Summary是为了给tensorboard提供数据,而tensorboard在tensorflow是一种非常方便和实用的内置可视化工具,但可视化对程序来说显然不是必须的。
其中包含以下几种数据结构:
- Scalars
- Images
- Audio
- Graph
- Distribution
- Histograms
- Embeddings
对应的都有tf.summary.xxx(xxx为上面提到的数据结构形式)
对于任何一个 tf.summary.xxx源码中都有默认collection=None这个参数,实际是将summary这个op收集到[tf.GraphKeys.SUMMARIES]这个内部维护的collection当中。
tf.summary.xxx的实质
举个栗子,通常,我们需要sess.run(train_op, feed_dict=...)来进行训练,train_op显然是依赖于loss计算,但所有的tf.summary.xxx操作都是图的最外层操作,一般来说不被任何别的op或Variable依赖,而为了可视化loss,我们又需要让tf.summary.scalar('loss', self.loss)run起来,所以程序可以不加sess.run(loss, feed_dict=...),而需要sess.run(summary_op, feed_dict=...)。
当我们想可视化的东西太多了,我们就需要诸多的sess.run(summary_op_i, feed_dict=...)操作,在tf中又可以用merged_op = tf.summary.merge_all()来把所有的sess.run(summary_op_i, feed_dict=...)合并起来,仅sess.run(merged_op, feed_dict=...)即可
可以理解为,
tf.summary.merge_all()是遍历collection,对其分别做.summary.xxx()操作
示例:
import tensorflow as tf
global_step = tf.Variable(0, trainable=False)
increment_op = tf.assign_add(global_step, tf.constant(1))
lr = tf.placeholder(tf.float32)
learning_rate = tf.train.exponential_decay(lr, global_step,
decay_steps=1, decay_rate=0.9, staircase=False)
one_op = tf.summary.scalar('learning_rate', learning_rate)
two_op = tf.summary.scalar('test', increment_op)
merged_op = tf.summary.merge_all()
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
summary_writer = tf.summary.FileWriter('./log/', sess.graph) # 指定检测结果的输出目录
for step in range(0, 10):
val,num_step = sess.run((merged_op, increment_op), {lr:0.1})
summary_writer.add_summary(val, global_step=num_step) # 写入文件
查看结果
terminal下:
tensorboard --logdir ./log/
再打开chrome,输入地址http://localhost:6006即可看见
其中端口号可以再terminal下指定,相应链接也修改
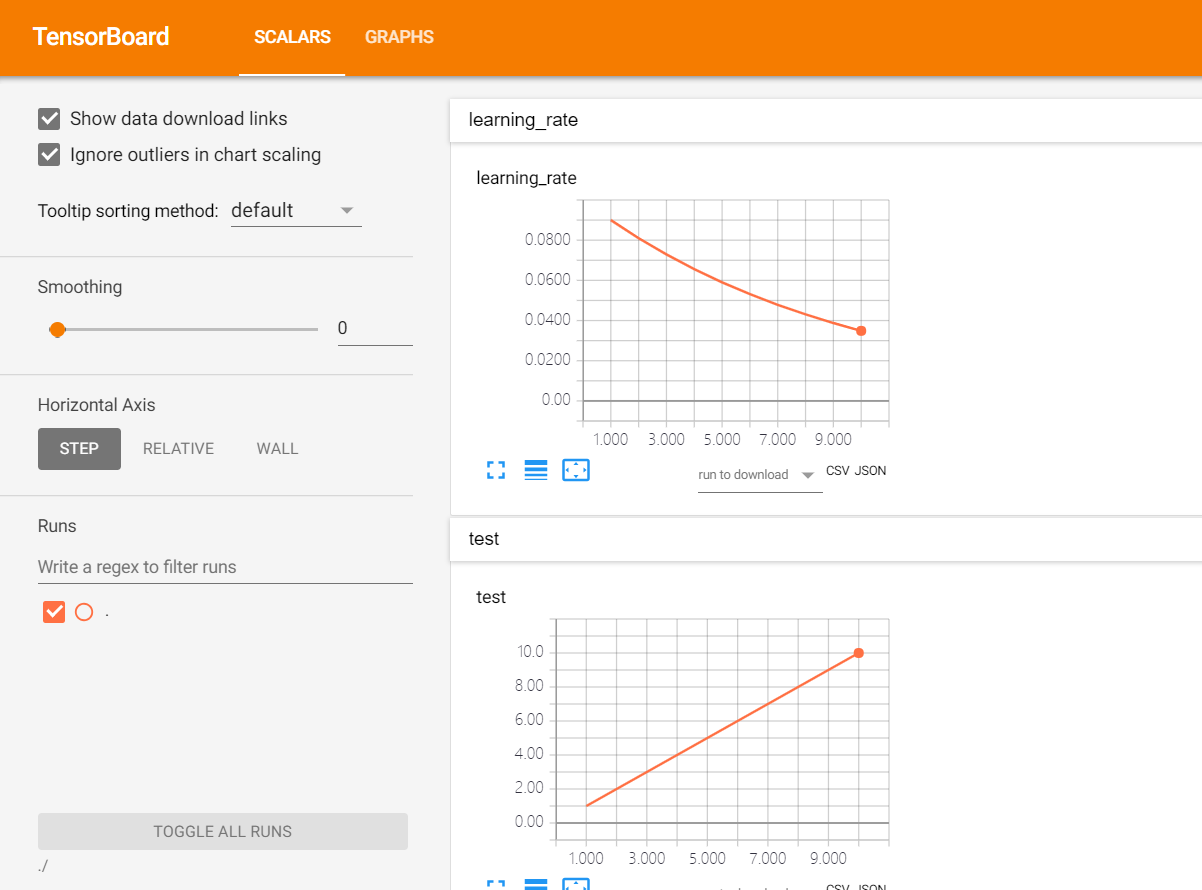
.#
最后
以上就是尊敬哑铃最近收集整理的关于tf.summary简单解析的全部内容,更多相关tf内容请搜索靠谱客的其他文章。







![[tensorflow] summary op 用法总结](https://www.shuijiaxian.com/files_image/reation/bcimg5.png)
发表评论 取消回复