
overview:
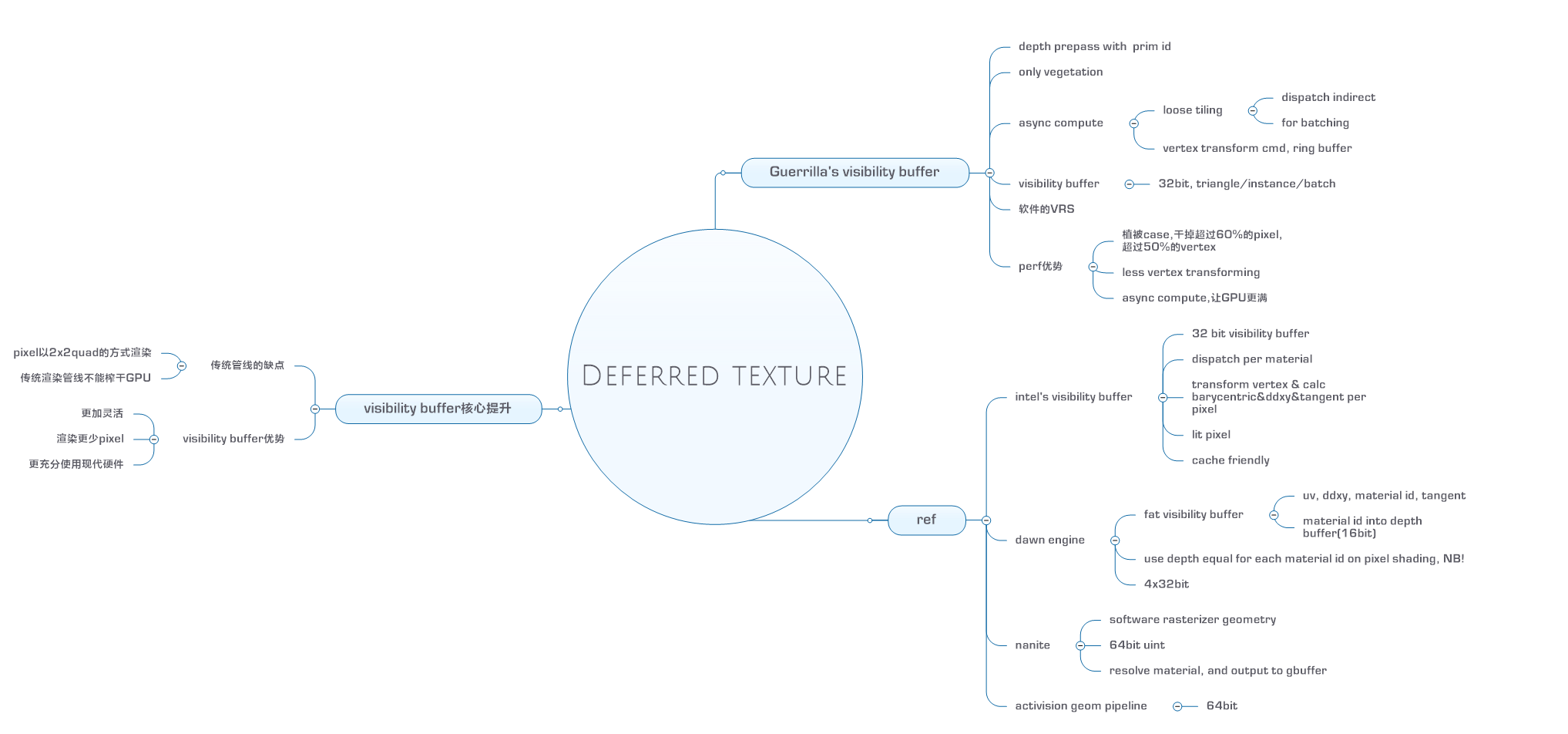
visibility buffer
visibility buffer其实出来很长时间了,近期的话通过nanite被大家熟知;
其实这个有很多变种,如文章中所列:
- intel原版
- dawn engine(eidos)
- ue5
- activision
都有不同的做法;
总的说来就是开始渲染是一个比传统gbuffer小的多的visibility buffer,仅保存primitive id等少量信息,贴图等一概不读;
然后再来一个pass,把各种复杂信息补上,输出gbuffer或者直接shading都可以;
这个shading过程常常是在compute shader里做的;
visibility buffer的优势:
传统渲染管线的问题
我们以最标准的vs-rasterize-ps流程来看,这里有若干问题:
- ps总是以2x2 quad来渲染,对于tiny triangle的case,overhead非常的高
- 渲染管线非常的“死”,导致很多时候出现大量gap,比如做shadow depth pass的时候,gpu中大量单元非常空闲;老的流程在面临现在更加复杂的case,真的是越来越不给力了;
- async compute等需要进一步挖掘来提升gpu利用率;
visibility buffer的优势
- 实际shading更少的pixel
- 可以各种batch,大幅度提升cache效率
- 可以使用compute shader,async compute,进一步提升gpu的利用率;
guerrilla的做法
overview亮点
- 用于植被,相比很多visibility buffer做法用于static mesh,这里是多了一个进步
- 使用IndirectDispatch来进一步做了batch,大幅度提升了wave的利用率
- 融合了自己实现的VRS(不是使用硬件的)
- 完整的管线介绍,和足够有说服力的性能提升
植被
首先guerrilla在horizon里是把visibility buffer用于植被的;

因为植被是一直动的,而且风动动画也一直比较消耗,所以在整个过程中带来挑战:降低vertex transform就格外的重要;
技术细节:
visibility buffer的格式:

存的是一个32bit的信息;
相比ue和activision的都更小;
pipeline & batch
batch
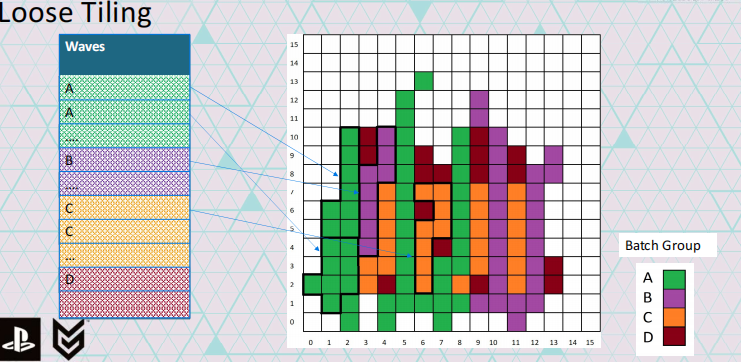
如果我们建好visibility buffer,然后一个compute shader上去算,那么就会出现大量的divergence,导致性能很差;
这里使用一个DispatchIndirect,先对visibility buffer的内容进行排序,pack到16x16的tile中,然后在发起wave cmd;
这样的话,shader,texture,const的切换就大大降低,效率提升了不少;
vertex transform
这里visibility一种做法就是在shading pixel的时候,直接做vertex的transform;
这个如果triangle特别小的话,也可以是一个选项;
但是horizon的case是,triangle往往还比较大的,那么就还是batc起来比较好;
就是把要transform的vertex输出到一个ring buffer里,batch&去重,然后计算好了之后,在使用;
pipeline
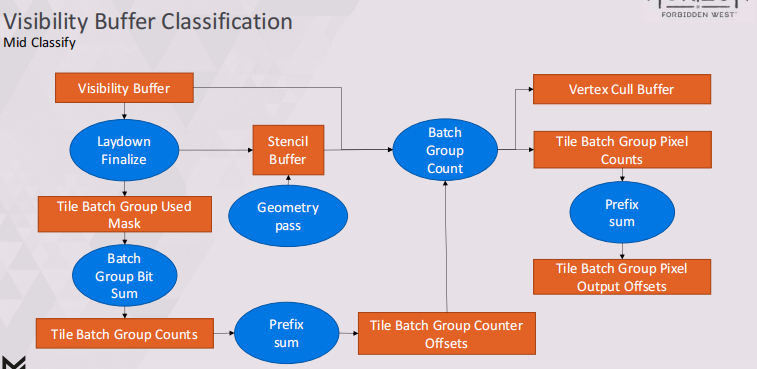
整个过程拆的比较细,这里没必要记了,用到的时候再查就好,道理就是那么个道理;
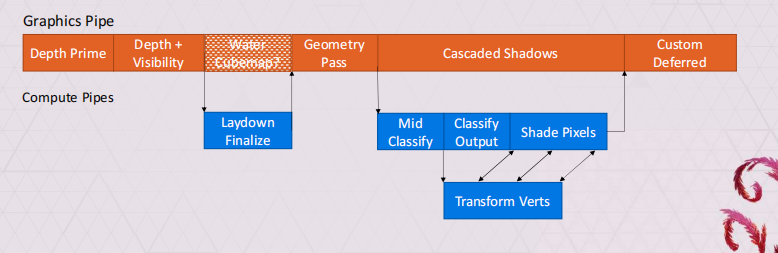
在pipeline上可以看下;
中间可以看到,基本都用async compute把计算给hide起来了;
性能
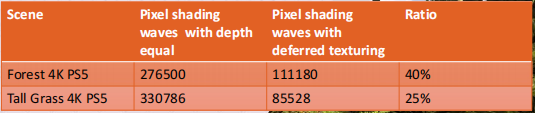

可以看到在这个管线里,性能提升还是很可观的
最后
以上就是甜甜机器猫最近收集整理的关于[gdc22]<Horizon Forbidden West>的DeferredTexture技术overview:visibility bufferguerrilla的做法性能的全部内容,更多相关[gdc22]<Horizon内容请搜索靠谱客的其他文章。




![[gdc22]<Horizon Forbidden West>的DeferredTexture技术overview:visibility bufferguerrilla的做法性能](https://www.shuijiaxian.com/files_image/reation/bcimg6.png)



发表评论 取消回复