由于自己的研究方向主要是文本处理、分类、预测。在学习了深度学习的基本代码后,最近实践文本相似度的相关深度模型的过程中,由于对Tensorflow框架的了解太少,在看别人写的代码的过程中,有些困惑,所以就抽出点时间学了一下Tensorflow框架。这里主要讲解学习炼数成金的Tensorflow视频教程的学习笔记。
此视频课程的课程大纲如下:
第一课 Tensorflow简介,Anaconda安装,Tensorflow的CPU版本安装。
第二课 Tensorflow的基础使用,包括对图(graphs),会话(session),张量(tensor),变量(Variable)的一些解释和操作。
第三课 Tensorflow线性回归以及分类的简单使用,softmax介绍。
第四课 交叉熵(cross-entropy),过拟合,dropout以及Tensorflow中各种优化器的介绍。
第五课 使用Tensorboard进行结构可视化,以及网络运算过程可视化。
第六课 卷积神经网络CNN的讲解,以及用CNN解决MNIST分类问题。
第七课 递归神经网络LSTM的讲解,以及LSTM网络的使用。
第八课 保存和载入模型,使用Google的图像识别网络inception-v3进行图像识别。
第九课 Tensorflow的GPU版本安装。设计自己的网络模型,并训练自己的网络模型进行图像识别。
第十课 多任务学习以及验证码识别。
第十一课 word2vec讲解和使用,cnn解决文本分类问题。
第十二课 语音处理以及使用LSTM构建语音分类模型。
由于我有一定的基础了,所以我是选择性的学习的。
第四课:Tensorflow中各种优化介绍(学习率更改、权重w的初始化、优化器Optimizer的选择、激活函数的选择、Dropout的使用、代价函数的选择)
1. 学习率的更改,伪代码如下:
lr = tf.Variable(0.001, dtype=tf.float32)
# ...
train_step = tf.train.AdamOptimizer(lr).minimize(loss)
# ...
for step in range(100):
sess.run(tf.assign(lr, 0.001 * (0.95 ** step)))
for batch in batches:
# train
learning_rate = sess.run(lr)
# 输出准确率2. 权重w的初始化
w = tf.Variable(tf.truncated_normal([diminput, dimhidden], stddev=0.1))3. 优化器Optimizer的选择
标准梯度下降法:计算所有样本汇总误差,根据总误差来更新权值;缺点:太慢;
随机梯度下降法:随机抽取一个样本来计算误差,然后更新权值;缺点:对噪声过于敏感
批量梯度下降法:算是一种折中方案,从总样本中选取一个批次,计算该批次数据误差,来更新权值;
Tensorflow中的优化器:

各种优化器的实验效果比较一:
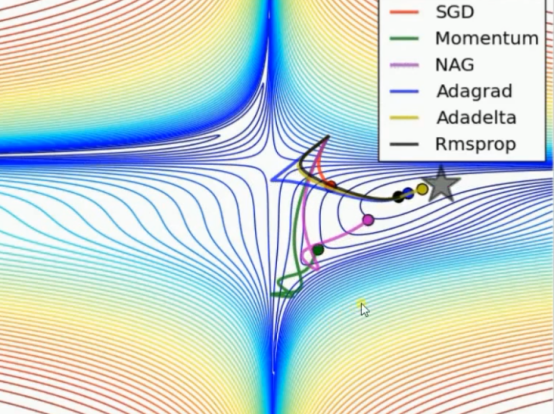
排名:Adadelta、Adagrade、Rmsprop、NAG、Momentum、SGD
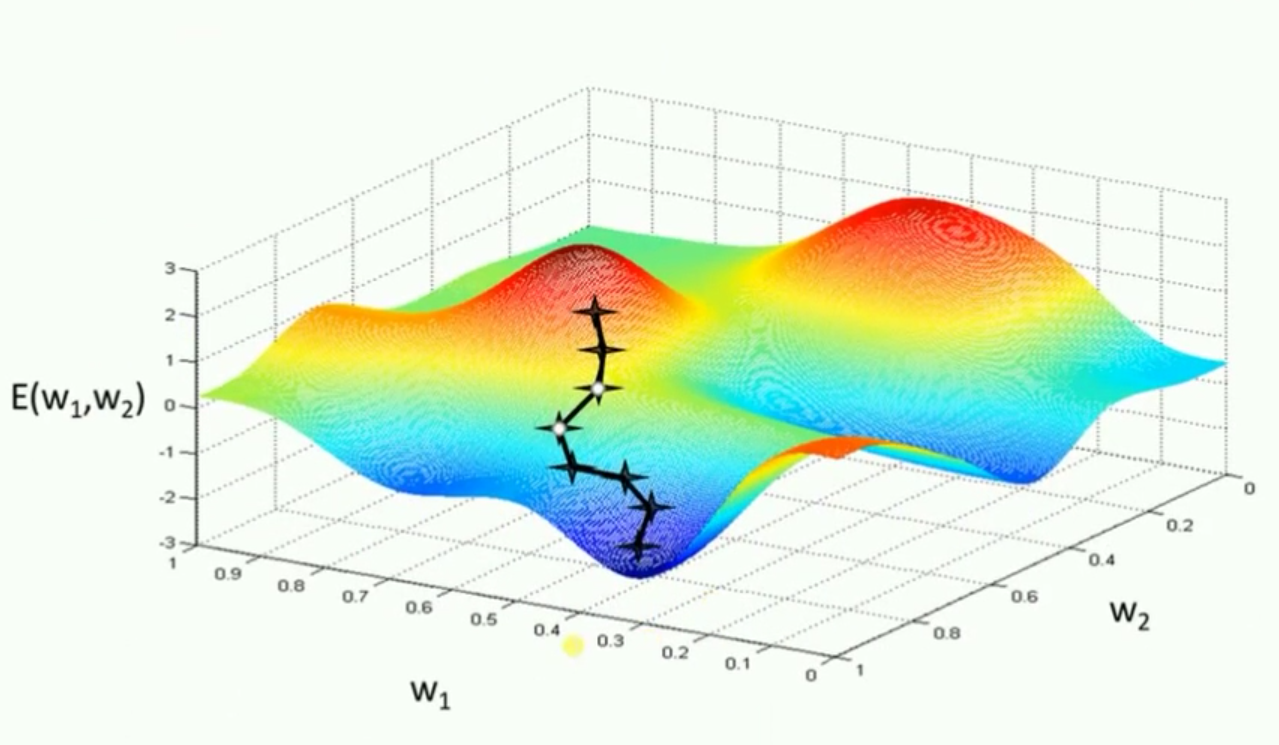
各种优化器的实验效果比较二:鞍点问题
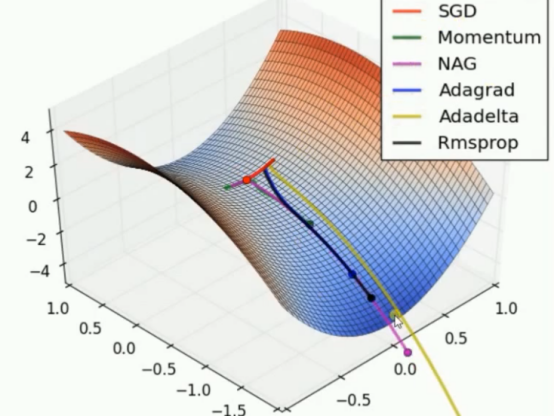
排名:
Adadelta以很快的速度冲下来;
NAG在最初的迷茫之后快速走下鞍点,速度很快;
Momentum也在迷茫之后走下鞍点,但是没有NAG;
Rmsprop没有迷茫,但是下降速度有点慢;
Adagrad 也没有迷茫,但是速度更慢;
SGD,直接在鞍点下不来了。
总结:
优化器各有优缺点,别的优化器收敛速度会比较快,但是SGD最后的结果一般来说很好。
以下网址有不错的优化器的总结,可以参考:
https://blog.csdn.net/g11d111/article/details/76639460
4. Dropout的使用
dropout主要是解决过拟合问题
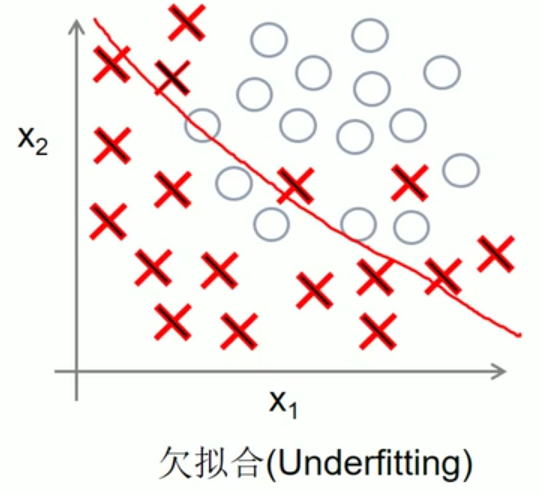
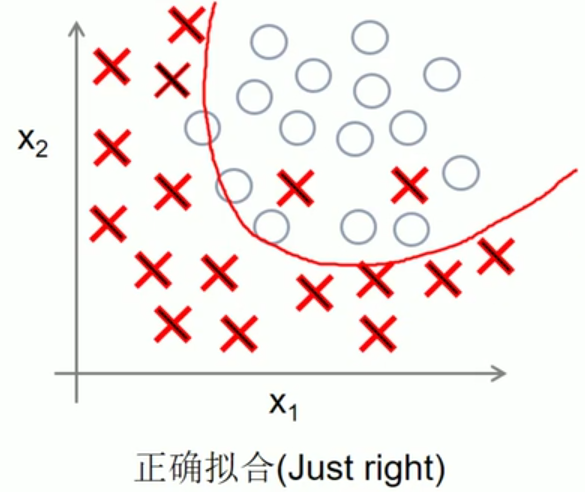
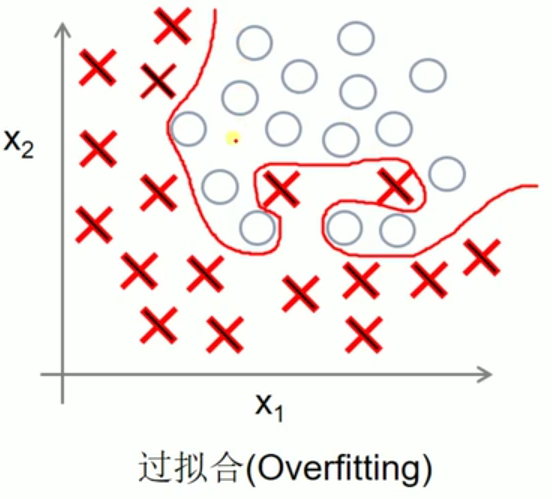
过拟合的解决方法有三种:增加数据集、正则化方法、Dropout
Dropout的实现方式如下:
Layer1_y = tf.nn.softmax(x)
Layer1_drop = tf.nn.dropout(Layer1_y, keep_prob)5.代价函数的选择
一般训练都是以梯度下降来实现的。
代价函数用来计算损失,Tensorflow中主要用三种代价函数:
总的来说:输出神经元是线性的,用二次代价函数;输出神经元是S型的函数,如果用的sigmoid激活函数,使用交叉熵代价函数;如果用的softmax激活函数,使用对数似然代价函数。
(1)二次代价函数:
loss = tf.reduce_mean(tf.square(y - y_pred))二次代价函数在梯度下降时与激活函数的导数有关系,就会导致问题。
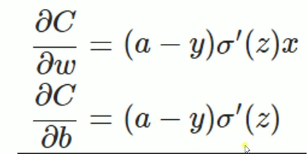
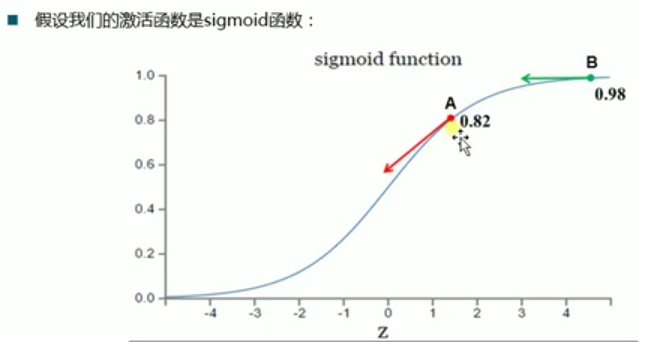
![]()
(2)交叉熵:解决了二次代价函数的问题
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=y_pred))
# y_pred是用softmax激活函数
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=y, logits=y_pred))
# y_pred是用sigmoid激活函数

第五课 使用Tensorboard进行结构可视化。查看网络结构、查看网络运行数据、以手写字分类为例实现训练的可视化。
1. 查看网络结构
# 一般写神经网络都会写
with tf.name_scope("***"):
W = tf.Variable("***", name="W")
b = tf.Variable("***", name="b")
# ...
writer = tf.summary.FileWriter(FLAGS.data_dir, graph=sess.graph)
# 运行就ok了,然后在cmd中切换到相应保存的磁盘中,输入:tensorboard --logdir=(writer保存的路径)
# 会出现一个网址,复制,在浏览器中打开大致效果如下:
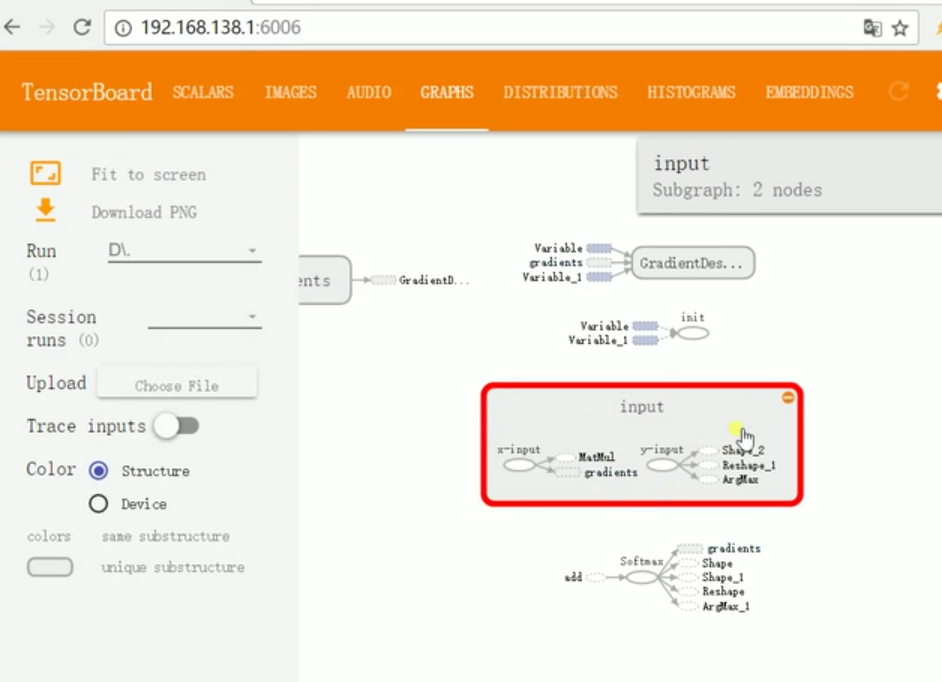
2.查看网络运行数据
# 1.定义一个方法
def variable_summaries(var):
with tf.name_scope('summaries'):
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean) # 平均值
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev', stddev) # 标准差
tf.summary.scalar("max", tf.reduce_max(var)) # 最大值
tf.summary.scalar('min', tf.reduce_min(var)) # 最小值
tf.summary.histogram('histogram', var) # 直方图
#
# 2. 使用方法,如w的数据变化:一般查看loss,w,b,accuracy
# W值的查看
W = tf.Variable("***", name="W")
variable_summaries(W)
# loss值的查看
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=y, logits=y_pred))
tf.summary.scalar('loss', loss)
# accuracy值的查看
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
tf.summary.scalar('accuracy', accuracy)
# 3. 合并所有的summary
merged = tf.summary.merge_all()
# 4. 在运行的代码加上merged
summary, _ = sess.run([merged, train_step], feed_dict={x:batch_x, y:batch_y})
# 5. 把summary添加至writer中
writer.add_summary(summary, step)
# 注意:一般我们训练时使用的是如下格式:
for step in range(100):
for batch in batches:
summary, _ = sess.run([merged, train_step], feed_dict={x:batch_x, y:batch_y})
writer.add_summary(summary, step)
# 这一格式会使得样本点比较少,画出的图形不够平滑,想要使得样本点多,可以采用如下形式:
for step in range(100):
batch_x, batch_y = mnist.train_next_batch(100)
summary, _ = sess.run([merged, train_step], feed_dict={x: batch_x, y: batch_y})
writer.add_summary(summary, step)
# 6.最后在网页上浏览就有图像显示
# 如果loss的生成图上下跳动很厉害的话,说明learning_rate设置大了。大致效果如下:
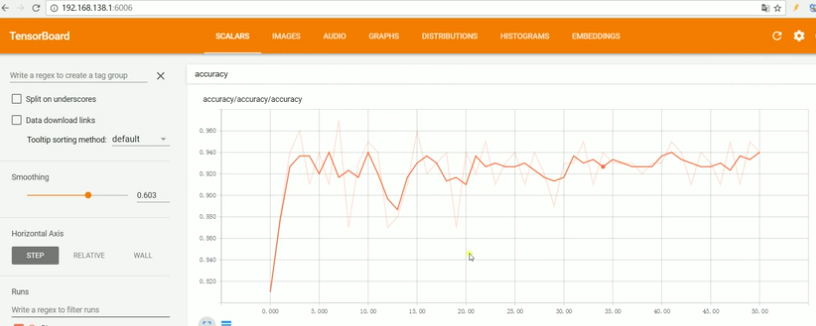
3. 以手写字分类为例实现训练的可视化。
具体实现我没看,主要自己不做图像处理这块,所以就只了解了哈,这里截了一下最终的效果图:
训练前数据分布:
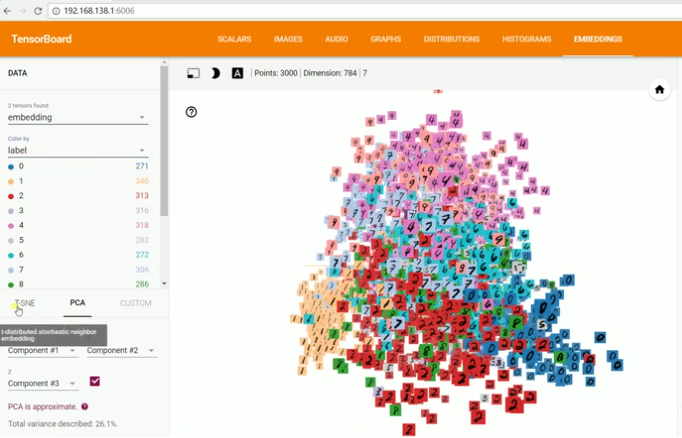
训练后数据分布:
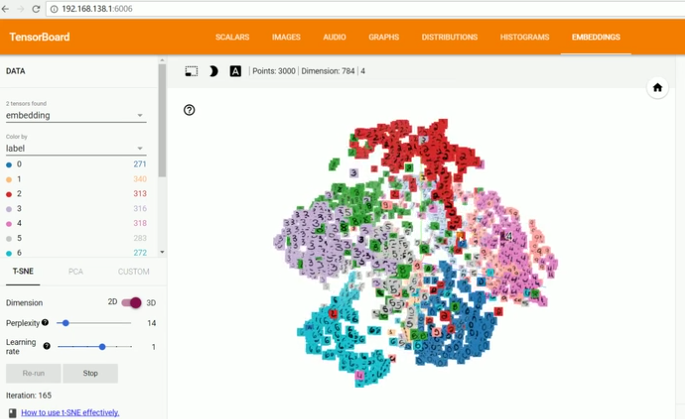
第八课 主要讲解:保存和载入模型,使用Google的图像识别网络inception-v3进行图像识别。
1. 保存模型
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init)
for epoch in range(21):
for batch in range(n_batch):
# train
acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels})
print("Iter " + str(epoch) + " Testing Accuracy: " + str(acc))
saver.save(sess, model_dir + '/test_net.ckpt')2.载入模型
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init)
acc1 = sess.run(accuracy, feed_dict={x:mnist.test.images, y:mnist.test.labels})
saver.restore(sess, model_dir + '/test_net.ckpt')
acc2 = sess.run(accuracy, feed_dict={x:mnist.test.images,y:mnist.test.labels})
print(" Init Accuracy" + str(acc1))
print(" Restore Accuracy: " + str(acc2))3. 使用inception-v3进行图像识别
这里我也没看,主要自己不做图像处理这块。以后用到的话可以补一下。
第九课 Tensorflow的GPU版本安装。设计自己的网络模型,并训练自己的网络模型进行图像识别。
这节主要讲解如何训练自己的模型代码,主要有三种方法:
1. 自己写自己从头构建网络,从头训练;
2. 用一个现成的质量比较好的模型,固定前面参数,在后面添加几层,训练后面的参数;
3. 改造现成的质量比较好的模型,训练整个网络的模型(初始层的学习率比较低);也就是对已有模型的权重参数做微调,重点训练最后几层自己写的模型的权重参数,但总体来说所有的权重参数都有改变。
第十一课 word2vec讲解和使用,cnn解决文本分类问题。
对于这一节课的内容,我在后边有一节专门讲解word2vec预训练的时候着重讲解。
最后
以上就是灵巧香菇最近收集整理的关于深度学习(六):炼数成金的Tensorflow教程学习笔记(含代码)的全部内容,更多相关深度学习(六):炼数成金内容请搜索靠谱客的其他文章。






![[tensorflow] summary op 用法总结](https://www.shuijiaxian.com/files_image/reation/bcimg5.png)

发表评论 取消回复