文章目录
- 0 背景
- 1 代码
- 2 sql 语句分析
- 2.1关键词解析:
- 2.2 全语句解释:
- 2.3 从任何一个节点出发查询整条链的数据
0 背景
因为实际用到递归查询数据库表中结果,本想用其他语言实现递归select操作,但是发现sql语句自身也可以进行递归查询,而且效率很高,因此就搜了相关的资料,发现网上很多的代码,但是几乎都没有注解。于是我就决定写一下注解,方便大家理解,使用和测试的环境为Qt,
1 代码
连接数据库:
#ifndef CREATECONNECTION_H
#define CREATECONNECTION_H
#include<QSqlDatabase>
#include<QCoreApplication>
#include<QFile>
#include<QSysInfo>
#include<QtGlobal>
//#include<QDebug>
static bool CreateConnection(){
// qDebug()<<"可用驱动";
// QStringList drivers = QSqlDatabase::drivers();
// for(auto driver: drivers){
// qDebug()<<driver<<" ";
// }
//设置数据库驱动
QSqlDatabase db1 = QSqlDatabase::addDatabase("QSQLITE", "connection1");
// db1.setHostName("127.0.0.1");
// db1.setUserName("root");
// db1.setPassword("root");
// db1.setPort(9998);
db1.setDatabaseName("/Users/mac/Qt/test/database/test.db");
//打开数据库
if(!db1.open()){
return false;
}
return true;
}
#endif // CREATECONNECTION_H
进行递归查询:
//向上查询
QSqlDatabase db = QSqlDatabase::database("connection1");
QSqlQuery query2(db);
QVariantList codesList;//商品编码(按照从大小排序)
QVector<int> splitRuleVector;//拆分规则(按照从大小的拆分,例如0好对应codesList中0号和1号的拆分规则)
query2.exec(QString("WITH splitInformation AS(SELECT *,0 AS rank FROM SplitRule WHERE smallCode = '%1' UNION ALL SELECT asr.*,info.rank+1 FROM SplitRule AS asr JOIN splitInformation AS info ON asr.smallCode = info.bigCode ) SELECT rank,bigCode,number FROM splitInformation").arg(queryCode));
while(query2.next()){
//从大---->小存:递减
codesList.push_front(query2.value(1).toString());
splitRuleVector.push_front(query2.value(2).toInt());
//从小--->大存:递增
// codesList.push_back(query2.value(1).toString());
// splitRuleVector.push_back(query2.value(2).toInt());
}
codesList.push_back(queryCode);//放入当前查询
//向下查询
query2.exec(QString("WITH splitInformation AS(SELECT *,0 AS rank FROM SplitRule WHERE bigCode = '%1' UNION ALL SELECT asr.*,info.rank+1 FROM 、SplitRule AS asr JOIN splitInformation AS info ON asr.bigCode = info.smallCode ) SELECT rank,smallCode,number FROM splitInformation").arg(queryCode));
while(query2.next()){
//从大--->小存:递减
codesList.push_back(query2.value(1).toString());
splitRuleVector.push_back(query2.value(2).toInt());
//从小--->大存:递增
// codesList.push_front(query2.value(1).toString());
// splitRuleVector.push_front(query2.value(2).toInt());
}
拆分数据表:
| 大件商品编码 | 数量 | 小件商品编码 |
|---|---|---|
| a98 | 10 | b92 |
| b92 | 5 | c75 |
| c75 | 7 | d64 |
| d64 | 7 | e53 |
根据上面的代码:
查询a98、d64、e53,都可以得到
codesList:
a98—>b92—>c75—>d64—>e53
splitRuleVector:
10—>5—>7—>7
2 sql 语句分析
查父节点:
WITH splitInformation AS
(SELECT *,0 AS rank FROM SplitRule WHERE smallCode = 'c75'
UNION ALL
SELECT asr.*,info.rank+1 FROM SplitRule AS asr
JOIN splitInformation AS info ON asr.smallCode = info.bigCode )
SELECT rank,bigCode,number FROM splitInformation
2.1关键词解析:
- 1, WITH AS
作用:把查询结果作为子查询部分 - 2,SELECT 查询的列名 FROM 表 WHERE 条件
作用:查询符合条件的字段
*3,原名 AS 别名
作用:给原名取别名,如果原名不存在,则新建列,并且列名为别名 - 4,UNION ALL
作用:结合两个 SELECT 语句的结果,包括重复行
区别于UNION:
UNION:合并两个或多个 SELECT 语句的结果,不返回任何重复的行 - 5,JOIN ON
作用:内联
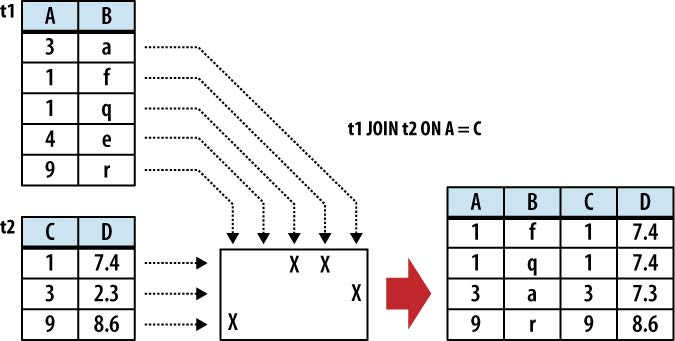
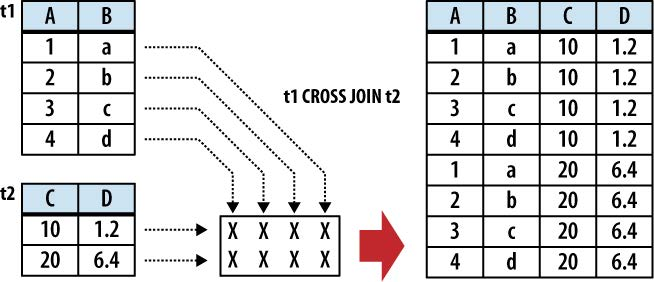
CROSS JOIN:笛卡尔积
OUTER JOIN:外联
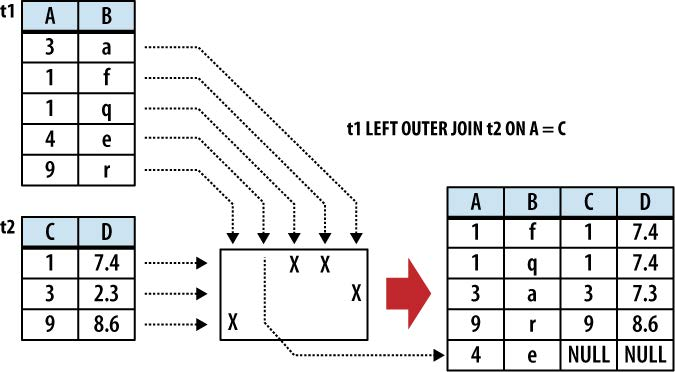
上面三张图感谢此coroutines
博客
2.2 全语句解释:
SELECT *,0 AS rank FROM SplitRule WHERE smallCode = 'c75'
查询SplitRule表中smallCode 等于75 的全部信息,
其中0 为不存在的列,因此会新建一个名为rank的列,
SELECT asr.*,info.rank+1 FROM SplitRule AS asr
JOIN splitInformation AS info ON asr.smallCode = info.bigCode
查询SplitRule表(别名为asr )中全部信息和splitInformation表(别名为info)中的rank值,并对其进行加1操作, 然后把splitInformation表中的bigCode 字段等于SplitRule表中的bigCode字段的结果集合联合起来,
WITH splitInformation AS(* ... *)
把()中的结果集合取名为splitInformation表,对于第二个SELECT语句来说,就是调用本身
SELECT rank,bigCode,number FROM splitInformation
从 splitInformation表中查询rank,bigCode,number这几个字段
第一次执行结果为:
相当于只有第一个select语言起作用,因为splitInformation表中为空,第二个语句条件判断为假
| 大件商品编码 | 数量 | 小件商品编码 |
|---|---|---|
| c75 | 7 | d64 |
执行后splitInformation表为上面的表
第二次执行结果为:
| 大件商品编码 | 数量 | 小件商品编码 |
|---|---|---|
| c75 | 7 | d64 |
| b92 | 5 | c75 |
也就是查询SplitRule表中smallCode字段等于 splitInformation表中bigCode字段的(第二条SELECT语句起作用),因此就新增了第二条记录
执行后splitInformation表为上面的表
第三次执行结果为:
拆分数据表:
| 大件商品编码 | 数量 | 小件商品编码 |
|---|---|---|
| a98 | 10 | b92 |
| b92 | 5 | c75 |
| c75 | 7 | d64 |
也就是查询SplitRule表中smallCode字段等于 splitInformation表中bigCode字段的,因此就新增了第三条记录
执行后splitInformation表为上面的表
就这样一直执行到select语句查询结果为空为止
2.3 从任何一个节点出发查询整条链的数据
因为如果A是顶层节点,那么SplitRule表中的bigCode字段一定有A,
同理如果C是最底层节点,那么SplitRule表中的smallCode字段一定有C,
如果如果B是最底层节点,那么SplitRule表中的smallCode字段和bigCode字段一定有B,
因此第一次搜索,对于第一个SELECT条件语句判断时,执行smallCode字段等于?字段的向上搜索,
第二次搜索,对于第一个SELECT条件语句判断时,执行bigCode字段等于?字段的向下搜索,
这样就可以包括整条链的数据。
最后
以上就是沉默小蝴蝶最近收集整理的关于Qt中使用sqlite进行树状结构查询,查询父节点和子节点查询————附详细代码和解析0 背景1 代码2 sql 语句分析的全部内容,更多相关Qt中使用sqlite进行树状结构查询,查询父节点和子节点查询————附详细代码和解析0内容请搜索靠谱客的其他文章。








发表评论 取消回复