LOCNESS语料库的公开可用部分。
Evaluation data。我们报告了官方
M
2
M^2
M2评分器评估的CoNLL2014测试集的结果,以及ERRANT评估的BEA-2019 dev和测试集的结果。
3.字符级转换
我们开发了自定义字符级别的转换
T
(
x
i
)
T(x_i)
T(xi),以通过将目标文本应用于源字符
(
x
1
.
.
.
x
N
)
(x_1...x_N)
(x1...xN)来恢复目标文本。对于最常见的语法错误,例如拼写,名词数量,主语-动词一致和动词形式,通过限制有限的输出词汇数,Transformations增加了语法错误纠正的覆盖范围。
对应于我们默认标签词汇量=5000的编辑空间包括4971个
b
a
s
i
c
−
t
r
a
n
s
f
o
r
m
a
t
i
o
n
s
basic-transformations
basic−transformations(字符无关的KEEP和DELETE,字符相关的1167个APPEND,3802个REPLACE操作)和29个字符无关的
g
−
t
r
a
n
s
f
o
r
m
a
t
i
o
n
g-transformation
g−transformation。
(1)basic-transformations
b
a
s
i
c
−
t
r
a
n
s
f
o
r
m
a
t
i
o
n
s
basic-transformations
basic−transformations执行最常见的字符级别编辑操作,例如:保持当前字符不变(标签$KEEP),删除当前字符(标签$DELETE),在当前字符
x
i
x_i
xi旁边附加新字符
t
1
t_1
t1(标签$APPEND
t
1
t_1
t1) 或者将当前字符
x
i
x_i
xi替换为另一个字符
t
2
t_2
t2(标记$REPLACE
t
2
t_2
t2)。
(2)g-transformations
g
−
t
r
a
n
s
f
o
r
m
a
t
i
o
n
s
g-transformations
g−transformations执行特定于任务的操作,例如:更改当前字符的大小写(
C
A
S
E
CASE
CASE标签),将当前字符和下一个字符合并为一个(
M
E
R
G
E
MERGE
MERGE标签),并将当前字符拆分为两个新字符(
S
P
L
I
T
SPLIT
SPLIT标签) 。此外,使用NOUN NUMBER和VERB FORM转换中的标记对字符的语法属性进行编码。例如,这些转换包括将单数名词转换为复数,反之亦然,甚至更改规则/不规则动词的形式以表示不同的数目或时态。
要获得VERB FORM标签的转换后缀,我们使用动词共轭字典。为了方便起见,已将其转换为以下格式:
t
o
k
e
n
0
_
t
o
k
e
n
1
:
t
a
g
0
_
t
a
g
1
token_0_token_1:tag_0_tag_1
token0_token1:tag0_tag1(例如
g
o
_
g
o
e
s
:
V
B
_
V
B
Z
go_goes:VB_VBZ
go_goes:VB_VBZ)。这意味着存在从
w
o
r
d
0
word_0
word0和
w
o
r
d
1
word_1
word1到相应标签的过渡。过渡是单向的,因此,如果存在反向过渡,则会单独显示。
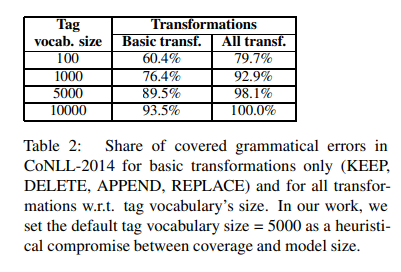
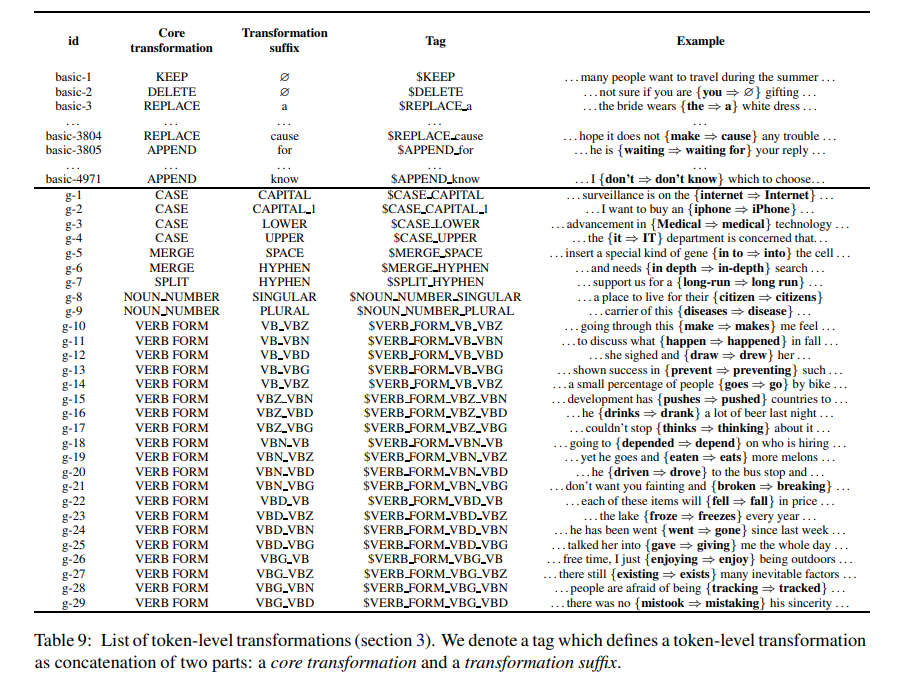
表2中对我们的字符级转换的覆盖能力进行了实验比较。附录9中列出了所有带有示例的转换类型。
(3)数据预处理

要将任务作为序列标注问题进行处理,我们需要将每个目标句子从训练/评估集中转换为标记序列,其中每个标记都映射到单个源字符。下面是表3中针对颜色编码的句子对的三步预处理算法的简要说明:
Step 1).将源句子中的每个字符映射到目标句子中的字符的子序列。
[
A
↦
A
]
,
[
t
e
n
↦
t
e
n
,
−
]
,
[
y
e
a
r
s
↦
y
e
a
r
,
−
]
,
[
o
l
d
↦
o
l
d
]
,
[
g
o
↦
g
o
e
s
,
t
o
]
,
[
s
c
h
o
o
l
↦
s
c
h
o
o
l
,
.
]
[Amapsto A],[tenmapsto ten,-],[yearsmapsto year,-],[oldmapsto old],[gomapsto goes,to],[schoolmapsto school,.]
[A↦A],[ten↦ten,−],[years↦year,−],[old↦old],[go↦goes,to],[school↦school,.]
为此,我们首先检测字符的最小范围,该最小距离定义了源字符
(
x
1
.
.
.
x
N
)
(x_1...x_N)
(x1...xN)与目标字符
(
y
1
.
.
.
y
M
)
(y_1... y_M)
(y1...yM)之间的差异。因此,这个范围是一对选定的源字符和对应的目标字符。我们无法使用基于范围的对齐方式,因为我们需要在字符级别获取标签。因此,对于每个源令牌
x
i
,
1
≤
i
≤
N
x_i,1≤i≤N
xi,1≤i≤N,我们通过最小化修改后的Levenshtein距离(考虑到成功的g-transformation等于零距离)来搜索目标字符的最适合子序列
Υ
i
=
(
y
j
1
.
.
.
y
j
2
)
,
1
≤
j
1
≤
j
2
≤
M
mathcal Υ_i=(y_{j_1}...y_{j_2}),1le j_1 le j_2le M
Υi=(yj1...yj2),1≤j1≤j2≤M。
Step 2).对于列表中的每个映射,我们需要找到将源字符转换为目标子序列的字符级别转换:
[
A
↦
A
]
[Amapsto A]
[A↦A]:$KEEP,
[
t
e
n
↦
t
e
n
,
−
]
[tenmapsto ten,-]
[ten↦ten,−]:$KEEP,$MERGE_HYPHEN,
[
y
e
a
r
s
↦
y
e
a
r
,
−
]
[yearsmapsto year,- ]
[years↦year,−]:$NOUN_NUMBER_SINGULAR,$MERGE_HYPHEN,
[
o
l
d
↦
o
l
d
]
[oldmapsto old]
[old↦old]:$KEEP,
[
g
o
↦
g
o
e
s
,
t
o
]
[gomapsto goes,to]
[go↦goes,to]:$VERB_FORM_VB_VBZ,$APPEND_to,
[
s
c
h
o
o
l
↦
s
c
h
o
o
l
,
.
]
[schoolmapsto school,.]
[school↦school,.]:$KEEP,$ APPEND_{.}。
Step 3).每个源字符仅保留一个转换:
A
⇔
A⇔
A⇔$KEEP,
t
e
n
⇔
ten⇔
ten⇔$MERGE_HYPHEN,
y
e
a
r
s
⇔
years⇔
years⇔$NOUN_NUMBER_SINGULAR,
o
l
d
⇔
old⇔
old⇔$KEEP,
g
o
⇔
go⇔
go⇔$NOUN_NUMBER_SINGULAR,
s
c
h
o
o
l
⇔
school⇔
school⇔$APPEND_{.}。
迭代序列标记方法增加了一个约束,因为我们只能为每个字符使用单个标记。如果有多个转换,我们将采用第一个不是$KEEP标记的转换。有关更多详细信息,请参见我们github repository中的预处理脚本。
4.模型结构
我们的GEC序列标注模型是一种编码器,由预训练的BERT型transformer组成,堆叠有两个线性层,顶部有softmax层。我们始终使用预训练transformer的Base配置。Tokenization取决于特定transformer的设计:BPE被用于RoBERTa,BERT使用WordPiece,XLNet则使用SentencePiece。为了在字符级别处理信息,我们从编码器表示中获取每个字符的第一个子词,然后将其传递到后续的线性层,这些线性层分别负责错误检测和错误标记。
5.迭代序列标记方法
为了纠正错误文本,对于源序列
(
x
1
.
.
.
x
N
)
(x_1...x_N)
(x1...xN)中的每个输入字符
x
i
,
1
≤
i
≤
N
x_i,1≤i≤N
xi,1≤i≤N,我们预测第3节中描述的标记编码的字符级变换
T
(
x
i
)
T(x_i)
T(xi)。然后将该变换应用于句子以获取修该后的句子。
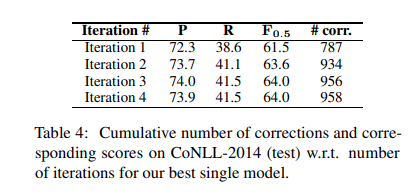
由于句子中的某些更正可能依赖于其他更正,因此仅应用GEC序列标记器一次可能不足以完全纠正该句子。因此,我们使用(Awasthi et al., 2019)中的迭代纠正方法:我们使用GEC序列标记器标记现在已修改的序列,并在新标记上应用相应的转换,从而进一步改变句子(请参见表3中的示例)。通常,校正的次数会随着每次连续的迭代而减少,并且大多数校正是在前两个迭代中完成的(表4)。因此通过限制迭代次数可加快总体流程,同时权衡定性性能。
A.附录
最后
以上就是忧郁背包最近收集整理的关于GECToR–Grammatical Error Correction: Tag, Not Rewrite翻译摘要1.介绍2.数据集3.字符级转换4.模型结构5.迭代序列标记方法A.附录的全部内容,更多相关GECToR–Grammatical内容请搜索靠谱客的其他文章。








发表评论 取消回复