目录
第3章 神经网络
3.1 从感知机到神经网络
3.1.1 神经网络的例子
3.1.2 复习感知机
3.1.3 激活函数登场
3.2 激活函数
3.2.1 sigmoid函数
3.2.2 阶跃函数的实现
3.2.4 sigmoid函数的实现
3.2.5 sigmoid函数和阶跃函数的比较
3.2.6 非线性函数
3.2.7 ReLU函数
3.3 多维数组的运算
3.3.1 多维数组
3.3.2 矩阵乘法
3.3.3 神经网络的内积
3.4 3层神经网络的实现
3.4.1 符号确认
3.4.2 各层间信号传递的实现
3.4.3 代码实现小结
3.5 输出层的设计
3.5.1 恒等函数和softmax函数
3.5.2 实现softmax函数时的注意事项
3.5.3 softmax函数的特征
3.5.4 输出层的神经元数量
3.6 手写数字的识别
3.6.1 MINIST数据集
3.6.2 神经网络的推理处理
3.6.3 批处理
3.7 小结
第3章 神经网络
神经网络的一个重要性质是它可以自动地从数据中学习到合适的权重参数。
3.1 从感知机到神经网络
3.1.1 神经网络的例子
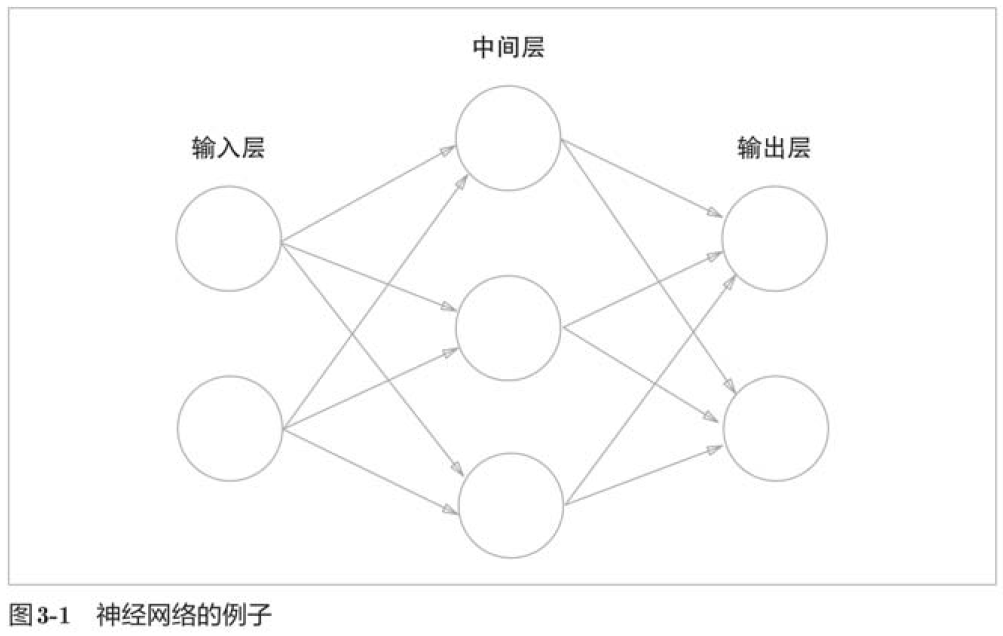
我们把最左边的一列称为输入层,最右边的一列称为输出层,中间的一列称为中间层。中间层有时候也称为“隐藏层”。“隐藏”一词的意思是,隐藏层的神经元(和输入层、输出层)不同肉眼看不见。
3.1.2 复习感知机
![]()
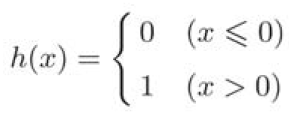
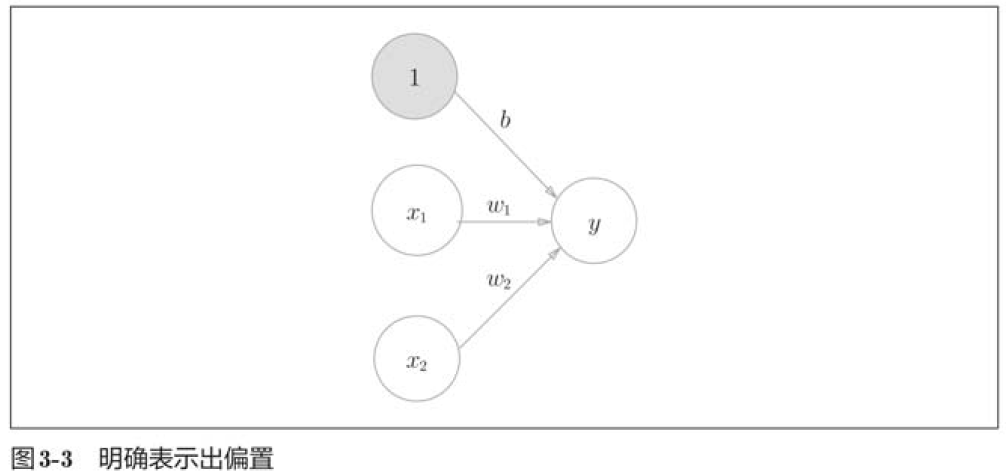
3.1.3 激活函数登场
刚才的h(x)函数会将输入信号的总和转换为输出信号,这种函数一般称为激活函数。如“激活”一词所示,激活函数的作用在于决定如何来激活输入信号的总和。
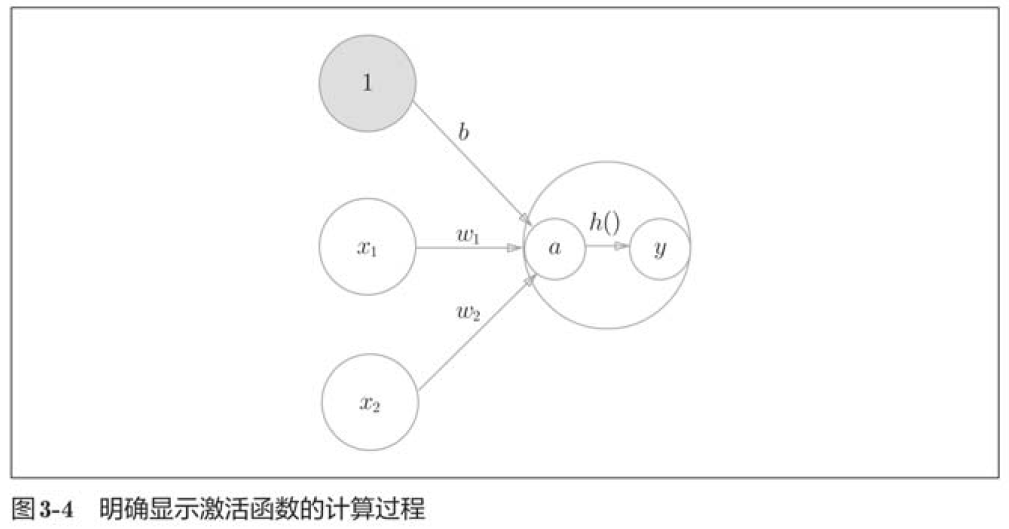
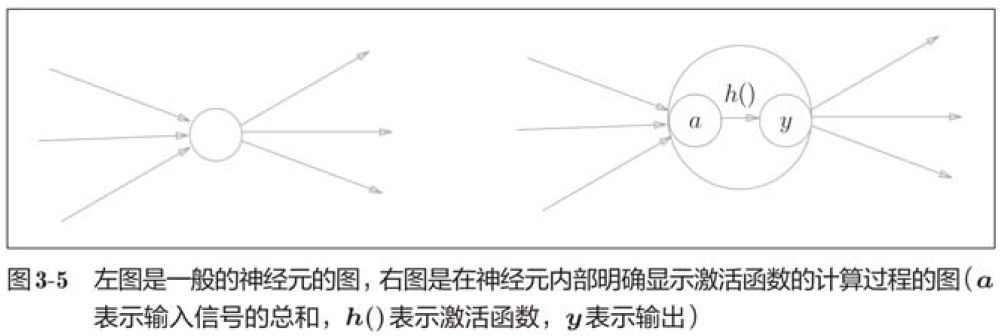
激活函数是连接感知机和神经网络的桥梁。一般而言“朴素感知机”是指单层网络,指的是激活函数使用了阶跃函数的模型。“多层感知机”是指神经网络,即使用sigmoid函数等平滑的激活函数的多层网络。
3.2 激活函数
在感知机中,激活函数以阈值为界,一旦输入超过阈值,就切换输出,这样的函数称为“阶跃函数”。如果感知机使用其他函数作为激活函数的话会怎么样呢?实际上,如果将激活函数从阶跃函数换成其他函数,就可以进入神经网络的世界了。
3.2.1 sigmoid函数
神经网络中经常使用的一个激活函数就是sigmoid函数。
![]()
式中的![]() 表示
表示![]() 的意思。
的意思。
神经网络中用sigmoid函数作为激活函数,进行信号的转换,转换后信号被传送给下一个神经元。感知机和神经网络的主要区别就在于这个激活函数,其他方面,比如神经元的多层连接的构造、信号的传递方法等,基本上和感知机是一样的。
3.2.2 阶跃函数的实现
import numpy as np
import matplotlib.pylab as plt
def step_function(x):
return np.array(x > 0, dtype=np.int64)
x = np.arange(-5.0, 5.0, 0.1)
y = step_function(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.show()
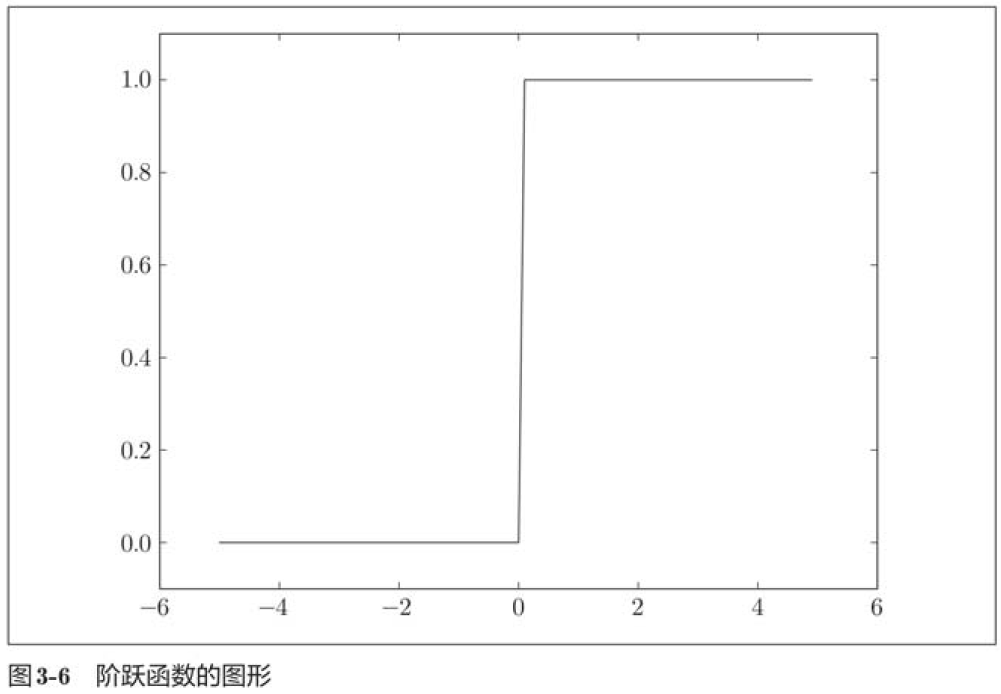
如图所示,阶跃函数以0为界,输出从0切换为1(或者从1切换为0)。它的值呈阶梯式变化,所以称为阶跃函数。
3.2.4 sigmoid函数的实现
import numpy as np
import matplotlib.pylab as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.show()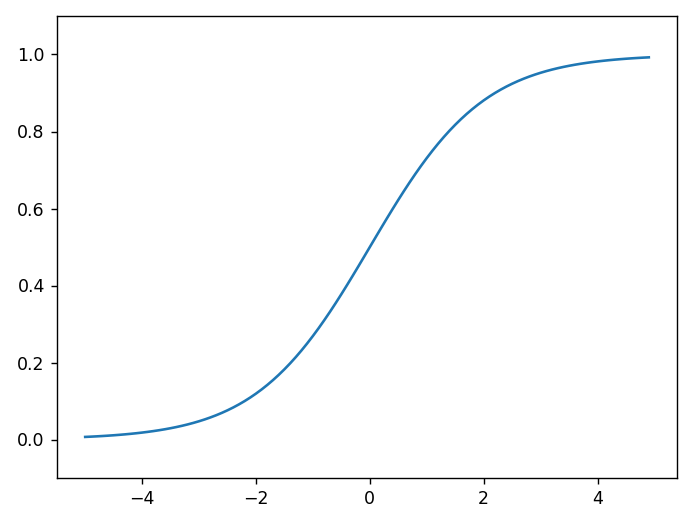
3.2.5 sigmoid函数和阶跃函数的比较
首先注意到的是“平滑性”的不同。sigmoid函数是一条平滑的曲线,输出随着输入发生连续性的变化,而阶跃函数以0为界,输出发生急剧性的变化。sigmoid函数的平滑性对神经网路的学习具有重要意义。
另一个不同点是,相对于阶跃函数只能返回0或1,sigmoid函数可以返回0.731....等实数。也就是说,感知机中神经元之间流动的是0或1的二元信号,而神经网络中流动的是连续的的实数值信号。
阶跃函数和sigmoid函数虽然在平滑性上有差异,但是如果从宏观视角看,可以发现二者具有相似的形状。实际上,二者的结构均是“输入小时,输出接近0(为0);随着输入增大,输出向1靠近(变成1)”。也就是说,当输入信号为重要信息时,阶跃函数和sigmoid函数都会输出较大的值;当输入信号为不重要的信息时,二者都输出较小的值。还有一个共同点是,不管输入信号有多小,或者有多大,输出信号的值都在0到1之间。
3.2.6 非线性函数
阶跃函数核sigmoid函数还有其他共同点,就是两者均为非线性函数,sigmoid函数是一条曲线,阶跃函数是一条像阶梯一样的折线,两者都属于非线性的函数。
神经网络的激活函数必须使用非线性函数,换句话说,激活函数不能使用线性函数。线性函数的问题在于,不管如何加深层数,总是存在与之等效的“无隐藏层的神经网络”。
3.2.7 ReLU函数
ReLU函数在输入大于0时,直接输出该值;在输入小于等于0时,输出0。
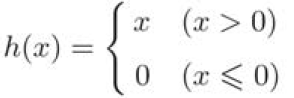
import numpy as np
import matplotlib.pylab as plt
def relu(x):
return np.maximum(0, x)
x = np.arange(-0.5, 0.5, 0.1)
y = relu(x)
plt.plot(x, y)
plt.ylim(-0.1, 0.6)
plt.show()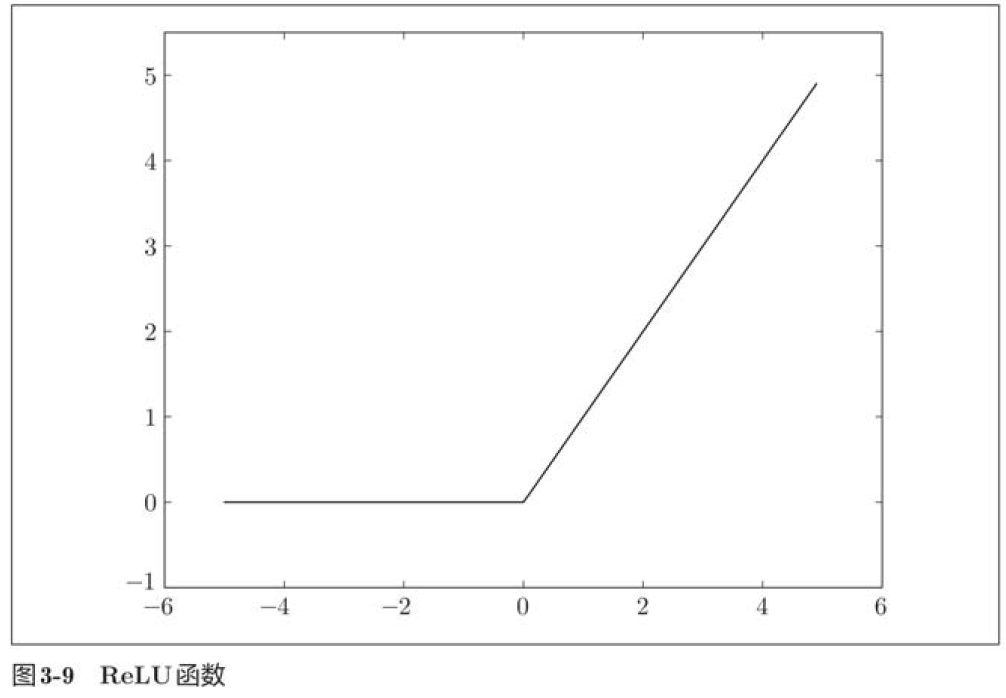
3.3 多维数组的运算
3.3.1 多维数组
第一个维度对应第0维,第二个维度对应第1维(Python的索引从0开始)。二维数组也称为矩阵,数组的横向排列称为行,纵向排列称为列。
3.3.2 矩阵乘法
import numpy as np
A = np.array([[1, 2], [3, 4]])
print(A.shape)
B = np.array([[5, 6], [7, 8]])
print(B.shape)
print(np.dot(A, B))
A = np.array([[1, 2, 3], [4, 5, 6]])
print(A.shape)
B = np.array([[1, 2], [3, 4], [5, 6]])
print(B.shape)
print(np.dot(A, B))(2, 2)
(2, 2)
[[19 22]
[43 50]]
(2, 3)
(3, 2)
[[22 28]
[49 64]]3.3.3 神经网络的内积
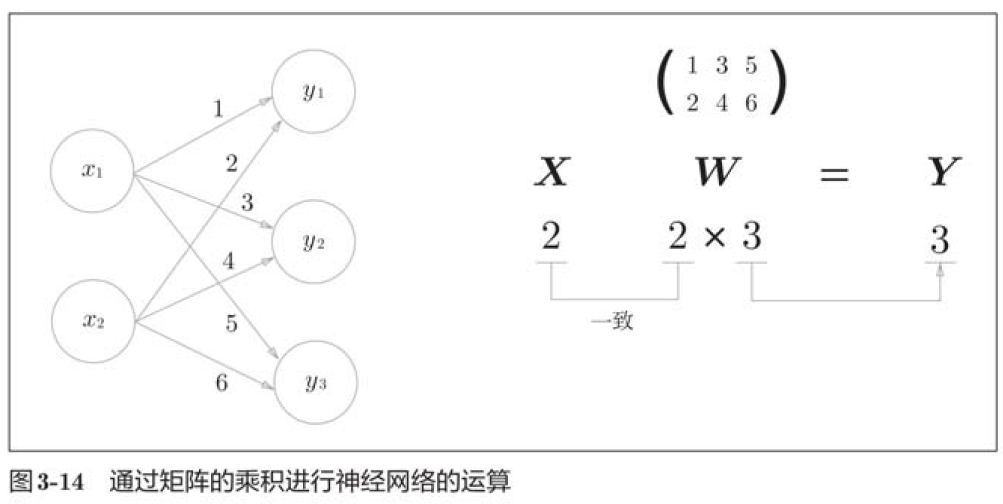
3.4 3层神经网络的实现
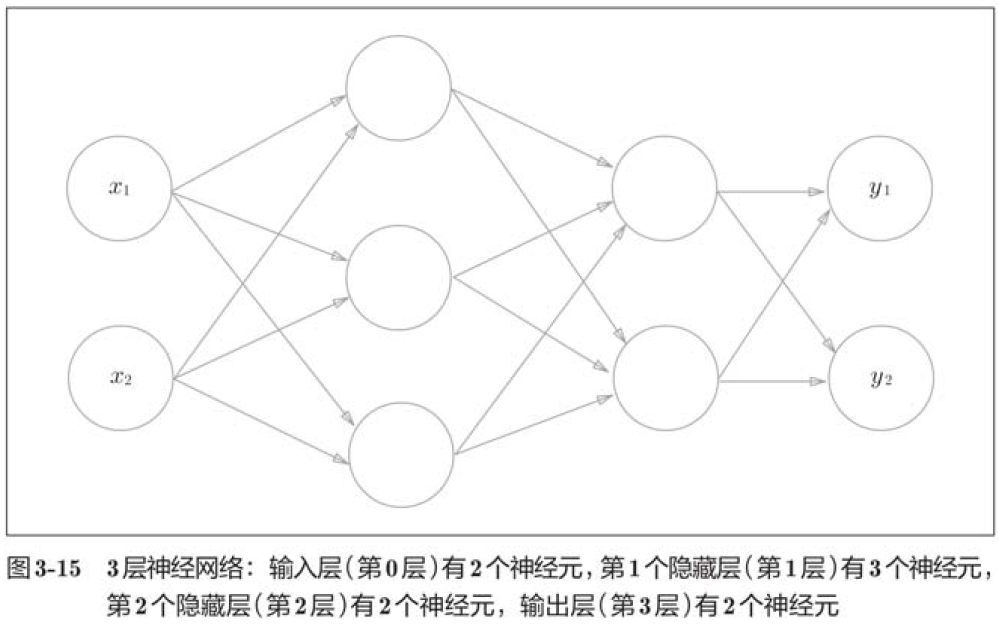
3.4.1 符号确认
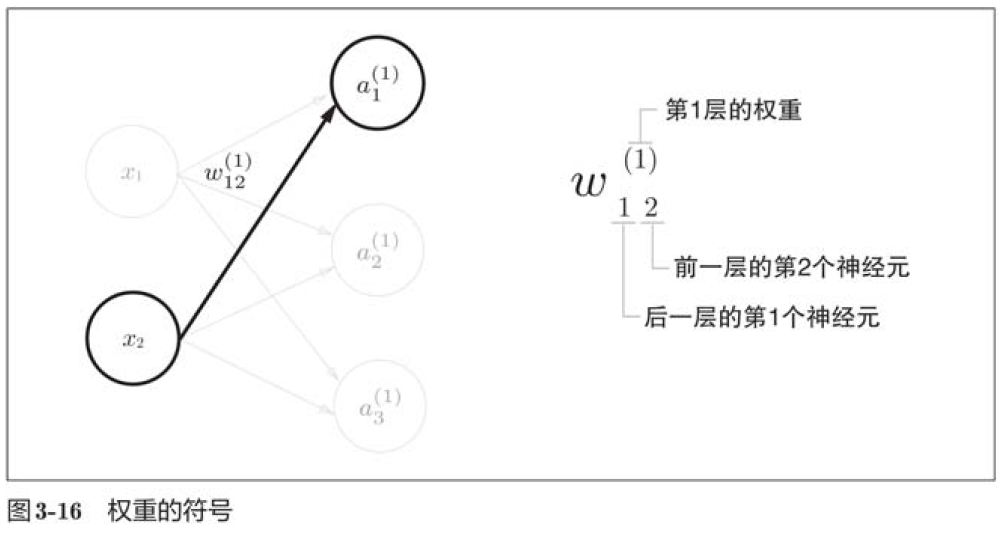
3.4.2 各层间信号传递的实现
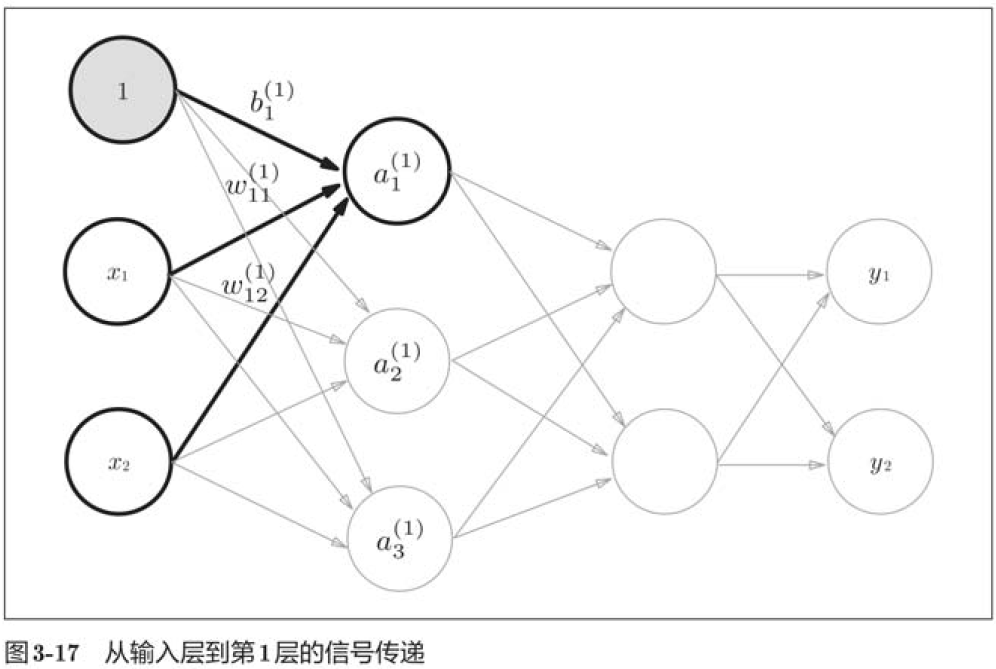
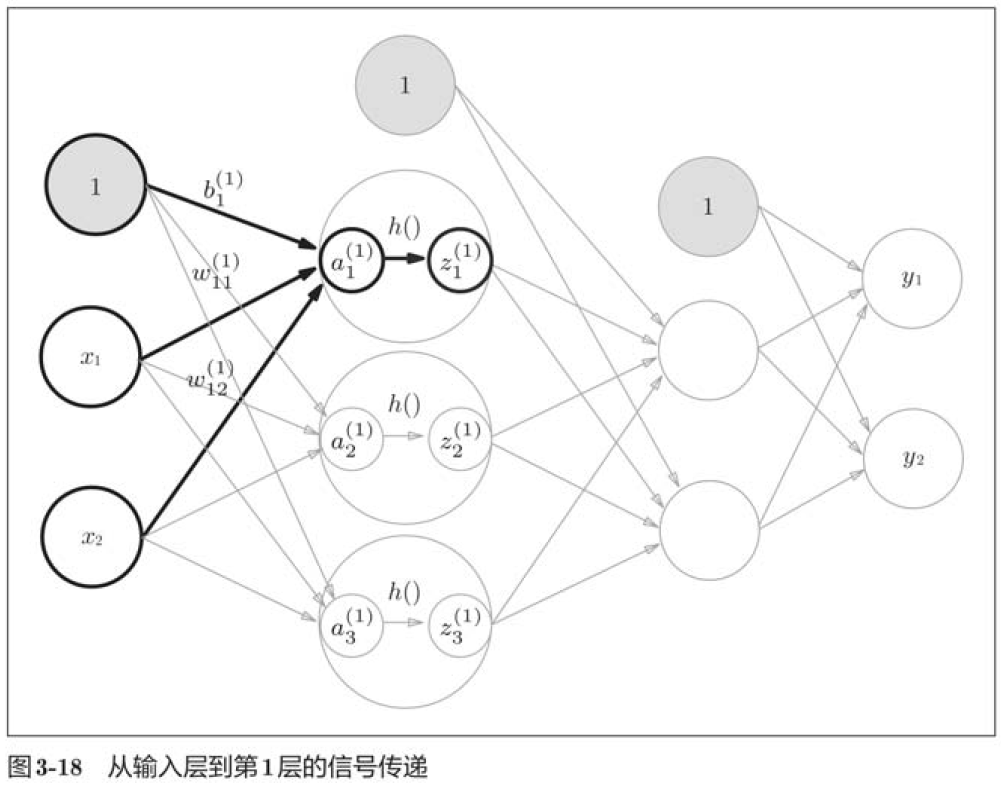
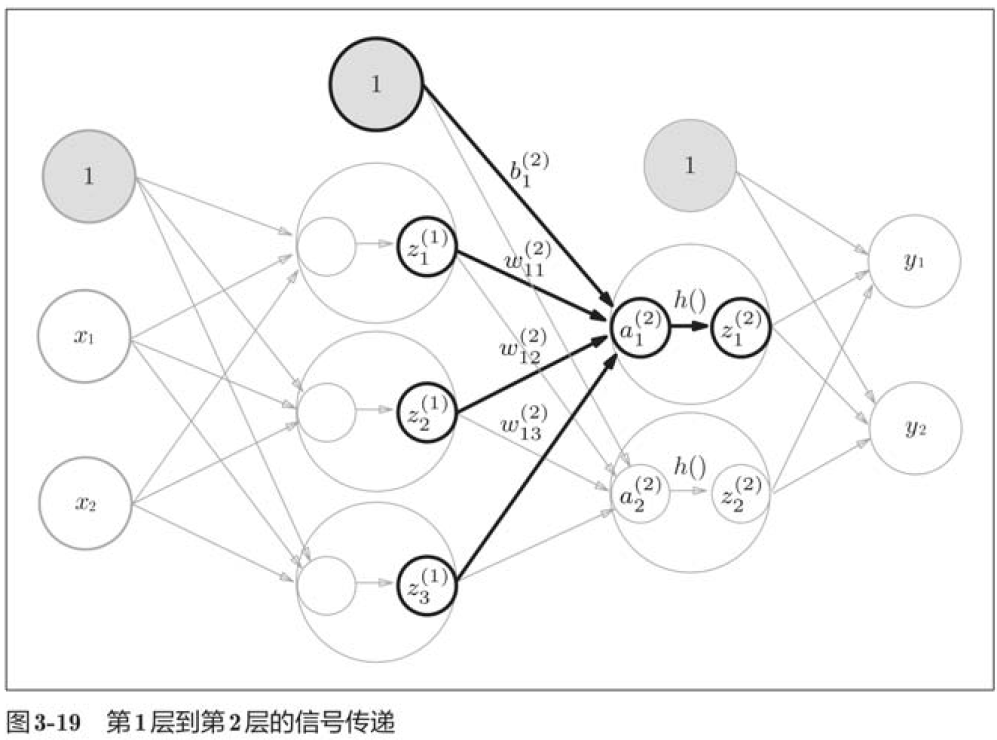
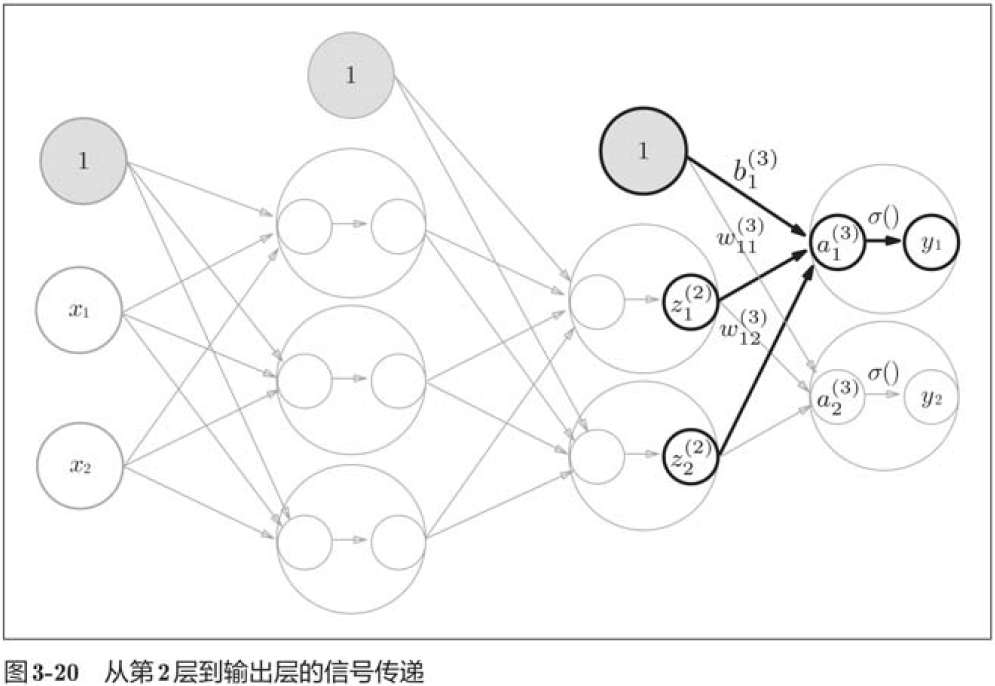
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.array([1.0, 0.5])
w1 = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
b1 = np.array([0.1, 0.2, 0.3])
print(w1.shape)
print(x.shape)
print(b1.shape)
a1 = np.dot(x, w1) + b1
z1 = sigmoid(a1)
print(a1)
print(z1)
w2 = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
b2 = np.array([0.1, 0.2])
print(z1.shape)
print(w2.shape)
print(b2.shape)
a2 = np.dot(z1, w2) + b2
z2 = sigmoid(a2)
print(a2)
print(z2)
def identity_function(x):
return x
w3 = np.array([[0.1, 0.3], [0.2, 0.4]])
b3 = np.array([0.1, 0.2])
a3 = np.dot(z2, w3) + b3
y = identity_function(a3)
print(a3)
print(y)
(2, 3)
(2,)
(3,)
[0.3 0.7 1.1]
[0.57444252 0.66818777 0.75026011]
(3,)
(3, 2)
(2,)
[0.51615984 1.21402696]
[0.62624937 0.7710107 ]
[0.31682708 0.69627909]
[0.31682708 0.69627909]
输出层所用的激活函数,要根据求解问题的性质决定。一般地,回归问题可以使用恒等函数,二元分类问题可以使用sigmoid函数,多元分类问题可以使用softmax函数。
3.4.3 代码实现小结
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def identity_function(x):
return x
def init_network():
network = {}
network['W1'] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = identity_function(a3)
return y
network = init_network()
x = np.array([1.0, 0.5])
y = forward(network, x)
print(y)
[0.31682708 0.69627909]
这里定义了init_network()和forward()函数。init_network()函数会进行权重和偏置的初始化,并将它们保存在字典变量network中。这个字典变量network中保存了每一层所需的参数(权重和偏置) 。forward()函数中则封装了将输入信号转换为输出信号的处理过程。
另外,这里出现了forward(前向) 一词,它表示的是从输入到输出方向的传递处理。后面在进行神经网络的训练时,我们将介绍后向(backward,从输出到输入方向)的处理。
至此,神经网络的前向处理的实现就完成了。通过巧妙地使用NumPy多维数组,我们高效地实现了神经网络。
3.5 输出层的设计
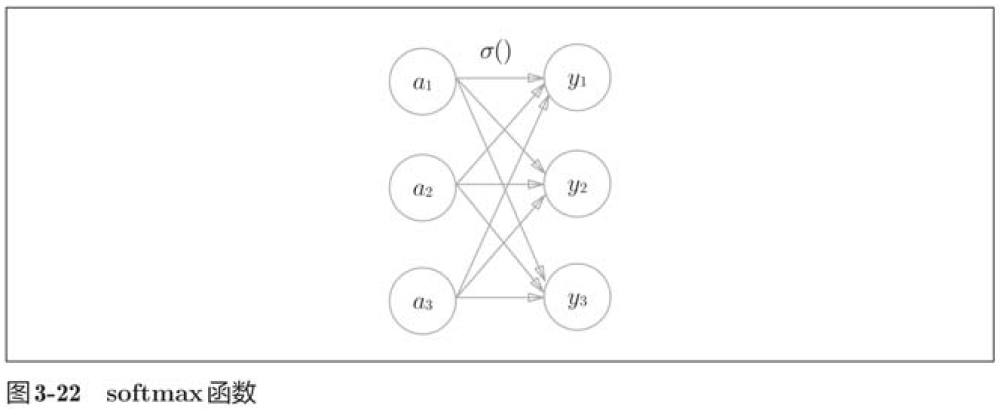
3.5.1 恒等函数和softmax函数
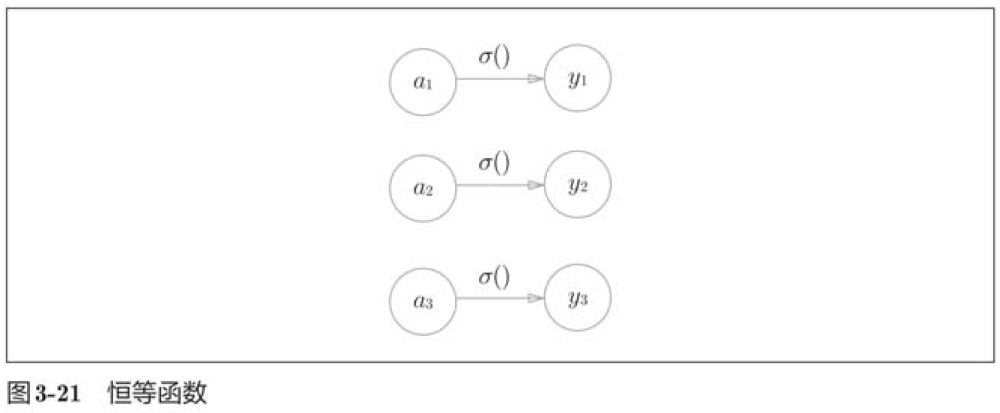
分类问题中的softmax函数可以用下式表示:
![]()
import numpy as np
a = np.array([0.3, 2.9, 4.0])
exp_a = np.exp(a)
print(exp_a)
sum_exp_a = np.sum(exp_a)
print(sum_exp_a)
y = exp_a / sum_exp_a
print(y)[ 1.34985881 18.17414537 54.59815003]
74.1221542101633
[0.01821127 0.24519181 0.73659691]3.5.2 实现softmax函数时的注意事项
softmax函数的实现中要进行指数函数的运算,但是此时指数函数的值很容易变得非常大。计算机处理“数”时,数值必须在4字节或8字节的有限数据宽度内,这意味着数存在有效位数,也就是说,可以表示的数值范围是有限的。因此,会出现超大值无法表示的问题。这个问题称为溢出,在进行计算机的运算时必须常常注意。
softmax函数的实现可以进行如下改进:
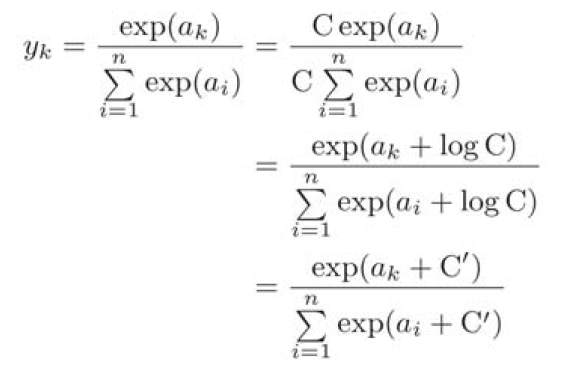
上式说明,在进行softmax的指数函数的运算时,加上(或者减去某个常数并不会改变运算的结果) 。这里![]() 可以使用任何值,但是为了防止溢出,一般会使用输入信号中的最大值。
可以使用任何值,但是为了防止溢出,一般会使用输入信号中的最大值。
import numpy as np
a = np.array([1010, 1000, 990])
b = np.exp(a) / np.sum(np.exp(a))
print(b)
c = np.max(a)
d = a - c
e = np.exp(a - c) / np.sum(np.exp(a - c))
print(e)D:projects2022202201�125�4.py:6: RuntimeWarning: overflow encountered in exp
b = np.exp(a) / np.sum(np.exp(a))
D:projects2022202201�125�4.py:6: RuntimeWarning: invalid value encountered in true_divide
b = np.exp(a) / np.sum(np.exp(a))
[nan nan nan]
[9.99954600e-01 4.53978686e-05 2.06106005e-09]
3.5.3 softmax函数的特征
import numpy as np
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
a = np.array([0.3, 2.9, 4.0])
y = softmax(a)
print(y)
print(np.sum(y))[0.01821127 0.24519181 0.73659691]
1.0
如上所示,softmax函数的输出是0.0到1.0之间的实数,并且,softmax函数的输出值的总和是1。输出总和为1是softmax函数的一个重要性质。正因为有了这个性质,我们才可以把softmax函数的输出解释为“概率”。
即使使用了softmax函数,各个元素之间的大小关系也不会改变,这是因为指数函数是单调递增函数。
一般而言,神经网络只把输出值最大的神经元所对应的类别作为识别结果,并且,即便使用softmax函数,输出值最大的神经元的位置也不会变。因此,神经网络在进行分类时,输出层的softmax函数可以省略。在实际的问题中,由于指数函数的运算需要一定的计算机运算量,因此输出层的softmax一般会被省略。
求解机器学习问题的步骤可以分为“学习”和“推理”两个阶段。首先,在学习阶段进行模型的学习,然后,在推理阶段,用学到的模型对未知的数据进行推理(分类)。推理阶段一般会省略输出层的softmax函数,在输出层使用softmax函数是因为它和神经网络的学习有关系。
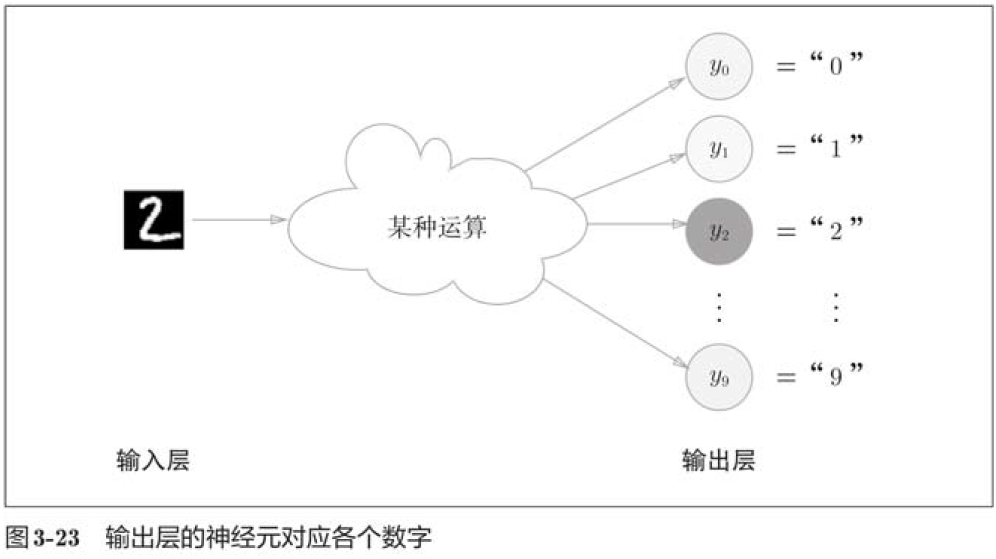
3.5.4 输出层的神经元数量
输出层的神经元数量需要根据待解决的问题来决定。对于分类问题,输出层的神经元数量一般设定为类别的数量。
3.6 手写数字的识别
和求解机器学习问题的步骤(分成学习和推理两个阶段进行)一样,使用神经网络解决问题时,也需要首先使用训练数据(学习数据)进行权重参数的学习;进行推理时,使用刚才学习到的参数,对输入数据进行分类。我们使用学习到的参数,先实现神经网络的“推理处理”,这个推理处理也称为神经网络的前向传播。
3.6.1 MINIST数据集
MINIST是机器学习领域最有名的数据集之一,被应用于从简单的实验到发表的论文研究等各种场合。实际上,在阅读图像识别或机器学习的论文时,MINIST数据集经常作为实验用的数据出现。
import sys
import os
import numpy as np
sys.path.append(os.pardir)
from mnist import load_mnist
from PIL import Image
def img_show(img):
pil_img = Image.fromarray(np.uint8(img))
pil_img.show()
(x_train, t_train), (x_test, y_test) = load_mnist(flatten=True, normalize=False)
img = x_train[0]
label = t_train[0]
print(label)
print(img.shape)
img = img.reshape(28, 28)
print(img.shape)
img_show(img)
5
(784,)
(28, 28)
3.6.2 神经网络的推理处理
import sys
import os
sys.path.append(os.pardir)
import numpy as np
import pickle
from mnist import load_mnist
from functions import sigmoid, softmax
def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)
return x_test, t_test
def init_network():
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return y
x, t = get_data()
network = init_network()
accuracy_cnt = 0
for i in range(len(x)):
y = predict(network, x[i])
p = np.argmax(y)
if p == t[i]:
accuracy_cnt += 1
print('Accuracy:' + str(float(accuracy_cnt) / len(x)))Accuracy:0.9352预处理在神经网络(深度学习)中非常实用,其有效性已在提高识别性能和学习的效率等众多实验中得到证明。在以上例子中,作为一种预处理,我们将各个像素值除以255,进行了简单的正规化。实际上,很多预处理都会考虑到数据的整体分布。比如,利用数据整体的均值或标准差,移动数据,使数据整体以0为中心分布,或者进行正规化,把数据的延展控制在一定范围内。除此之外,还有将数据整体的分布形状均匀化的方法,即数据白化等。
3.6.3 批处理
x, _ = get_data()
network = init_network()
W1, W2, W3 = network['W1'], network['W2'], network['W3']
print(x.shape)
print(W1.shape)
print(W2.shape)
print(W3.shape)(10000, 784)
(784, 50)
(50, 100)
(100, 10)我们通过上述结果来确认一下多维数组的对应维度的元素个数是否一致(省略了偏置)。可以发现,多维数组的对应维度的元素个数确实是一致的。此外,我们还可以确认最终的结果是输出元素个数为10的一维数组。
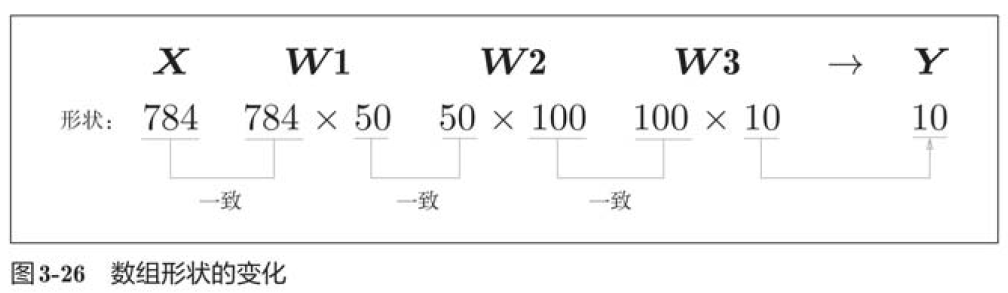
从整体的处理流程来看,上图中,输入一个由784个元素(原本是一个28*28的二维数组)构成的一维数组后,输出一个有10个元素的一维数组,这是只输入一张图像数据时的处理流程。
现在我们来考虑打包输入多张图像的情形。
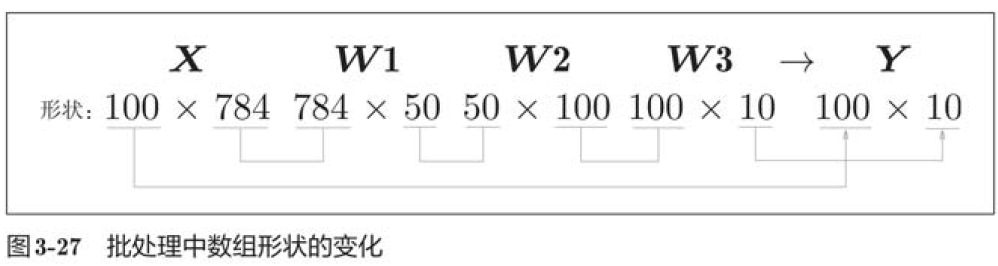
如上图所示,输入数据的形状为100*784,输出数据的形状为100*10。这表示输入的100张图像的结果被一次性输出了。比如,x[0]和y[0]中保存了第0张图像及其推理结果,x[1]和y[1]中保存了第1张图像及其推理结果,等等。
这种打包式的输入数据称为批。
批处理对计算机的运算大有利处,可以大幅缩短每张图像的处理时间。那么为什么批处理可以缩短处理时间呢?这是因为大多数处理数值计算的库都进行了能够高效处理大型数组运算的最优化。并且,在神经网络的运算中,当数据传送成为瓶颈时,批处理可以减轻数据总线的负荷(严格地讲,相对于数据读入,可以将更多的时间用在计算上)。也就是说,批处理一次性计算大型数组要比分开逐步计算各个小型数组速度更快。
batch_size = 100
accuracy_cnt = 0
for i in range(0, len(x), batch_size):
x_batch = x[i:i+batch_size]
y_batch = predict(network, x_batch)
p = np.argmax(y_batch, axis=1)
accuracy_cnt += np.sum(p == t[i:i+batch_size])
print('Accuracy:' + str(float(accuracy_cnt) / len(x)))Accuracy:0.9352
(10000, 784)
(784, 50)
(50, 100)
(100, 10)3.7 小结
本章介绍了神经网络的前向传播。本章介绍的神经网络和上一章的感知机在信号的按层传递这一点上是相同的,但是,向下一个神经元发送信号时,改变信号的激活函数有很大差异。神经网络中使用的是平滑变化的sigmoid函数,而感知机中使用的是信号急剧变化的阶跃函数。
1.神经网络中的激活函数使用平滑变化的sigmoid函数或ReLU函数;
2.通过巧妙地使用NumPy多维数组,可以高效地实现神经网络;
3.机器学习的问题大体上可以分为回归问题和分类问题;
4.关于输出层的激活函数,回归问题中一般用恒等函数,分类问题中一般用softmax函数;
5.分类问题中,输出层的神经元的数量设置为要分类的类别数;
6.输入数据的集合称为批,通过批为单位进行推理处理,能够实现高速的运算。
最后
以上就是朴素发夹最近收集整理的关于《深度学习入门:基于Python的理论与实现》读书笔记:第3章 神经网络第3章 神经网络的全部内容,更多相关《深度学习入门:基于Python的理论与实现》读书笔记:第3章内容请搜索靠谱客的其他文章。








发表评论 取消回复