第三章 学习目标

3.1.1urllib库的概念
urllib库是Python编写爬虫程序操作URL的常用内置库。在不同的Python解释器版本下,使用方法也稍有不同,本书采用Python3.x来讲解urllib库,具体版本是Python 3.6.1。 需要说明的是,在Python 2.x中urllib库包含urllib2和urllib两个版本,而在Python 3.x中urllib2合并到了urllib中。在此总结了一些urllib模块在Python2.x和Python3.x中使用的变动,方便大家快速掌握该库的用法,具体如下所示:
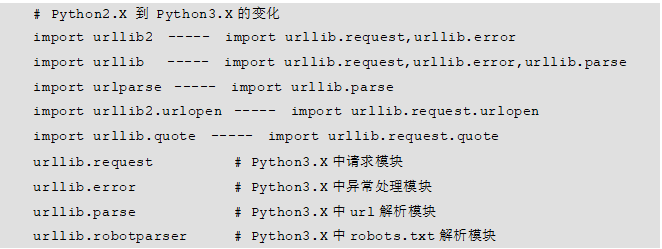
3.1.2 urllib库的使用
3.1.1节对urllib库作了简单的介绍,接下来讲解如何使用urllib库快速爬取一个网页。具体步骤如下:
导入urllib.reques模块。
使用urllib.request.urlopen()方法打开并爬取一个网页。
使用response.read()方法读取网页内容,并以utf-8格式进行解码。
具体示例代码如下: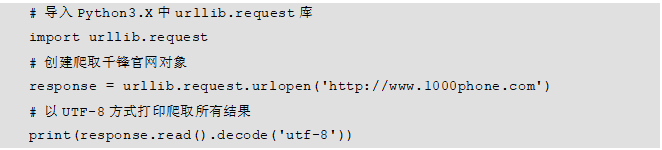
上述示例中使用到了urlopen方法,该方法有3个常用的参数,具体示例如下: 
其中,url表示需要打开的网址;data表示访问网址时需要传送的数据,一般在使用POST请求时使用;timeout是设置网站的访问超时时间。
response是爬取到的网页对象,若想读取该网页内容,可以使用response.read()方法,并使用utf-8解码即可。如果不使用read()而直接对response解码,则上述示例返回结果如下:
下面演示使用urllib库中的POST方法获取网页内容。这里使用“http://httpbin.org/
”网站演示,具体示例代码如下:
**注意使用该网站的POST方法时需要在网址后面加上“/post”,**如上述代码所示。上面代码中客户端对网站服务器发送了请求数据{‘word’: ‘hello’},并使用urllib.parse库中bytes()方法将请求数据进行转换后,放入urllib.request.urlopen()方法的data参数中,这样就完成了一次POST请求。
运行该程序,结果如图所示。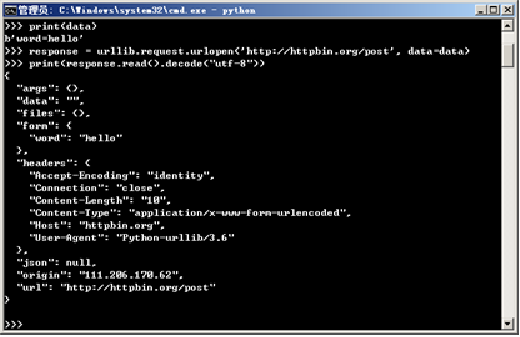
此时可以看到客户端通过POST请求向网站服务器传递了表单数据“word”:“hello”,程序也返回了相应的结果。
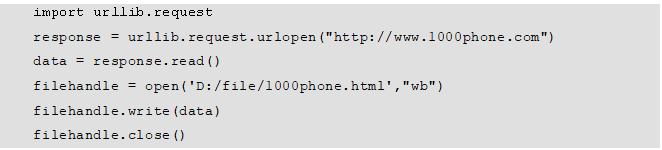
通过上面的学习,相信大家已经可以使用urllib库对网页进行简单爬取,如果爬取的网页结果想要保存到本地,可通过如下代码实现:
1.
2.
代码中首先通过open()函数以wb(二进制写入)的方式打开文件,打开后再将其赋值给变量filehandle,然后再用write()方法将爬取的data数据写入打开的文件中,写入完成后使用close()方法关闭该文件,使其不能再进行读写操作,程序到此结束。
除此方法外,还可以使用urllib.request中的urlretrieve()方法直接将对应信息写入本地文件,具体代码如下所示:
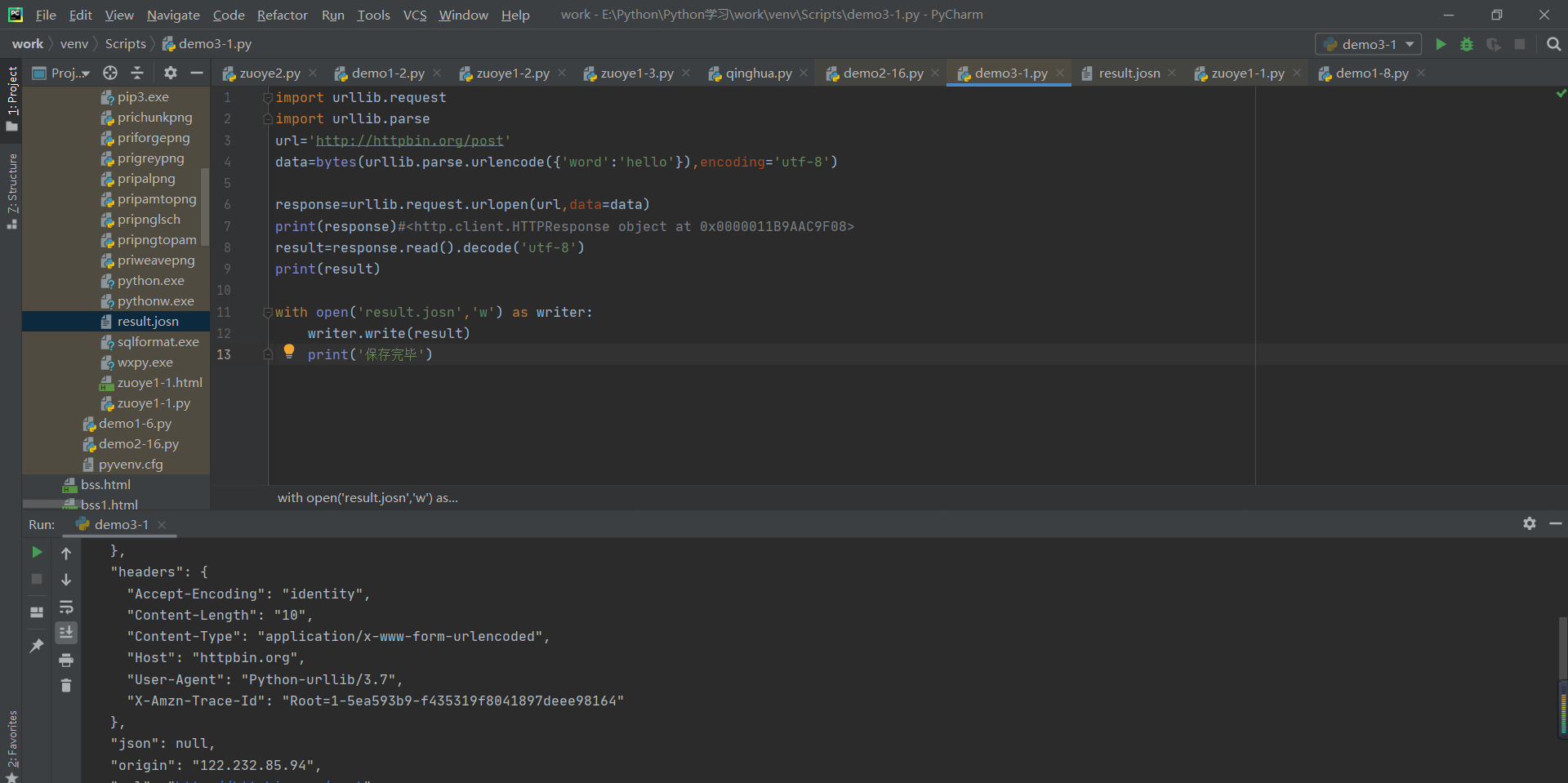
urllib库中还有一些常用方法,如例所示。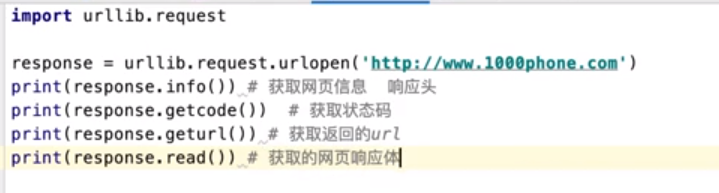

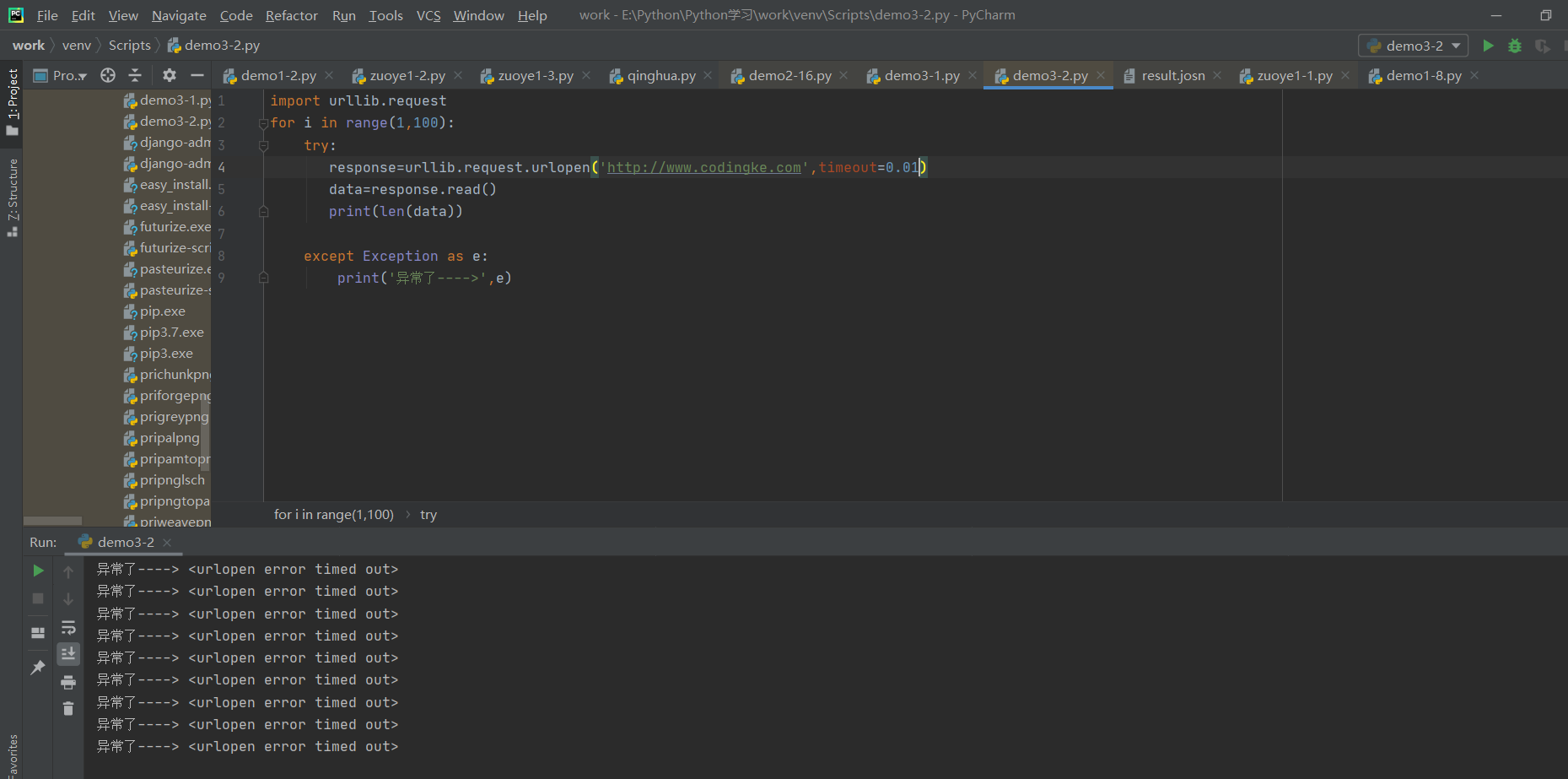
在浏览网页时,如果此网页长时间没有响应,系统就会提示该网页超时无法打开。在爬取网页时正确设置timeout的值,可以避免超时异常。其设置格式代码如下:
比如,有的网站响应快,若以3秒作为判断是否超时的标准,timeout值就是3,有的网站响应缓慢,可以设置timeout值为10秒。如例所示。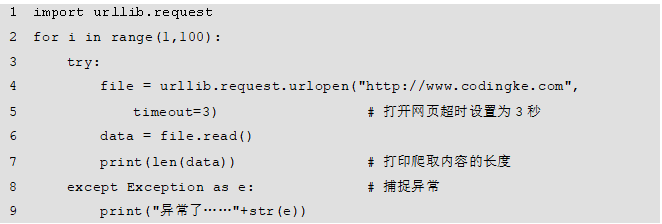
最后
以上就是满意丝袜最近收集整理的关于第三章 3.1 Urlib库的全部内容,更多相关第三章内容请搜索靠谱客的其他文章。








发表评论 取消回复