背景:
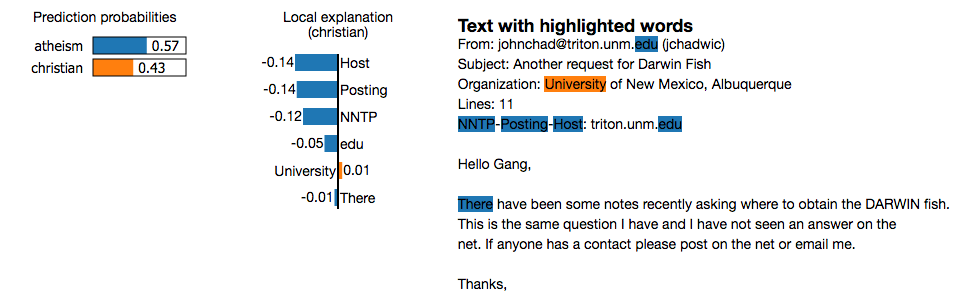
我们在建立模型的时候,经常会思考我们的模型是不是够稳定,会不会出现样本偏差效应, p>>N时候会不会过拟合? 我们检查模型稳定,我们进行一些cross-validation来看看各项评估指标方差大不大。 可是如果样本一开始因为采样偏差导致样本有偏,导致模型和实际情况有差异,这个就不太好评估了。同样,p>>N也会有类似的问题,尤其在文本挖掘领域。一般情况,如果特征不是很多的话,尤其像logistic regression这样的model,我们会把模型权重给打印出来看看,看看训练出的模型结果,是否和人的经验吻合。下面是lime 文章中提到一个文本分类的case,预测一段文本是无神论相关的,还是基督徒相关的。文中分类器预测结果这篇文本是无神论相关的,可是主要区分特征却与人的经验十分不吻合的,这样的模型是不能让人信服的,当我们把这几个特征删除后,预测结果又反向了。我们可以通过人工构建一些由这些特征组成的文本来加入到预测实验中,会大大降低模型性能。
LIME解释原理:
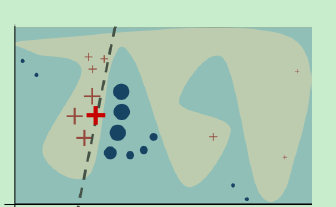
LIME是Local Interpretable Model-Agnostic Explanations的缩写。LIME的目的是试图解释模型在预测样本上的行为,这种解释是可被理解的,并且这种解释是模型无关的,不需要深入到模型内部。作者提出的方法一种局部方法,非全局的,在每个预测样本附近随机采样产生一些样本,就像下图所,红色“x”是预测样本,周边‘*’和圆形样本都是采样得到的。
采样的机制是随机替换掉原始样本中若干个特征。如文本a="我女朋友非常喜欢看奇葩说",生成的样本可以是“我非常喜欢看奇葩说”,“我女朋友看奇葩说”等等。每个生成样本和原始样本都有个权重,权重的计算方式: w=exp(-d^2/theta^2), d是距离,文本中我们可以采用cosine 距离来表征文本样本间的距离。
下面是lime_text.py 中__data_labels_distances函数的代码,针对是文本文本分类的解释,下面代码的主要作用如何给预测样本生成近邻采样样本,以及相应权重,采样样本在当前分类器的预测概率。
生成的样本表征方式是bag of word: [0,1,0,0,1]。
注意
这时候采样样本特征不是高维的,最大长度只是预测样本的长度。


有了采样样本,以及采样样本的权重,预测概率。有了这些东西,我们下面该干什么呢?记住我们的目的是要解释我们分类器在该预测样本中如何起作用的? 简单的说是在该预测样本,分类器都是哪些特征起到作用?我们可以事先设定个数值K,我们只看前K个起作用的特征(太多了,人无法查看)
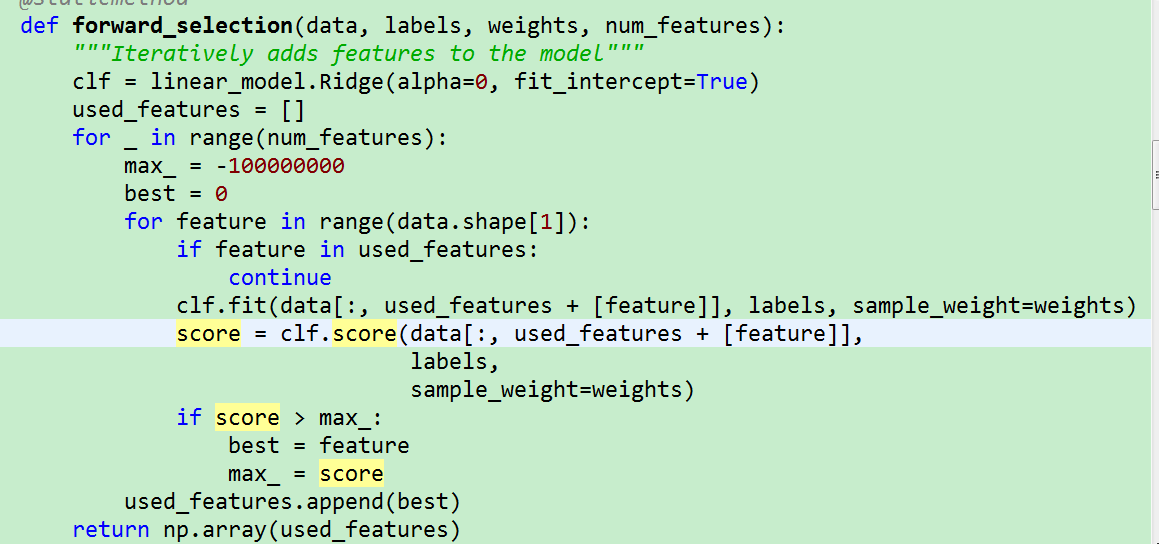
既然是特征选择问题,那我们可以用这些采样样本做个加权回归模型。做回归模型前,先选取k个重要特种,如何选取? 方法是可以是根据回归模型训练结果中最大的权重,或者是前向搜索方法(每次选取使回归模型R^2值最大的特征加入到集合中。),或者采用lasso_path的方法。注意样本的权重是不一样的。
具体可以看下面代码:

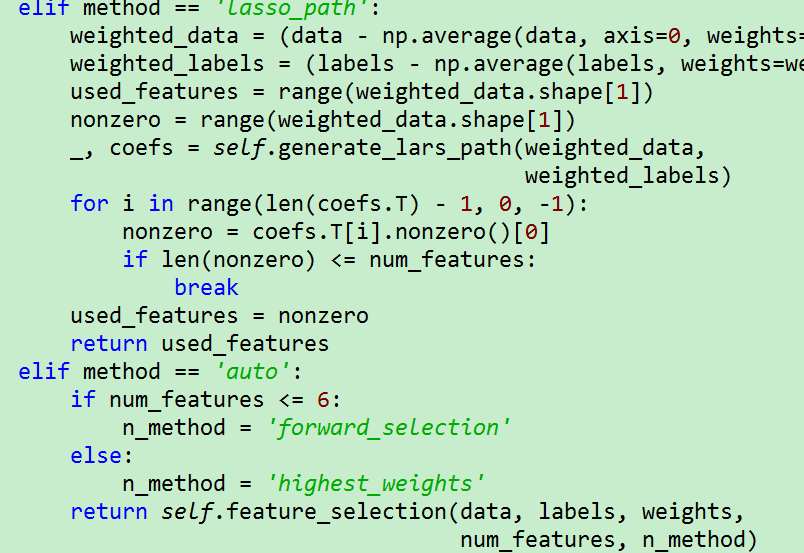
选取K个特征后,我们就可以在采样的样本,以及这K个特征上,做个加权回归模型。回归模型输出的K个特征以及权重,就是分类器对预测样本的解释。下面是explain_instance_with_data函数代码:

上面的方法总体可以用paper上的描述来概括:

总结:
上面主要围绕文本分类解释展开的,并且主要是基于文本bag of word方式。其实基于文本嵌入表征方式也是可行的,文本中词的替换机制一样,只是在预测采样样本分类概率前需要把采样样本变成向量方式。
其实可以拓展到很多其他领域,比如风控征信等。预测一个行为是否有风险,当我们的模型预测到该行为是有风险的,我们需要给我们分析师,客服解释这个行为为什么有风险,模型识别风险行为特征是什么。
拓展时候预测样本的近邻采样机制可能要优化设计下。更多场景很多特征不是离散或者二值的,而是连续的,尤其像Random Forest等树模型其实更适合处理连续的这种变量。针对这种情况,如何处理? 采样怎么做? 一种简单的方法是把连续特征进行离散化,one-hot编码,这样就和lime对文本分类模型的解释中采样机制是一样的啦。一种就是完全和文本一样,对特征进行置0采样,不管是否是连续变量。
总体上来说,LIME对模型的解释方法比较简单,论文描述略显复杂(本来很简单的东西为啥写的这么复杂呢?),论文更多是从实验角度来分析LIME方法的有效性,没有太多理论分析,让人感觉不是很放心(想想这个方法有哪些坑),毕竟实验是根据样本有关的,在一些复杂的场景是否有效? 还有实验更多用的文本和图像场景,其他领域是否奏效? 为什么在预测样本的采样样本中做加权回归分析,回归模型结果特征权重大小能代表原始模型在预测样本的表现呢?
最后
以上就是潇洒时光最近收集整理的关于LIME:模型预测结果是否值得信任?的全部内容,更多相关LIME:模型预测结果是否值得信任内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。







![[可解释机器学习]Task06:LIME算法学习一、 LIME算法讲解二、LIME论文逐句精读](https://www.shuijiaxian.com/files_image/reation/bcimg20.png)
发表评论 取消回复