声明:本文来自于微信公众号锌财经(ID:xincaijing),作者:孙鹏越,授权热心网友转载发布。
360创始人周鸿祎,涉及“AI盗图”风波,最终上演了大结局。
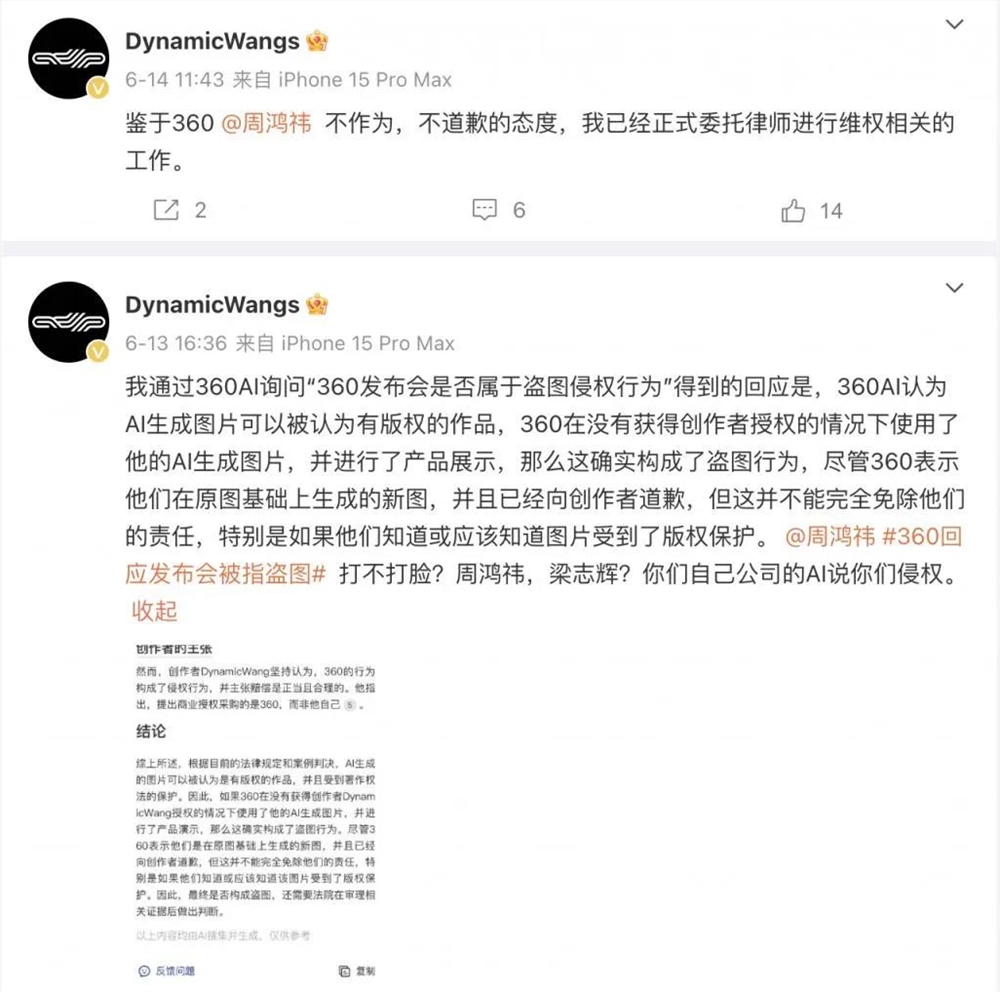
就在上周五,网络创作者DynamicWang在社交媒体控诉,360公司和周鸿祎本人对侵权时间不作为,于是委托律师进行维权相关的工作。
DynamicWang微博
在AI版权问题上,不少知名AI公司都曾经引发过侵权风波,就连头部公司OpenAI和微软,也曾被纽约时报一纸诉讼送上被告席,要求数十亿美元的赔偿。
只能说,周鸿祎犯了个所有大厂都会犯的错误。
版权问题的“罗生门”
这起AI侵权风波,是个巨大的罗生门。
在6月6日,360举办AI新品发布会暨开发者沟通会,周鸿祎演示了360AI浏览器的“局部重绘”功能,用“性感”作为关键词,生成了一张女性古装写真图片。
创作者DynamicWangs在社交网络上表示,360在该场AI新品发布会上使用的图片,正是盗用其本人创作的文生图。

左:360发布会使用的图片 右:DynamicWangs的模型生成图片
360公司在第一时间与DynamicWangs进行联系,但双方沟通后,协商宣布破裂,双方各执一词。
360副总裁梁志辉回应称:“我们曾试图沟通协商,但作者表示,希望我们10倍价格购买模型,并另行支付赔偿费用。这个方案超出了我们认知的合理范畴,我们愿意诉诸法律,在法庭上公开探讨版权问题。”
DynamicWang则斥责梁志辉言论前后不一,表示是360方先提出商业授权采购,后面又偷换概念,贼喊捉贼。
最终两者谈崩,相约法庭。
在AIGC的时代,输入几个关键词,再选择风格与视角,AI就能自动生成美轮美奂的画作。看似方便了,但大模型背后的版权问题一直是灰色区域,也没有相关的法律政策明确设计归属权。
AI侵权并不是只有孤例,甚至已经成为AI大模型的“通病”。
上一个坐在被告席的,正是国内另一互联网大厂,小红书。
据了解,小红书于今年3月开始筹备独立的大模型团队,4月推出了AI创作应用“Trik”,该应用声称能将用户上传的任意照片或图片一键转化为艺术画作。
羊城晚报报道,Trik在未标注画师署名、未获得画师授权的情况下,疑似使用了画师的原图生成大量AI图片,这些图片在色调、笔触、构图等方面与原图极为相似。
于是在2023年11月,四位绘画创作者将小红书的主体公司告上法庭,此案亦被普遍认为是AI大模型首次在国内站上被告席。
难道所有的创作者,都只能任由AI来“割韭菜”?白嫖自家的创意吗?
其实并不是,在小红书之前,中国首例AI生成图片著作权侵权案,已经在2024年1月宣判。
原告李昀锴起诉Stable Diffusion模型侵权案件已经胜诉,法院最终判决被告在判决生效之日起七日内,在涉案百家号上发布声明向原告李昀锴赔礼道歉,并赔偿李昀锴经济损失500元。
作为中国首例AI生成图片著作权侵权案,意义深远,甚至还入选了2023年中国法治实施十大事件。
相信这次“AI侵权案件”的判决,也给众多文生图大模型敲响了警钟。
国外大模型官司不断
如果说国内的AI版权问题还处于萌芽阶段,那么国外大模型早已经过上了“官司不断”的日子。
AI领头羊OpenAI不满足对普通人下手,开始盯上了电影大制作。
今年年初,OpenAI旗下知名文生图Midjourney迎来了V6版本的更新,通过光影、纹理等细节的升级,让生成的图片极其逼真,彻底告别“六个手指的人”等系统缺陷。
但是Midjourney生成的图片,居然和电影的画面非常相似。不但涉及到《复仇者联盟》《小丑》等多部好莱坞大片,甚至动画、商标都高度雷同。

左:电影原图 右:Midjourney文生图
面对众多用户的不满,OpenAI不但没有道歉,反而还玩了波骚操作:自己偷偷更改了服务条款。
据了解,Midjourney原本的服务条款并没有涉及到知识版权问题,十分潦草,更改后直接写明:“Midjourney不保证服务生成的作品不存在侵犯他人权利的情形,而Midjourney生成作品的过程中有可能使用了未经授权的由他人享有著作权的作品,所以不能排除生成作品侵犯他人著作权的可能性。”
同时,还特别注明了:“因用户协议已明确约定所有法律责任由用户自行承担,所以在使用AI生成作品时要注意防范可能的著作权侵权风险。”
言下之意就是,我可能会使用了未经授权的他人作品,但所有法律责任都由用户自行承担。
这份傲慢之极的服务条款引发了用户们的集体抗议,有1.6万名英国艺术家联名,计划对Midjourney和其他人工智能公司发起集体诉讼。
《纽约时报》也向纽约联邦地方法院起诉OpenAI和微软,指控这两家公司未经许可使用其数百万篇文章用于训练GPT模型,要求承担数十亿美元的法定和实际损害赔偿,并销毁所有包含NYT版权材料的模型和训练数据。

左:GPT-4生成文章 右:纽约时报原文
除了OpenAI和微软之外,谷歌、Mata等科技巨头都收到过涉嫌侵犯版权的诉讼,几乎波及到99%的AI公司。
为了处理AI侵权问题,OpenAI们一般会用“合理使用”“避风港规则”两条法律条款来反驳上诉。
“合理使用”是美国对版权法的一种宽松处理,对于一些特殊的场景给予使用版权的权利,例如批判、新闻报道、教育、学术研究等。
“避风港规则”也就是“通知-删除”规则,只要OpenAI们在服务条款告知用户,之后再删除用户侵权内容,就可以免责。
不得不说,在寻求法律灰色地带这方面,还是美国互联网公司更有经验一些。
需要学习的AI大模型
AI搜索引擎创企Perplexity CEO表示:“任何人都可以免费抓取网络上的内容,这属于合理使用。”
虽然侵犯知识版权问题非常严肃,但是对于AI大模型来说,优秀的文字作品和图片作品,同样也是它的养分。
AI大模型本身需要大量文本素材训练,那么在网络上抓取内容时候,它可分辨不出来是正版还是盗版,也不懂得人类世界的版权问题,统一都被它当做食物抓取。
所以,AI版权归根究底,并不是AI大模型的错,而是它背后的管理者失职。
ChatGPT需要训练,那么OpenAI就应该规范化它抓取的内容,用符合人类社会的法律法规,来约束AI。
如果出现类似的AI盗图事件,那就是大模型公司们该承担的责任、履行的义务并没有做到位。
同时,关于AI著作权的法律法规也在逐渐落。
2023年8月15日,《生成式人工智能服务管理暂行办法》实施,明确了服务提供者的活动规范和法律责任;10月,《生成式人工智能服务安全基本要求(征求意见稿)》发布,为AI发展提供了安全指导。
随着陆续几例AI侵权案件的审判,对于AI大模型未经授权使用创作人作品的行为是否构成侵权,在司法实践中逐渐有了方向。
相信在不远的未来,对AI大模型的规范化使用,对创作者知识产权的保护,会有更加明确的规定。
类似周鸿祎和DynamicWang的罗生门事件,会越来越少。
(举报)








发表评论取消回复