关于如何使用监督机器学习算法进行情感分类的教程
自由文本文档的情感分析是文本挖掘领域的一项常见任务。在情感分析中,预定义的情感标签,例如“正面”或“负面”被分配给文本。文本(此处称为文档)可以是关于产品或电影、文章、推文等的评论。
在本文中,我们将向您展示如何使用KNIME 文本处理扩展与传统 KNIME 学习器和预测器节点相结合,为文档分配预定义的情感标签。
已从大型电影评论数据集 v1.0的训练集中抽取了一组 2000 个文档。大型电影评论数据集 v1.0 包含 50000 条英文电影评论及其相关的情感标签“正面”和“负面”。我们抽取了正组的 1000 个文档和负组的 1000 个文档。这里的目标是为每个文档分配正确的情感标签。
自己尝试与这篇文章相关的工作流程(图 1)。可从KNIME Hub下载。
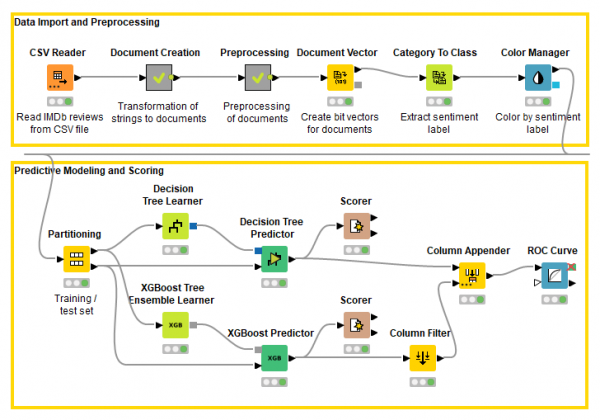
图 1. 该工作流程预处理文本文档,创建文档向量,并训练两个机器学习模型为文档分配情感标签。
阅读评论文本:文本数据
该工作流从一个CSV 阅读器节点开始,读取一个 CSV 文件,该文件包含评论文本、其关联的情感标签、相应电影的 IMDb URL 及其在大型电影评论数据集 v1.0 中的索引。重要的是文本和情绪栏。在第一个元节点“文档创建”中,使用字符串到文档节点从字符串单元创建文档单元;情感标签存储在每个文档的类别字段中,以供以后的任务使用;并过滤掉除 Document 列之外的所有列。
第一个元节点“文档创建”的输出是一个数据表,只有一列包含文档单元格。
预处理文本
文本数据由KNIME 文本处理扩展提供的各种节点进行预处理。所有预处理步骤都应用在第二个元节点“预处理”中,如图 2所示

图 2. “预处理”元节点执行文本特定的数据预处理
首先,Punctuation Erasure节点去除标点符号,然后过滤数字和停用词,并将所有术语转换为小写。之后,使用Snowball Stemmer节点从每个单词中提取词干。实际上,单词“选择”、“选择”和“选择”指的是相同的词汇概念,并在文档分类或主题检测上下文中携带相同的信息。除了英文文本,Snowball Stemmer节点还可以应用于各种语言的文本,例如德语、法语、意大利语、西班牙语等。该节点使用的是Snowball 词干库。
提取特征并创建文档向量
在所有这些预处理之后,我们到达了分析的中心点,即提取术语以用作文档向量的组成部分和分类模型的输入特征。
要为文本创建文档向量,首先我们使用Bag Of Words Creator节点创建它们的词袋;然后我们将包含词袋的数据表提供给文档向量节点。该文献向量节点将考虑到包含在话创建相应的文件向量的袋的所有术语。
请注意,文本由单词组成,而文档(包含类别或作者等附加信息的文本)包含术语,即包含语法、性别或词干等附加信息的单词。
提示:当文本很长时如何避免性能问题?
由于文本很长,相应的词袋可能包含很多词,相应的文档向量可能具有很高的维数(分量太多),并且分类算法在速度性能方面会受到影响。但是,并非文本文档中的所有单词都同等重要。
一种常见的做法是过滤掉所有信息最少的词,只保留最重要的词。单词重要性的一个很好的衡量标准可以通过单词在每个单个文档以及整个数据集中出现的次数来表示。
基于这种考虑,在创建词袋之后,我们过滤掉数据集中少于 20 个文档中出现的所有术语。在GroupBy节点中,我们按词条分组并对包含词条的所有唯一文档至少计数一次。输出是一个术语列表,其中包含它们出现的文档数量。
我们过滤这个词条列表,只保留那些文档数大于 20 的词条,然后我们使用Reference Row Filter节点相应地过滤每个词袋中的词条。通过这种方式,我们将特征空间从 22379 个不同的单词减少到 1499 个。这个特征提取过程是“预处理”元节点的一部分,可以在图 3 中看到。
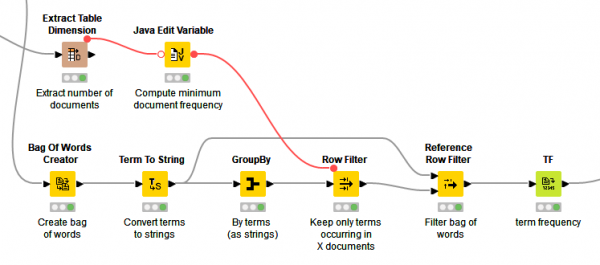
图 3. 特征提取 - 创建和过滤词袋。
我们将最小文档数设置为 20,因为我们假设一个词必须出现在所有文档的至少 1%(2000 年的 20 个)中才能表示有用的分类特征。这是一个经验法则,当然可以优化。
现在基于这些提取的词(特征)创建文档向量。文档向量是文档的数字表示。这里字典中的每个词都成为向量的一个组成部分,并且对于每个文档都假定一个数值,该数值可以是 0/1(文档中 0 个词不存在,文档中出现 1 个词)或文档中词重要性的度量(例如单词分数或频率)。该文献矢量节点允许创建位向量(0/1)或数字载体。作为数值,可以使用先前计算的单词分数或频率,例如由TF或IDF节点使用。在我们的例子中使用了位向量。
使用监督挖掘算法进行分类
对于分类,我们可以使用 KNIME 分析平台中可用的任何传统监督挖掘算法(例如决策树、随机森林、支持向量机、神经网络等等)。
与所有监督挖掘算法一样,我们需要一个目标变量。在我们的示例中,目标是情感标签,存储在文档类别中。因此,使用Category To Class节点从文档中提取目标或类列并附加为字符串列。根据类别,颜色管理器节点为每个文档分配一种颜色。标签为“positive”的文件为绿色,标签为“negative”的文件为红色。
作为分类算法,我们使用决策树和 XGBoost Tree Ensemble 应用于训练 (70%) 和测试集 (30%),从原始数据集中随机提取。决策树的准确率为 91.3%,XGBoost Tree Ensemble 的准确率为 92.0%。相应的 ROC 曲线如图 4所示。
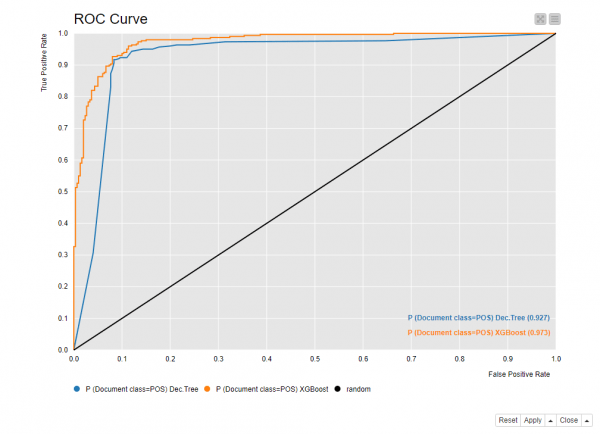
图 4. 决策树和 XGBoost 模型的 ROC 曲线。
虽然性能稍好一些,但 XGBoost Tree Ensemble 没有决策树可以提供的可解释性。下图(图 5)显示了决策树的前两个级别的视图。区分这两个类别的最具区别性的术语是“坏”、“浪费”和“电影”。如果“坏”一词出现在文档中,则很可能会产生负面情绪。如果没有出现“坏”而是“浪费”(浪费的词干),则它可能再次成为负面文件,依此类推。
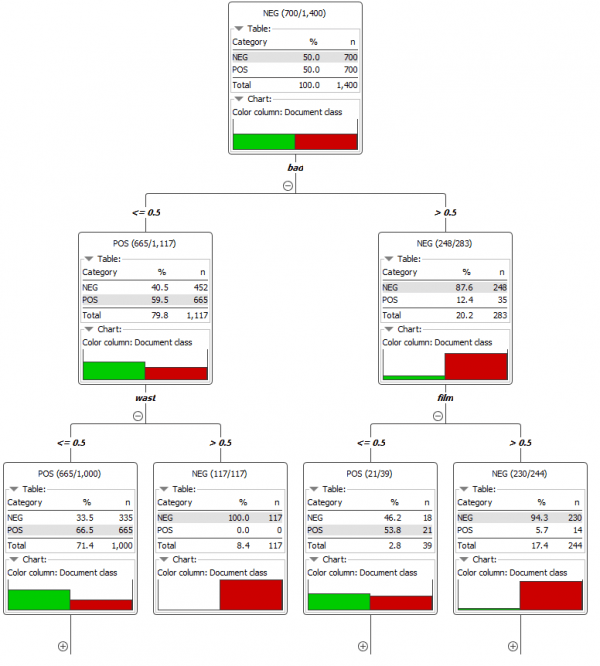
图 5. 决策树视图允许我们调查哪些特征(在我们的例子中是词或其词干)对分离两个情感类别中的文档贡献最大。
原文链接
最后
以上就是强健彩虹最近收集整理的关于关于如何使用监督机器学习算法进行情感分类的教程的全部内容,更多相关关于如何使用监督机器学习算法进行情感分类内容请搜索靠谱客的其他文章。
![[春秋云镜]CVE-2014-3529声明:⽂中所涉及的技术、思路和⼯具仅供以安全为⽬的的学习交流使⽤,任何⼈不得将其⽤于⾮法⽤途以及盈利等⽬的,否则后果⾃⾏承担。所有渗透都需获取授权!靶场介绍](https://www.shuijiaxian.com/files_image/reation/bcimg6.png)







发表评论 取消回复