雷锋网(公众号:雷锋网) AI 科技评论按:OpenAI 于今日发布了 Neural MMO,它是一个为强化学习智能体创建的大型多智能体游戏环境。该平台支持在一个持久、开放的任务中使用大规模且数量可变的智能体。将更多的智能体和物种囊括到环境中可以更好地执行探索任务,促进多种生态位的形成,从而增强系统整体的能力。

近年来,多智能体环境已经成为深度强化学习的一个有效的研究平台。虽然该领域目前已经取得了一定的研究进展,但是多智能体强化学习仍存在两大主要挑战:当前的强化学习环境要么足够复杂但是限制条件太多,普适性不强;要么限制条件很少但是过于简单。因而我们需要创建具有高复杂度上限的开放式任务,其中,持久性和大的种群规模等属性是需要讨论的关键因素。但同时,我们还需要更多的基准测试环境,来量化对于持久性和大的种群规模这些属性的学习进展。大型多人在线游戏(MMO)类型的游戏模拟了一个规模庞大的生态系统,其中数量不断变化的玩家在持久、广阔的环境下对战。
为了应对这些挑战,OpenAI 开发了 Neural MMO,它满足以下的标准:
(1)持久性:在不对环境进行重置的情况下,智能体可以在其它智能体也正在学习的情况下同时进行学习。策略必须考虑到长远的规划,并适应其他智能体可能发生快速变化的行为。
(2)规模:该环境支持大规模且数量可变的实体。本实验考虑了在 100 个并发服务器中,每个服务器中的 128 个并发的智能体长达 100M 的生命周期。
(3)效率:计算的准入门槛很低。我们可以在一块桌面级 CPU 上训练有效的策略。
(4)扩展性:与现有的大型多人在线游戏类似,我们设计的 Neural MMO 旨在更新新的内容。它目前的核心功能包括程序化的基于拼接地块的地形生成,寻找食物和水资源的系统以及战略战斗系统。在未来,该系统有机会进行开源驱动的扩展。
环境
玩家(智能体)可以加入到任何可用的服务器(环境)中,每个服务器都会包含一个可配置大小的自动生成的基于地块的游戏地图。一些诸如上面放有食物的森林地块和草地地块是可以穿越的;其他的诸如水、实心岩石的地块则无法穿越。
智能体在沿着环境边缘随机分布的位置诞生。为了维持生存的状态,他们需要获取食物和水,同时还要避免与其他智能体进行战斗受到的伤害。通过踩在森林地块上或站在水地块的旁边,智能体可以分别给自己补充一部分食物和水供应。然而,森林地块中的食物供应有限,食物会随着时间的推移缓慢地再生。这意味着智能体必须为争夺食品块而战,并同时定期从无限的水形地块中补充水源。玩家可以使用三种战斗风格进行战斗,分别为近战、远程攻击及法术攻击。
输入:智能体观察以其当前位置为中心的方形农作物地块。输入包括地块的地形类型和当前智能体选中的属性(生命值、食物、水和位置)。
输出:智能体为下一个游戏时钟刻度(时间步)输出动作选项。该动作由一次移动和一次攻击组成。
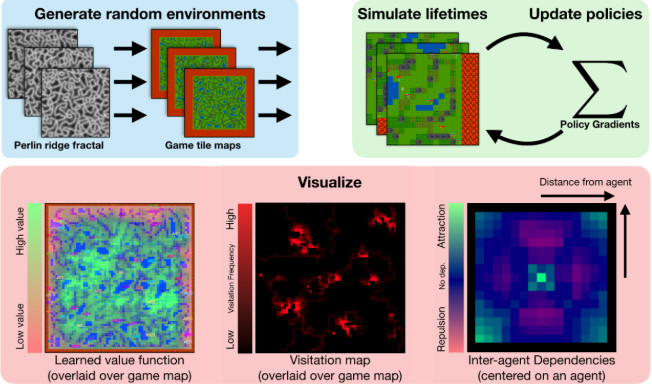
该平台提供了一个程序化的环境生成器以及「值函数、地图地块的访问分布、在学习到的策略中智能体与智能体之间的依赖关系」的可视化工具。用以对比的基线模型是在 100 个世界中训练出来的策略梯度方法。
模型
OpenAI 研究人员使用 vanilla 策略梯度算法、仅对价值函数基线和奖励折扣进行了强化,训练了一个小型的、全连接的架构作为一个简单的基线。智能体实现最优化以获得奖励仅仅是为了维持自身的生命周期(轨迹长度),而不是为了实现特定的目标:他们得每获得 1 个奖励,生命周期就会延长一个时钟刻度。同时,他们通过计算出所有玩家获得奖励的最大值,将长度可变的观测结果(例如周围玩家的列表)转换为一个定长的向量(OpenAI Five 也采用了这个技巧)。本项目发布的源代码包含了基于 PyTorch 和 Ray 的完整的分布式训练实现。
模型评估结果
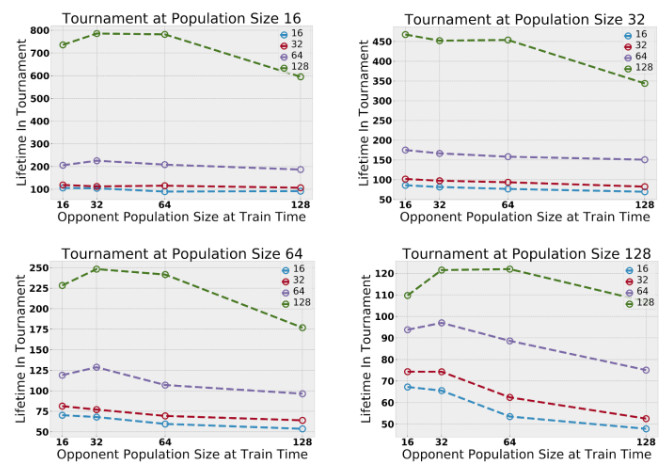
训练时的最大种群规模在(16,32,64,128)的范围内变化。为了提高效率,每组中的 16 个智能体会共享策略。在测试时,我们会合并在成对的实验中学到的种群,并评估固定规模的种群的生命周期。由于战斗策略更加难于直接对比,我们仅仅评估觅食行为。在大规模种群上训练出来的智能体往往表现得更好。
OpenAI 研究人员从大量种群中均匀采样得到智能体的策略,发现不同种群中的智能体会共享网络架构,但只有同一种群中的智能体才会共享权重。初步的实验结果表明,随着多智能体交互的增多,智能体的能力也会攀升。提高共存玩家数量的上限可以扩大探索范围,而增加种群的数量则会扩大生态位的形成结构——也就是说,扩大了种群在地图上的不同区域扩散和觅食的趋势。
服务器合并锦标赛:多智能体能力增强
对于大型多智能体在线游戏来说,并没有跨服务器评估玩家相对战斗力的标准方法。然而,大型多智能体在线游戏的服务器有时会出现合并的情况,此时多个服务器上的玩家数据会被放入同一个服务器。通过合并在不同服务器中训练的玩家数据,OpenAI 研究人员实现了「锦标赛」式的模型评估,这让他们能够直接比较智能体在不同实验环境下学习到的策略。另外,通过改变测试时的环境规模,他们发现在较大的环境中训练的智能体一致地比在较小的环境中训练的智能体表现更好。
种群规模的增加扩大了探索范围
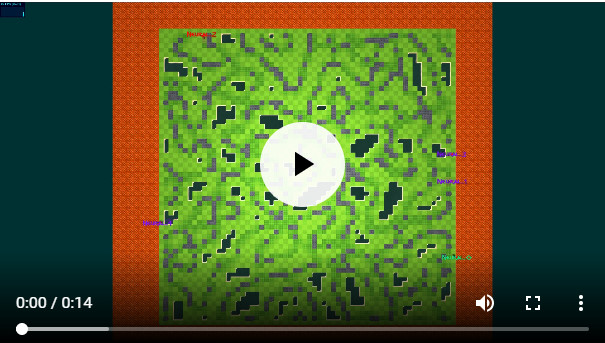
种群数量的增加扩大了搜索范围:智能体分散开来从而避免对战。最后几帧显示的是学习到的价值函数的重叠情况。要想查看更多的图标信息,请参阅:「Neural MMO: A Massively Multiagent Game Environment for Training and Evaluating Intelligent Agents」(https://arxiv.org/pdf/1903.00784.pdf)。
在自然界中,动物之间的竞争可以激励它们分散开来以避免冲突。研究人员观察到,智能体在地图上的覆盖率随共存智能体数量的增加而增加。智能体之所以会学着去探索,只是因为其他智能体的存在为它们提供了这样做的自然动机。
种群数量的增加扩大了生态位的形成
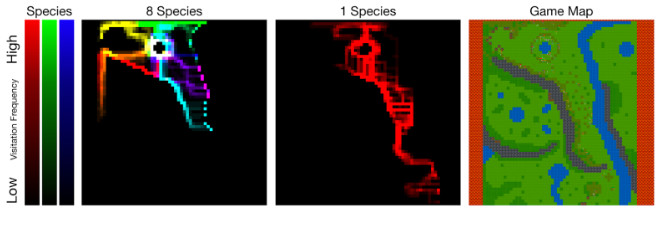
物种数量(种群数量)的增加扩大了生态位(种群在自然生态系统中,在时间、空间上所占据的位置及其与相关种群之间的功能关系和作用)的形成。可视化的地图渐渐覆盖了游戏的地图,不同的颜色对应不同的物种。对单个种群的训练往往会促使系统产生一个深入的探索路径。而训练八个种群则会导致产生很多较浅的探索路径:种群会分散以避免物种之间的竞争。
给定一个足够大的资源丰富的环境,他们发现当智能体的种群数量增加时,不同种群会分散地遍布在地图上以避免与其他种群的竞争。由于实体无法在竞争中胜过同一个种群中的其它智能体(即与之共享权重的智能体),它们倾向于寻找地图上包含足够多用于维持种群规模的资源的区域。DeepMind 在共生多智能体研究中也独立观察到了类似的效果(https://arxiv.org/abs/1812.07019)。
另外的一些思考
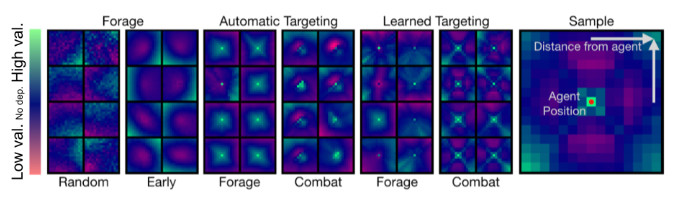
每个方形地图显示了位于方块中心的智能体对其周围智能体的响应。我们展示出了初始化阶段和训练早期的觅食地图,以及额外的对应于不同的觅食和战斗形式的依赖关系图。
OpenAI 研究人员通过将智能体固定在假设的地图地块的中心,来可视化智能体与智能体之间的依赖关系。针对对该智能体可见的每个位置,我们的实验显示了,假如在该位置有第二个智能体,价值函数将会变成什么。同时,他们发现,在觅食和战斗环境中,智能体学习的策略会依赖于其他智能体的策略。经过了仅仅几分钟的训练后,智能体就能学会「正中靶心」的正确回避路线,从而开始更有效地觅食。当智能体学习环境中的战斗机制时,它们会开始适当地评估有效的接近范围和角度。
下一步的工作
OpenAI 的 Neural MMO 解决了之前基于游戏的环境的两个主要局限性,但仍有许多问题尚未解决。Neural MMO 在环境复杂性和种群规模之间找到了一个中间地带。同时,他们在设计这个环境时还考虑到了开源扩展,并计划将其作为创建研究社区的基础。
总结:强化学习中的「探索-利用」问题
强化学习是一种试错学习方式:最开始的时候不清楚环境的工作方式,不清楚执行什么样的动作是对的,什么样的动作是错的。因而智能体需要从不断尝试的经验中发现一个好的决策,从而在这个过程中获取更多的奖励。
因此,对于强化学习研究来说,需要在探索(未知领域)和利用(现有知识)之间找到平衡。实际上,探索和利用是一对相对来说较为矛盾的概念,利用是做出当前信息下的最佳决策,探索则是尝试不同的行为继而收集更多的信息、期望得到更好的决策。最好的长期战略通常包含一些牺牲短期利益举措。通过搜集更多或者说足够多的信息使得个体能够达到宏观上的最佳策略。
实际上,OpenAI 扩大种群规模和种群数量,使智能体趋向于分散,也正是希望能够扩大探索的范围,找到能够使智能体能力更强、种群更稳定的决策方式。从单个服务器上看,这种做法背后隐藏着最大熵的思想;而从整体来看,他们依托于 OpenAI 强大的计算资源,将探索任务用分而治之的方式分配到各个服务器上分别进行决策,最后再进行合并。
via https://blog.openai.com/neural-mmo/ 雷锋网 AI 科技评论编译 雷锋网
最后
以上就是魁梧金针菇最近收集整理的关于强化学习怎样在探索和利用之间找到平衡?OpenAI 推出了大型多智能体游戏环境 Neural MMO...的全部内容,更多相关强化学习怎样在探索和利用之间找到平衡?OpenAI内容请搜索靠谱客的其他文章。








发表评论 取消回复