
文章目录
- 4.1 从数据中学习
- 4.2 损失函数
- a.均方误差
- b.交叉熵误差
- c.mini-batch学习
- d.为何要设定损失函数
- 4.3 梯度
- 梯度法
- 4.4 神经网络的学习步骤
- 开篇介绍:《深度学习入门-基于Python的理论与实现》书籍介绍
- 第一章:《深度学习入门-基于Python的理论与实现》第一章带读
- 第二章:《深度学习入门-基于Python的理论与实现》第二章带读 – 感知机
- 第三章:深度学习入门-基于Python的理论与实现》第三章带读 – 神经网络
上一章我们介绍了什么是神经网络,本章我们接着介绍神经网络的学习,这里的“学习”是指从训练数据中“自动”获取最优权重参数的过程。
4.1 从数据中学习
- 数据驱动
通常要解决某个问题时,人们习惯以自己的经验和直觉来分析问题找出规律,然后反复试验推进。机器学习在前期收集问题的各项特征数据,用模型从数据中发现答案,争取避免人为介入。深度学习在数据收集上(比如选/不选哪些特征的数据)较之机器学习更能避免人为介入。
举例来说,我们如何能实现从一堆手写数字中区别出是不是“5”呢?
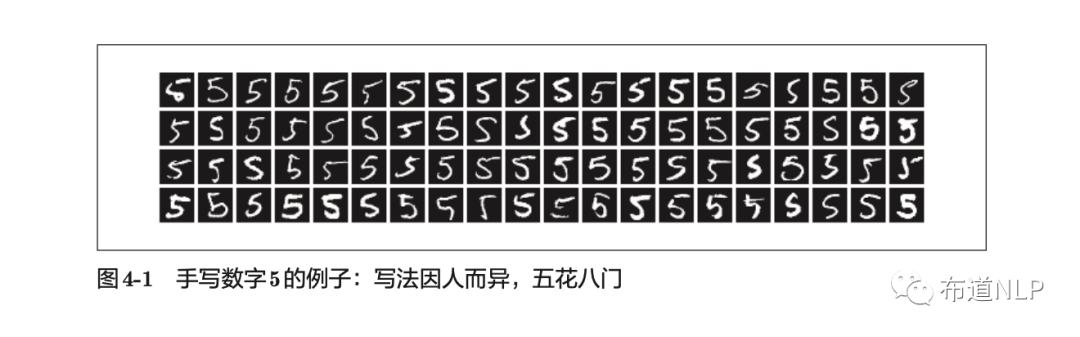
如果让我们自己设计一个程序能将“5”正确分类,会发现虽然人可以很容易识别出“5”,但是却很难说明自己是基于何种特征规律识别出的。而且从图4-1可以看到,每个人各有自己的书写习惯,要确定其中的规律非常困难。
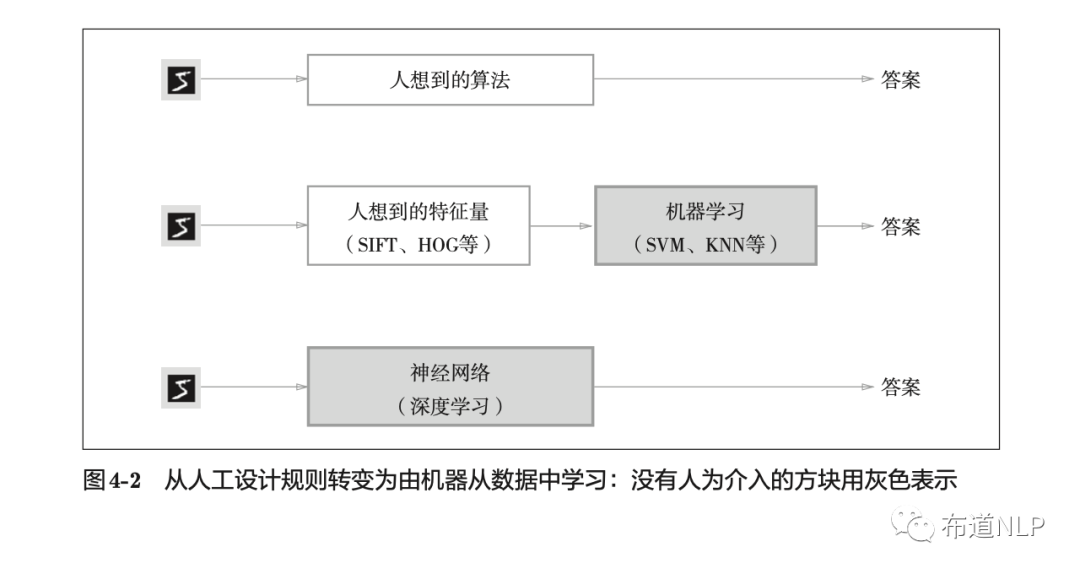
如果我们引入机器学习技术似乎可以实现是否是“5”的分类问题。先从图像中提取特征量(SIFT、SURF和HOG等),用向量的形式表示。然后使用机器学习中的SVM、KNN等分类器对这些特征向量进行学习,获得分类器的最优参数。只是,我们需要注意的是,针对不同的问题,合适的特征量提取方式和机器学习模型的选择都需要不同的人工考量的参与。
除了上面介绍的两种方法外,这里如果用深度学习方法的话,上面第二种方法中的特征量的设计可以省去人工的参与而完全由机器来学习。三种方法的比较,如图4-2所示。
4.2 损失函数
神经网络的学习目标是寻找权重参数的最优值,在学习的过程需要有数值类指标来表示当前的状态。通常,我们用损失函数来作为这个指标。损失函数表示神经网络当前的性能与最优目标的差距,一般用均方误差和交叉熵误差等。
a.均方误差
公式如下:
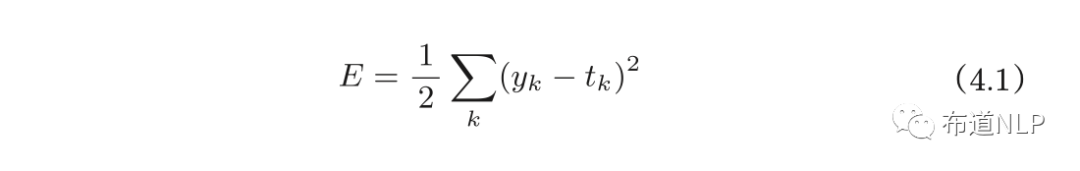
yk表示神经网络的输出,tk表示训练数据,k表示数据的维度。
b.交叉熵误差
公式如下:
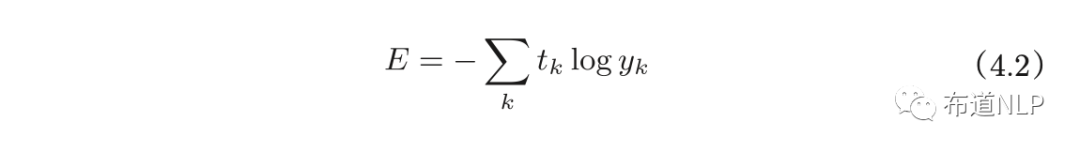
log表示以e为底数的自然对数(log e)。yk是神经网络的输出,tk是正确解标签。并且,t k中只有正确解标签的索引为1,其他均为0(one-hot表示)。因此,式(4.2)实际上只计算对应正确解标签的输出的自然对数。
c.mini-batch学习
不管是机器学习还是神经网络学习,在遇到要处理的训练数据量在万级以上的时候,如果以全部数据为对象求损失函数的和,计算过程太长。因此,从全部数据中随机选出多个小批量数据,作为全部数据的近似,然后对这几个批次的数据进行训练,这种方式称为mini-batch学习。
d.为何要设定损失函数
以手写数字识别任务为例,学习的目标是获得使识别精度尽可能高的神经网络,为什么不直接把识别精度作为指标,而是要另外引入损失函数呢?这里需要考虑导数的连续性问题。假设某个神经网络正确识别出了100个训练数据中的32个,识别精度为32%,以识别精度为指标的话,微调参数,识别精度不会有反应,即使有反应也是不连续地、突然地变化(类似于阶跃函数)。在参数变化而精度不变的阶段,参数的导数为0,神经网络无法进行学习。
在神经网络的学习中,寻找最优参数(权重和偏置)时,要寻找使损失函数的值尽可能小的参数。为此需要计算参数的导数,并以这个导数为指引,逐步更新参数的值。
4.3 梯度
由全部变量的偏导数汇总而成的向量称为梯度。
梯度法
神经网络寻求的最优参数(权重和偏置)是指损失函数取最小值时的参数。
虽然梯度的方向并不一定指向最小值(可能指向局部极小值或者鞍点),但是沿着梯度方向能够最大限度地减小损失函数的值,所以以梯度信息为线索,作为最小值位置的寻找方向。函数的取值沿着梯度方向前进一定距离后重新计算梯度,再沿着新梯度方向前进的过程就是梯度法。
4.4 神经网络的学习步骤
前提
神经网络存在合适的权重和偏置,调整权重和偏置以便拟合训练数据的过程称为“学习”。神经网络的学习分成下面4个步骤。
-
步骤1(mini-batch)
- 从训练数据中随机选出一部分数据,这部分数据称为mini-batch。我们的目标是减小mini-batch的损失函数的值。
-
步骤2(计算梯度)
- 为了减小mini-batch的损失函数的值,需要求出各个权重参数的梯度。梯度表示损失函数的值减小最多的方向。
-
步骤3(更新参数)
- 将权重参数沿梯度方向进行微小更新。
-
步骤4(重复)
- 重复步骤1、步骤2、步骤3。
书籍下载链接:https://pan.baidu.com/s/1goHhf2GZt0gxxbLXa42CmA
密码: 4vi2
欢迎关注微信公众号【布道NLP】获取更多AI相关知识。

最后
以上就是虚幻鸡翅最近收集整理的关于《深度学习入门-基于Python的理论与实现》第四章带读 – 神经网络的学习的全部内容,更多相关《深度学习入门-基于Python的理论与实现》第四章带读内容请搜索靠谱客的其他文章。








发表评论 取消回复