在前面一篇文章中,我们分析了网页分块的光栅化过程。根据Chromium的启动选项,网页分块有可能使用GPU来执行光栅化操作,也有可能使用CPU来执行光栅化操作。不管是使用GPU,还是CPU,光栅化操作最终都是统一通过调用Skia图形库提供的绘图接口完成的。如果使用GPU来执行光栅化操作,那么当它在调用绘图接口的时候,实际上是在执行相应的OpenGL命令。本文接下来就详细分析GPU光栅化的实现原理。
老罗的新浪微博:http://weibo.com/shengyangluo,欢迎关注!
《Android系统源代码情景分析》一书正在进击的程序员网(http://0xcc0xcd.com)中连载,点击进入!
网页分块的光栅化过程,实际上是执行之前所记录的分块绘制命令,最终得到一个包含RGB值的图形缓冲区,如下所示:
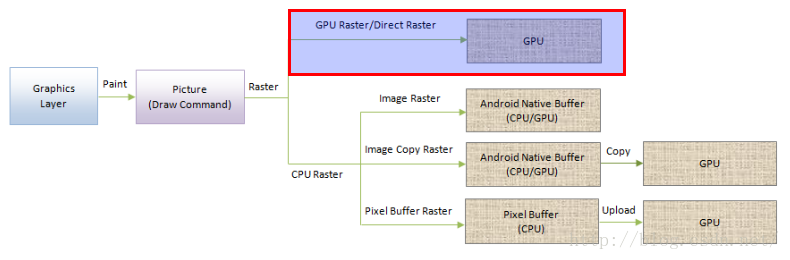
图1 网页分块光栅化过程
网页分块的绘制命令的收集过程可以参考前面Chromium网页Layer Tree绘制过程分析一文,有了这些绘制命令,就可以通过GPU或者CPU将它们转化为一个图形缓冲区。在GPU光栅化方式中,这个图形缓冲区的本质是一个纹理,如下所示:
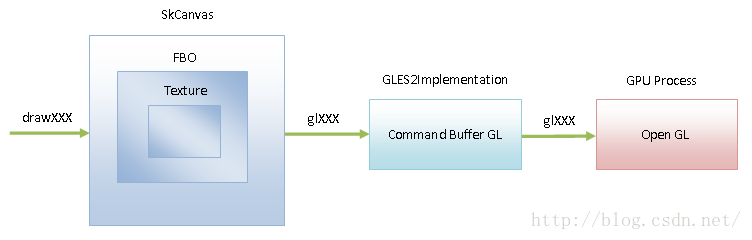
图2 GPU光栅化原理
纹理被绑定在一个FBO中。这个FBO再被封装为Skia图形库的SkCanvas类中。SkCanvas类描述的是一个画布,网页分块的绘制命令就是通过调用这个画布提供的绘图接口drawXXX来执行的。SkCanvas类的绘图接口drawXXX又是通过调用Command Buffer GL提供的接口glXXX实现的。
Command Buffer GL是Chromium提供的一套OpenGL接口。这套OpenGL接口由GLES2Implementation类实现,具体可以参考前面Chromium硬件加速渲染机制基础知识简要介绍和学习计划这个系列的文章。Command Buffer GL不是真的实现了OpenGL接口,它只是将通过Command Buffer将GPU命令转发给GPU进程执行。GPU进程会将通过Command Buffer接收到的GPU命令交给真实的OpenGL库执行。
理解GPU的光栅化原理,最关键的就是掌握以下两点:
1. SkCanvas是如何与Command Buffer GL建立起联系的?只有建立起这个联系之后,SkCanvas才可以将绘制命令交给Command Buffer GL执行。
2. SkCanvas是如何与FBO、Texture关联起来的?关联起来之后,SkCanvas才可以将绘制命令作用到纹理上。
接下来,我们就先分析这两个关键点,然后再分析SkCanvas执行绘制命令的过程。
从前面Chromium硬件加速渲染的OpenGL上下文创建过程分析一文可以知道,Render进程所使用的Command Buffer GL被封装在一个WebGraphicsContext3DCommandBufferImpl对象中。Render进程在使用这个WebGraphicsContext3DCommandBufferImpl对象所封装的Command Buffer GL之前,先调用它的成员函数makeContextCurrent激活该Command Buffer GL,如下所示:
bool WebGraphicsContext3DCommandBufferImpl::makeContextCurrent() {
if (!MaybeInitializeGL()) {
......
return false;
}
gles2::SetGLContext(GetGLInterface());
......
return true;
} WebGraphicsContext3DCommandBufferImpl类的成员函数makeContextCurrent首先调用另外一个成员函数MaybeInitializeGL检查当前使用的OpenGL上下文是否已经初始化过。如果还没有初始化,那么WebGraphicsContext3DCommandBufferImpl类的成员函数MaybeInitializeGL就会对其进行初始化,并且在初始化完成之后,创建一个Command Buffer GL接口。
WebGraphicsContext3DCommandBufferImpl类的成员函数makeContextCurrent接下来通过调用成员函数GetGLInterface获得上述Command Buffer GL调用接口,并且调用函数gles2::SetGLContext将其设置为当前线程的OpenGL调用接口。
接下来我们就继续分析WebGraphicsContext3DCommandBufferImpl类的成员函数MaybeInitializeGL和函数gles2::SetGLContext的实现。
WebGraphicsContext3DCommandBufferImpl类的成员函数MaybeInitializeGL的实现如下所示:
bool WebGraphicsContext3DCommandBufferImpl::MaybeInitializeGL() {
if (initialized_)
return true;
......
if (!CreateContext(surface_id_ != 0)) {
......
return false;
}
......
initialized_ = true;
return true;
} WebGraphicsContext3DCommandBufferImpl类的成员函数MaybeInitializeGL首先检查成员变量initialized_的值是否等于true。如果等于true,那么就说明当前使用的OpenGL上下文已经初始化过了。否则的话,就调用另外一个成员函数CreateContext进行初始化,并且在初始化成功后,将成员变量initialized_的值设置为true。
WebGraphicsContext3DCommandBufferImpl类的成员函数CreateContext的实现如下所示:
bool WebGraphicsContext3DCommandBufferImpl::CreateContext(bool onscreen) {
......
// Create the object exposing the OpenGL API.
bool bind_generates_resources = false;
real_gl_.reset(
new gpu::gles2::GLES2Implementation(gles2_helper_.get(),
gles2_share_group,
transfer_buffer_.get(),
bind_generates_resources,
lose_context_when_out_of_memory_,
command_buffer_.get()));
setGLInterface(real_gl_.get());
......
return true;
} WebGraphicsContext3DCommandBufferImpl类的成员函数CreateContext的详细分析可以参考前面Chromium硬件加速渲染的OpenGL上下文创建过程分析一文。这里我们观察到, WebGraphicsContext3DCommandBufferImpl类的成员函数CreateContext创建了一个GLES2Implementation对象,保存在成员变量real_gl_中。这个GLES2Implementation对象实现了Command Buffer GL接口。这个Command Buffer GL接口通过调用另外一个成员函数setGLInterface保存起来。
WebGraphicsContext3DCommandBufferImpl类的成员函数setGLInterface是从父类WebGraphicsContext3DImpl继承下来的,它的实现如下所示:
class WEBKIT_GPU_EXPORT WebGraphicsContext3DImpl
: public NON_EXPORTED_BASE(blink::WebGraphicsContext3D) {
public:
......
::gpu::gles2::GLES2Interface* GetGLInterface() {
return gl_;
}
protected:
......
void setGLInterface(::gpu::gles2::GLES2Interface* gl) {
gl_ = gl;
}
......
::gpu::gles2::GLES2Interface* gl_;
......
};WebGraphicsContext3DImpl类的成员函数setGLInterface将参数描述的Command Buffer GL接口保存在成员变量gl_中。这个Command Buffer GL接口可以通过调用WebGraphicsContext3DImpl类的另外一个成员函数GetGLInterface获得。
回到WebGraphicsContext3DCommandBufferImpl类的成员函数makeContextCurrent,它确保当前线程所使用的OpenGL上下文已经初始化了之后,接下来就会调用从父类WebGraphicsContext3DImpl继承下来的成员函数GetGLInterface获得前面所创建的Command Buffer GL接口,也就是一个GLES2Implementation对象,并且将该Command Buffer GL接口设置为当前线程的OpenGL调用接口。这是通过调用函数gles2::SetGLContext实现的,如下所示:
namespace gles2 {
......
// TODO(kbr): the use of this anonymous namespace core dumps the
// linker on Mac OS X 10.6 when the symbol ordering file is used
// namespace {
static gpu::ThreadLocalKey g_gl_context_key;
// } // namespace anonymous
......
void SetGLContext(gpu::gles2::GLES2Interface* context) {
gpu::ThreadLocalSetValue(g_gl_context_key, context);
}
......
}参数context描述的Command Buffer GL接口将被保存在全局变量g_gl_context_key所描述的一个线程局部储存中,作为当前线程所使用的OpenGL接口。以后通过调用另外一个函数gles2::GetGLContext就可以获得保存在这个线程局部储存中的Command Buffer GL接口,如下所示:
namespace gles2 {
......
gpu::gles2::GLES2Interface* GetGLContext() {
return static_cast<gpu::gles2::GLES2Interface*>(
gpu::ThreadLocalGetValue(g_gl_context_key));
}
......
}一般情况下,我们都是通过调用glXXX函数使用OpenGL的。如何确保在一个线程中调用glXXX函数时,使用的是前面所述的Command Buffer GL接口呢?
glXXX函数包含在<GLES2/gl2.h>头文件中,这个头文件又包含了另外一个头文件<GLES2/gl2chromium.h>,如下所示:
#ifdef __cplusplus
extern "C" {
#endif
......
#include <GLES2/gl2chromium.h>
......
#ifdef __cplusplus
}
#endif头文件<GLES2/gl2chromium.h>的定义如下所示:
......
// Because we are using both the real system GL and our own
// emulated GL we need to use different names to avoid conflicts.
#if defined(GLES2_USE_CPP_BINDINGS)
#define GLES2_GET_FUN(name) gles2::GetGLContext()->name
#else
#define GLES2_GET_FUN(name) GLES2 ## name
#endif
#endif
#include <GLES2/gl2chromium_autogen.h>
......这个头文件文件定义了一个宏GLES2_GET_FUN。这个宏分为C和C++两种实现,用来定义OpenGL函数。接下来我们会看到它的用法。
这个头文件又会包含另外一个头文件<GLES2/gl2chromium_autogen.h>,它的实现如下所示:
#define glActiveTexture GLES2_GET_FUN(ActiveTexture)
#define glAttachShader GLES2_GET_FUN(AttachShader)
.......
#define glScheduleOverlayPlaneCHROMIUM
GLES2_GET_FUN(ScheduleOverlayPlaneCHROMIUM)头文件<GLES2/gl2chromium_autogen.h>为每一个OpenGL函数glXXX都定义了一个同名的宏,这个宏在C++中被定义为gles2::GetGLContext()->XXX,在C中被定义为GLES2XXX。
以OpenGL函数glActiveTexture为例。将宏GLES2_GET_FUN展开后,就得到宏glActiveTexture在C++和C中的定义为gles2::GetGLContext()->ActiveTexture和GLES2ActiveTexture。
从前面的分析可以知道,函数gles2::GetGLContext返回的当前线程所使用的OpenGL接口。这个OpenGL接口实际上是一个Command Buffer GL接口,由一个GLES2Implementation对象实现。因此,当我们在C++中调用OpenGL函数glActiveTexture时,实际上是通过宏glActiveTexture调用了GLES2Implementation类的成员函数ActiveTexture。GLES2Implementation类的成员函数ActiveTexture所做的事情是通过Command Buffer将所执行的命令传递给GPU进程执行。
另一方面,当我们在C中调用OpenGL函数glActiveTexture时,实际上是通过宏glActiveTexture调用了函数GLES2ActiveTexture,这个函数的实现如下所示:
void GLES2ActiveTexture(GLenum texture) {
gles2::GetGLContext()->ActiveTexture(texture);
}从这里可以看到,函数GLES2ActiveTexture同样是通过调用GLES2Implementation类的成员函数ActiveTexture实现的。也就是无论我们是在C++还是C中调用OpenGL函数glXXX,最终都是通过同名的glXXX宏调用了GLES2Implementation类的成员函数XXX,也就是通过Command Buffer将GPU命令传递给GPU进程执行。
理解了将Command Buffer GL接口设置为当前线程所使用的OpenGL接口之后,接下来我们继续分析网页分块的GPU光栅化所使用的画布的创建过程。从前面Chromium网页光栅化过程分析一文可以知道,GPU光栅化所使用的画布是通过调用DirectRasterWorkerPool类的成员函数AcquireCanvasForRaster创建的,如下所示:
SkCanvas* DirectRasterWorkerPool::AcquireCanvasForRaster(RasterTask* task) {
return resource_provider_->MapDirectRasterBuffer(task->resource()->id());
}DirectRasterWorkerPool类的成员变量resource_provider_指向的是一个ResourceProvider对象,DirectRasterWorkerPool类的成员函数AcquireCanvasForRaster调用这个ResourceProvider对象的成员函数MapDirectRasterBuffer为参数task描述的光栅化任务创建一个画布,如下所示:
SkCanvas* ResourceProvider::MapDirectRasterBuffer(ResourceId id) {
// Resource needs to be locked for write since DirectRasterBuffer writes
// directly to it.
LockForWrite(id);
Resource* resource = GetResource(id);
if (!resource->direct_raster_buffer.get()) {
resource->direct_raster_buffer.reset(
new DirectRasterBuffer(resource, this, use_distance_field_text_));
}
return resource->direct_raster_buffer->LockForWrite();
}参数id描述的是一个资源ID。在GPU光栅化模式中,这个资源ID对应的是一个纹理资源。ResourceProvider对象的成员函数MapDirectRasterBuffer首先调用成员函数LockForWrite这个纹理资源是否已经创建。如果还没有创建,那么就会进行创建。创建之后,会封装在一个Resource对象中。这个Resource对象可以通过调用ResourceProvider类的成员函数GetResource获得。
如果前面获得的Resource对象的成员变量direct_raster_buffer的值等于NULL,那么就会创建一个DirectRasterBuffer对象保存在这个成员变量DirectRasterBuffer中。这个DirectRasterBuffer对象封装了参数id所描述的纹理资源,并且通过调用这个DirectRasterBuffer对象的成员函数LockForWrite就可以获得一个画布。这个画布就以参数id所描述的纹理资源为底层存储。
DirectRasterBuffer对象的成员函数LockForWrite是从父类RasterBuffer继承下来的,它的实现如下所示:
SkCanvas* ResourceProvider::RasterBuffer::LockForWrite() {
......
locked_canvas_ = DoLockForWrite();
......
return locked_canvas_;
}RasterBuffer类的成员函数LockForWrite调用由子类重写的成员函数DoLockForWrite获得一个SkCanvas对象。这个SkCanvas描述的就是一个画布。这个画布最后会返回给调用者。
在我们这个情景中,RasterBuffer类的成员函数LockForWrite调用的就是DirectRasterBuffer类的成员函数DoLockForWrite获得一个SkCanvas对象,它的实现如下所示:
SkCanvas* ResourceProvider::DirectRasterBuffer::DoLockForWrite() {
if (!surface_)
surface_ = CreateSurface();
surface_generation_id_ = surface_ ? surface_->generationID() : 0u;
return surface_ ? surface_->getCanvas() : NULL;
}DirectRasterBuffer类的成员函数DoLockForWrite首先检查成同变量surface_的值是否等于NULL。如果等于NULL,那么就会调用DirectRasterBuffer类的另外一个成员函数CreateSurface创建一个Skia Surface。有了这个Skia Surface之后,就可以调用它的成员函数getCanvas获得一个SkCanvas对象。
接下来我们继续分析DirectRasterBuffer类的成员函数CreateSurface的实现,以便了解Skia Surface的创建过程,如下所示:
skia::RefPtr<SkSurface> ResourceProvider::DirectRasterBuffer::CreateSurface() {
skia::RefPtr<SkSurface> surface;
switch (resource()->type) {
case GLTexture: {
DCHECK(resource()->gl_id);
class GrContext* gr_context = resource_provider()->GrContext();
if (gr_context) {
GrBackendTextureDesc desc;
desc.fFlags = kRenderTarget_GrBackendTextureFlag;
desc.fWidth = resource()->size.width();
desc.fHeight = resource()->size.height();
desc.fConfig = ToGrPixelConfig(resource()->format);
desc.fOrigin = kTopLeft_GrSurfaceOrigin;
desc.fTextureHandle = resource()->gl_id;
skia::RefPtr<GrTexture> gr_texture =
skia::AdoptRef(gr_context->wrapBackendTexture(desc));
SkSurface::TextRenderMode text_render_mode =
use_distance_field_text_ ? SkSurface::kDistanceField_TextRenderMode
: SkSurface::kStandard_TextRenderMode;
surface = skia::AdoptRef(SkSurface::NewRenderTargetDirect(
gr_texture->asRenderTarget(), text_render_mode));
}
break;
}
case Bitmap: {
DCHECK(resource()->pixels);
DCHECK_EQ(RGBA_8888, resource()->format);
SkImageInfo image_info = SkImageInfo::MakeN32Premul(
resource()->size.width(), resource()->size.height());
surface = skia::AdoptRef(SkSurface::NewRasterDirect(
image_info, resource()->pixels, image_info.minRowBytes()));
break;
}
default:
NOTREACHED();
}
return surface;
}DirectRasterBuffer类的成员函数CreateSurface首先调用成员函数resource获得它所封装的资源的类型。如果是一个纹理资源,那么就会创建一个类型为SkSurface_Gpu的Skia Surface。如果是一个Bitmap资源,那么就会创建一个类型为SkSurface_Raster的Skia Surface。
类型为SkSurface_Raster的Skia Surface的底层存储是一块系统内存,调用它的成员函数getCanvas获得的画布也是以这块系统内存为底层存储的。这块系统内存由前面获得的资源对象的成员变量pixels描述。有了这块系统内存,就可以调用SkSurface类的静态成员函数NewRasterDirect创建一个类型为SkSurface_Raster的Skia Surface。
类型为SkSurface_Gpu的Skia Surface的底层存储是一个纹理对象,调用它的成员函数getCanvas获得的画布也是以这个纹理对象为底层存储的。这个纹理对象的ID由前面获得的资源对象的成员变量gl_id描述。
在GPU光栅化模式中,DirectRasterBuffer类的成员函数CreateSurface调用成员函数resource获得的是一个纹理资源,因此接下来我们只关注类型为SkSurface_Gpu的Skia Surface的创建过程。
DirectRasterBuffer类的成员函数CreateSurface首先调用成员函数resource_provider获得一个ResourceProvider对象,并且调用这个ResourceProvider对象的成员函数GrContext对象。有了这个GrContext对象之后,DirectRasterBuffer类的成员函数CreateSurface主要做四件事情:
1. 将纹理信息,包含纹理宽度、高度和ID等信息,封装在一个GrBackendTextureDesc对象中。
2. 调用前面获得的GrContext对象的成员函数wrapBackendTexture根据上述GrBackendTextureDesc对象描述的纹理信息创建一个GrTexture对象。
3. 调用上述GrTexture对象的成员函数asRenderTarget获得一个GrRenderTarget对象。
4. 调用SkSurface类的静态成员函数NewRenderTargetDirect根据上述GrRenderTarget对象创建一个类型为SkSurface_Gpu的Skia Surface。
接下来我们就分别分析ResourceProvider类的成员函数GrContext、GrContext类的成员函数wrapBackendTexture、GrTexture类的成员函数asRenderTarget和SkSurface类的静态成员函数NewRenderTargetDirect的实现,以便了解类型为SkSurface_Gpu的Skia Surface的创建过程,
ResourceProvider类的成员函数GrContext的实现如下所示:
class GrContext* ResourceProvider::GrContext() const {
ContextProvider* context_provider = output_surface_->context_provider();
return context_provider ? context_provider->GrContext() : NULL;
}ResourceProvider类的成员变量output_surface_指向的是一个CompositorOutputSurface对象。这个CompositorOutputSurface对象描述的就是当前加载网页的绘图表面,它的创建过程可以参考前面Chromium网页绘图表面(Output Surface)创建过程分析和Chromium的GPU进程启动过程分析这两篇文章。
调用上述CompositorOutputSurface对象的成员函数context_provider可以获得一个ContextProviderCommandBuffer对象。这个ContextProviderCommandBuffer对象的创建过程可以参考前面Chromium的GPU进程启动过程分析一文,
ResourceProvider类的成员函数GrContext最后调用上述ContextProviderCommandBuffer对象的成员函数GrContext获得一个GrContext对象,并且返回给调用者。
接下来我们就继续分析ContextProviderCommandBuffer类的成员函数GrContext的实现,以便了解GrContext对象的创建过程,如下所示:
class GrContext* ContextProviderCommandBuffer::GrContext() {
......
if (gr_context_)
return gr_context_->get();
gr_context_.reset(
new webkit::gpu::GrContextForWebGraphicsContext3D(context3d_.get()));
return gr_context_->get();
}这个函数定义在文件external/chromium_org/content/common/gpu/client/context_provider_command_buffer.cc中。
ContextProviderCommandBuffer类的成员函数GrContext首先判断成员变量gr_context_的值是否不等于NULL。如果不等于NULL,那么它指向的是一个GrContextForWebGraphicsContext3D对象。调用这个GrContextForWebGraphicsContext3D对象的成员函数get可以获得一个GrContext对象。这个GrContext对象将会返回给调用者。
如果ContextProviderCommandBuffer类的成员变量gr_context_的值等于NULL,那么ContextProviderCommandBuffer类的成员函数GrContext就先会创建一个GrContextForWebGraphicsContext3D对象保存在成员变量gr_context_,然后再调用这个GrContextForWebGraphicsContext3D对象的成员函数get获得一个GrContext对象返回给调用者。
在创建GrContextForWebGraphicsContext3D对象的时候,需要使用到ContextProviderCommandBuffer类的成员变量context3d_。这个成员变量指向的是一个WebGraphicsContext3DCommandBufferImpl对象。这个WebGraphicsContext3DCommandBufferImpl对象的创建过程可以参考前面Chromium的GPU进程启动过程分析一文。
GrContextForWebGraphicsContext3D对象的创建过程,也就是GrContextForWebGraphicsContext3D类的构造函数的实现,如下所示:
GrContextForWebGraphicsContext3D::GrContextForWebGraphicsContext3D(
blink::WebGraphicsContext3D* context3d) {
......
skia::RefPtr<GrGLInterface> interface = skia::AdoptRef(
context3d->createGrGLInterface());
......
gr_context_ = skia::AdoptRef(GrContext::Create(
kOpenGL_GrBackend,
reinterpret_cast<GrBackendContext>(interface.get())));
......
}GrContextForWebGraphicsContext3D类的构造函数首先调用参数context3d指向的一个WebGraphicsContext3DCommandBufferImpl对象的成员函数createGrGLInterface创建一个OpenGL接口,接着又调用GrContext类的静态成员函数Create将这个OpenGL接口封装在一个GrContext对象中。
上面创建的GrContext对象将会保存在GrContextForWebGraphicsContext3D类的成员变量gr_context_中,并且通过调用GrContextForWebGraphicsContext3D类的成员函数get可以获得该GrContext对象,如下所示:
class WEBKIT_GPU_EXPORT GrContextForWebGraphicsContext3D {
public:
......
GrContext* get() { return gr_context_.get(); }
......
private:
skia::RefPtr<class GrContext> gr_context_;
......
};从这里可以看到,GrContextForWebGraphicsContext3D类的成员函数get返回的是成员变量gr_context_指向的GrContext对象。
回到GrContextForWebGraphicsContext3D类的构造函数中,接下来我们继续分析WebGraphicsContext3DCommandBufferImpl类的成员函数createGrGLInterface创建OpenGL接口的过程,以及GrContext类的静态成员函数Create创建GrContext对象的过程。
WebGraphicsContext3DCommandBufferImpl类的成员函数createGrGLInterface是从父类WebGraphicsContext3DImpl继承下来的,它的实现如下所示:
GrGLInterface* WebGraphicsContext3DImpl::createGrGLInterface() {
makeContextCurrent();
return skia_bindings::CreateCommandBufferSkiaGLBinding();
}WebGraphicsContext3DImpl类的成员函数createGrGLInterface通过调用另外一个函数CreateCommandBufferSkiaGLBinding来创建一个OpenGL接口,如下所示:
GrGLInterface* CreateCommandBufferSkiaGLBinding() {
GrGLInterface* interface = new GrGLInterface;
......
GrGLInterface::Functions* functions = &interface->fFunctions;
functions->fActiveTexture = glActiveTexture;
......
functions->fGenerateMipmap = glGenerateMipmap;
return interface;
}函数CreateCommandBufferSkiaGLBinding创建了一个GrGLInterface对象来描述OpenGL接口。这个GrGLInterface对象的成员变量fFunctions描述的是一个OpenGL函数表。这个函数表的每一个入口都代表一个OpenGL调用,被设置为对应的glXXX函数。
从前面的分析可以知道,glXXX实际是一个宏。这个宏展开后,代表的是GLES2Implementation类的对应的成员函数XXX。这意味着函数CreateCommandBufferSkiaGLBinding创建的是一个Command Buffer GL接口。
回到GrContextForWebGraphicsContext3D类的构造函数中,它获得了一个Command Buffer GL接口之后,就会调用GrContext类的静态成员函数Create将这个Command Buffer GL接口封装在一个GrContext对象,如下所示:
GrContext* GrContext::Create(GrBackend backend, GrBackendContext backendContext) {
GrContext* context = SkNEW(GrContext);
if (context->init(backend, backendContext)) {
return context;
}
......
}GrContext类的静态成员函数Create首先通过宏SkNEW创建了一个GrContext对象,接着再调用这个GrContext对象的成员函数init对其进行初始化。初始化完成后,再将上述GrContext对象返回给调用者。
GrContext对象的初始化过程,也就是GrContext类的成员函数init的实现,如下所示:
bool GrContext::init(GrBackend backend, GrBackendContext backendContext) {
......
fGpu = GrGpu::Create(backend, backendContext, this);
......
return true;
}GrContext类的成员函数init主要是调用GrGpu类的静态成员函数Create创建了一个GrGpuGL对象,并且保存在成员变量fGpu中。
GrGpu类的静态成员函数Create的实现如下所示:
GrGpu* GrGpu::Create(GrBackend backend, GrBackendContext backendContext, GrContext* context) {
const GrGLInterface* glInterface = NULL;
......
if (kOpenGL_GrBackend == backend) {
glInterface = reinterpret_cast<const GrGLInterface*>(backendContext);
......
GrGLContext ctx(glInterface);
if (ctx.isInitialized()) {
return SkNEW_ARGS(GrGpuGL, (ctx, context));
}
}
return NULL;
}从前面的调用过程可以知道,第一个参数backend的值等于kOpenGL_GrBackend,第二参数backendContext描述的是一个Command Buffer GL接口,第三个参数context指向的是一个GrContext对象。
GrGpu类的静态成员函数Create主要是做两件事情。第一件事情是使用参数backendContext描述的Command Buffer GL接口,也就是一个GrGLInterface对象,创建和初始化另外一个GrGLContext对象。第二件事情是在上述GrGLContext对象创建和初始化成功之后,将它以及参数context指向的GrContext对象封装在一个GrGpuGL对象中,并且将该GrGpuGL对象返回给调用者。
GrGLContext对象的创建过程,也就是GrGLContext类的构造函数的实现,如下所示:
class GrGLContext : public GrGLContextInfo {
public:
......
explicit GrGLContext(const GrGLInterface* interface) {
this->initialize(interface);
}
......
};GrGLContext类的构造函数调用从父类GrGLContextInfo继承下来的成员函数initialize执行初始化工作,如下所示:
bool GrGLContextInfo::initialize(const GrGLInterface* interface) {
......
// We haven't validated the GrGLInterface yet, so check for GetString
// function pointer
if (interface->fFunctions.fGetString) {
......
if (interface->validate()) {
......
// This must occur before caps init.
fInterface.reset(SkRef(interface));
return fGLCaps->init(*this, interface);
}
}
return false;
} GrGLContextInfo类的成员函数initialize首先验证参数interface描述的Command Buffer GL接口的正确性,也就是确保该参数指向的GrGLInterface对象的成员变量fFunctions描述的OpenGL函数表已经被初始化。在已经初始化的情况下,GrGLContextInfo类的成员函数initialize就将它保存在成员变量fInterface中。这意味着GrGLContextInfo类的成员变量fInterface指向的是一个GrGLInterface对象。这个GrGLInterface对象描述的是一个Command Buffer GL接口。
回到GrGpu类的静态成员函数Create中,它构造了一个GrGLContext对象之后,接着再使用这个GrGLContext对象以及参数context指向的GrContext对象创建一个GrGpuGL对象,如下所示:
GrGpuGL::GrGpuGL(const GrGLContext& ctx, GrContext* context)
: GrGpu(context)
, fGLContext(ctx) {
......
}GrGpuGL类的构造函数除了将参数ctx描述的一个GrGLContext对象保存在成员变量fGLContext中之外,还调用了父类GrGPU的构造函数执行其它的初始化工作,如下所示:
GrGpu::GrGpu(GrContext* context)
: GrDrawTarget(context)
, ...... {
......
}GrGPU类的构造函数主要是调用父类GrDrawTarget的构造函数执行初始化工作,如下所示:
GrDrawTarget::GrDrawTarget(GrContext* context)
: .....
, fContext(context
, ...... {
......
}GrDrawTarget类的构造函数主要是将参数context指向的GrContext对象保存在成员变量fContext中。
这一步执行完成之后,我们就获得了一个GrContext对象。这个GrContext对象的成员变量fGpu指向了一个GrGpuGL对象。这个GrGpuGL对象又通过其父类GrGpu的的成员变量fGLContext指向了一个GrGLContext对象。这个GrGLContext对象又通过其父类GrGLContextInfo的成员变量fInterface指向了一个Command Buffer GL接口。这意味着GrContext类间接地封装了Command Buffer GL接口。
此外,一个GrGpuGL对象又会通过其父类GrDrawTarget的成员变量fContext指向了一个GrContext对象。这同样意味着GrGpuGL类间接封装了Command Buffer GL接口。
回到DirectRasterBuffer类的成员函数CreateSurface中,它通过ResourceProvider类的成员函数GrContext获得了一个GrContext对象之后, 接下来就会调用这个GrContext对象的成员函数wrapBackendTexture将一个纹理资源封装在一个GrTexture对象中,如下所示:
GrTexture* GrContext::wrapBackendTexture(const GrBackendTextureDesc& desc) {
return fGpu->wrapBackendTexture(desc);
}从前面的分析可以知道,GrContext类的成员变量fGpu指向的是一个GrGpuGL对象。GrContext类的成员函数wrapBackendTexture调用这个GrGpuGL对象的成员函数wrapBackendTexture将参数desc描述的纹理资源封装在一个GrTextrue对象中。
GrGpuGL类的成员函数wrapBackendTexture是从父类GrGpu继承下来的,它的实现如下所示:
GrTexture* GrGpu::wrapBackendTexture(const GrBackendTextureDesc& desc) {
......
GrTexture* tex = this->onWrapBackendTexture(desc);
......
GrRenderTarget* tgt = tex->asRenderTarget();
if (NULL != tgt &&
!this->attachStencilBufferToRenderTarget(tgt)) {
tex->unref();
return NULL;
} else {
return tex;
}
}GrGpu类的成员函数wrapBackendTexture首先是调用由子类GrGpuGL实现的成员函数onWrapBackendTexture将参数desc描述的纹理资源封装在一个GrTexture对象中,接下来再调用获得的GrTexture对象的成员函数asRenderTarget获得一个GrRenderTarget对象。有了这个GrRenderTarget对象之后,再通过调用GrGpu类的成员函数attachStencilBufferToRenderTarget为其关联一个Stencil Buffer。
接下来我们主要分析GrGpuGL类的成员函数onWrapBackendTexture的实现,以便了解将纹理资源封装成GrTexture对象的过程。在这个过程中,我们就可以看到上述GrRenderTarget对象的含义。
GrGpuGL类的成员函数onWrapBackendTexture的实现如下所示:
GrTexture* GrGpuGL::onWrapBackendTexture(const GrBackendTextureDesc& desc) {
......
GrGLTexture::Desc glTexDesc;
// next line relies on GrBackendTextureDesc's flags matching GrTexture's
glTexDesc.fFlags = (GrTextureFlags) desc.fFlags;
glTexDesc.fWidth = desc.fWidth;
glTexDesc.fHeight = desc.fHeight;
......
glTexDesc.fTextureID = static_cast<GrGLuint>(desc.fTextureHandle);
......
bool renderTarget = SkToBool(desc.fFlags & kRenderTarget_GrBackendTextureFlag);
......
GrGLTexture* texture = NULL;
if (renderTarget) {
GrGLRenderTarget::Desc glRTDesc;
glRTDesc.fRTFBOID = 0;
glRTDesc.fTexFBOID = 0;
glRTDesc.fMSColorRenderbufferID = 0;
glRTDesc.fConfig = desc.fConfig;
glRTDesc.fSampleCnt = desc.fSampleCnt;
glRTDesc.fOrigin = glTexDesc.fOrigin;
glRTDesc.fCheckAllocation = false;
if (!this->createRenderTargetObjects(glTexDesc.fWidth,
glTexDesc.fHeight,
glTexDesc.fTextureID,
&glRTDesc)) {
return NULL;
}
texture = SkNEW_ARGS(GrGLTexture, (this, glTexDesc, glRTDesc));
} else {
texture = SkNEW_ARGS(GrGLTexture, (this, glTexDesc));
}
......
return texture;
}GrGpuGL类的成员函数onWrapBackendTexture主要是将参数desc描述的纹理资源封装在一个GrGLTexture对象中。GrGLTexture类是从GrTexture类继承下来的,因此GrGpuGL类的成员函数onWrapBackendTexture可以将GrGLTexture对象当作GrTexture对象返回给调用者。
如果参数desc描述的纹理资源设置了kRenderTarget_GrBackendTextureFlag标记,那么就表示要将该纹理资源关联一个FBO。这个FBO通过调用GrGpuGL类的成员函数createRenderTargetObjects创建。一个纹理资源只有在关联FBO的情况下,才可以作为画布的底层存储,也就是才可以用来光栅化网页分块。否则的话,它就只能作为一个简单的纹理使用。
在我们这个情景中,参数desc描述的纹理资源是用来光栅化网页分块的,因此它设置了kRenderTarget_GrBackendTextureFlag标记。接下来我们就继续分析GrGpuGL类的成员函数createRenderTargetObjects的实现,以便了解为纹理资源关联FBO的过程。
GrGpuGL类的成员函数createRenderTargetObjects的实现如下所示:
bool GrGpuGL::createRenderTargetObjects(int width, int height,
GrGLuint texID,
GrGLRenderTarget::Desc* desc) {
......
desc->fTexFBOID = 0;
......
GL_CALL(GenFramebuffers(1, &desc->fTexFBOID));
......
GL_CALL(BindFramebuffer(GR_GL_FRAMEBUFFER, desc->fTexFBOID));
......
if (this->glCaps().usesImplicitMSAAResolve() && desc->fSampleCnt > 0) {
GL_CALL(FramebufferTexture2DMultisample(GR_GL_FRAMEBUFFER,
GR_GL_COLOR_ATTACHMENT0,
GR_GL_TEXTURE_2D,
texID, 0, desc->fSampleCnt));
} else {
GL_CALL(FramebufferTexture2D(GR_GL_FRAMEBUFFER,
GR_GL_COLOR_ATTACHMENT0,
GR_GL_TEXTURE_2D,
texID, 0));
}
......
return true;
FAILED:
......
return false;
}这个函数定义在文件external/chromium_org/third_party/skia/src/gpu/gl/GrGpuGL.cpp中。
GrGpuGL类的成员函数createRenderTargetObjects是通过宏GL_CALL来调用Command Buffer GL接口的,它的定义如下所示:
#define GL_CALL(X) GR_GL_CALL(this->glInterface(), X)宏GL_CALL又是通过另外一个宏GR_GL_CALL来调用Command Buffer GL接口X的。宏GR_GL_CALL的第一个参数是调用GrGpuGL类的成员函数glInterface获得的返回值,第二个参数是指定要调用的Command Buffer GL接口X。
GrGpuGL类的成员函数glInterface的定义如下所示:
class GrGpuGL : public GrGpu {
public:
......
const GrGLInterface* glInterface() const { return fGLContext.interface(); }
......
};从前面的分析可以知道,GrGpuGL类的成员函变量fGLContext描述的是一个GrGLContext对象。GrGpuGL类的成员函数glInterface调用这个GrGLContext对象的成员函数interface获得一个GrGLInterface对象,然后返回给调用者。
GrGLContext类的成员函数interface的实现如下所示:
class GrGLContext : public GrGLContextInfo {
public:
......
const GrGLInterface* interface() const { return fInterface.get(); }
......
}; GrGLContext类的成员函数interface返回的是从父类GrGLContextInfo继承下来的成员变量fInterface指向的一个GrGLInterface对象。从前面的分析可以知道,这个GrGLInterface对象描述的正是一个Command Buffer GL接口。
接下来我们再来看宏GR_GL_CALL的定义,如下所示:
// makes a GL call on the interface and does any error checking and logging
#define GR_GL_CALL(IFACE, X)
do {
GR_GL_CALL_NOERRCHECK(IFACE, X);
GR_GL_CHECK_ERROR_IMPL(IFACE, X);
} while (false)宏GR_GL_CALL首先通过宏GR_GL_CALL_NOERRCHECK调用Command Buffer GL接口IFACE提供的OpenGL函数X,接着再通过宏GR_GL_CHECK_ERROR_IMPL检查调用结果。我们主要关注宏GR_GL_CALL_NOERRCHECK的实现,如下所示:
// Variant of above that always skips the error check. This is useful when
// the caller wants to do its own glGetError() call and examine the error value.
#define GR_GL_CALL_NOERRCHECK(IFACE, X)
do {
GR_GL_CALLBACK_IMPL(IFACE);
(IFACE)->fFunctions.f##X;
GR_GL_LOG_CALLS_IMPL(X);
} while (false)宏GR_GL_CALL_NOERRCHECK主要做的事情就是在参数IFACE描述的Command Buffer GL接口的OpenGL函数表fFunctions中找到名称为fX的函数,并且进行调用。这个OpenGL函数表的设置可以参考前面分析的函数CreateCommandBufferSkiaGLBinding。这些OpenGL函数实际上就是对应于GLES2Implementation类的各个成员函数。
宏GR_GL_CALL_NOERRCHECK在调用指定的OpenGL函数之前,还会通过另外一个宏GR_GL_CALLBACK_IMPL调用记录在参数IFACE描述的Command Buffer GL接口中的一个Callback函数,让其有机会在OpenGL函数执行之前做一些工作。
宏GR_GL_CALL_NOERRCHECK在调用指定的OpenGL函数之后,还会通过另外一个宏GR_GL_LOG_CALLS_IMPL输出一个日志,用来记录此次OpenGL函数调用。
理解了宏GL_CALL的定义之后,回到GrGpuGL类的成员函数createRenderTargetObjects中,它的执行过程如下所示:
1. 调用Command Buffer GL接口GenFramebuffers生成一个FBO,并且将该FBO的ID记录在参数desc描述的一个GrGLRenderTarget::Desc对象的成员变量fTexFBOID中。
2. 调用Command Buffer GL接口BindFramebuffer激活第1步生成的FBO,这意味着接下来的操作都是与这个FBO相关的。
3. 判断Command Buffer GL接口是否支持多重采样(Multisample)反锯齿纹理。如果支持,并且参数desc指定了采样数(Sample Count),那么就会调用Command Buffer GL接口FramebufferTexture2DMultisample将参数textID描述的纹理绑定到第1步生成的FBO上。其余情况下,则调用Command Buffer GL接口FramebufferTexture2D将参数textID描述的纹理绑定到第1步生成的FBO上。这意味着第1步生成的FBO是以参数textID描述的纹理为底层存储的。也就是说,我们对第1步生成的FBO进行渲染时,渲染的结果就保存在参数textID描述的纹理中。
这一步执行完成之后,回到GrGpuGL类的成员函数onWrapBackendTexture中,这时候它就会创建一个GrGLTexture对象,如下所示:
GrGLTexture::GrGLTexture(GrGpuGL* gpu,
const Desc& textureDesc,
const GrGLRenderTarget::Desc& rtDesc)
: INHERITED(gpu, textureDesc.fIsWrapped, textureDesc) {
this->init(gpu, textureDesc, &rtDesc);
}GrGLTexture类的构造函数首先调用父类GrTexture的构造函数执行一部分初始化工作,如下所示:
class GrTexture : public GrSurface {
public:
......
protected:
// A texture refs its rt representation but not vice-versa. It is up to
// the subclass constructor to initialize this pointer.
SkAutoTUnref<GrRenderTarget> fRenderTarget;
GrTexture(GrGpu* gpu, bool isWrapped, const GrTextureDesc& desc)
: INHERITED(gpu, isWrapped, desc)
, fRenderTarget(NULL) {
......
}
......
};GrTexture类的构造函数除了将成员变量fRenderTarget设置为NULL之外,还调用了父类GrSurface的构造函数执行其它的初始化工作,如下所示:
class GrSurface : public GrGpuObject {
public:
......
protected:
GrSurface(GrGpu* gpu, bool isWrapped, const GrTextureDesc& desc)
: INHERITED(gpu, isWrapped)
, fDesc(desc) {
}
GrTextureDesc fDesc;
......
};从前面的调用过程可以知道,参数desc指向的是一个GrTextureDesc对象。这个GrTextureDesc对象描述了一个纹理,它将会保存在GrSurface类的成员变量fDesc中。GrSurface类的构造函数还会调用父类GrGpuObject的构造函数继承执行其它初始化工作,如下所示:
GrGpuObject::GrGpuObject(GrGpu* gpu, bool isWrapped) {
fGpu = gpu;
......
}从前面的调用过程可以知道,参数gpu指向的是一个GrGpuGL对象,这个GrGpuGL对象将会保存在GrGpuObject类的成员变量fGpu中。
这一步执行完成后,回到GrGLTexture类的构造函数中,它接下来调用成员函数init创建一个GrGLRenderTarget对象,如下所示:
void GrGLTexture::init(GrGpuGL* gpu,
const Desc& textureDesc,
const GrGLRenderTarget::Desc* rtDesc) {
......
if (NULL != rtDesc) {
GrGLIRect vp;
vp.fLeft = 0;
vp.fWidth = textureDesc.fWidth;
vp.fBottom = 0;
vp.fHeight = textureDesc.fHeight;
fRenderTarget.reset(SkNEW_ARGS(GrGLRenderTarget, (gpu, *rtDesc, vp, fTexIDObj, this)));
}
}创建出来的GrGLRenderTarget对象保存在GrGLTexture类的成员变量fRenderTarget中。从前面的分析可以知道,这个成员变量是从父类GrTexture继承下来的。这个GrGLRenderTarget对象描述了一个FBO。这个FBO就是用来光栅化网页分块的。
接下来我们分析GrGLRenderTarget对象的创建过程,也就是GrGLRenderTarget类的构造函数的实现,如下所示:
GrGLRenderTarget::GrGLRenderTarget(GrGpuGL* gpu,
const Desc& desc,
const GrGLIRect& viewport,
GrGLTexID* texID,
GrGLTexture* texture)
: INHERITED(gpu,
desc.fIsWrapped,
texture,
MakeDesc(kNone_GrTextureFlags,
viewport.fWidth, viewport.fHeight,
desc.fConfig, desc.fSampleCnt,
desc.fOrigin)) {
......
this->init(desc, viewport, texID);
}GrGLRenderTarget类的构造函数首先调用父类GrRenderTarget的构造函数执行一部分初始化工作,接着再调用成员函数init执行另一部分初始化工作。
GrRenderTarget类的构造函数的实现如下所示:
class GrRenderTarget : public GrSurface {
public:
......
protected:
GrRenderTarget(GrGpu* gpu,
bool isWrapped,
GrTexture* texture,
const GrTextureDesc& desc)
: INHERITED(gpu, isWrapped, desc)
, ......
, fTexture(texture) {
......
}
......
private:
.....
GrTexture* fTexture; // not ref'ed
......
};从前面的调用过程可以知道,参数texture指向的是一个GrGLTexture对象,这个GrGLTexture对象将会保存在GrRenderTarget类的成员变量fTexture中。此外,GrRenderTarget类的构造函数还会调用父类GrSurface的构造函数执行其它的初始化工作。GrSurface类的构造函数我们前面已经分析过,这里不再复述。
这一步执行完成之后,回到GrGLRenderTarget类的构造函数中,接下来它调用成员函数init执行剩余的初始化工作,如下所示:
void GrGLRenderTarget::init(const Desc& desc,
const GrGLIRect& viewport,
GrGLTexID* texID) {
......
fTexFBOID = desc.fTexFBOID;
......
fViewport = viewport;
fTexIDObj.reset(SkSafeRef(texID));
}GrGLRenderTarget类的成员函数init主要是做以下三件事情:
1. 将参数desc描述的FBO的ID记录在成员变量fTexFBOID中。
2. 将参数viewport描述的FBO大小记录在成员变量fViewport中,这个大小即为一个网页分块的大小。
3. 将参数textID描述的纹理的ID记录在成员变量fTextIDObj中。
这一步执行完成之后,就将分配一个网页分块的纹理资源封装成了一个GrGLTexture对象。这个GrGLTexture对象通过从父类GrTexture继承下来的成员变量fRenderTarget指向一个GrGLRenderTarget对象。这个GrGLRenderTarget对象描述的是一个FBO。这个FBO就是用来光栅化网页分块的。
回到DirectRasterBuffer类的成员函数CreateSurface中,它接下来就调用前面所述的GrGLTexture对象的成员函数asRenderTarget获得一个GrRenderTarget对象。这个GrRenderTarget对象接下来将会用来创建一个类型为SkSurface_Gpu的Skia Surface。
GrGLTexture类的成员函数asRenderTarget是从父类GrLTexture继承下来的,它的实现如下所示:
class GrTexture : public GrSurface {
public:
.....
virtual GrRenderTarget* asRenderTarget() SK_OVERRIDE { return fRenderTarget.get(); }
......
}从这里可以看到,GrLTexture类的成员函数asRenderTarget返回的是成员变量fRenderTarget描述的一个GrRenderTarget对象。从前面的分析可以知道,这实际上是一个GrGLRenderTarget对象。
这一步执行完成后,再回到DirectRasterBuffer类的成员函数CreateSurface中,它接下来就会根据前面获得的GrGLRenderTarget对象创建一个类型为SkSurface_Gpu的Skia Surface,这是通过调用SkSurface类的静态成员函数NewRenderTargetDirect实现的,如下所示:
SkSurface* SkSurface::NewRenderTargetDirect(GrRenderTarget* target, TextRenderMode trm) {
if (NULL == target) {
return NULL;
}
return SkNEW_ARGS(SkSurface_Gpu, (target, false, trm));
}创建类型为SkSurface_Gpu的Skia Surface是需要用到一个GrRenderTarget对象的,因此参数target的值不能等于NULL。在这种情况下,SkSurface类的静态成员函数NewRenderTargetDirect创建了一个SkSurface_Gpu对象,并且返回给调用者。
SkSurface_Gpu对象的创建过程,也就是SkSurface_Gpu类的构造函数的实现,如下所示:
SkSurface_Gpu::SkSurface_Gpu(GrRenderTarget* renderTarget, bool cached, TextRenderMode trm)
: INHERITED(renderTarget->width(), renderTarget->height()) {
......
fDevice = SkGpuDevice::Create(renderTarget, flags);
......
}SkSurface_Gpu类的构造函数主要是创建了一个SkGpuDevice对象,并且保存在成员变量fDevice中。这个SkGpuDevice对象是通过调用SkGpuDevice类的静态成员函数Create创建的,如下所示:
SkGpuDevice* SkGpuDevice::Create(GrSurface* surface, unsigned flags) {
......
if (surface->asTexture()) {
return SkNEW_ARGS(SkGpuDevice, (surface->getContext(), surface->asTexture(), flags));
} else {
return SkNEW_ARGS(SkGpuDevice, (surface->getContext(), surface->asRenderTarget(), flags));
}
}从前面的调用过程可以知道,参数surface指向的实际上是一个GrGLRenderTarget对象,因此SkGpuDevice类的静态成员函数Create会通过else子句来创建一个SkGpuDevice对象,如下所示:
SkGpuDevice::SkGpuDevice(GrContext* context, GrRenderTarget* renderTarget, unsigned flags)
: SkBitmapDevice(make_bitmap(context, renderTarget)) {
this->initFromRenderTarget(context, renderTarget, flags);
}SkGpuDevice类的构造函数主要是调用另外一个成员函数initFromRenderTarget执行初始化工作,如下所示:
void SkGpuDevice::initFromRenderTarget(GrContext* context,
GrRenderTarget* renderTarget,
unsigned flags) {
......
fContext = context;
fContext->ref();
......
fRenderTarget = renderTarget;
fRenderTarget->ref();
......
GrSurface* surface = fRenderTarget->asTexture();
......
SkPixelRef* pr = SkNEW_ARGS(SkGrPixelRef,
(surface->info(), surface, SkToBool(flags & kCached_Flag)));
this->setPixelRef(pr)->unref();
}SkGpuDevice类的成员函数initFromRenderTarget首先将参数context指向的一个GrContext对象保存在成员变量fContext中,并且增加这个GrContext对象的引用计数。
SkGpuDevice类的成员函数initFromRenderTarget接下来又将参renderTarget指向的一个GrGLRenderTarget对象保存在成员变量fRenderTarget中,并且增加这个GrGLRenderTarget对象的引用计数。
SkGpuDevice类的成员函数initFromRenderTarget再接下来调用上述GrGLRenderTarget对象的成员函数asTexture获得一个GrTexture对象。这个GrTexture对象接下来将会用来创建一个SkGrPixelRef对象。
GrGLRenderTarget类的成员函数asTexture是从父类GrRenderTarget继承下来的,它的实现如下所示:
class GrRenderTarget : public GrSurface {
public:
......
virtual GrTexture* asTexture() SK_OVERRIDE { return fTexture; }
......
};从前面的分析可以知道,GrRenderTarget类的成员变量fTexture指向的实际上是一个GrGLTexture对象。GrRenderTarget类的成员函数asTexture将这个GrGLTexture对象将返回调用者。
回到SkGpuDevice类的成员函数initFromRenderTarget中,它获得了一个GrGLTexture对象之后,接下来就使用这个GrGLTexture对象创建一个SkGrPixelRef对象,如下所示:
SkGrPixelRef::SkGrPixelRef(const SkImageInfo& info, GrSurface* surface,
bool transferCacheLock) : INHERITED(info) {
......
if (NULL == fSurface) {
fSurface = surface;
}
......
}SkGrPixelRef类的构造函数主要是将参数surface指向的一个GrGLTexture对象保存在成员变量fSurface中。这意味当前正在创建的SkGrPixelRef对象封装的是一个纹理对象。
再回到SkGpuDevice类的成员函数initFromRenderTarget中,它接下来将前面创建的SkGrPixelRef对象交给父类SkBitmapDevice管理。这是通过调用父类SkBitmapDevice的成员函数setPixelRef实现的,如下所示:
class SK_API SkBitmapDevice : public SkBaseDevice {
public:
......
protected:
......
SkPixelRef* setPixelRef(SkPixelRef* pr) {
fBitmap.setPixelRef(pr);
return pr;
}
......
private:
......
SkBitmap fBitmap;
......
};SkBitmapDevice类的成员函数setPixelRef将参数pr指向的SkGrPixelRef对象设置给成员变量fBitmap描述的一个SkBitmap对象管理。这是通过调用SkBitmap类的成员函数setPixelRef实现的, 如下所示:
class SK_API SkBitmap {
public:
......
SkPixelRef* setPixelRef(SkPixelRef* pr) {
return this->setPixelRef(pr, 0, 0);
}
......
};SkBitmap类的成员函数setPixelRef调用另外一个重载版本的成员函数setPixelRef保存参数pr指向的SkGrPixelRef对象,如下所示:
SkPixelRef* SkBitmap::setPixelRef(SkPixelRef* pr, int dx, int dy) {
......
if (fPixelRef != pr) {
this->freePixels();
......
SkSafeRef(pr);
fPixelRef = pr;
......
}
......
return pr;
}SkBitmap类的成员函数setPixelRef主要是将参数pr指向的SkGrPixelRef对象保存在成员变量fPixelRef中。这意味着当前正在处理的SkBitmap对象的成员变量fPixelRef描述的是一个纹理。
这一步执行完成后,我们就创建了一个类型为SkSurface_Gpu的Skia Surface。这个Skia Surface将会从DirectRasterBuffer类的成员函数CreateSurface返回给DirectRasterBuffer类的成员函数DoLockForWrite,后者将其保存在成员变量surface_中,接下来又会调用它的成员函数getCanvas获得一个SkCanvas对象。这个SkCanvas对象描述的就是一个画布。
SkSurface_Gpu类的成员函数getCanvas是从父类SkSurface继承下来的,它的实现如下所示:
SkCanvas* SkSurface::getCanvas() {
return asSB(this)->getCachedCanvas();
}这个函数定义在文件external/chromium_org/third_party/skia/src/image/SkSurface.cpp中。
从前面的调用过程可以知道,this指针指向的是一个SkSurface_Gpu对象。SkSurface_Gpu类是从SkSurface_Base类继承下来的,因此,SkSurface类的成员函数getCanvas可以调用另外一个成员函数asSB将this指针转换为一个SkSurface_Base指针,然后再调用这个SkSurface_Base指针指向的SkSurface_Base对象的成员函数getCachedCanvas获取一个画布。
SkSurface_Base类的成员函数getCachedCanvas的实现如下所示:
SkCanvas* SkSurface_Base::getCachedCanvas() {
if (NULL == fCachedCanvas) {
fCachedCanvas = this->onNewCanvas();
if (NULL != fCachedCanvas) {
fCachedCanvas->setSurfaceBase(this);
}
}
return fCachedCanvas;
}SkSurface_Base类的成员变量fCachedCanvas用来缓存当前正在处理的SkSurface_Base对象之前创建过的画布。因此,当这个成员变量的值不等于NULL的时候,就可以直接将它指向的画布返回给调用者。
另一方面,如果当前正在处理的SkSurface_Base对象之前还没有创建过画布,那么SkSurface_Base类的成员函数就会调用由子类SkSurface_Gpu实现的成员函数onNewCanvas创建一个画布,也就是一个SkCanvas对象,并且将这个SkCanvas对象保存在成员变量fCachedCanvas。
SkSurface_Gpu类的成员函数onNewCanvas的实现如下所示:
SkCanvas* SkSurface_Gpu::onNewCanvas() {
return SkNEW_ARGS(SkCanvas, (fDevice));
}从前面的分析可以知道,SkSurface_Gpu类的成员变量fDevice指向的是一个SkGpuDevice对象,SkSurface_Gpu类的成员函数onNewCanvas使用这个SkGpuDevice对象创建一个SkCanvas对象,如下所示:
SkCanvas::SkCanvas(SkBaseDevice* device)
: fMCStack(sizeof(MCRec), fMCRecStorage, sizeof(fMCRecStorage))
{
......
this->init(device);
}SkCanvas类的构造函数首先是初始化一个类型为MCRec的队列,并且保存在成员变量fMCStack中。这个队列是用来记录画布的Layer结构的,队列中的每一个MCRec对象就代表一个Layer。
SkCanvas类的构造函数接下来调用另外一个成员函数init对当前正在创建的SkCanvas对象进行初始化,如下所示:
SkBaseDevice* SkCanvas::init(SkBaseDevice* device) {
.....
fMCRec = (MCRec*)fMCStack.push_back();
new (fMCRec) MCRec(NULL, 0);
fMCRec->fLayer = SkNEW_ARGS(DeviceCM, (NULL, 0, 0, NULL, NULL));
fMCRec->fTopLayer = fMCRec->fLayer;
......
return this->setRootDevice(device);
}SkCanvas类的成员函数init首先是在成员变量fMCStack描述的队列中创建第一个Layer,然后再调用另外一个成员函数setRootDevice将参数device指向的SkGpuDevice对象保存在内部,如下所示:
SkBaseDevice* SkCanvas::setRootDevice(SkBaseDevice* device) {
SkDeque::F2BIter iter(fMCStack);
MCRec* rec = (MCRec*)iter.next();
......
SkRefCnt_SafeAssign(rec->fLayer->fDevice, device);
rootDevice = device;
......
return device;
}SkCanvas类的成员函数setRootDevice主要是将参数device指向的SkGpuDevice对象保存在成员变量rootDevice中。此外,参数device指向的SkGpuDevice对象还会作为当前正在创建的画布的第一个Layer的Device。
这一步执行完成后,一个SkCanvas对象就创建和初始化完成了,并且这个SkCanvas对象会返回给SkSurface_Base类的成员函数getCachedCanvas中。
SkSurface_Base类的成员函数getCachedCanvas获得一个新创建的SkCanvas对象之后,会调用这个SkCanvas对象的成员函数setSurfaceBase给它关联一个Skia Surface,也就是正当前正在处理的SkSurface_Gpu对象,如下所示:
class SK_API SkCanvas : public SkRefCnt {
......
private:
......
SkSurface_Base* fSurfaceBase;
......
void setSurfaceBase(SkSurface_Base* sb) {
fSurfaceBase = sb;
}
......
};SkCanvas类的成员函数setSurfaceBase主要是将参数sb指向的SkSurface_Gpu对象保存在成员变量fSufaceBase中,后面在光栅化网页分块时就需要使用到该SkSurface_Gpu对象。
这一步执行完成之后,一个画布就创建完成了。这个画布的底层存储是一个FBO。这个FBO又关联了一个纹理。当我们调用这个画布的API光栅化网页分块时,光栅化结果就保存在与这个画布关联的纹理中。
从前面Chromium网页光栅化过程分析一文可以知道,网页分块的光栅化操作是通过调用PicturePileImpl类的成员函数RasterToBitmap进行的,如下所示:
void PicturePileImpl::RasterToBitmap(
SkCanvas* canvas,
const gfx::Rect& canvas_rect,
float contents_scale,
RenderingStatsInstrumentation* rendering_stats_instrumentation) {
canvas->discard();
......
RasterCommon(canvas,
NULL,
canvas_rect,
contents_scale,
rendering_stats_instrumentation,
false);
}参数canvas指向的SkCanvas对象即为前面所创建的画布。网页分块的光栅化操作是通过调用PicturePileImpl类的成员函数RasterCommon实现的,也就是通过调用画布提供的API来执行网页分块的绘制命令。例如,如果有网页分块记录了一个绘制矩形的命令,那么PicturePileImpl类的成员函数RasterCommon就会调用参数canvas指向的SkCanvas对象的成员函数drawRect来执行它。
我们注意到,在将网页分块光栅化在参数canvas指向的SkCanvas对象描述的画布之前,PicturePileImpl类的成员函数RasterToBitmap会先调用这个SkCanvas对象的成员函数discard,目的是将与它关联的FBO设置为当前所使用的离屏渲染对象,这样后面才能通过画布API将网页分块光栅化在指定的纹理中。
SkCanvas类的成员函数discard的实现如下所示:
class SK_API SkCanvas : public SkRefCnt {
......
public:
......
void discard() { this->onDiscard(); }
......
};SkCanvas类的成员函数discard调用另外一个成员函数onDiscard将当前正在处理的画布关联的FBO设置为当前所使用的离屏渲染对象,如下所示:
void SkCanvas::onDiscard() {
if (NULL != fSurfaceBase) {
fSurfaceBase->aboutToDraw(SkSurface::kDiscard_ContentChangeMode);
}
}从前面的分析可以知道,SkCanvas类的成员变量fSurfaceBase的值不等于NULL,它指向了一个SkSurface_Gpu对象,SkCanvas类的成员函数onDiscard调用这个SkSurface_Gpu对象的成员函数aboutToDraw执行绘制之前的准备工作,其中就包括将当前正在处理的画布关联的FBO设置为当前所使用的离屏渲染对象。
SkSurface_Gpu类的成员函数aboutToDraw是从父类SkSurface_Base继承下来的,它的实现如下所示:
void SkSurface_Base::aboutToDraw(ContentChangeMode mode) {
.....
if (NULL != fCachedImage) {
......
fCachedImage->unref();
fCachedImage = NULL;
} else if (kDiscard_ContentChangeMode == mode) {
this->onDiscard();
}
}SkSurface类的成员函数aboutToDraw首先检查当前正在处理的画布是否缓存了上次的绘制结果。如果缓存了,那么SkSurface类的成员变量fCachedImage的值就不等于NULL,并且它指向了一个SkImage对象。这个SkImage对象就描述了上次的绘制结果。现在由于要绘制新的内容了,因此就需要将上次的绘制结果丢弃。
如果当前正在处理的画布没有缓存上次的绘制结果,并且参数mode的值等于kDiscard_ContentChangeMode,那么SkSurface类的成员函数aboutToDraw就会调用由子类SkSurface_Gpu实现的成员函数onDiscard将当前正在处理的画布关联的FBO设置为当前所使用的离屏渲染对象。
从前面的调用过程可以知道,参数mode的值等于kDiscard_ContentChangeMode。我们假设此时当前正在处理的画布没有缓存上次的绘制结果,因此接下来SkSurface类的成员函数aboutToDraw就会调用SkSurface_Gpu类的成员函数onDiscard,用来设置当前所使用的离屏渲染对象。
SkSurface_Gpu类的成员函数onDiscard的实现如下所示:
void SkSurface_Gpu::onDiscard() {
fDevice->accessRenderTarget()->discard();
}SkSurface_Gpu类的成员变量fDevice指向了一个SkGpuDevice对象。从前面的分析过程可以知道,这个SkGpuDevice对象关联了一个GrGLRenderTarget对象,通过调用SkGpuDevice类的成员函数accessRenderTarget可以获得这个GrGLRenderTarget对象。有了这个GrGLRenderTarget对象之后,SkSurface_Gpu类的成员函数onDiscard就调用它的成员函数discard将它设置为当前所使用的离屏渲染对象。
GrGLRenderTarget类的成员函数discard是从父类GrRenderTarget继承下来的,它的实现如下所示:
void GrRenderTarget::discard() {
// go through context so that all necessary flushing occurs
GrContext* context = this->getContext();
if (NULL == context) {
return;
}
context->discardRenderTarget(this);
}从前面GrGLRenderTarget对象的创建过程可以知道,每一个GrGLRenderTarget对象都关联有一个GrGpuGL对象。这个GrGpuGL对象又关联有一个GrContext对象。这个GrContext对象可以通过调用GrRenderTarget类的成员函数getContext获得。有了这个GrContext对象之后,GrRenderTarget类的成员函数discard就可以调用它的成员函数discardRenderTarget将当前正在处理的GrGLRenderTarget对象设置为当前所使用的离屏渲染对象。
GrContext类的成员函数discardRenderTarget的实现如下所示:
void GrContext::discardRenderTarget(GrRenderTarget* target) {
......
this->prepareToDraw(NULL, BUFFERED_DRAW, &are, &acf)->discard(target);
}GrContext类的成员函数discardRenderTarget首先调用成员函数prepareToDraw获得它内部维护的一个GrGpuGL对象,如下所示:
GrDrawTarget* GrContext::prepareToDraw(const GrPaint* paint,
BufferedDraw buffered,
AutoRestoreEffects* are,
AutoCheckFlush* acf) {
......
GrDrawTarget* target;
if (kYes_BufferedDraw == buffered) {
......
target = fDrawBuffer;
} else {
......
target = fGpu;
}
......
return target;
}从前面分析的GrContext对象创建过程可以知道,GrContext类的成员变量fGpu指向的这个GrGpuGL对象。画布的绘制操作就是通过这个GrGpuGL对象完成的。GrContext类还有另外一个成员变量fDrawBuffer,它指向的是一个GrInOrderDrawBuffer对象。画布的绘制操作也可以通过这个GrInOrderDrawBuffer对象完成。实际上,这个GrInOrderDrawBuffer对象的绘制操作最终也是通过上述GrGpuGL对象完成的。
那么,通过GrGpuGL对象和GrInOrderDrawBuffer对象来执行画布的绘制操作有什么区别呢?前者会马上执行绘制操作,而后者会先将绘制操作记录起来,然后再执行,起到的作用类型于Android应用程序UI硬件加速渲染机制中的Display List,具体可以参考前面Android应用程序UI硬件加速渲染技术简要介绍和学习计划这个系列的文章。这个GrInOrderDrawBuffer对象带来的好处就如Display List一样:每次绘制画布时只需要重绘那些发生了变化的元素,没有发生变化的元素可以复用上次的绘制结果,而且在执行一些透明度、偏移和缩放动画时,不必重绘整个画布,利用画布的上一次绘制结果即可。
使用GrGpuGL对象还是GrInOrderDrawBuffer对象来执行画布的绘制操作,是由参数buffered决定的。从前面的调用过程可以知道,参数buffered的值等于BUFFERED_DRAW。BUFFERED_DRAW实际上是一个宏,它的定义如下所示:
// It can be useful to set this to false to test whether a bug is caused by using the
// InOrderDrawBuffer, to compare performance of using/not using InOrderDrawBuffer, or to make
// debugging simpler.
SK_CONF_DECLARE(bool, c_Defer, "gpu.deferContext", true,
"Defers rendering in GrContext via GrInOrderDrawBuffer.");
#define BUFFERED_DRAW (c_Defer ? kYes_BufferedDraw : kNo_BufferedDraw)从这里可以看到,当全局变量c_Defer的值等于true时,宏BUFFERED_DRAW的值就等于kYes_BufferedDraw;否则的话,宏BUFFERED_DRAW的值就等于kNo_BufferedDraw。
全局变量c_Defer的值在默认情况下等于true。不过也可以通过配置文件将gpu.deferContext的值设置为false,从而使得宏BUFFERED_DRAW的值等于kNo_BufferedDraw。
由于GrInOrderDrawBuffer对象最终也是通过GrGpuGL对象来完成绘制操作的,因此为了简单起见,我们假设全局变量c_Defer的值设置为false,也就是传递给GrContext类的成员函数prepareToDraw的参数buffered的值等于kNo_BufferedDraw。在这种情况下,GrContext类的成员函数prepareToDraw返回的是成员变量fGpu所指向的GrGpuGL对象。
回到GrContext类的成员函数discardRenderTarget中,它获得了一个GrGpuGL对象之后,就调用这个GrGpuGL对象的成员函数discard将参数target指向的GrGLRenderTarget对象设置为当前所使用的离屏渲染对象,如下所示:
void GrGpuGL::discard(GrRenderTarget* renderTarget) {
......
GrGLRenderTarget* glRT = static_cast<GrGLRenderTarget*>(renderTarget);
if (renderTarget != fHWBoundRenderTarget) {
......
GL_CALL(BindFramebuffer(GR_GL_FRAMEBUFFER, glRT->renderFBOID()));
}
......
} GrGpuGL类的成员变量fHWBoundRenderTarget表示上次所使用的离屏渲染对象。参数renderTarget表示当前所要使用的离屏渲染对象。当这两者的值不相等的时候,就需要将参数renderTarget指向的GrGLRenderTarget对象设置为当前所要使用的离屏渲染对象。这是通过调用Command Buffer GL接口BindFramebuffer实现的。
在调用Command Buffer GL接口BindFramebuffer的时候,需要指定一个FBO的ID。这个FBO的ID可以通过调用参数renderTarget指向的GrGLRenderTarget对象的成员函数renderFBOID获得。
这一步执行完成后,回到PicturePileImpl类的成员函数RasterToBitmap,我们就将参数canvas描述的画布所关联的FBO设置为当前所使用的离屏渲染对象了。这样就可以确保接下来调用这个画布的API都作用在它所关联的FBO上。由于这个FBO绑定了之前分配给即将要执行光栅化操作的网页分块的纹理,因此当网页分块所有的光栅化操作执行完成后,这个纹理就包含了光栅化结果。
接下来我们以画布提供的矩形绘制API的执行过程为例,分析网页分块的GPU光栅化过程,也就是分析SkCanvas类的成员函数drawRect的实现,如下所示:
void SkCanvas::drawRect(const SkRect& r, const SkPaint& paint) {
......
LOOPER_BEGIN(paint, SkDrawFilter::kRect_Type, bounds)
while (iter.next()) {
iter.fDevice->drawRect(iter, r, looper.paint());
}
LOOPER_END
}这个函数定义在文件external/chromium_org/third_party/skia/src/core/SkCanvas.cpp中。
宏LOOPER_BEGIN和LOOPER_END的定义如下所示:
#define LOOPER_BEGIN(paint, type, bounds)
this->predrawNotify();
AutoDrawLooper looper(this, paint, false, bounds);
while (looper.next(type)) {
SkDrawIter iter(this);
#define LOOPER_END }在SkCanvas类的成员函数drawRect展开这两个宏之后,会得两个while循环。第一个while循环是针对参数paint描述的画笔的。例如,参数paint描述的画笔可能指定了绘制阴影,那么第一个while循环就会执行两遍。第一遍用来绘制内容本身,第二遍用来绘制内容的阴影。
第二个while循环是针对当前正在绘制的画布的Layer的。每一个画布都有一个Layer Stack。从前面的分析可以知道,画布在初始化的时候,默认创建了一个Layer。以后每当调用一次画布的成员函数saveLayer,就会在Layer Stack上压入一个新的Layer。并且会为这个新的Layer创建一个离屏渲染缓冲区,以及一个Device,后者以前者为底层存储。接下来调用画布的成员函数drawXXX时,所绘制的图形就会通过上述Device作用在它的底层存储中,也就是它所封装的离屏渲染缓冲区中。
离屏渲染缓冲区绘制完成后,需要调用画布的成员函数restore。一方面是取消将图形绘制在离saveLayer屏渲染缓冲区,也就是将Layer Stack最上面的Layer出栈,另一方面是将已经绘制好的离屏渲染缓冲区的内容绘制到Layer Stack的下一个Layer上去。这意味着SkCanvas类的成员函数saveLayer和restore是需要成对出现的。
这里比较奇怪的是,SkCanvas类的所有成员函数drawXXX,都将自己要绘制的图形绘制在所有的Layer中,而不只是Layer Stack最上面的Layer之上。这似乎会导致一个图形被多次绘制在画布默认创建的Layer上。以SkCanvas类的成员函数drawRect为例,此时我们假设画布有两个Layer。第一个Layer是画布初始化时默认创建的Layer,第二个Layer是调用画布的成员函数saveLayer创建的。SkCanvas类的成员函数drawRect在展开宏LOOPER_BEGIN和LOOPER_END之后,第二个while循环将会在两个Layer中分别绘制由参数r指定的矩形。但是后面调用画布的成员函数restore平衡前面调用的成员函数saveLayer时,第二个Layer的内容又会绘制在第一个Layer上。这就相当于在第一个Layer上绘制两次参数r指定的矩形。这个逻辑没有搞明白,先留下一个问号。也希望理解这个逻辑的读者帮忙指点一下。
为了简单起见,我们假设SkCanvas类的成员函数drawRect被调用的时候,画布只有一个Layer。这个Layer就是画布初始化默认创建的Layer中。上述第二个while循环将会调用这个Layer的成员变量fDevice指向一个Device的成员函数drawRect绘制参数r指定的矩形。从前面的分析可以知道,在使用GPU渲染的情况下,画布默认创建的Layer的成员变量fDevice指向的Device实际上是一个GrGpuDevice。因此,在使用GPU渲染的情况下,SkCanvas类的成员函数drawRect实际上是调用了GrGpuDevice类的成员函数drawRect绘制参数r指定的矩形。
GrGpuDevice类的成员函数drawRect的实现如下所示:
void SkGpuDevice::drawRect(const SkDraw& draw, const SkRect& rect,
const SkPaint& paint) {
......
bool doStroke = paint.getStyle() != SkPaint::kFill_Style;
SkScalar width = paint.getStrokeWidth();
......
bool usePath = doStroke && width > 0 &&
(paint.getStrokeJoin() == SkPaint::kRound_Join ||
(paint.getStrokeJoin() == SkPaint::kBevel_Join && rect.isEmpty()));
......
if (usePath) {
SkPath path;
path.addRect(rect);
this->drawPath(draw, path, paint, NULL, true);
return;
}
GrPaint grPaint;
SkPaint2GrPaintShader(this->context(), paint, true, &grPaint);
fContext->drawRect(grPaint, rect, &strokeInfo);
}从前面的分析可以知道,GrGpuDevice类的成员变量fContext指向的是一个GrContext对象。如果要绘制的矩形以简单的方式(纯色)填充,那么GrGpuDevice类的成员函数drawRect将会调用这个GrContext对象的成员函数drawRect绘制指定的矩形。否则的话,就会调用另外一个成员函数drawPath绘制指定的矩形。
为简单起见,我们假设要绘制的矩形以简单的方式(纯色)填充,因此接下来GrContext类的成员函数drawRect就会被调用,它的实现如下所示:
void GrContext::drawRect(const GrPaint& paint,
const SkRect& rect,
const GrStrokeInfo* strokeInfo,
const SkMatrix* matrix) {
......
GrDrawTarget* target = this->prepareToDraw(&paint, BUFFERED_DRAW, &are, &acf);
......
SkScalar width = NULL == strokeInfo ? -1 : strokeInfo->getStrokeRec().getWidth();
......
if (width >= 0) {
......
target->drawNonIndexed(primType, 0, vertCount);
} else {
// filled BW rect
target->drawSimpleRect(rect, matrix);
}
}GrContext类的成员函数drawRect首先调用另外一个成员函数prepareToDraw获得一个GrDrawTarget对象。这个GrDrawTarget对象负责执行将参数rect描述的矩形绘制在画布上。前面我们已经分析过GrContext类的成员函数prepareToDraw的实现,它返回的实际上是一个GrGpuGL对象。注意,GrGpuGL是GrGpu的子类,后者又是GrDrawTarget的子类。
GrContext类的成员函数drawRect接下来判断应该调用前面获得的GrGpuGL对象的成员函数drawNonIndexed还是drawSimpleRect绘制参数rect指定的矩形,取决于这个矩形的边是否被设置为虚线。如果设置为虚线,就调用前者。否则的话,就调用后者。
我们假设参数rect指定的矩形的边是实线,因此接下来GrContext类的成员函数drawRect就会调用GrGpuGL类的成员函数drawSimpleRect绘制该矩形。GrGpuGL类的成员函数drawSimpleRect是从父类GrDrawTarget继承下来的,它的实现如下所示:
class GrDrawTarget : public SkRefCnt {
protected:
......
public:
......
void drawSimpleRect(const SkRect& rect, const SkMatrix* matrix = NULL) {
this->drawRect(rect, matrix, NULL, NULL);
}
......
};GrDrawTarget类的成员函数drawSimpleRect调用另外一个成员函数drawRect绘制参数rect指定的矩形,如下所示:
class GrDrawTarget : public SkRefCnt {
protected:
......
public:
......
void drawRect(const SkRect& rect,
const SkMatrix* matrix,
const SkRect* localRect,
const SkMatrix* localMatrix) {
AutoGeometryPush agp(this);
this->onDrawRect(rect, matrix, localRect, localMatrix);
}
......
}; GrDrawTarget类的成员函数drawRect又调用另外一个成员函数onDrawRect绘制参数rect指定的矩形,如下所示:
void GrDrawTarget::onDrawRect(const SkRect& rect,
const SkMatrix* matrix,
const SkRect* localRect,
const SkMatrix* localMatrix) {
......
SkRect bounds;
this->getDrawState().getViewMatrix().mapRect(&bounds, rect);
this->drawNonIndexed(kTriangleFan_GrPrimitiveType, 0, 4, &bounds);
}GrDrawTarget类的成员函数onDrawRect首先根据之前设置的变换矩阵对要绘制的矩形进行变换。变换之后,再调用另外一个成员函数drawNonIndexed对其进行绘制,如下所示:
void GrDrawTarget::drawNonIndexed(GrPrimitiveType type,
int startVertex,
int vertexCount,
const SkRect* devBounds) {
if (vertexCount > 0 && this->checkDraw(type, startVertex, -1, vertexCount, -1)) {
DrawInfo info;
info.fPrimitiveType = type;
info.fStartVertex = startVertex;
info.fStartIndex = 0;
info.fVertexCount = vertexCount;
info.fIndexCount = 0;
......
if (NULL != devBounds) {
info.setDevBounds(*devBounds);
}
......
this->onDraw(info);
}
}从前面的调用过程可以知道,参数vertexCount的值等于4,表示要绘制的是一个矩形,它有4个顶点。GrDrawTarget类的成员函数drawNonIndexed首先调用另外一个成员函数checkDraw检查当前正在处理的GrDrawTarget对象是否可以绘制图形,也就是它是否关联了一个图形缓冲区。对于GPU渲染来说,这个图形缓冲区实际上就是一个纹理,这个纹理同时被设置为一个FBO的底层存储。
当GrDrawTarget类的成员函数checkDraw的返回等于true的时候,就表示当前正在处理的GrDrawTarget对象可以绘制由参数devBounds指定的矩形。接下来GrDrawTarget类的成员函数drawNonIndexed要绘制的矩形的信息封装在一个DrawInfo对象中,最后调用由子类GrGpu实现的成员函数onDraw执行具体的绘制操作,如下所示:
void GrGpu::onDraw(const DrawInfo& info) {
......
this->onGpuDraw(info);
}GrGpu类的成员函数onDraw又调用了由子类GrGpuGL实现的成员函数onGpuDraw使用GPU来绘制参数info指定的矩形,如下所示:
void GrGpuGL::onGpuDraw(const DrawInfo& info) {
size_t indexOffsetInBytes;
this->setupGeometry(info, &indexOffsetInBytes);
.....
if (info.isIndexed()) {
GrGLvoid* indices =
reinterpret_cast<GrGLvoid*>(indexOffsetInBytes + sizeof(uint16_t) * info.startIndex());
// info.startVertex() was accounted for by setupGeometry.
GL_CALL(DrawElements(gPrimitiveType2GLMode[info.primitiveType()],
info.indexCount(),
GR_GL_UNSIGNED_SHORT,
indices));
} else {
// Pass 0 for parameter first. We have to adjust glVertexAttribPointer() to account for
// startVertex in the DrawElements case. So we always rely on setupGeometry to have
// accounted for startVertex.
GL_CALL(DrawArrays(gPrimitiveType2GLMode[info.primitiveType()], 0, info.vertexCount()));
}
......
}从这里就可以看到,GrGpuGL类的成员函数onGpuDraw是通过Command Buffer GL接口DrawElements或者DrawArrays绘制指定的矩形的。这说明在使用GPU光栅化网页分块时,SkCanvas类的绘图成员函数drawXXX都是通过调用Command Buffer GL接口实现自身功能的。
至此,我们就分析完成网页分块GPU光栅化的原理了。总结来说,就是以下三点:
1. 每一个网页分块都分配了一个纹理。
2. 纹理被绑定在一个FBO上,FBO又被设置为一个画布(SkCanvas)的后端存储。
3. SkCanvas通过Command Buffer GL接口实现自身的绘制API。
这样当CC模块调用SkCanvas提供的绘制API光栅化网页分块时,实际上是通过Command Buffer GL接口将网页分块的内容绘制在为其分配的纹理中。这个纹理接下来就可以直接渲染在屏幕上。这就是网页分块GPU光栅化的实理。在接下来的一篇文章中,我们将继续分析网页分块CPU光栅化的原理。显然,CPU光栅化就是使用CPU执行光栅化操作的。不过,光栅化操作结果最终还是需要通过GPU来渲染在屏幕上。相对于CPU光栅化操作,将光栅化结果从CPU上传到GPU是一个很慢的操作。因此,CPU光栅化需要解决的一个核心问题如何快速地将光栅化结果上传给GPU。这个问题的答案我们将会在分析网页分块CPU光栅化原理的过程中给出,敬请关注!更多的信息也可以关注老罗的新浪微博:http://weibo.com/shengyangluo。
最后
以上就是粗犷黄豆最近收集整理的关于Chromium网页GPU光栅化原理分析的全部内容,更多相关Chromium网页GPU光栅化原理分析内容请搜索靠谱客的其他文章。

![[转]:复杂多边形光栅化算法](https://www.shuijiaxian.com/files_image/reation/bcimg21.png)






发表评论 取消回复