今天有一个数据库有点反常,早上的时候报出了CPU使用率的警告。
警告内容如下:
首先查看了CPU的使用情况
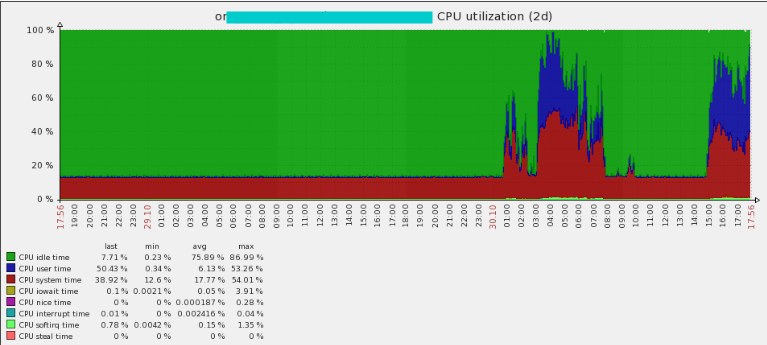
查看了DB time的情况,发现在早晨和下午的时候都开始有大的波动。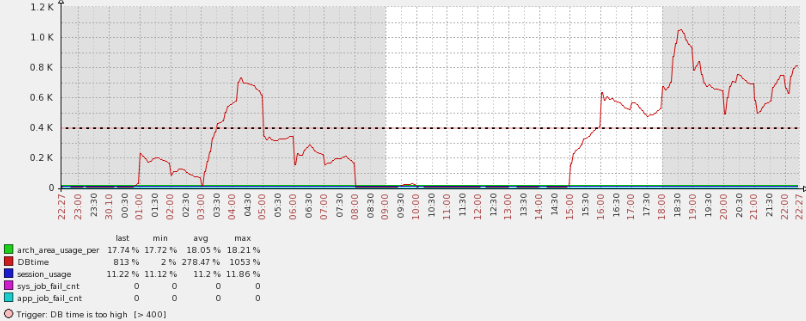
至于初步原因,自己查看分析图发现在这段时间内产生了大量的日志切换。
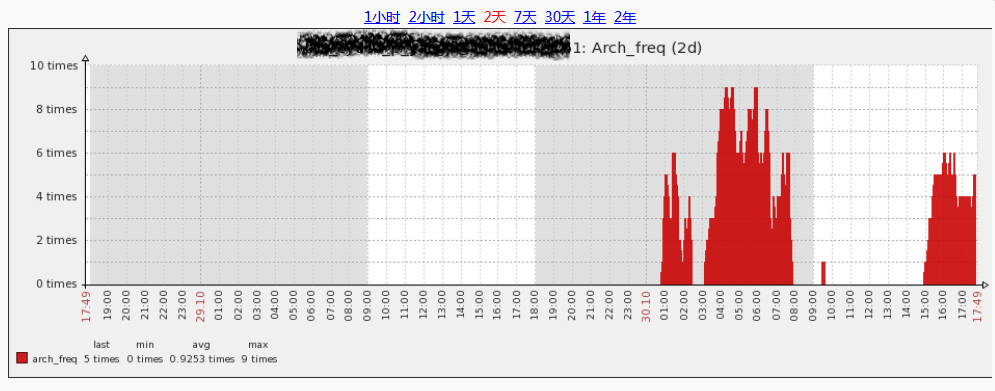
所以这个问题查看了sar的结果得到了基本的确认。
07:40:01 AM CPU %user %nice %system %iowait %steal %idle
03:40:01 AM all 40.46 0.00 42.52 0.09 0.00 16.92
03:50:01 AM all 42.85 0.00 46.63 0.06 0.00 10.45
04:00:01 AM all 44.83 0.03 50.16 0.05 0.00 4.92
04:10:01 AM all 38.23 0.00 50.79 0.11 0.00 10.87
04:20:02 AM all 45.22 0.00 52.64 0.04 0.00 2.10
04:30:01 AM all 39.96 0.00 51.98 0.21 0.00 7.85
04:40:01 AM all 40.59 0.00 52.29 0.12 0.00 6.99
04:50:01 AM all 36.73 0.00 48.04 0.17 0.00 15.06
查看了awr中的sql占用DB time的情况,发现有一条语句的占用情况实在是太高了。从执行情况来看似乎也不是很慢,但是DB time就是很高。
SNAP_ID SQL_ID EXECUTIONS_DELTA ELAPSED_TI PER_TOTAL
---------- ------------------------------- ---------- ----------
12952 04twf1qr6hbxb 77421 12231s 94%
12952 14qykh7dc3gts 52014 4s 0%
12952 4v43gna7jcpwd 51975 6s 0%
12952 9fz0usaqnsubf 2 0s 0%
12952 c831ks00zc8c2 16676 2s 0%
对于这个问题查看了下执行计划,发现
Execution Plan
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
--------------------------------------------------------------------------------------
| 0 | MERGE STATEMENT | | | | 3 (100)|
| 1 | MERGE | UC_OPENPLATFORM_USER | | | |
| 2 | VIEW | | | | |
| 3 | NESTED LOOPS OUTER | | 6 | 5634 | 3 (0)|
| 4 | VIEW | | 1 | 13 | 0 (0)|
| 5 | SORT AGGREGATE | | 1 | 115 | |
| 6 | INDEX UNIQUE SCAN| OPNE_USER_ID_IDX | 1 | 115 | 0 (0)|
| 7 | VIEW | | 6 | 5556 | 3 (0)|
| 8 | FILTER | | | | |
| 9 | TABLE ACCESS FULL| UC_OPENPLATFORM_USER | 6 | 5556 | 3 (0)|
--------------------------------------------------------------------------------------
Note
-----
- dynamic sampling used for this statement (level=2)
发现一个特别之处在于使用了动态采样,意味着相关的表没有收集统计信息。从动态采样的结果来看,资源消耗似乎不高。
我们通过awr sql report来抓取一个执行时的执行计划的报告。
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
---------------------------------------------------------------------------------------
| 0 | MERGE STATEMENT | | 802K| 129M| 1891 (1)|
| 1 | MERGE | UC_OPENPLATFORM_USER | | | |
| 2 | VIEW | | | | |
| 3 | NESTED LOOPS OUTER | | 802K| 718M| 1891 (1)|
| 4 | VIEW | | 1 | 13 | 2 (0)|
| 5 | SORT AGGREGATE | | 1 | 20 | |
|* 6 | INDEX UNIQUE SCAN| OPNE_USER_ID_IDX | 1 | 20 | 2 (0)|
| 7 | VIEW | | 802K| 708M| 1889 (1)|
|* 8 | FILTER | | | | |
| 9 | TABLE ACCESS FULL| UC_OPENPLATFORM_USER | 802K| 41M| 1889 (1)|
---------------------------------------------------------------------------------------
发现差距还是要大的多,而且瓶颈还是在于全表扫描。
这个时候查看等待事件,发现还有buffer busy waits,查看了sga的设置情况,竟然还真是有问题。
SQL> show parameter sga
NAME TYPE VALUE
------------- ------------ --------
lock_sga boolean FALSE
pre_page_sga boolean FALSE
sga_max_size big integer 24G
sga_target big integer 12032M
这个sga占用了近24G,但是实际使用了才一半,所以使用不够充分,所以简单评估之后调整到了20G,以备不时之需。
SQL> alter system set sga_target=20G;
System altered.
但是调整之后,除去系统级的影响,发现性能提升并不是很大。那么注意力还是到了这条sql语句上。而且通过addm,sql tuning advisor也给不出建议来,看来还得自己分析分析了。
来仔细回顾一下这条语句,为什么走了全表扫描。结合执行计划,其实谓词信息就很明显了。
6 - access("USER_ID"=:1 AND "PLATFORM"=:2)
8 - filter("TW"."CNT">0)
主要问题就在于filter的部分。
那么来回顾一下这条语句。为什么需要设定CNT>0这么个条件。
MERGE INTO UC_OPENPLATFORM_USER t
USING (SELECT count(*) CNT from UC_OPENPLATFORM_USER where
USER_ID=:1 and PLATFORM=:2) tw
ON (tw.CNT>0)
WHEN MATCHED THEN UPDATE SET t.NAME=:3, t.UPDATE_DATE=SYSDATE
where USER_ID=:4 and PLATFORM=:5
WHEN NOT MATCHED THEN INSERT(USER_ID, PLATFORM, NAME,
CREATE_DATE, UPDATE_DATE) VALUES(:6, :7, :8, SYSDATE, SYSDATE)
自己琢磨了下原因,子表tw输出的是表中数据的返回结果,因为user_id是唯一性约束,所以如果匹配则值返回一条结果,如果不匹配则则返回0
根据下面的match条件进行update或者insert操作。整个语句的意思其实就是一句话,根据user_id来匹配,如果找到相关的记录就修改,如果没有就增加一条。
那么为什么需要加CNT呢,我觉得开发同学还是考虑到如果没有匹配的值,那么如果tw根据user_id来和t关联,就没法匹配了。 因为tw就是空值,肯定执行不了insert的部分。
我们来做个简单的例子,可能就会更容易理解。
首先创建一个表test含有id和name字段。插入一条记录id=100
CREATE TABLE TEST(ID NUMBER,NAME VARCHAR(100));
INSERT INTO TEST VALUES(100,'TEST');
如果使用id=100有匹配的数据,那么可能会执行update
MERGE INTO TEST t
USING (SELECT ID from TEST where ID=100 ) tw
ON (tw.ID=T.ID)
WHEN MATCHED THEN UPDATE SET t.NAME='AAA_MATCHED'
where ID= 100
WHEN NOT MATCHED THEN INSERT(ID, NAME) VALUES(100,'BBB_NOT_MATCHED') ;
1 row merged.
SQL> select *from test;
ID NAME
---------- --------------------
100 AAA_MATCHED
那么如果不匹配呢,我们给一个id为1000,肯定匹配不到。
MERGE INTO TEST t
USING (SELECT ID from TEST where ID=1000 ) tw
ON (tw.ID=T.ID)
WHEN MATCHED THEN UPDATE SET t.NAME='AAA_MATCHED'
where ID= 1000
WHEN NOT MATCHED THEN INSERT(ID, NAME) VALUES(100,'BBB_NOT_MATCHED') ;
0 rows merged.
这个时候问题来了,压根不会insert
所以根据这个情况,开发可能会有这种顾虑所以才会考虑通过CNT>0来得到这种匹配,可能他们也觉得没有办法。
其实可以动个小脑筋,我们直接使用一个union all来给出一个dummy的数据,保证是不会匹配的id
比如id根据业务是需要为证书或者字符,那么给一个负数肯定是不糊匹配的。
MERGE INTO TEST t
USING (SELECT ID from TEST where ID=1000 union all select -1 id from dual ) tw
ON (tw.ID=T.ID)
WHEN MATCHED THEN UPDATE SET t.NAME='AAA_MATCHED'
where ID= 1000
WHEN NOT MATCHED THEN INSERT(ID, NAME) VALUES(100,'BBB_NOT_MATCHED') ;
1 rows merged.
这个时候就达到了预期的结果,而且是按照id来关联的,避免了全表扫描。
那么真实环境中的sql语句级可以简单调整一下
MERGE INTO UC_OPENPLATFORM_USER t
USING (SELECT USER_ID from UC_OPENPLATFORM_USER where
USER_ID=:1 and PLATFORM=:2 union all select '-999' from dual) tw
ON (tw.USER_ID=T.USER_ID)
WHEN MATCHED THEN UPDATE SET t.NAME=:3, t.UPDATE_DATE=SYSDATE
where USER_ID=:4 and PLATFORM=:5
WHEN NOT MATCHED THEN INSERT(USER_ID, PLATFORM, NAME,
CREATE_DATE, UPDATE_DATE) VALUES(:6, :7, :8, SYSDATE, SYSDATE)
这样就可以满足需求了,而且全表扫描也没有了。
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
----------------------------------------------------------------------------------------------
| 0 | MERGE STATEMENT | | 2 | 338 | 8 (0)|
| 1 | MERGE | UC_OPENPLATFORM_USER | | | |
| 2 | VIEW | | | | |
| 3 | NESTED LOOPS OUTER | | 2 | 312 | 8 (0)|
| 4 | VIEW | | 2 | 204 | 4 (0)|
| 5 | UNION-ALL | | | | |
|* 6 | INDEX UNIQUE SCAN | OPNE_USER_ID_IDX | 1 | 20 | 2 (0)|
| 7 | FAST DUAL | | 1 | | 2 (0)|
| 8 | TABLE ACCESS BY INDEX ROWID| UC_OPENPLATFORM_USER | 1 | 54 | 2 (0)|
|* 9 | INDEX UNIQUE SCAN | OPENPLATFORM_USER | 1 | | 1 (0)|
----------------------------------------------------------------------------------------------
这样就达到了初步效果,所以下一步就是建议开发同学来这么修改了。因为还不能动态修改,所以这个问题就是万事俱备只欠东风了。
通过这个案例可以发现,其实很多问题还是需要去分析原因,为什么要写成那样,是出于什么样的考虑,可能出发点是好的,但是结果把问题从一个极端逮到了另外一个极端。
警告内容如下:
ZABBIX-监控系统:
------------------------------------
报警内容: CPU utilization is too high
------------------------------------
报警级别: PROBLEM
------------------------------------
监控项目: CPU idle time:44.61 %
------------------------------------
报警时间:2015.10.30-06:51:00
首先查看了CPU的使用情况
查看了DB time的情况,发现在早晨和下午的时候都开始有大的波动。
至于初步原因,自己查看分析图发现在这段时间内产生了大量的日志切换。
所以这个问题查看了sar的结果得到了基本的确认。
07:40:01 AM CPU %user %nice %system %iowait %steal %idle
03:40:01 AM all 40.46 0.00 42.52 0.09 0.00 16.92
03:50:01 AM all 42.85 0.00 46.63 0.06 0.00 10.45
04:00:01 AM all 44.83 0.03 50.16 0.05 0.00 4.92
04:10:01 AM all 38.23 0.00 50.79 0.11 0.00 10.87
04:20:02 AM all 45.22 0.00 52.64 0.04 0.00 2.10
04:30:01 AM all 39.96 0.00 51.98 0.21 0.00 7.85
04:40:01 AM all 40.59 0.00 52.29 0.12 0.00 6.99
04:50:01 AM all 36.73 0.00 48.04 0.17 0.00 15.06
查看了awr中的sql占用DB time的情况,发现有一条语句的占用情况实在是太高了。从执行情况来看似乎也不是很慢,但是DB time就是很高。
SNAP_ID SQL_ID EXECUTIONS_DELTA ELAPSED_TI PER_TOTAL
---------- ------------------------------- ---------- ----------
12952 04twf1qr6hbxb 77421 12231s 94%
12952 14qykh7dc3gts 52014 4s 0%
12952 4v43gna7jcpwd 51975 6s 0%
12952 9fz0usaqnsubf 2 0s 0%
12952 c831ks00zc8c2 16676 2s 0%
对于这个问题查看了下执行计划,发现
Execution Plan
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
--------------------------------------------------------------------------------------
| 0 | MERGE STATEMENT | | | | 3 (100)|
| 1 | MERGE | UC_OPENPLATFORM_USER | | | |
| 2 | VIEW | | | | |
| 3 | NESTED LOOPS OUTER | | 6 | 5634 | 3 (0)|
| 4 | VIEW | | 1 | 13 | 0 (0)|
| 5 | SORT AGGREGATE | | 1 | 115 | |
| 6 | INDEX UNIQUE SCAN| OPNE_USER_ID_IDX | 1 | 115 | 0 (0)|
| 7 | VIEW | | 6 | 5556 | 3 (0)|
| 8 | FILTER | | | | |
| 9 | TABLE ACCESS FULL| UC_OPENPLATFORM_USER | 6 | 5556 | 3 (0)|
--------------------------------------------------------------------------------------
Note
-----
- dynamic sampling used for this statement (level=2)
发现一个特别之处在于使用了动态采样,意味着相关的表没有收集统计信息。从动态采样的结果来看,资源消耗似乎不高。
我们通过awr sql report来抓取一个执行时的执行计划的报告。
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
---------------------------------------------------------------------------------------
| 0 | MERGE STATEMENT | | 802K| 129M| 1891 (1)|
| 1 | MERGE | UC_OPENPLATFORM_USER | | | |
| 2 | VIEW | | | | |
| 3 | NESTED LOOPS OUTER | | 802K| 718M| 1891 (1)|
| 4 | VIEW | | 1 | 13 | 2 (0)|
| 5 | SORT AGGREGATE | | 1 | 20 | |
|* 6 | INDEX UNIQUE SCAN| OPNE_USER_ID_IDX | 1 | 20 | 2 (0)|
| 7 | VIEW | | 802K| 708M| 1889 (1)|
|* 8 | FILTER | | | | |
| 9 | TABLE ACCESS FULL| UC_OPENPLATFORM_USER | 802K| 41M| 1889 (1)|
---------------------------------------------------------------------------------------
发现差距还是要大的多,而且瓶颈还是在于全表扫描。
这个时候查看等待事件,发现还有buffer busy waits,查看了sga的设置情况,竟然还真是有问题。
SQL> show parameter sga
NAME TYPE VALUE
------------- ------------ --------
lock_sga boolean FALSE
pre_page_sga boolean FALSE
sga_max_size big integer 24G
sga_target big integer 12032M
这个sga占用了近24G,但是实际使用了才一半,所以使用不够充分,所以简单评估之后调整到了20G,以备不时之需。
SQL> alter system set sga_target=20G;
System altered.
但是调整之后,除去系统级的影响,发现性能提升并不是很大。那么注意力还是到了这条sql语句上。而且通过addm,sql tuning advisor也给不出建议来,看来还得自己分析分析了。
来仔细回顾一下这条语句,为什么走了全表扫描。结合执行计划,其实谓词信息就很明显了。
6 - access("USER_ID"=:1 AND "PLATFORM"=:2)
8 - filter("TW"."CNT">0)
主要问题就在于filter的部分。
那么来回顾一下这条语句。为什么需要设定CNT>0这么个条件。
MERGE INTO UC_OPENPLATFORM_USER t
USING (SELECT count(*) CNT from UC_OPENPLATFORM_USER where
USER_ID=:1 and PLATFORM=:2) tw
ON (tw.CNT>0)
WHEN MATCHED THEN UPDATE SET t.NAME=:3, t.UPDATE_DATE=SYSDATE
where USER_ID=:4 and PLATFORM=:5
WHEN NOT MATCHED THEN INSERT(USER_ID, PLATFORM, NAME,
CREATE_DATE, UPDATE_DATE) VALUES(:6, :7, :8, SYSDATE, SYSDATE)
自己琢磨了下原因,子表tw输出的是表中数据的返回结果,因为user_id是唯一性约束,所以如果匹配则值返回一条结果,如果不匹配则则返回0
根据下面的match条件进行update或者insert操作。整个语句的意思其实就是一句话,根据user_id来匹配,如果找到相关的记录就修改,如果没有就增加一条。
那么为什么需要加CNT呢,我觉得开发同学还是考虑到如果没有匹配的值,那么如果tw根据user_id来和t关联,就没法匹配了。 因为tw就是空值,肯定执行不了insert的部分。
我们来做个简单的例子,可能就会更容易理解。
首先创建一个表test含有id和name字段。插入一条记录id=100
CREATE TABLE TEST(ID NUMBER,NAME VARCHAR(100));
INSERT INTO TEST VALUES(100,'TEST');
如果使用id=100有匹配的数据,那么可能会执行update
MERGE INTO TEST t
USING (SELECT ID from TEST where ID=100 ) tw
ON (tw.ID=T.ID)
WHEN MATCHED THEN UPDATE SET t.NAME='AAA_MATCHED'
where ID= 100
WHEN NOT MATCHED THEN INSERT(ID, NAME) VALUES(100,'BBB_NOT_MATCHED') ;
1 row merged.
SQL> select *from test;
ID NAME
---------- --------------------
100 AAA_MATCHED
那么如果不匹配呢,我们给一个id为1000,肯定匹配不到。
MERGE INTO TEST t
USING (SELECT ID from TEST where ID=1000 ) tw
ON (tw.ID=T.ID)
WHEN MATCHED THEN UPDATE SET t.NAME='AAA_MATCHED'
where ID= 1000
WHEN NOT MATCHED THEN INSERT(ID, NAME) VALUES(100,'BBB_NOT_MATCHED') ;
0 rows merged.
这个时候问题来了,压根不会insert
所以根据这个情况,开发可能会有这种顾虑所以才会考虑通过CNT>0来得到这种匹配,可能他们也觉得没有办法。
其实可以动个小脑筋,我们直接使用一个union all来给出一个dummy的数据,保证是不会匹配的id
比如id根据业务是需要为证书或者字符,那么给一个负数肯定是不糊匹配的。
MERGE INTO TEST t
USING (SELECT ID from TEST where ID=1000 union all select -1 id from dual ) tw
ON (tw.ID=T.ID)
WHEN MATCHED THEN UPDATE SET t.NAME='AAA_MATCHED'
where ID= 1000
WHEN NOT MATCHED THEN INSERT(ID, NAME) VALUES(100,'BBB_NOT_MATCHED') ;
1 rows merged.
这个时候就达到了预期的结果,而且是按照id来关联的,避免了全表扫描。
那么真实环境中的sql语句级可以简单调整一下
MERGE INTO UC_OPENPLATFORM_USER t
USING (SELECT USER_ID from UC_OPENPLATFORM_USER where
USER_ID=:1 and PLATFORM=:2 union all select '-999' from dual) tw
ON (tw.USER_ID=T.USER_ID)
WHEN MATCHED THEN UPDATE SET t.NAME=:3, t.UPDATE_DATE=SYSDATE
where USER_ID=:4 and PLATFORM=:5
WHEN NOT MATCHED THEN INSERT(USER_ID, PLATFORM, NAME,
CREATE_DATE, UPDATE_DATE) VALUES(:6, :7, :8, SYSDATE, SYSDATE)
这样就可以满足需求了,而且全表扫描也没有了。
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
----------------------------------------------------------------------------------------------
| 0 | MERGE STATEMENT | | 2 | 338 | 8 (0)|
| 1 | MERGE | UC_OPENPLATFORM_USER | | | |
| 2 | VIEW | | | | |
| 3 | NESTED LOOPS OUTER | | 2 | 312 | 8 (0)|
| 4 | VIEW | | 2 | 204 | 4 (0)|
| 5 | UNION-ALL | | | | |
|* 6 | INDEX UNIQUE SCAN | OPNE_USER_ID_IDX | 1 | 20 | 2 (0)|
| 7 | FAST DUAL | | 1 | | 2 (0)|
| 8 | TABLE ACCESS BY INDEX ROWID| UC_OPENPLATFORM_USER | 1 | 54 | 2 (0)|
|* 9 | INDEX UNIQUE SCAN | OPENPLATFORM_USER | 1 | | 1 (0)|
----------------------------------------------------------------------------------------------
这样就达到了初步效果,所以下一步就是建议开发同学来这么修改了。因为还不能动态修改,所以这个问题就是万事俱备只欠东风了。
通过这个案例可以发现,其实很多问题还是需要去分析原因,为什么要写成那样,是出于什么样的考虑,可能出发点是好的,但是结果把问题从一个极端逮到了另外一个极端。
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/23718752/viewspace-1819471/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/23718752/viewspace-1819471/
最后
以上就是怕孤单帽子最近收集整理的关于merge语句导致的CPU使用率过高的优化的全部内容,更多相关merge语句导致内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复