一、利用与探索
对于一个智能体而言需要权衡利用和探索。
利用就是利用过往的经验,探索就是对环境进行随机的探索
二、利用与探索的简单试验
2.1 环境构建
对于一个摇臂机器, 有n个臂,不同臂的中奖概率不同,我们需要在一定的摇臂次数之内达到最高的收益。
class RockerEnv:
def __init__(self, rocker_reward_rate_list, total_do=30):
self.rocker_reward_rate_list = rocker_reward_rate_list
self.total_do = total_do
self.cnt = 0
def __len__(self):
return len(self.rocker_reward_rate_list)
def reset(self):
self.cnt = 0
def step(self, action):
done = False
if self.cnt >= self.total_do:
done = True
rocker_reward_rate = self.rocker_reward_rate_list[action]
if rocker_reward_rate >= random.random():
reward = 1
else:
reward = 0
self.cnt += 1
return reward, done
2.2 构建探索与利用的智能体
当生成的随机数小于探索概率的时候进行探索(即探索覆盖的概率范围是是0-探索概率),反之则利用之前的经验,及每个臂的平均期望。
import numpy as np
class RockerAgent:
def __init__(self, explore_rate=0.1):
self.explore_rate = explore_rate
self.V = []
def policy(self):
"""智能体的行动策略"""
rockers = range(len(self.V))
if random.random() < self.explore_rate:
return random.choice(rockers)
return np.argmax(self.V)
def play(self, env):
env.reset()
done = False
rocker_done_nums = [0] * len(env)
self.V = [0] * len(env)
rewards = []
while not done:
action = self.policy()
reward, done = env.step(action)
# 更新经验
new_avg = (self.V[action] + reward) / (rocker_done_nums[action] + 1)
self.V[action] = new_avg
rocker_done_nums[action] += 1
rewards.append(reward)
return rewards
2.3 智能体行动
针对不用策略进行多步探测,查看不同策略的最终受益。
from collections import defaultdict
import matplotlib.pyplot as plt
rk_env = RockerEnv([0.1, 0.8, 0.1, 0.9, 0.1, 0.6, 0.1])
explore_rate_list = [0.0, 0.1, 0.2, 0.5, 0.8]
total_do_list = list(range(10, 310, 10))
rewards_record_dict = defaultdict(list)
for ep in explore_rate_list:
ag = RockerAgent(explore_rate=ep)
for td in total_do_list:
tmp_rewards = []
for _ in range(3):
rk_env.total_do = td
tmp_rewards.append(np.mean(ag.play(rk_env)))
rewards_record_dict[f'explore_rate={ep}'].append(np.mean(tmp_rewards))
for key_ in rewards_record_dict:
plt.plot(rewards_record_dict[key_], label=key_)
plt.xticks(range(len(total_do_list)), total_do_list)
plt.legend()
plt.show()
从下图可以看出,在行动中增加一点探索(0.1, 0.2)可以达到较高的收益,在前期较小的探索率会有较大的波动,随着试验的次数增加收益会趋于稳定。
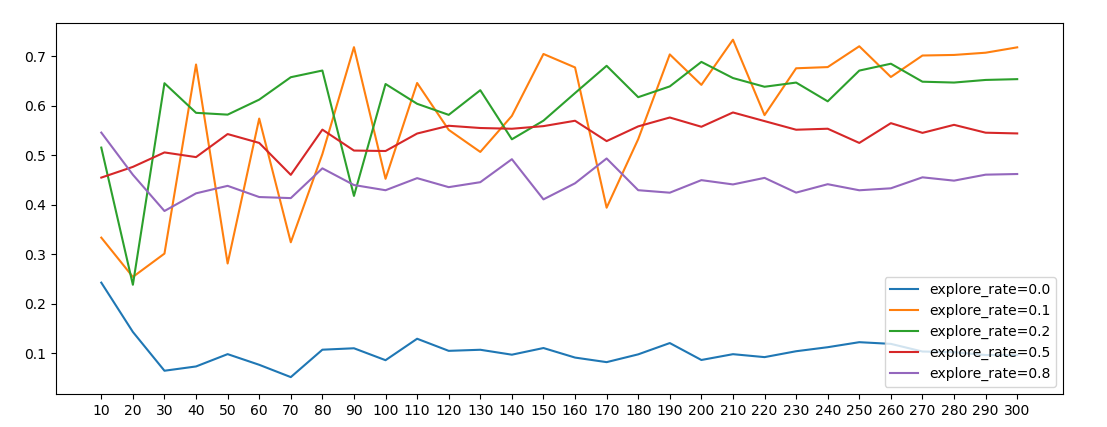
所以,要在一个领域达到较高的水准,需要我们具有一定的冒险精神,且持续不断的投入
最后
以上就是过时裙子最近收集整理的关于强化学习_03_利用与探索一、利用与探索二、利用与探索的简单试验的全部内容,更多相关强化学习_03_利用与探索一、利用与探索二、利用与探索内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复