声明:本文来自于微信公众号 头号AI玩家(ID:AIGCplayer),作者:阿虎,授权热心网友转载发布。
这届年轻人越来越喜欢跟AI做搭子。
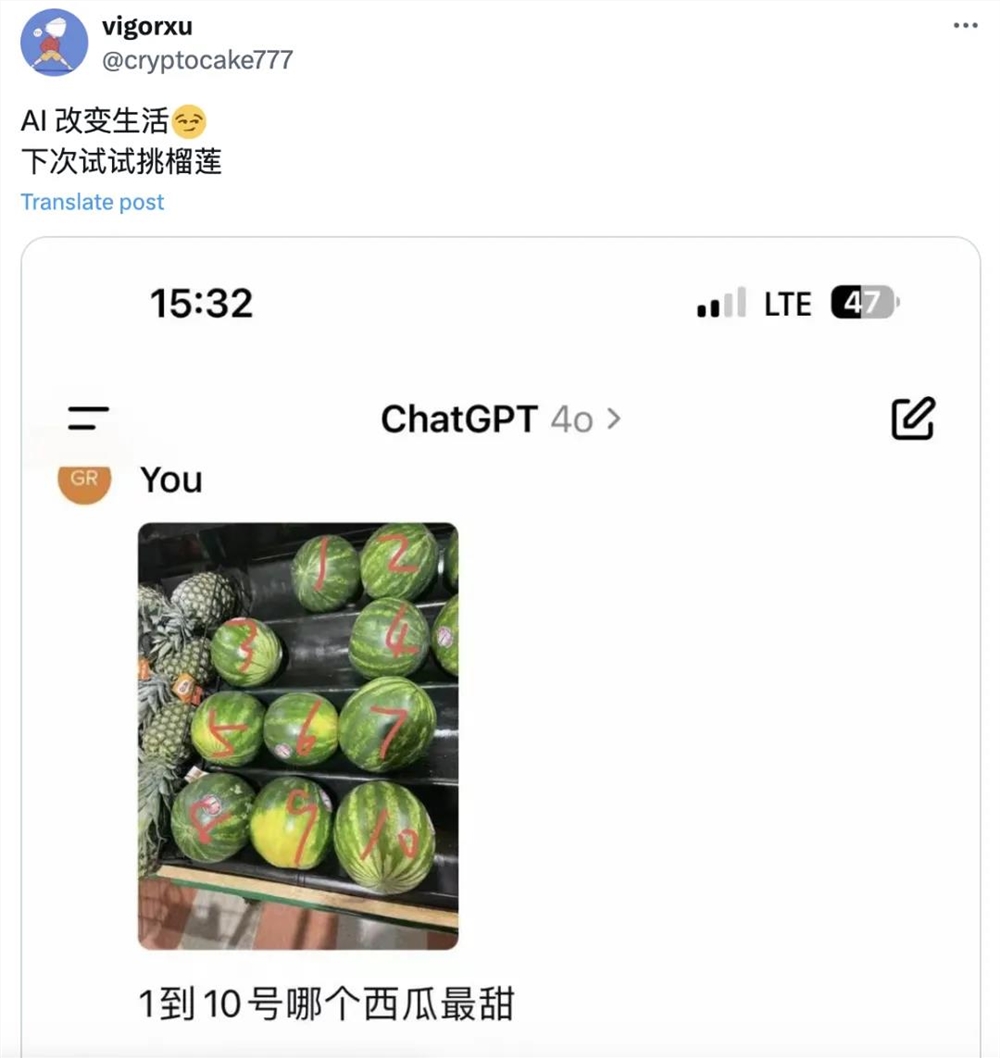
比如跟AI做生活搭子,让它帮自己挑水果,X平台网友“Cydiar”前不久发文,说自己用GPT-4o选出了水果店里薄皮沙瓤的一个甜西瓜。

对此,有超70万网友在线围观,还有不少人在评论区用AI选起了各种水果。
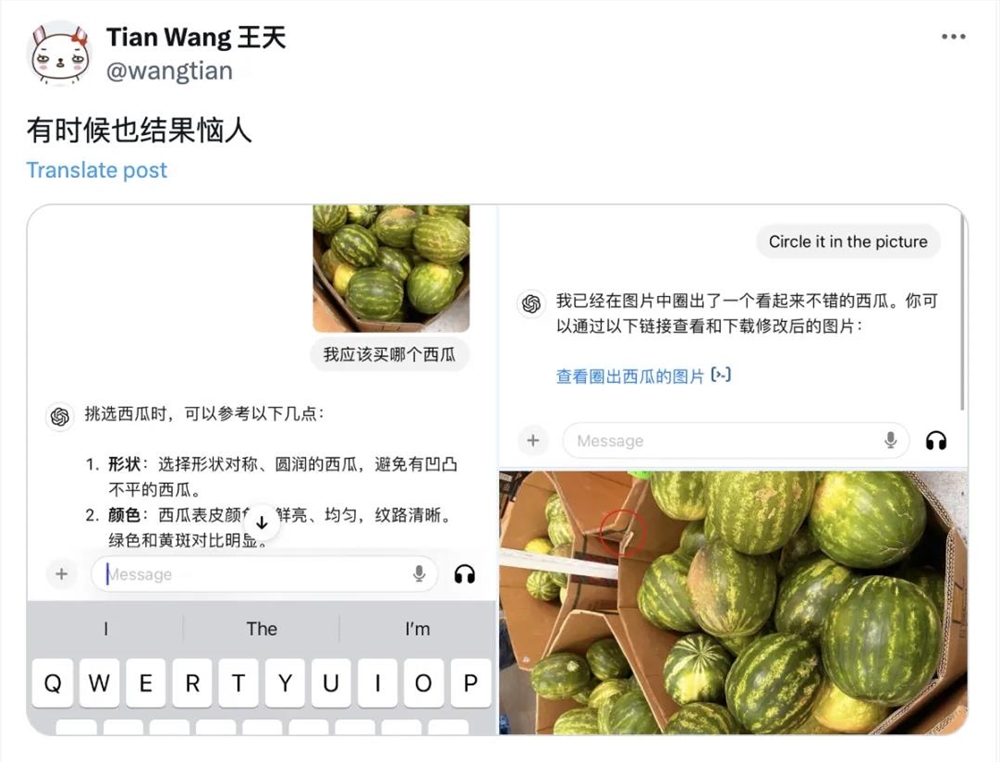
除了让AI挑西瓜,挑榴莲也是网友们热衷于让AI完成的任务。
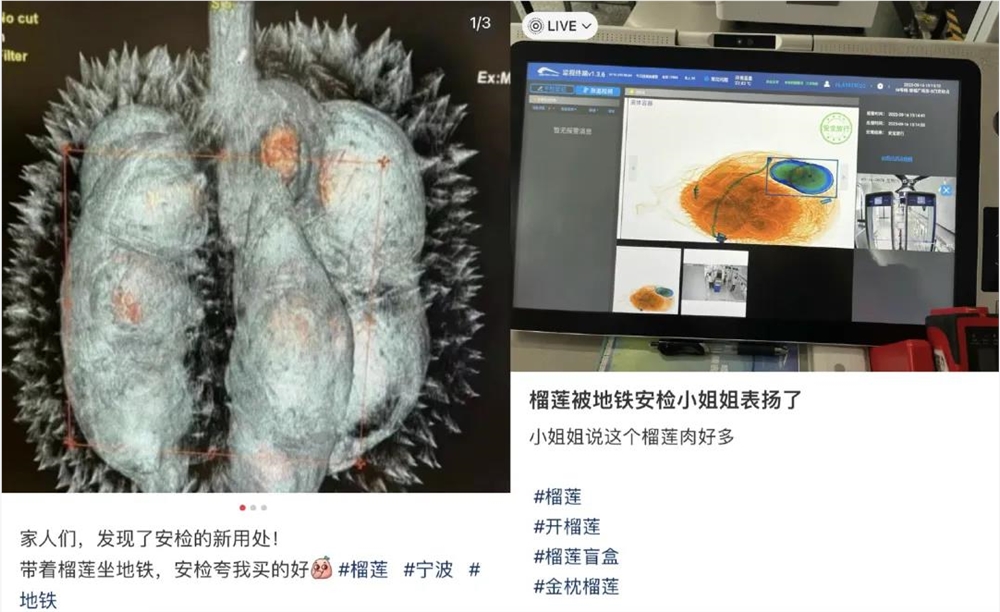
毕竟,“开榴莲”是近来较为流行的“赌石生意”,此前还有网友拿着榴莲照CT,带榴莲过地铁安检等等,就是为了验证他们的果房多不多。
比如即刻网友“AIchain花生”带着GPT-4o买榴莲,宣称成功避坑了一个烂榴莲。
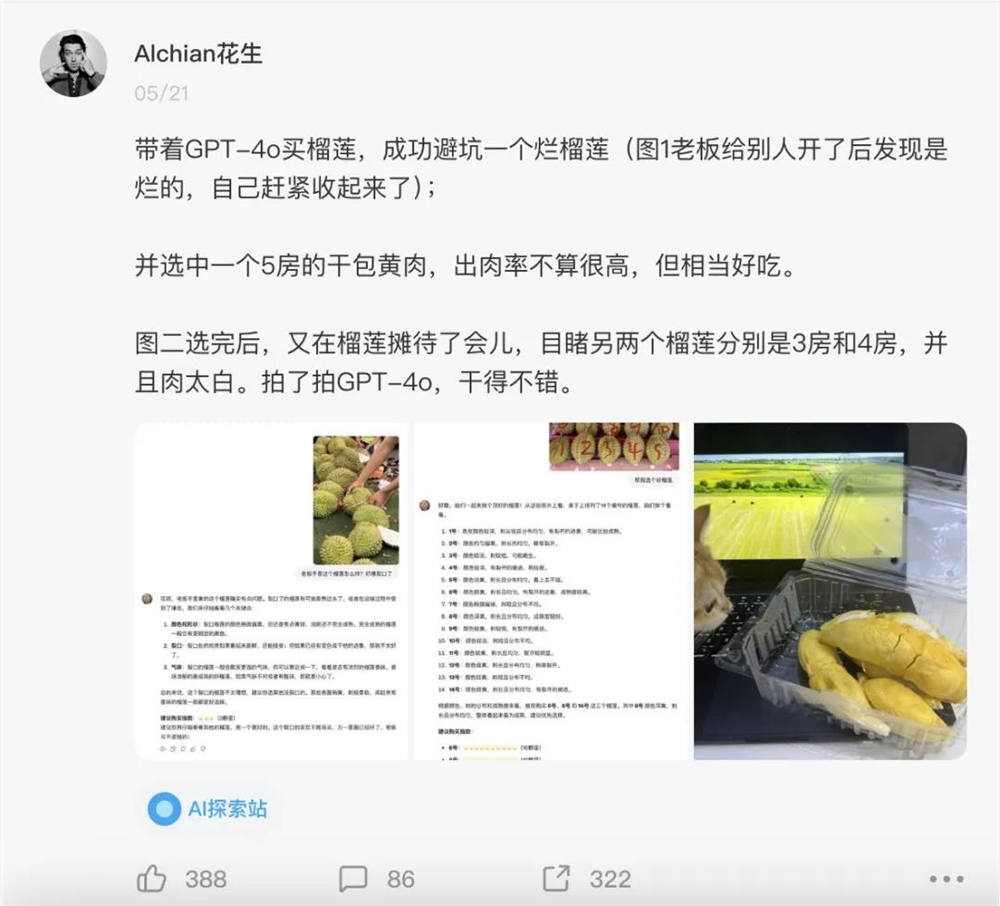
他还上手训练了一个GPT“这瓜保熟吗”,帮助大家挑选水果。
这个GPTs在选瓜的时候会详细描述特征,解释为什么该水果是最好的选择,并且以1-10颗星的方式呈现出购买推荐程度。
更关键的是,网友们用AI选出的水果品质都还不错。
让AI搭子挑水果还只是小意思,如今广大网友生活中的方方面面,都开始有了AI的身影。
此前有网友让GPT-4o做微表情观察专家,让通义千问评价工作餐属于什么水准,甚至生活中拍完的骨科片子也让AI给出意见。
这些场景下,AI又成了“互联网冲浪吃瓜搭子”、“工作用餐时的吃饭搭子”,以及“看病搭子”。
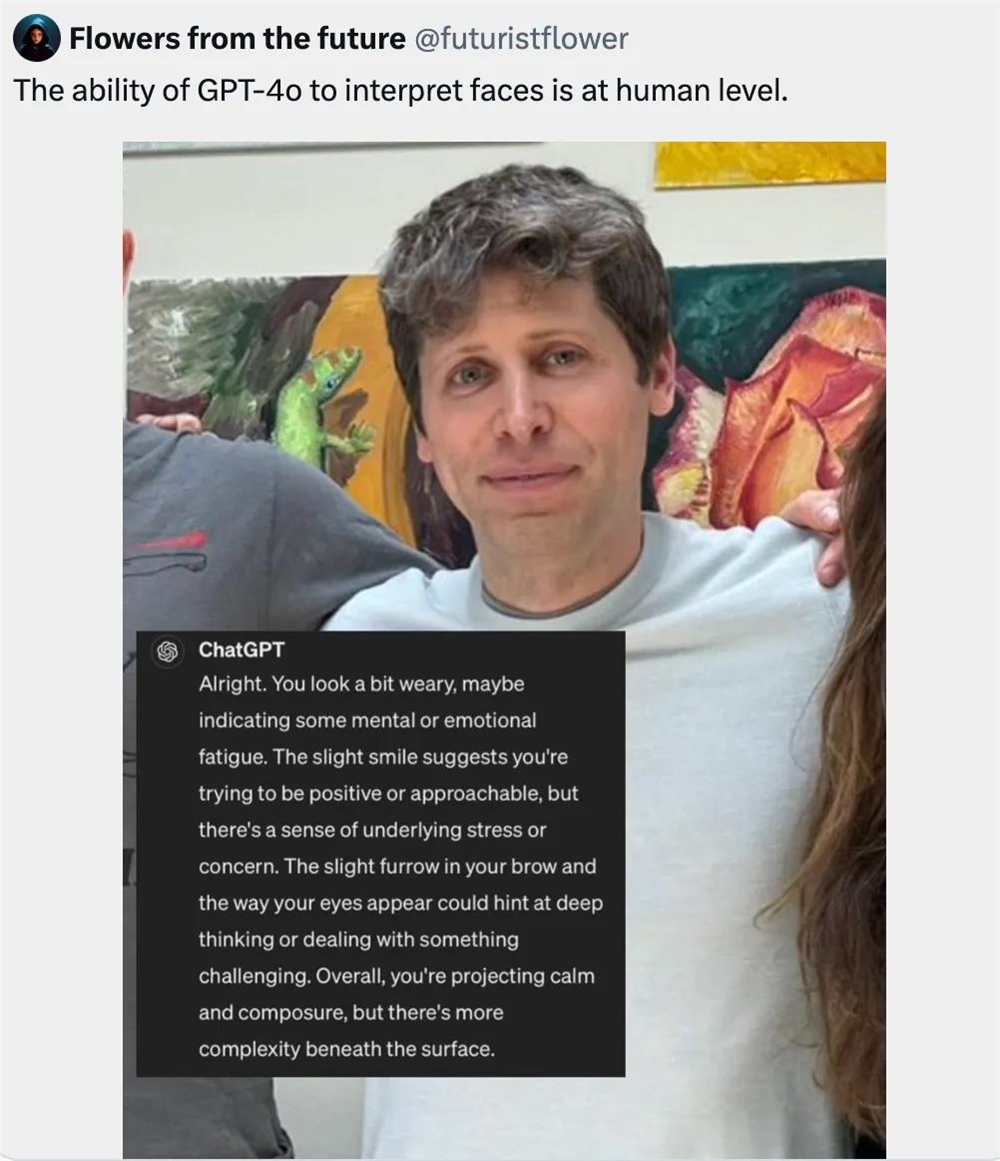
微表情识别专家

私人牙医
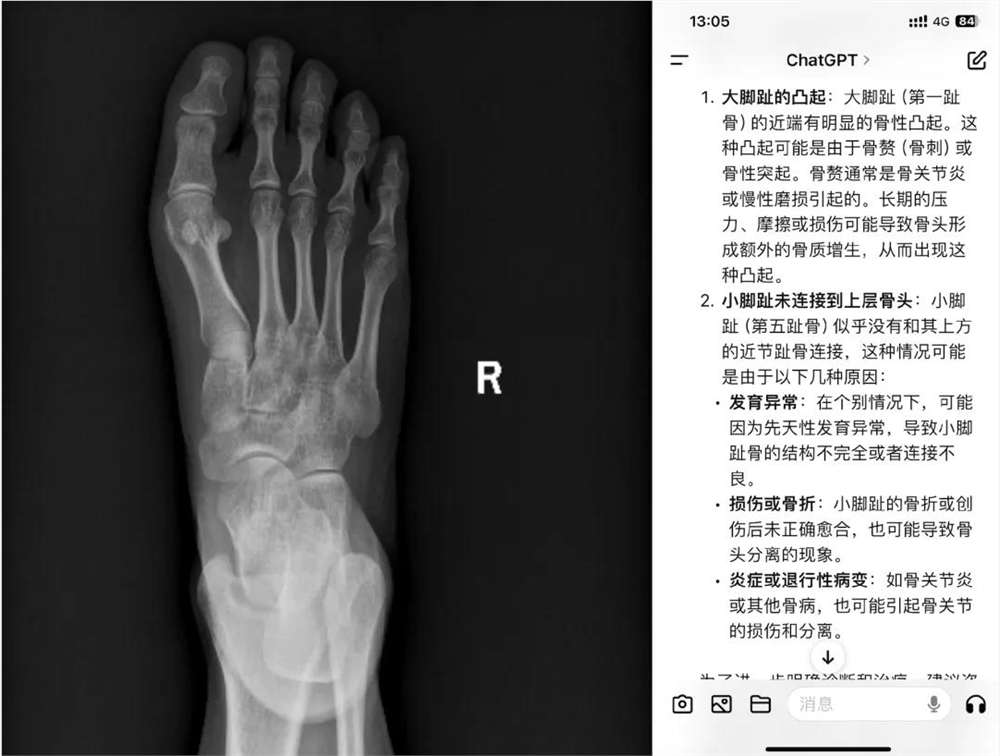
家庭医生
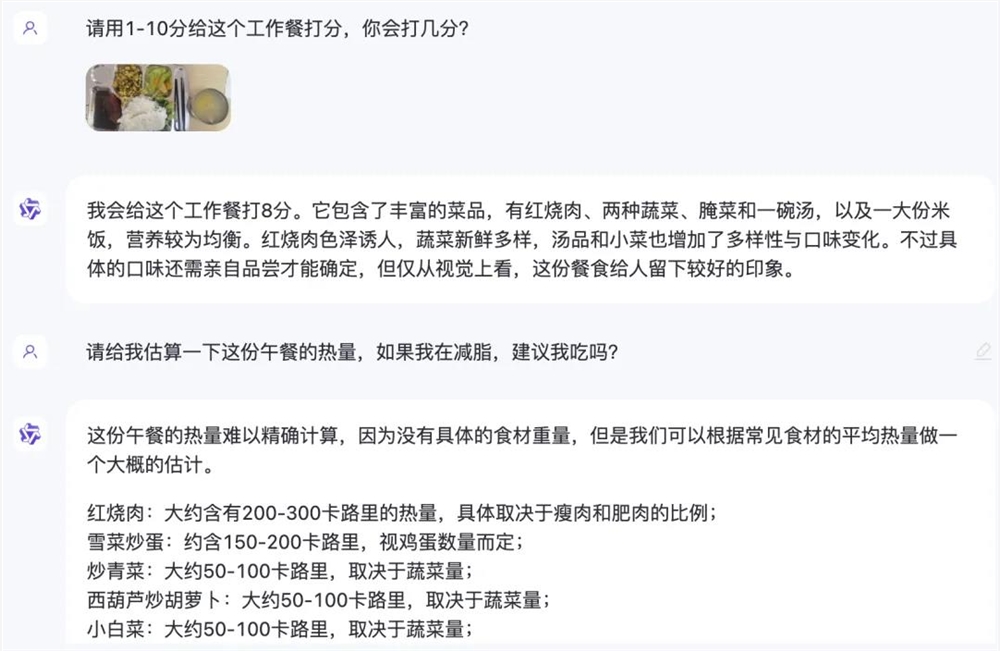
工作餐搭子
当然,这么多AI搭子里,最出圈的还是“恋爱搭子”——直接跟AI搞对象。
还有一些细思极恐的案例。
此前,YouTube博主和AI工具“GeoSpy”进行了一次照片拍摄定位比赛,参赛的AI不仅能快速定位到照片拍摄背景,还精准到具体经纬度。
这AI,让人一时间分不清是地理老师还是犯罪分子。
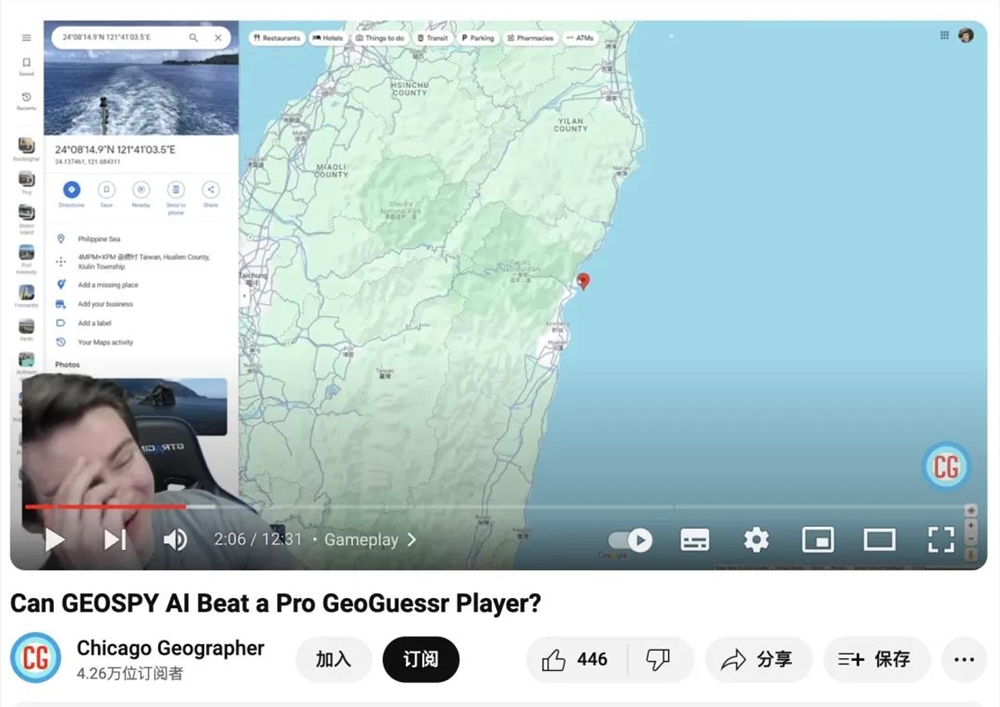
以前总觉得大模型技术离普通人很远,但如今,AI已经在为生活的方方面面提供技术支持,在不同的场景中提供意见与陪伴。
6月16日,加州大学最新研究显示,GPT-4已经通过了图灵测试,它在一半以上(约54%)的时间里被误认为是人类,GPT-3.5则是在50%的时间里被误认为是人类。
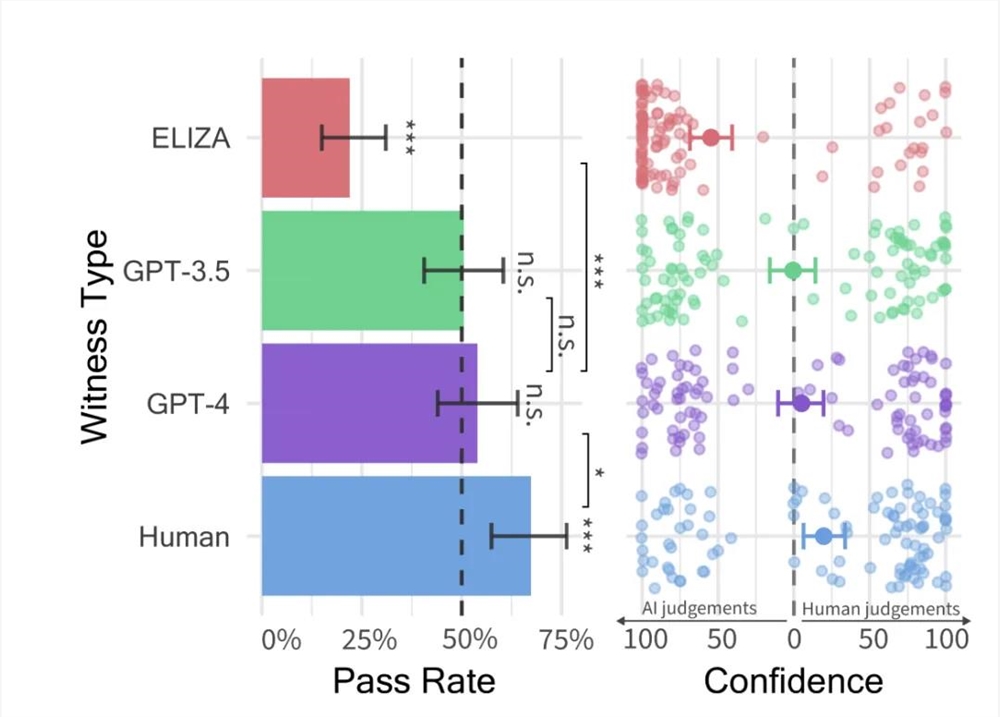
https://arxiv.org/abs/2405.08007
这意味着,在语言交流能力上,我们和AI之间的区分越来越模糊,人类朋友能够完成的事,找AI搭子也可以做到。
上个月,谷歌推出了最新的AI模型Gemini1.5,腾讯发布最新AI应用“元宝”,阿里云正式发布通义千问2.5。
这些模型不仅更新了处理文本的能力,还在多模态能力上进一步提升,能够更好识别并理解图片内容。上面的大部分案例,都是网友们借助AI的多模态能力,整出了各种花活。
那么,在视觉识别、任务理解等能力上,AI究竟能够达到什么样的水平?我们距离和AI一起“看”世界,还有多远?
围绕这个问题,“头号AI玩家”试了试当在生活中遇到各种问题时,能否都让AI们替我们决定,并给出相应的建议。
同时,本文也对实力王者GPT-4o、老牌选手Gemini、热门玩家腾讯元宝、开源霸主通义千问的视觉能力进行了一番测评,看看哪位“AI搭子”表现更好。
找AI做“挑水果搭子”,各家眼光出奇一致
首先,我火速前往一家水果摊,决定从最近流行的“AI挑报恩水果”开始尝试,看看究竟是噱头还是真像那么一回事儿。
要是真能选出最甜水果,以后岂不是在老妈面前横着走?(bushi)

各位玩家可以选一选你认为品质较好的榴莲
1、GPT-4o
我先将榴莲摊上的6个备选榴莲标上了序号,并发给了GPT-4o,让它从中挑选出果肉较多的一个榴莲。
GPT-4o认为,在这6个参赛榴莲中,品质最好的是1号榴莲,因为它的外形较大且圆润,颜色也较黄,看起来成熟度更高。

对于其他榴莲选手,GPT-4o也给出了相应的外观描述,编号5和6也是不错的选择,编号5体积较小,但刺不密集,可能会有惊喜。但综合来说,他更推荐1号。
在GPT-4o的推荐下,我选择了1号榴莲:

一打开这个榴莲,店员表示这是一个干巴款的榴莲,但果肉较为饱满,如果喜欢紧实口感的,1号榴莲就是个不错的选择。
总之,对于挑选小白来说,GPT-4o给出的榴莲意见,确实能提供参考方向。至少选的榴莲果肉丰满,气味浓郁,并没有踩雷。
2、Gemini
相比GPT-4o给出的意见,Gemini更希望我自行判断,他表示我提供的照片光线较暗,只有一个拍摄角度,无法判断出榴莲的完整性和成熟度。
他认为,1、2、3都是成熟款的榴莲,而6号榴莲可能还没熟透。另外,他表示如果我纠结的话,可以把6个都打开看看……

Gemini在挑选榴莲这件事上,更像是一个辅助的工具,需要人工告诉他更具体的细节,比如榴莲的尖刺形状什么样、颜色是什么,他才能给出更专业的判断。
虽然我尝试调整了几次提示词,比如“请从外观角度判断”“忽略榴莲完整性”等等,Gemini1.5pro都拒绝回答。
这一轮Gemini选榴莲,宣告失败。
3、通义千问
我同样测试了开源领域的最强霸主——通义千问2.5。
当我直接上传图片,让他从1-6号中选出一个果肉较多的榴莲,通义千问会回答自己无法直接判断榴莲的果肉量和口感,并给出一些挑选榴莲的建议。
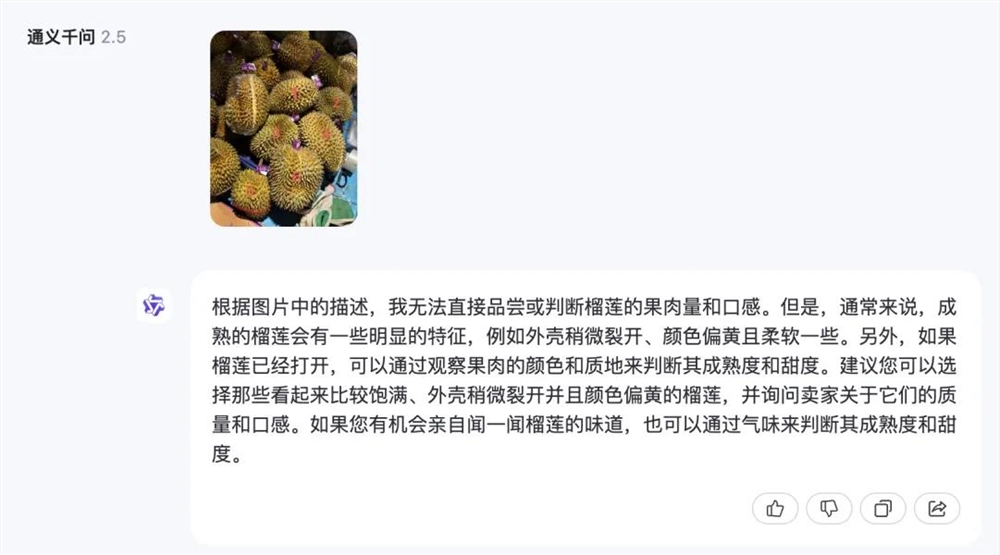
但当我提出“请从外观上看,帮我选出一个品质较好的榴莲”时,通义综合了颜色、刺的硬度、外壳是否裂开,同样选择了1号榴莲。

不得不说,AI大模型的“眼光”还是相当一致。
4、腾讯元宝
最近热度较高的元宝,给出的建议就很直接,一下子推荐了1、3、6号3个榴莲。
理由是这些榴莲看起来比较饱满,还圆滑地表示“这只是根据视觉判断的结果”,言外之意就是“看着都不错,好不好吃请别问我”。
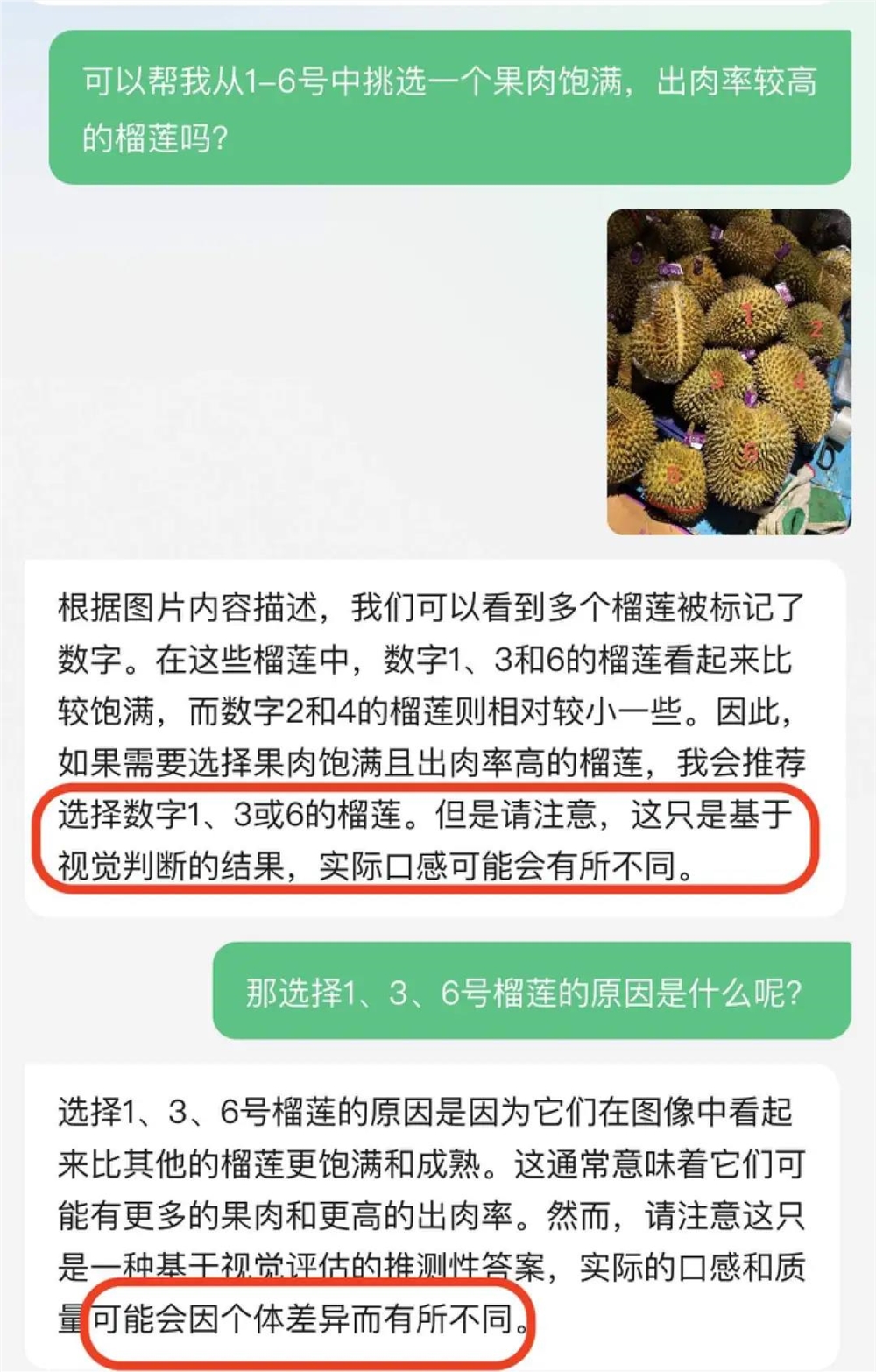
我进一步提问为什么看起来1、3、6更饱满成熟,元宝认为,它们外壳颜色较深,并且没有明显的裂纹。
相比其他大模型坚定选择1号,元宝还预判了顾客的喜好进行推荐。他认为如果看中果肉饱满,更推荐1、3、6号,如果看中出肉率,就要选择表皮较薄的榴莲,但需要顾客自行挑选,并未做进一步的推荐。
通过上述的榴莲挑选体验,我发现大多数AI大模型通常都是靠尖刺、外壳颜色和形状进行初步判断,而这些因素其实很依赖当时拍摄图片的场景和灯光。
所以,能不能挑到满意的榴莲,还是需要在现场根据气味、尖刺进一步判断。
AI给出的意见很大程度是踩中了“现阶段榴莲都不难吃”这一点。但如果真是个挑水果小白,AI分析水果外观这方面,还是提供了一些参考建议。

找AI做“科普搭子”,通义千问学会摆烂了
除了挑选水果之外,当触及知识盲区时,AI能够帮我们识别相关的内容吗?
比如,在地铁上遇到一些正反颠倒的外语文字:

1、GPT-4o
这张印有日文的图像,GPT-4o压根没有识别出文字颠倒了,开始编纂上面的日语是“厉害的、惊人的”的意思。

当我把图片翻转180度变正之后,它才回答出日语是“猫咪”的意思。

2、Gemini
Gemini虽然对文字的识别还不够准确,但也能够通过图片猜测出这是一个黑色毛绒玩具的一部分。

遗憾的是,通义千问和元宝都没有办法识别出这些文字的意思,通义千问甚至开始说自己还没有识别文字的能力,直接摆烂。

可见,现阶段的AI识别任意字符,依旧需要我们提供正确的文字样式,经过颠倒、翻转或镜像的图片,AI都没法辨认。

找AI做“看展搭子”,GPT-4o和元宝略胜一筹
如果和AI进行一场“看展式社交”,一起逛博物馆,是不是能学到新知识?
我们让AI“品鉴”了一下中国古代艺术《千里江山图》局部图,并问他们“这幅画是什么意思”。

GPT-4o和元宝在两次提问后,能够知道这是《千里江山图》的局部图,并详细阐述了这幅山水画的意境。而Gemini和通义千问都无法认出具体是哪一副传统山水画,GPT-4o和腾讯元宝略胜一筹。
这么看来,邀请GPT-4o和元宝做博物馆搭子,会是不错的选择。

左边为GPT-4o回答;右边为Gemini1.5pro

找AI做“吃瓜搭子”,玩梗能力堪忧
挑水果、逛博物馆、识别陌生文字,只是AI图像识别中的部分用例。接下来,我们来看看AI能不能和我一起冲浪第一线吃瓜。
比如,最近火爆AI视频生成领域的梗图,让Runway转头就更新了Gen3模型,我们来看看AI会如何解读:

1、GPT-4o

GPT-4o真的就把图片原原本本翻译了一遍,并没有完全指出“由于Luma AI视频生成工具的火爆,人们早把Runway丢在一边了”等类似的内涵。
2、Gemini


除了最后总结上提到“人们对Sora的期待”有错误之外,Gemini至少可以识别出90%的梗图内在含义,还能看懂Sora代表的小孩脸上有不知所措的表情。
3、通义千问
可能是因为这张图有骷髅,所以通义千问让我换张图试一试,和AI一同吃瓜也要注意内容红线,通义的安全意识远高于其他模型。
4、腾讯元宝:

元宝至少看懂了这张图的内容,但并没有指出其中的玩味含义,回答还有些一本正经。
总的来说,Gemini看梗图的能力略强于其他几家,起码了解这是一张meme图,也能明白其中的幽默意味,但没有一家AI能和我一起调侃“6月更新的AI视频工具也太多了”,你们好歹都是大语言模型啊。
找AI做“娱乐搭子”,眼神大都比我好
面对互联网上层出不穷的娱乐向测试,我们接下去看看AI会如何应对,比如一些经典的视觉错觉图。
请各位玩家先判断一下,A和B色块颜色相同吗?

1、GPT-4o
GPT-4o不仅说出了正确答案,还告诉我这是一个知名的视觉错觉实验,并附上了具体的识别方法。

当我们进一步让它证明并画出A和B是相同色块,它还给出了取色图像和一段Python代码,帮助证明A和B是相同的颜色。

2、Gemini
Gemini也没有让人失望,除了准确说出A和B颜色相同之外,并解释了为什么大多数人会产生这种视觉错觉。

不过,当我们要求它能否画出来证明A和B颜色一致时,它表示需要用到图像编辑工具,没有办法直接输出一张新图片。

换言之,作为一个多模态模型,Gemini1.5pro目前还不能直接提供具体的图片示例,不具备多模态输出能力。
3、通义千问
通义千问同样识别出两个色块一致,还附上了更多识别方法和参考链接以证明色块的一致性。
值得一提的是,我们也要求通义千问能够画出来证明A和B是一样的色块,通义真的这么做了,但有些勉强:

我们压根无法分辨它一本正经强调“这两个色块一致”,究竟是自己出现的“大模型幻觉”还是真的受屏幕影响导致画面颜色不同。

可见,通义千问在理解多模态输入和输出方面都做了一定的努力,但图像输出的准确性需要进一步进行信息校准核验。
4、腾讯元宝
腾讯元宝的回答,让我看到了做视觉测验的我本人。


距离和AI一起“看”世界,还有多远?
除了对话沟通能力,这些能够读图的AI,似乎还有了“睁眼看世界”的能力。
无论是生活场景下挑水果,还是吃瓜读梗,GPT-4o、Gemini、通义和元宝都展现出了一定的图像分析能力,甚至在某些场景下,不仅能处理复杂的多模态输入输出,理解能力又更上一层。
OpenAI Sora及DALL·E团队负责人Aditya Ramesh最近提到,现阶段AI视觉的基础是对压缩图像的学习。模型会从原始图像中提取关键信息,并以一种压缩的形式来表示这些信息。
这个过程可以帮助模型识别图像中最重要的特征,忽略那些不那么重要的细节,从而提高识别图像中物体和场景的能力。他认为,能够模拟任何想要的内容将是未来的一个重要里程碑。
虽然AI在视觉理解方面已经取得了很大进展,但现有的多模态模型在识别图像上还不能做到百分百的精确。
正如我们让AI不断挑战图灵测试,或许在视觉识别领域也能看到它实现新的突破。至少目前,很多人类看不懂的知识,正在被AI以前所未有的方式重新解读。
当然,这只是选AI做搭子的部分实例,各位玩家会和AI一起做什么?欢迎在评论区分享你的故事~
(举报)








发表评论取消回复