本即将毕业工科硕士,编程小白,偶然认识了python,就觉得这东西很牛逼,在网上找了几节python教程视频看完后更加感受到了它的强大之处。在看视频教程的过程中想到能用python把工作学习中的一些繁琐量大的工作变得简单,也就是自动化办公,在具体实现的过程中也遇到了很多问题,好在参阅了各路大神的杰作,将各种困难逐一击破,可能在大神看来解决的办法比较蠢,但终究达到了目的,现在已经在本人所在课题组推广。发这篇博文有三个目的:1.给其他有相同需要的搬砖人提供帮助;2.和大家交流其中一些问题的解决方法;3.希望在各路大神的指点下,能获得更高程度的提升。
先介绍下问题背景。我们实验室有一台热失重分析仪,这台设备基本实验室百分之六十的人都会用到,但是在实验完成后处理实验数据是个大麻烦,少则几十组,多则上百组。
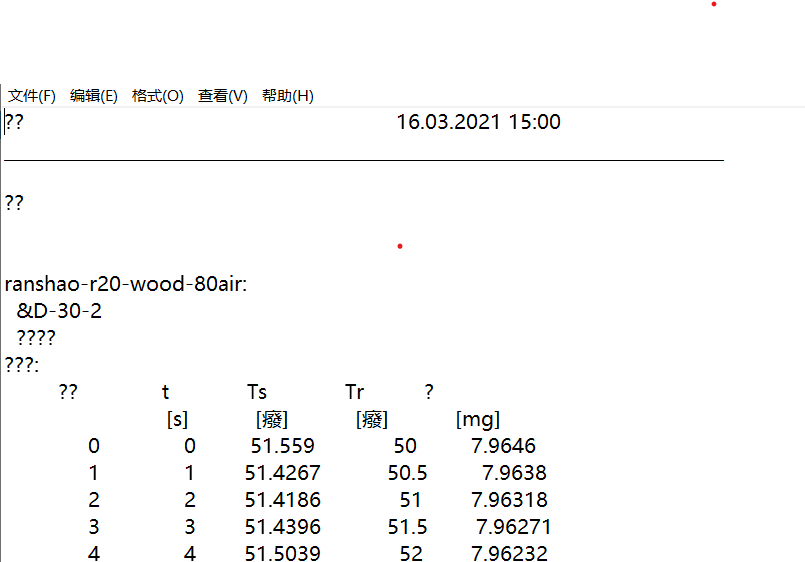
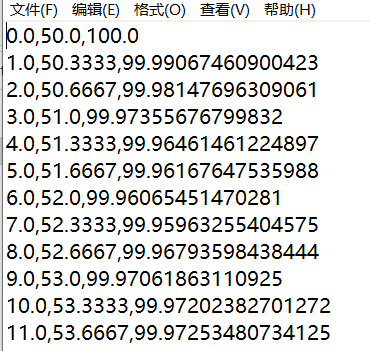
如上图,需要处理的是上百个这样的txt,最后需要处理成下图形式的txt,然后导入Proteus Analysis软件做相关分析。中间的变化主要是去掉了原有的无关内容(如标题,标尾等),只保留第一列、第四列、第五列的数据,第五列的数据由质量转换为失重百分比,每列数据以“,”分隔。
话不多说,先分享全部代码,再做详细解释!
#最终保存的是.txt,适合于热重分析
import numpy as np
import os
import xlrd
import xlwt
from openpyxl import Workbook
from openpyxl.utils import get_column_letter
path=r'D:Python data savetestauto worktest datatxt data' #给出文件路径
files=os.listdir(path) #得到文件夹下所有文件的名称
fileslens=len(files) #得到文件夹下有多少个txt文件
for filename in files:
domain=os.path.abspath(r'D:Python data savetestauto worktest datatxt data')
filename2=os.path.join(domain,filename) #filename2是带路径的文件名
with open(filename2,'r') as f:
data=f.readlines()[12:int((len(f.readlines()))-17)]
f.close()
lensdata=len(data)
returnMat=np.zeros((lensdata,5))
classLabelVector=[]
index=0
returnMat[0,:]=[1,2,3,4,5]
returnMat[1,:]=[6,7,8,9,10]
for line in data: #遍历文本中的每一行
line=line.strip() #删除每一行首尾的空格
listline=line.split(" ") #按“ ”分割
b=[x.strip() for x in listline if x.strip() !=''] #删除每一行内容中的空格
returnMat[index,:]=b
index+=1
number_row=returnMat.shape[0]
fixnumber=returnMat[0][4]
for i in range(number_row):
returnMat[i][4]=(float(returnMat[i][4])/float(fixnumber))*100
domain2=os.path.abspath(r'D:Python data savetestauto worktest dataxiugai txt data2')
dest_filename=os.path.join(domain2,filename)
with open(dest_filename,"w",encoding='utf-8') as m:
returnMat2=np.zeros((number_row,3))
classLabelVector=[]
index=0
returnMat2[0,:]=[1,2,3]
returnMat2[1,:]=[4,5,6]
#新建一个returnMat2用来接收returnMat的0,3,4列,第四列通过循环转换为百分比
for j in range(number_row):
returnMat2[j][0]=returnMat[j][0]
returnMat2[j][1]=returnMat[j][3]
returnMat2[j][2]=returnMat[j][4]
#写入第一行(第一块)
m.write(str(returnMat2[0,0])) #写第一行第一列
for n in range(1,np.size(returnMat2,1)):
m.write(','+str(returnMat2[0,n])) #写第一列后面的列
#写入第一行后面的行(第二块)
for k in range(1,np.size(returnMat2,0)):
m.write('n'+str(returnMat2[k,0]))
for f in range(1,np.size(returnMat2,1)):
m.write(','+str(returnMat2[k,f]))对这一问题我的解决思路是,先搞定一个文件,再通过for循环,处理文件夹下的每一个文件。
所以,第一步,读取目标文件
domain=os.path.abspath(r'D:Python data savetestauto worktest datatxt data')
#指定想要处理的文件的路径
filename2=os.path.join(domain,“filename”)
#filename是给定路径下要处理的文件名,在这里它是字符串要加双引
with open(filename2,'r') as f:
#读取指定文件
data=f.readlines()[12:int((len(f.readlines()))-17)]
#按行读取并赋值给data
#[12:int((len(f.readlines()))-17)]表示的是只读第13行到倒数17行
f.close()第二步,处理数据成想要的样子
lensdata=len(data)#读取到内容的总行数
returnMat=np.zeros((lensdata,5))#建一个同行数、同列数的数组,用来把list数据矩阵化,
#列数是我根据自己的文件数出来的
classLabelVector=[]
index=0
returnMat[0,:]=[1,2,3,4,5]
returnMat[1,:]=[6,7,8,9,10]
for line in data: #遍历文本中的每一行
line=line.strip() #删除每一行首尾的空格
listline=line.split(" ") #按“ ”分割,最后结果中每列数据之间出现不同个数的
#空格,需要删掉空格
b=[x.strip() for x in listline if x.strip() !=''] #删除每一行内容中的空格
returnMat[index,:]=b
index+=1 #把每行数据依次保存到矩阵
number_row=returnMat.shape[0] #矩阵的行数
fixnumber=returnMat[0][4] #把第五列的第一个数值赋给fixnumber
for i in range(number_row):
returnMat[i][4]=(float(returnMat[i][4])/float(fixnumber))*100
#第五列数据转换成百分比格式第三步,把处理好的数据写入到目标文件中,保存为txt按原文件名命名
domain2=os.path.abspath(r'D:Python data savetestauto worktest dataxiugai txt data2')
#给定要保存到的位置
dest_filename=os.path.join(domain2,filename)
#给文件按原文件名命名
with open(dest_filename,"w",encoding='utf-8') as m:
returnMat2=np.zeros((number_row,3))
classLabelVector=[]
index=0
returnMat2[0,:]=[1,2,3]
returnMat2[1,:]=[4,5,6]
#新建一个returnMat2用来接收returnMat的0,3,4列
for j in range(number_row):
returnMat2[j][0]=returnMat[j][0]
returnMat2[j][1]=returnMat[j][3]
returnMat2[j][2]=returnMat[j][4]
#把最终结果写入到目标文件中
#写入第一行(第一块)
m.write(str(returnMat2[0,0])) #写第一行第一列
for n in range(1,np.size(returnMat2,1)):
m.write(','+str(returnMat2[0,n])) #写第一列后面的列
#写入第一行后面的行(第二块)
for k in range(1,np.size(returnMat2,0)):
m.write('n'+str(returnMat2[k,0]))
for f in range(1,np.size(returnMat2,1)):
m.write(','+str(returnMat2[k,f]))第四步,实现批量处理
path=r'D:Python data savetestauto worktest datatxt data' #给出文件路径
files=os.listdir(path) #得到文件夹下所有文件的名称
fileslens=len(files) #得到文件夹下有多少个txt文件
for filename in files:
domain=os.path.abspath(r'D:Python data savetestauto worktest datatxt data')
#想要处理的文件的路径
filename2=os.path.join(domain,filename)
#filename是给定路径下要处理的文件名
with open(filename2,'r') as f: 成功实现批量预处理热失重数据的目标,得到的文件可以直接导入Proteus Analysis软件。另外类似的还写了一个txt转xlsx的代码,用以导入到origin作图,请各位客观大爷们享用。
#最终保存的是.xlsx,适合于origin作图
import numpy as np
import os
import xlrd
import xlwt
from openpyxl import Workbook
from openpyxl.utils import get_column_letter
path=r'D:Python data savetestauto worktest datatxt data' #给出文件路径
files=os.listdir(path) #得到文件夹下所有文件的名称
fileslens=len(files) #得到文件夹下有多少个txt文件
for filename in files:
domain=os.path.abspath(r'D:Python data savetestauto worktest datatxt data')
filename2=os.path.join(domain,filename) #filename2是带路径的文件名
with open(filename2,'r') as f:
data=f.readlines()[12:int((len(f.readlines()))-17)]
f.close()
lensdata=len(data)
returnMat=np.zeros((lensdata,5))
classLabelVector=[]
index=0
returnMat[0,:]=[1,2,3,4,5]
returnMat[1,:]=[6,7,8,9,10]
for line in data: #遍历文本中的每一行
line=line.strip() #删除每一行首尾的空格
listline=line.split(" ") #按“ ”分割
b=[x.strip() for x in listline if x.strip() !=''] #删除每一行内容中的空格
returnMat[index,:]=b
index+=1
#创建工作表和工作簿
wb=Workbook()
domain2=os.path.abspath(r'D:Python data savetestauto worktest dataexcel data2')
filename3=filename[:len(filename)-4]+".xlsx"
dest_filename=os.path.join(domain2,filename3)
#r'D:Python data savetestauto worktest dataempty_book.xlsx'
ws1=wb.active
ws1.title='sheet1'
number_row=returnMat.shape[0] #获取矩阵(数组)行数
for j in range(number_row):
ws1.cell(j+1,1).value=returnMat[j][3]
fixnumber=returnMat[0][4]
for i in range(number_row):
returnMat[i][4]=(float(returnMat[i][4])/float(fixnumber))*100
ws1.cell(j+1,2).value=returnMat[j][4]
#保存
wb.save(dest_filename)小白第一次分享,还请大家批的轻点
最后
以上就是缓慢西牛最近收集整理的关于实验数据用python自动批量处理,速来get的全部内容,更多相关实验数据用python自动批量处理内容请搜索靠谱客的其他文章。
![[ 游戏开发日记with Unity ] 首先,认识你自己,或者说Player吧。 有关于Rigidbody2D和Collider的一些使用知识写在前面Q.问题是什么? What is the “Problem”?See U](https://www.shuijiaxian.com/files_image/reation/bcimg17.png)







发表评论 取消回复