本文分为两个部分:
- LIME算法讲解
- LIME论文逐句精读
一、 LIME算法讲解
LIME是一种可以解释任务机器学习模型预测结果的通用方法
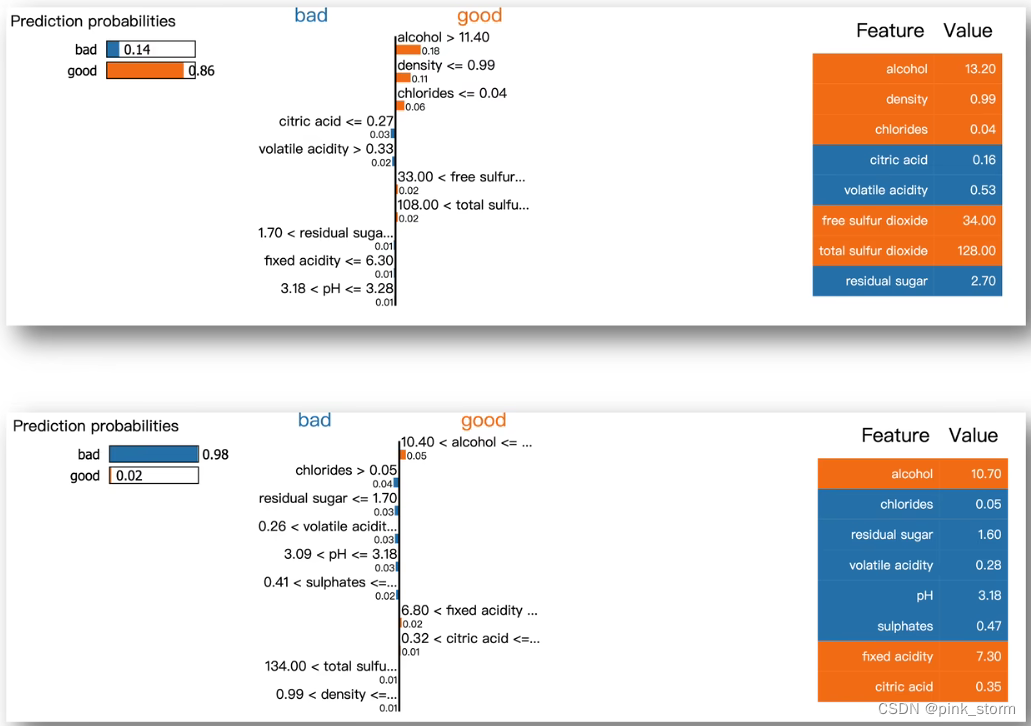
- 对于表格数据,如葡萄酒训练集 ,输入葡萄酒特征判断其是否为一个好的葡萄酒
哪些类别对模型被判断为好的贡献最大
我们可以把特征重要度,以及每个特征对模型预测为指定类别的贡献,定量展示出来
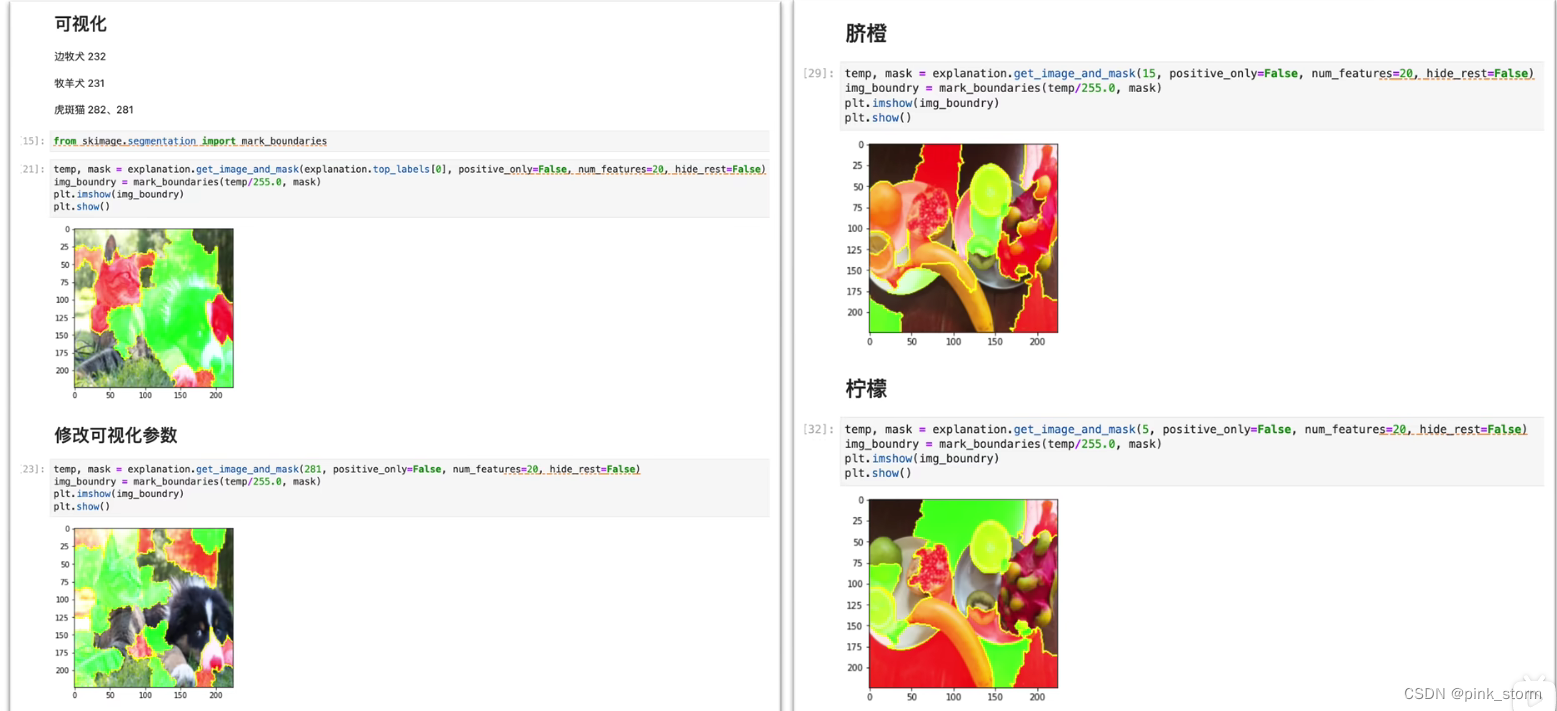
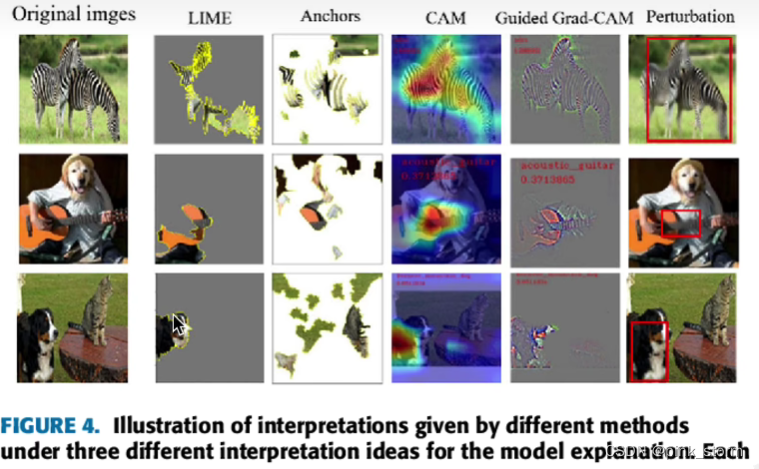
- 对于图像分类而言,我们可以将图像中一些对模型预测产生关键影响的区域高亮显示出来
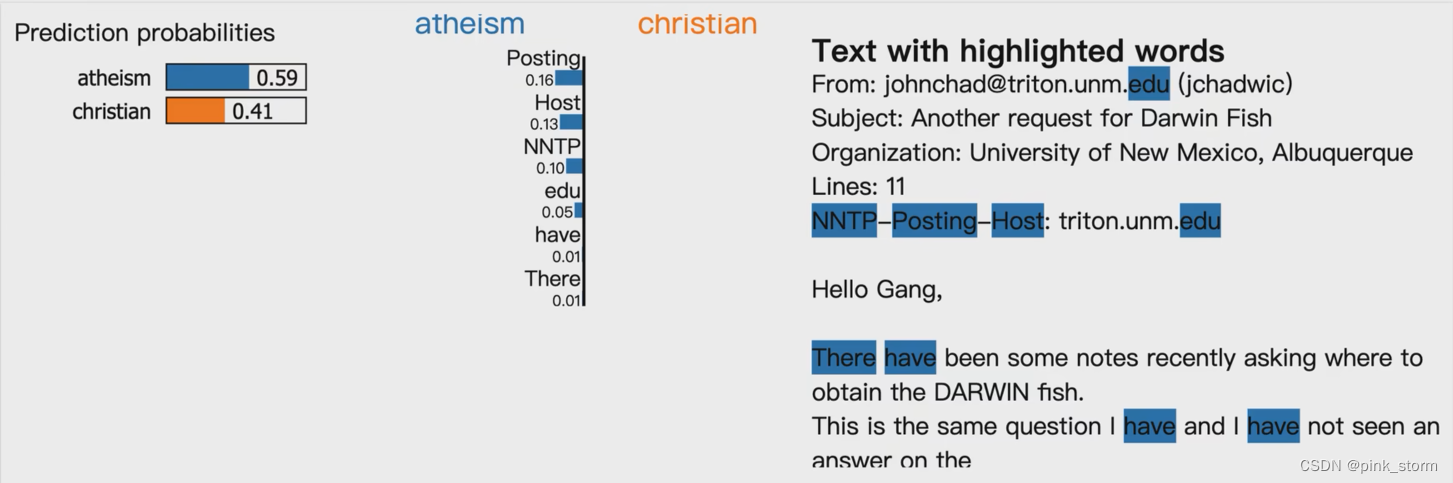
- 对文本分类进行可解释性分析,如预测一个文本是无神论的,还是基督教的
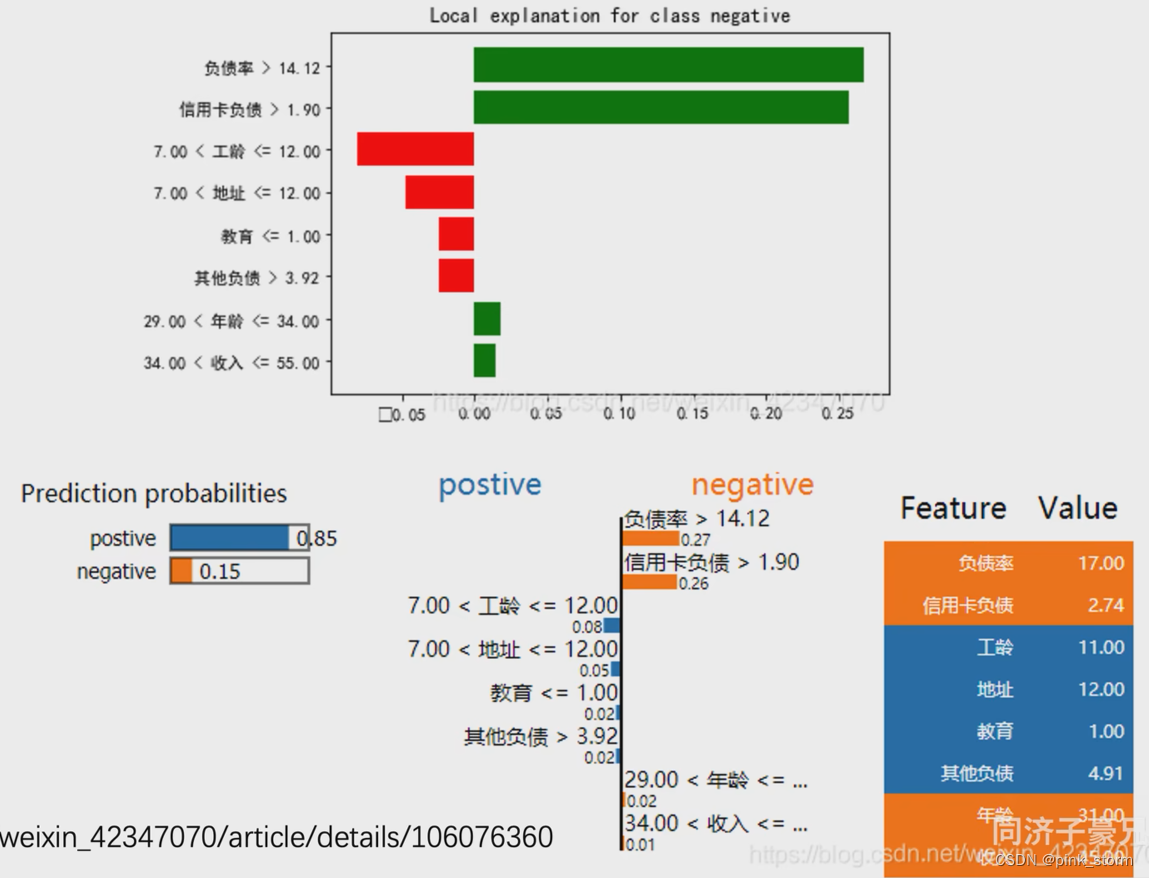
判断一个人是高收入还是低收入
能够明白到底是哪些特征让模型认为这个人是高收入还是低收入
预备知识:机器学习、线性分类、决策树
model-agnostic通用的,可解释任何一种机器学习
local是指只能拟合出待测样本模型的一个局部行为
interpretable是指其行为人类能够理解,可解释的
有些法律上要求人工智能必须具有可解释性
开始简述LIME
弱水三千只取一瓢
LIME实际上是一种范式
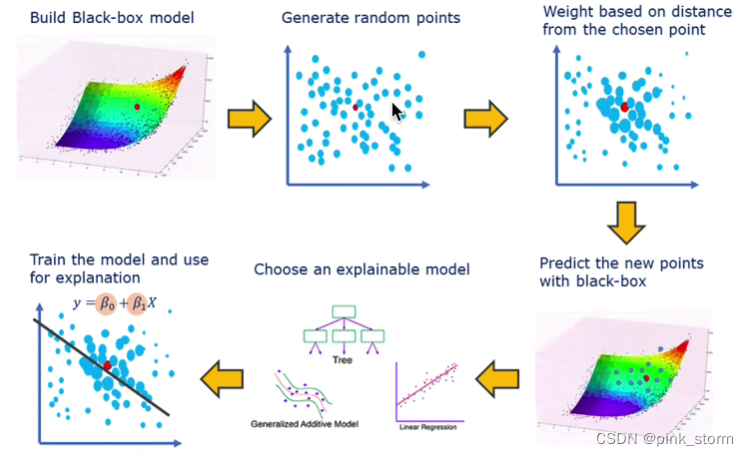
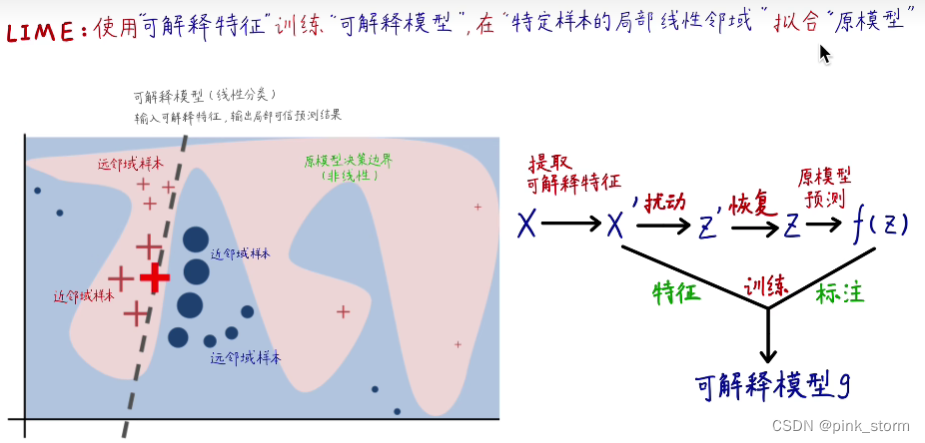
小局部上是线性的
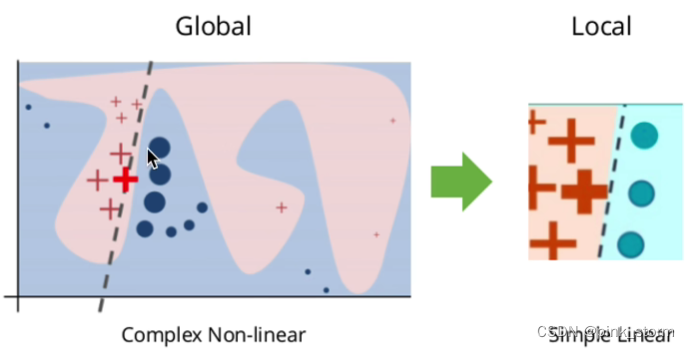
得到了每一个特征的重要性可以分析出可解释分析的结果
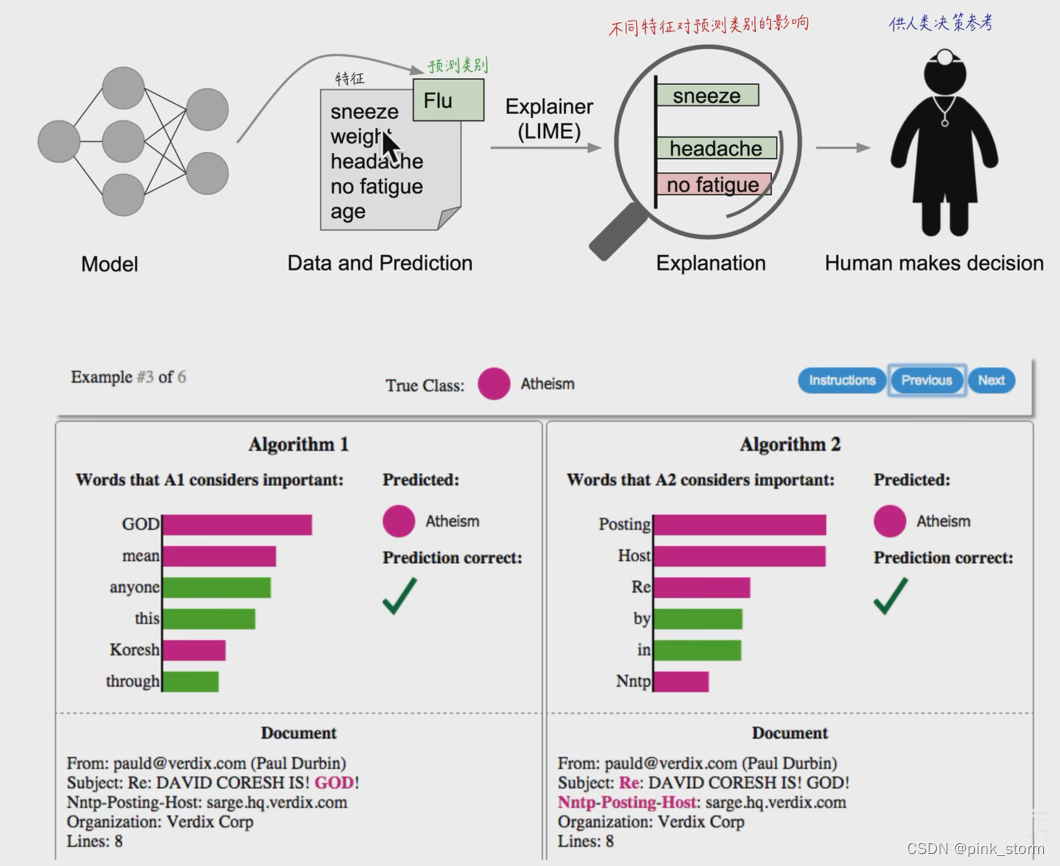
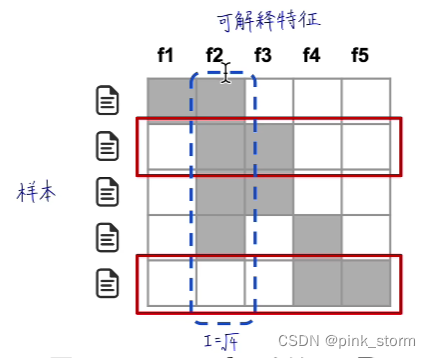
表格数据LIME可解释性分析
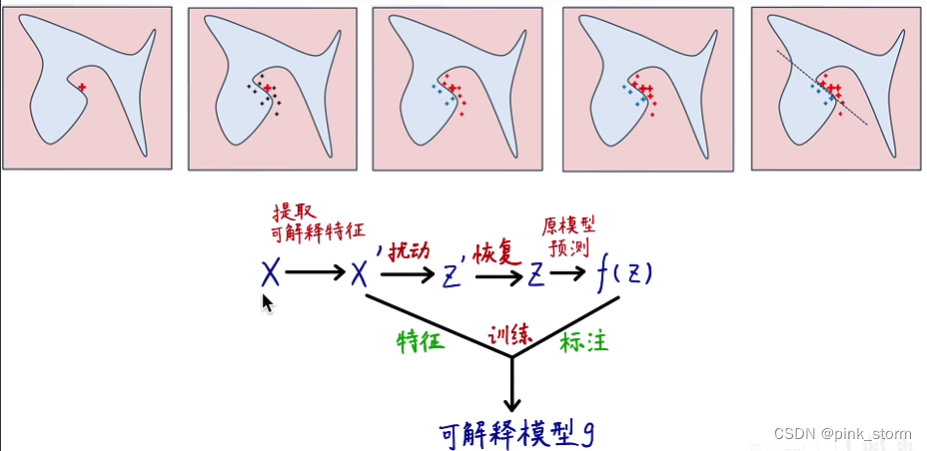
先选一个待测样本,然后对待测样本的特征进行扰动(因为都是实数,可以做加减乘除)
把模型预测的结果作为标注 ,扰动的样本作为特征,去训练一个可解释的模型
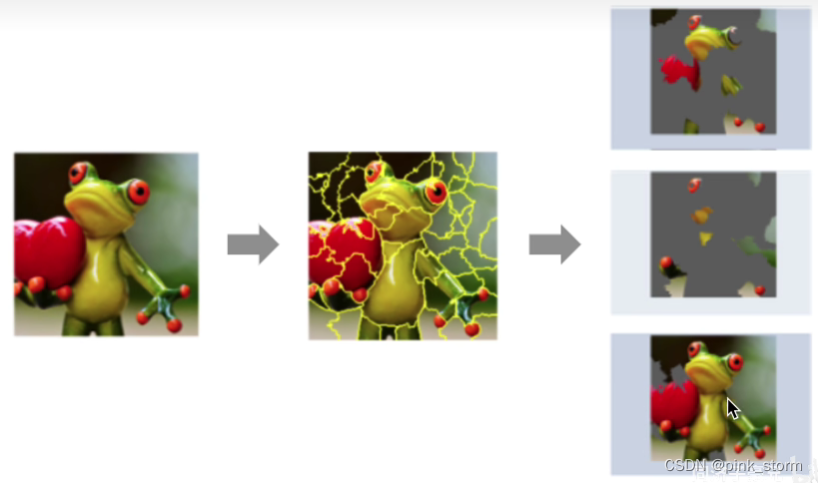
图像数据LIME可解释性分析
比较麻烦,因为要对待测数据进行扰动,RGB三个通道的像素矩阵很难在像素层面上进行扰动,得自己设计一套扰动的范式
这里直接将图形分块,直接判断存在不存在,存在就保留原来的像素,不存在就抹成灰色
每个图像有两种可能性,n个图块就有2^n个扰动的可能性


可以将这2^n个领域的样本输入到原始模型中,获得原始模型的预测结果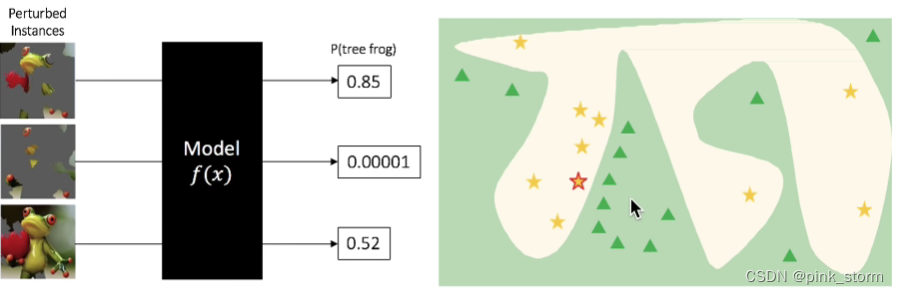
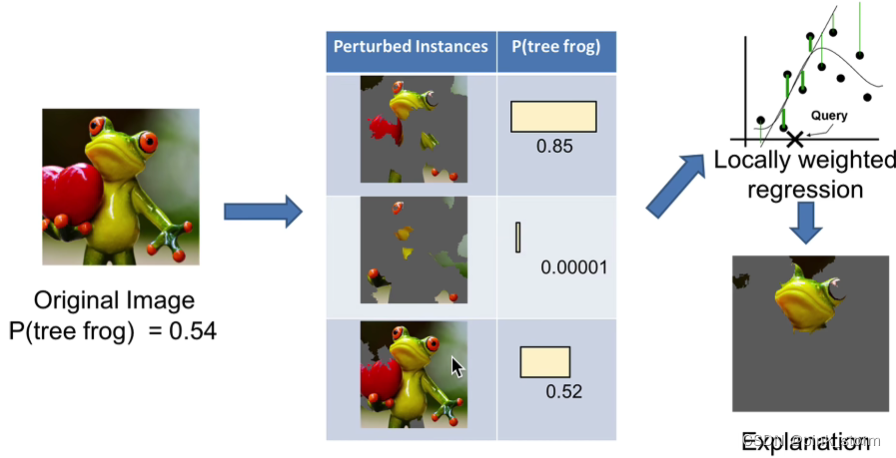
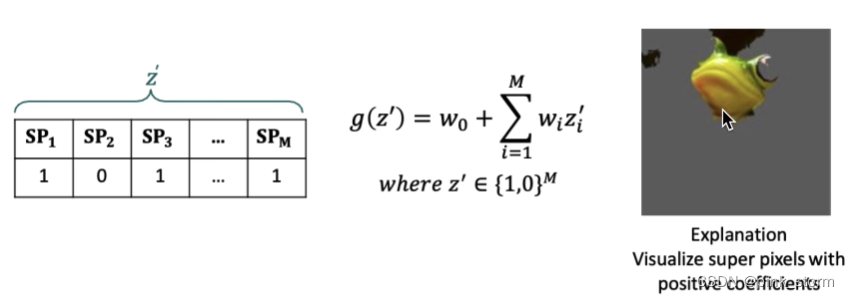
判断哪部分图块对模型判断产生影响
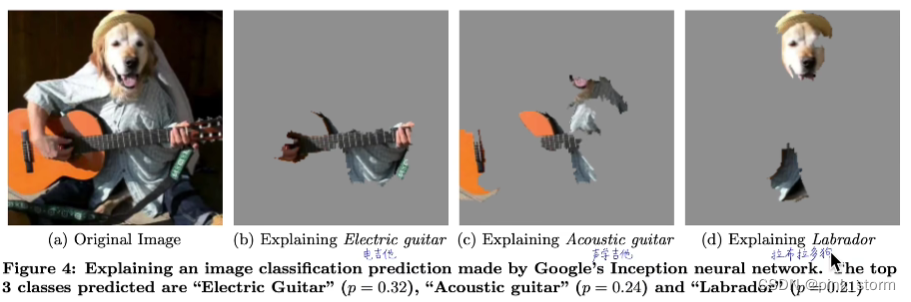
判断模型到底是在关注前景还是背景

文本数据LIME可解释性分析
文本很特殊,词向量根本不可解释
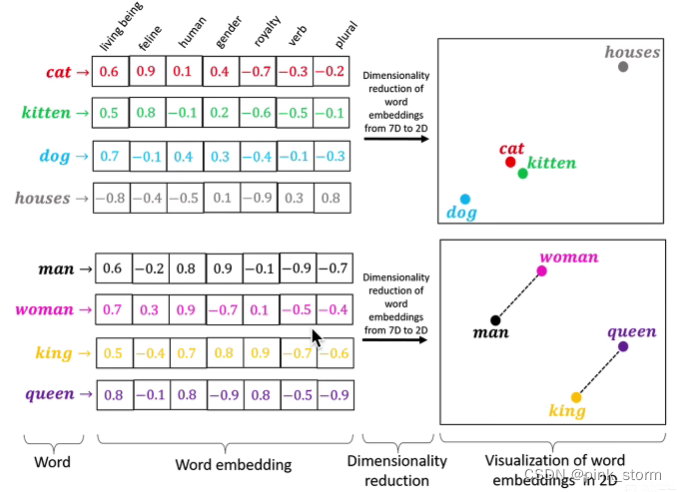
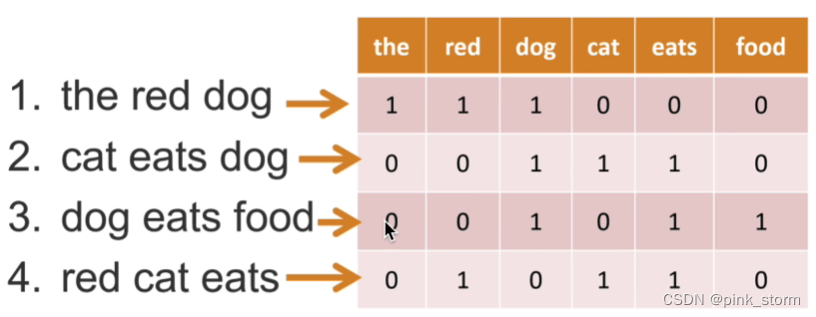
用词袋模型将其变为可解释特征
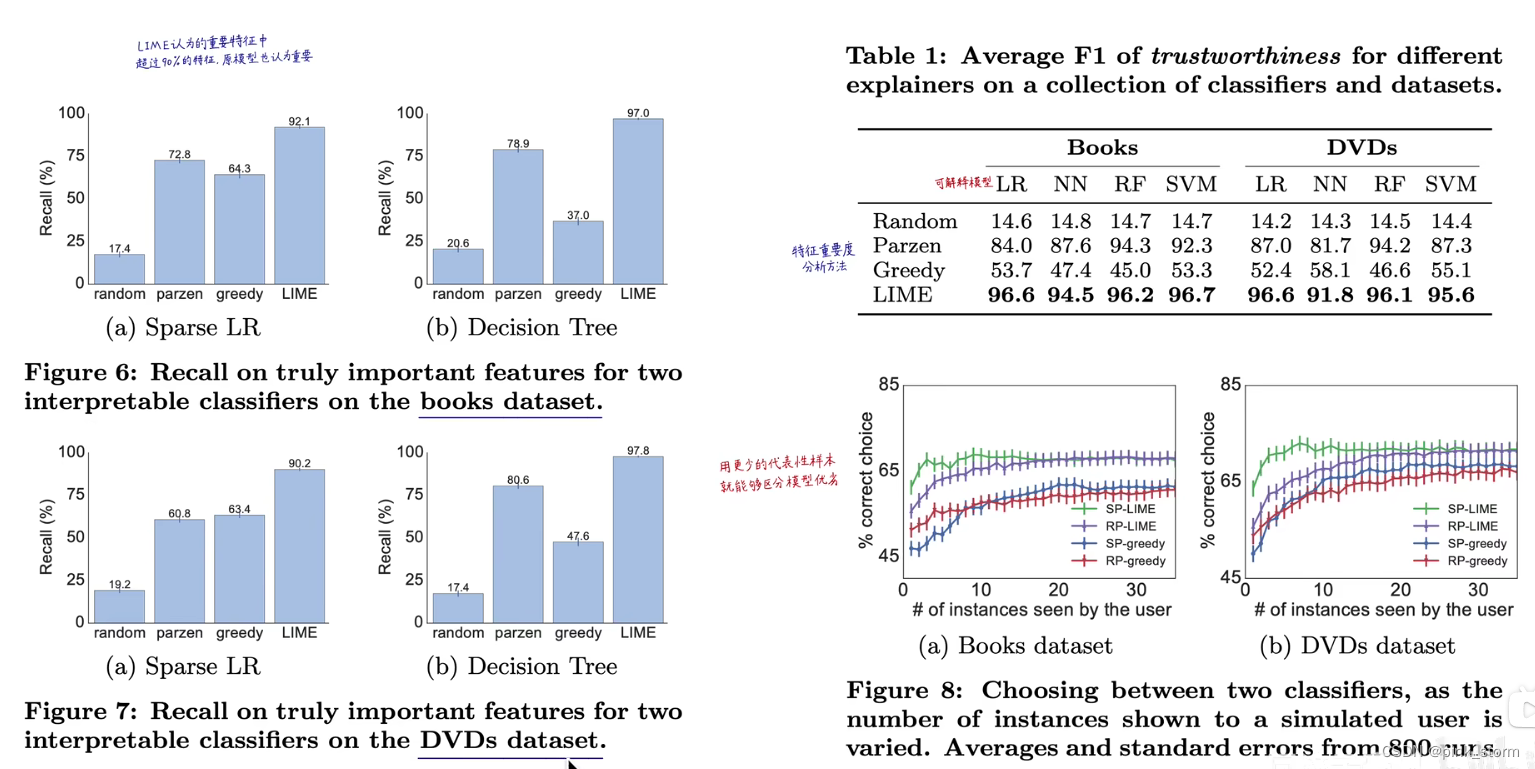
选取有代表性的样本
人类的耐心和时间都是极其有限的

先算出每一个特征的代表性,然后尽量覆盖代表性高的特征去选取代表性样本
实验
人工智能是通过判断背景雪地来判断哈士奇的
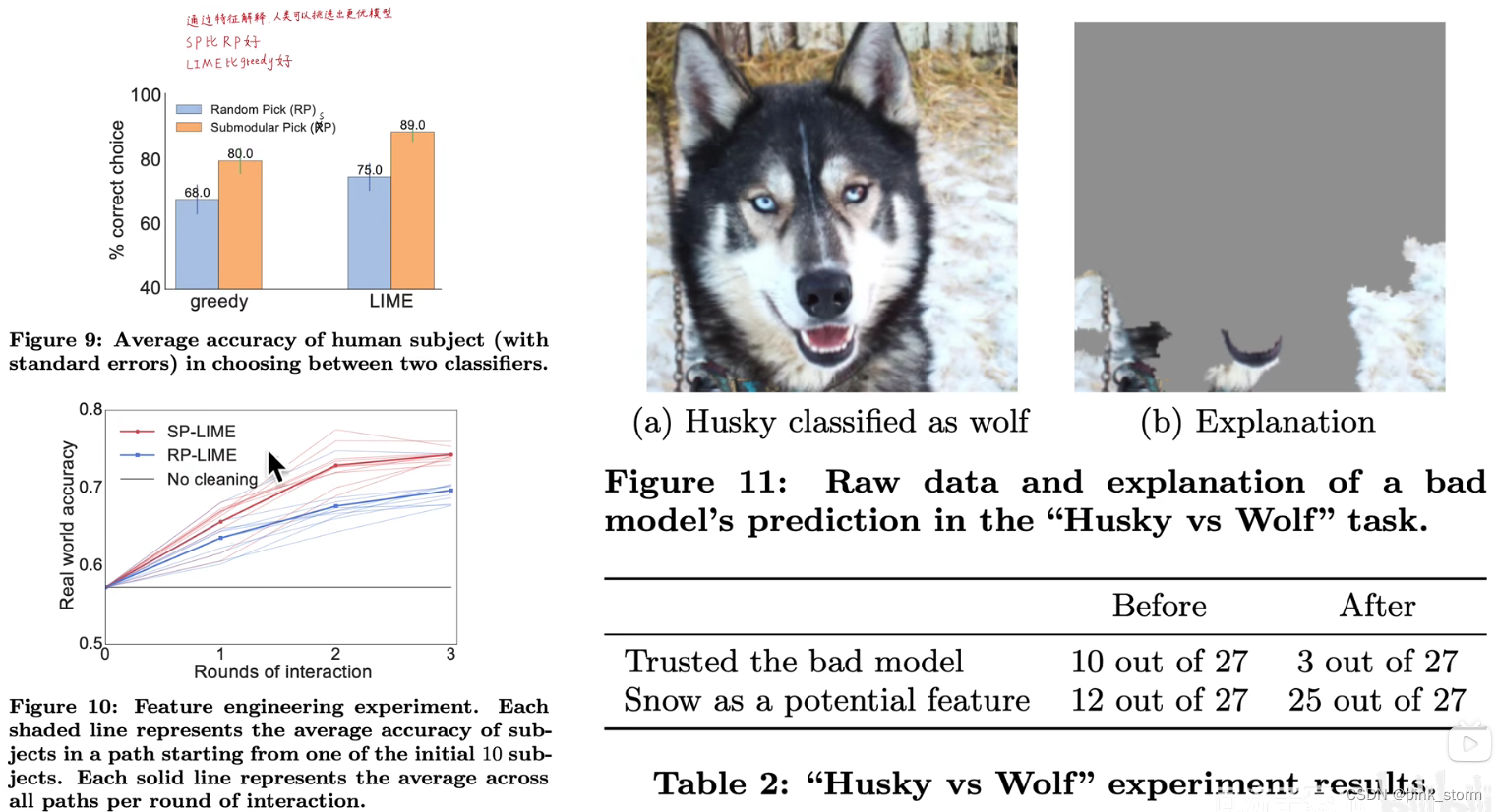
讨论
LIME的优点:
- 兼容任意一种机器学习算法
- 特征重点性:解释、理解、信赖、改进(特征工程)
- What-if场景:如果每个月多挣500元,额度是多少
- 可解释单个样本预测结果、选取代表性样本
- 可人工设计、构造可解释特征
但是成也萧何,败也萧何
LIME的缺点
- 人工设计、构造的“可解释特征”,不一定科学
- “局部线性”可能无法拟合原模型,有许多锯齿状边缘,不平滑
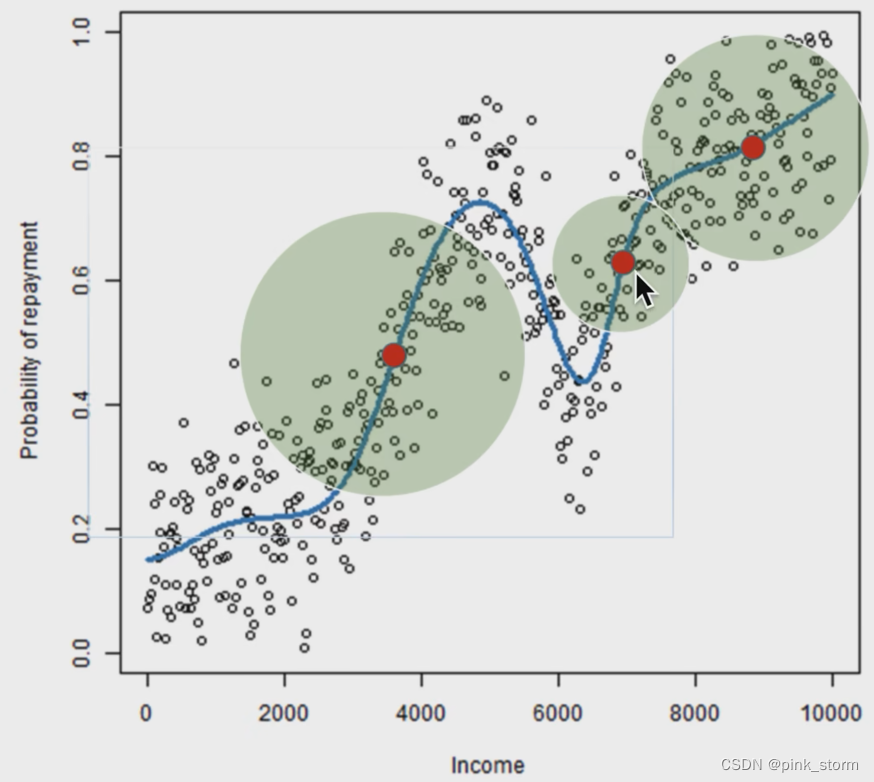
- 不同样本,如何计算领域样本权重
- 每个待测样本都需训练对应可解释模型,耗时长
LIME的改进:自适应距离
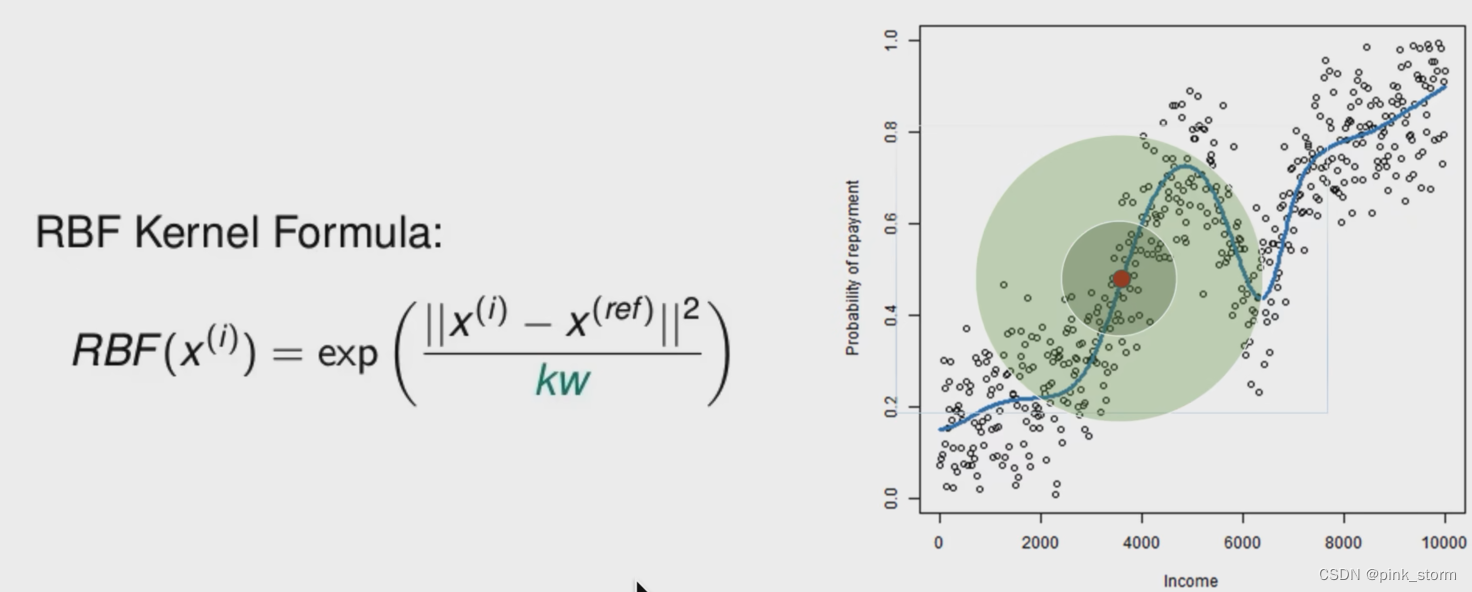
Optimal line能够调节出最适合的半径

二、LIME论文逐句精读
论文选择的是:"Why Should l Trust You?":Explaining the Predictions of Any Classifier
具体阅读笔记在EndNote中,需要可留言
论文目录:
- Introduction
- The case for explanations
- Local lnterpretable Model-Agnostic Explanations
- Submodular Pick for Explaining Models
- Simulated User Experiments
- Evaluation with human subjects
- Related Work
- Conclusion and Future Work
部分内容如下:

总结:LIME是一种模块化和可扩展的方法,可以对任何模型做可解释性分析的预测。还引入了SP-LIME,这是一种选择代表性和非冗余预测的方法,为用户提供了模型的全局视图。论文中实验表明,解释对于文本和图像领域中与信任相关的任务中的各种模型都很有用,可供非专业人士使用。
最后
以上就是斯文香水最近收集整理的关于[可解释机器学习]Task06:LIME算法学习一、 LIME算法讲解二、LIME论文逐句精读 的全部内容,更多相关[可解释机器学习]Task06内容请搜索靠谱客的其他文章。




![[可解释机器学习]Task06:LIME算法学习一、 LIME算法讲解二、LIME论文逐句精读](https://www.shuijiaxian.com/files_image/reation/bcimg20.png)



发表评论 取消回复