-前言
之前一直用scrapy与urllib姿势爬取数据,最近使用requests感觉还不错,这次希望通过对知乎数据的爬取为 各位爬虫爱好者和初学者更好的了解爬虫制作的准备过程以及requests请求方式的操作和相关问题。当然这是一个简单的爬虫项目,我会用重点介绍爬虫从开始制作的准备过程,目的是为了让和我一样自学的爬虫爱好者和初学者更多的了解爬虫工作。
一、观察目标网页模板和策略
很多人都忽略这一步,其实这一步最为重要,因为它决定了你将采取什么策略来获取数据,也可以评估出你能够做到什么程度
(1)打开浏览器的开发工具F12
这里我用的是Google浏览器,打开浏览器按F12,你将看到你加载网页情况,以及网络请求的方式和交互的参数情况。如果你没有看到,你应该百度自己的浏览器开发者工具,如何打开。我们在打开知乎门户网页后,F12看到开发者工具的Network一栏没有出现任何东西。如图1.1所示:
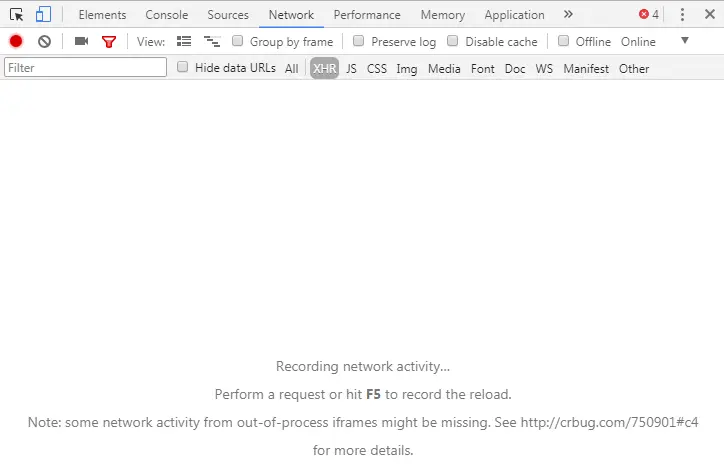
开发者工具 图 1.1
然后我们在知乎搜索框内输入需要搜索的内容,你将会看到网页后台与前台数据交互的变化,加载的数据以及数据请求的方式和参数。如图1.2:
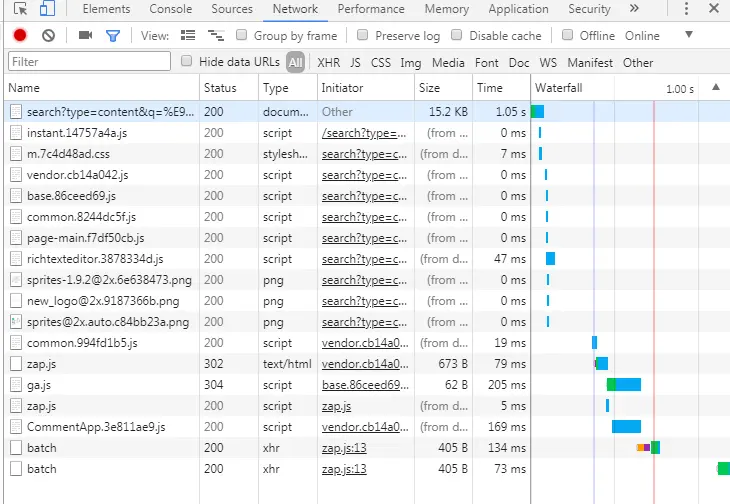
服务端与浏览器交互的信息 图1.2
这里你可以看到有很多js文件和png格式文件,这些文件都是通过你的搜索这个动作,对方服务器返回的文件,根据这些你可以更加了解网页服务端与浏览器的交互过程。这里如果你很有经验的话,可以根据它的size和name字段快速找出你想要的交互文件。
因为我们之前的搜索操作,所以很容易可以看出来第一个带有search字段的是搜索操作时和网站服务器交互的文件。点击我们可以看到 如图1.3:
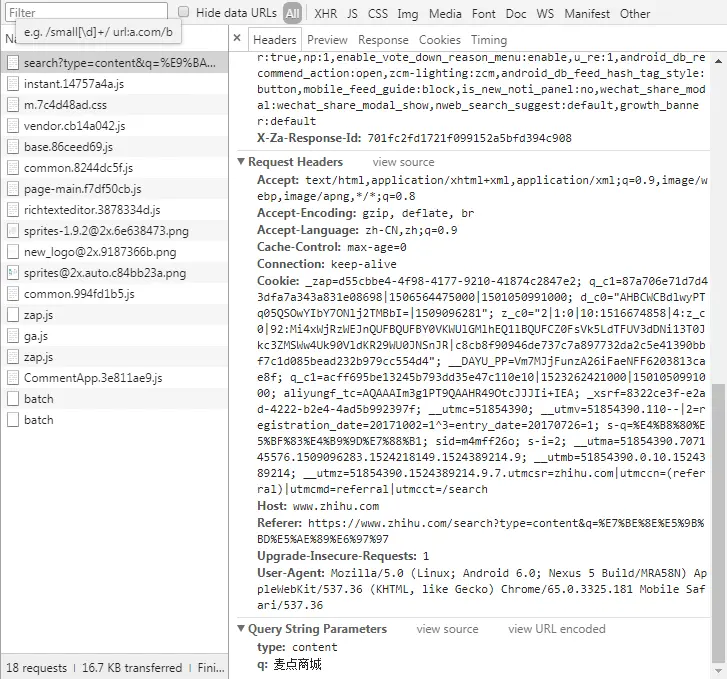
与服务器通信请求参数 图1.3
这里有返回给我们与服务器通信后的过程以及相关数据,右上方可以看到Headers、Previes、Response、cookie等选项 。
headers可以看到请求的参数,我们很多时候写爬虫访问服务器被拒绝就是因为这里有很多参数验证没有通过,所以学会运用这里
最后
以上就是激动斑马最近收集整理的关于python爬虫菜鸟教程-python爬虫项目(新手教程)之知乎(requests方式)的全部内容,更多相关python爬虫菜鸟教程-python爬虫项目(新手教程)之知乎(requests方式)内容请搜索靠谱客的其他文章。








发表评论 取消回复