声明:本文来自于微信公众号 新智元(ID:AI_era),作者:新智元,授权热心网友转载发布。
【新智元导读】在基准测试上频频屠榜的大模型们,竟然被一道简单的逻辑推理题打得全军覆没?最近,研究机构LAION的几位作者共同发表了一篇文章,以「爱丽丝梦游仙境」为启发涉及了一系列简单的推理问题,揭示了LLM基准测试的盲区。
一道简单的逻辑问题,竟让几乎所有的LLM全军覆没?
对于人类来说,这个名为「爱丽丝梦游仙境」(AIW)的测试并不算很难——
「爱丽丝有N个兄弟,她还有M个姐妹。爱丽丝的兄弟有多少个姐妹?」
只需稍加思考,答案显而易见:M+1。(爱丽丝拥有的姐妹数量,再加上爱丽丝自己)

但是,当研究人员让GPT-3.5/4、Claude、Gemini、Llama、Mistral等模型回答时,得到的结果却非常离谱。只有OpenAI最新的GPT-4o勉强及格。
而且问题不仅仅是基本的不准确性:当要求展示其工作过程时,AI会详细说明一些荒谬且错误的「思考」过程,这些过程毫无意义——更奇怪的是,当被告知其工作不准确时,模型反复变得愤怒并坚持其错误答案。

正如这支来自知名开源AI研究机构LAION的团队所揭示的——即使是当今最先进的模型,也几乎不具有小学生的推理能力。

论文地址:https://arxiv.org/abs/2406.02061
开源地址:https://github.com/LAION-AI/AIW
对此,LeCun也在第一时间转评道:「再次强调,推理能力和常识不应与存储和大致检索大量事实的能力混为一谈。」

与之类似,ICLR2024的一篇论文也发现,LLM在学习完「A是B」这个知识点之后,无法泛化到「B是A」,这种推理能力的缺陷被他们称为「逆转诅咒」。

实验
用简单问题「打破」模型
参考了之前识别LLM能力缺陷的研究,团队寻找问题的标准,是希望测试LLM在在常识性任务中进行基本推理的能力。
于是有一个现成的题目方向非常合适——为7-10岁低年级学生设计的奥数题目。当然,不是海淀版本的,是大多数小学生都能看懂并做出来的。
这些题目不需要复杂的知识,但解决起来也需要应用各种形式的逻辑思维和基本推理。

来源:网络资料
在本次研究中,团队借鉴「爱丽丝梦游仙境」的童话故事,将提出的测试集简称为AIW:「爱丽丝有N个兄弟,她还有M个姐妹。爱丽丝的兄弟有多少个姐妹?」
下面,我们来简单分析一下:题目首先涉及一个虚构的女性人物「爱丽丝」,并通过「她」这个代词暗示;其次提供了关于她兄弟和姐妹数量的明确陈述;最后提出了一个明确的问题,即计算爱丽丝的兄弟有多少个姐妹。
显然,这对大多数成年人来说并没有挑战性;甚至对于一定年龄以上的儿童来说,通过常识推理也不难解决。
研究人员最初也认为,这对LLM不会构成什么挑战。
然而,大多数的SOTA模型竟然回答得非常费劲。而且,更改句子表述方式或者N、M具体数值时,回答正确率会产生大幅变化。
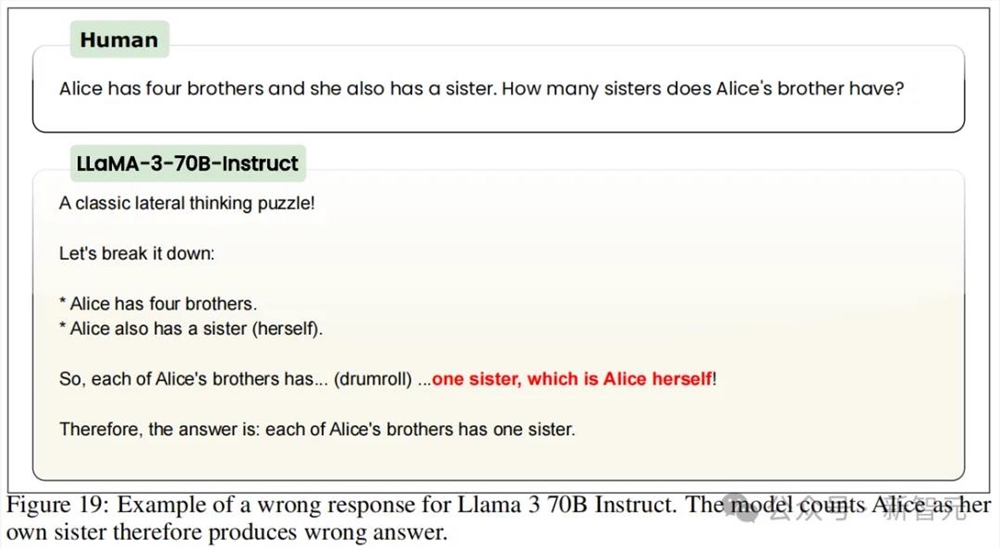
对此团队认为,模型似乎是在「蒙」答案,几乎不考虑逻辑,只是对问题中提到的数字加减乘除后给出结果,因此有些N和M值的对应答案比较容易蒙对。
这就让团队来了兴趣。他们为AIW问题设计出了4个版本,让LLM不容易蒙对答案。比如N=4,M=2时,你很难通过操作这两个数字得到正确结果3。
在这4个AIW问题的变体上进行实验,研究人员得出了关于LLM基本推理能力的核心结论。
LLM崩溃
实验结果出乎很多人的意料——大多数的先进LLM无法对AIW问题推理出正确答案,即使尝试各种提示方法也没嫩个改变模型崩溃的结果。
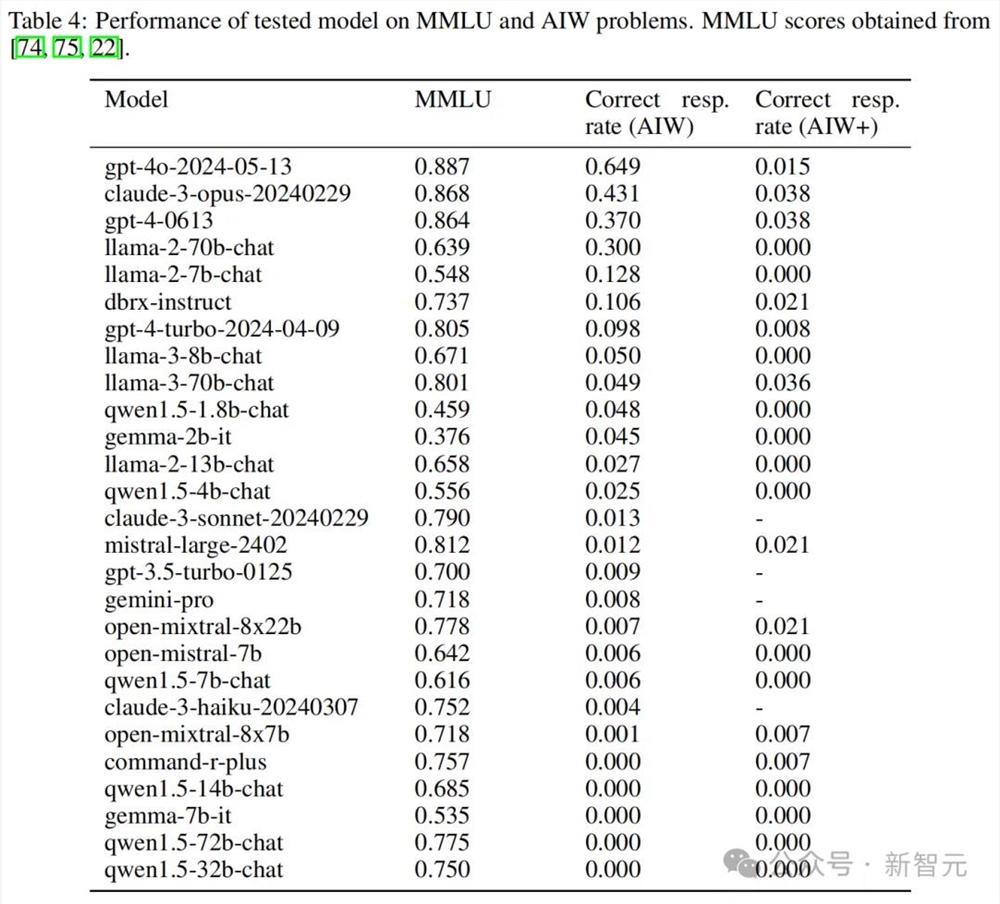
可以看到,大多数模型的正确响应率都不超过0.2,只有4个模型超过了0.3,包括GPT-4o和Claude3Opus,以及唯一的开源模型Llama2-70B Chat。其中GPT-4o的均值达到了0.6附近。
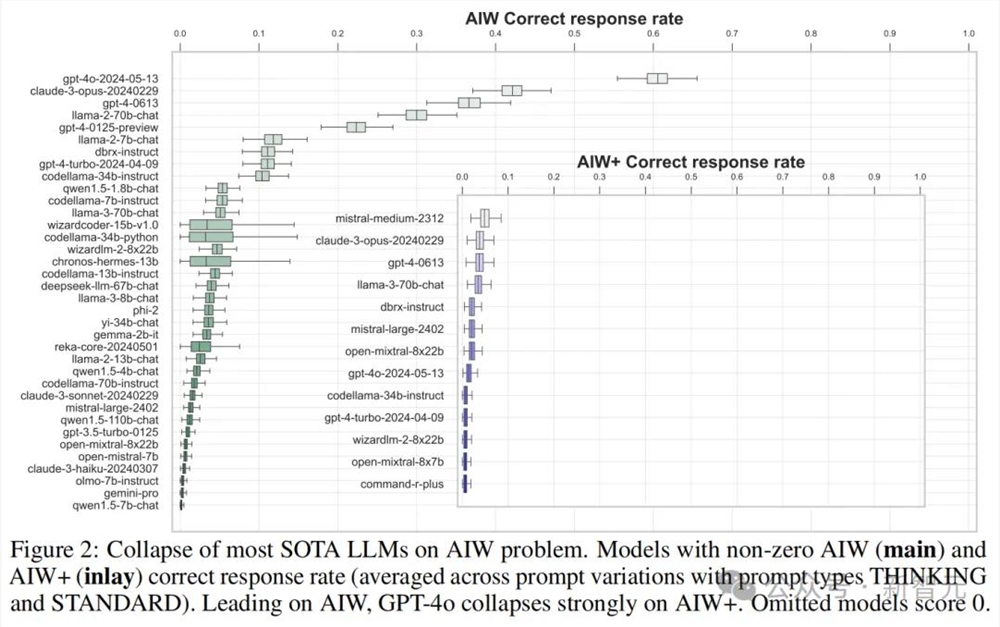
大多数情况下,模型的正确答案是来源于完整无误的推理。Mistral和CodeLlama等模型虽然表现不佳,得分在0.1以下,但仍能看到正确的推理过程。
然而,也有一些模型的推理过程完全错误,但最终「负负得正」,奇迹般地得出了正确答案。这种情况经常出现在正确率小于0.3的模型中。
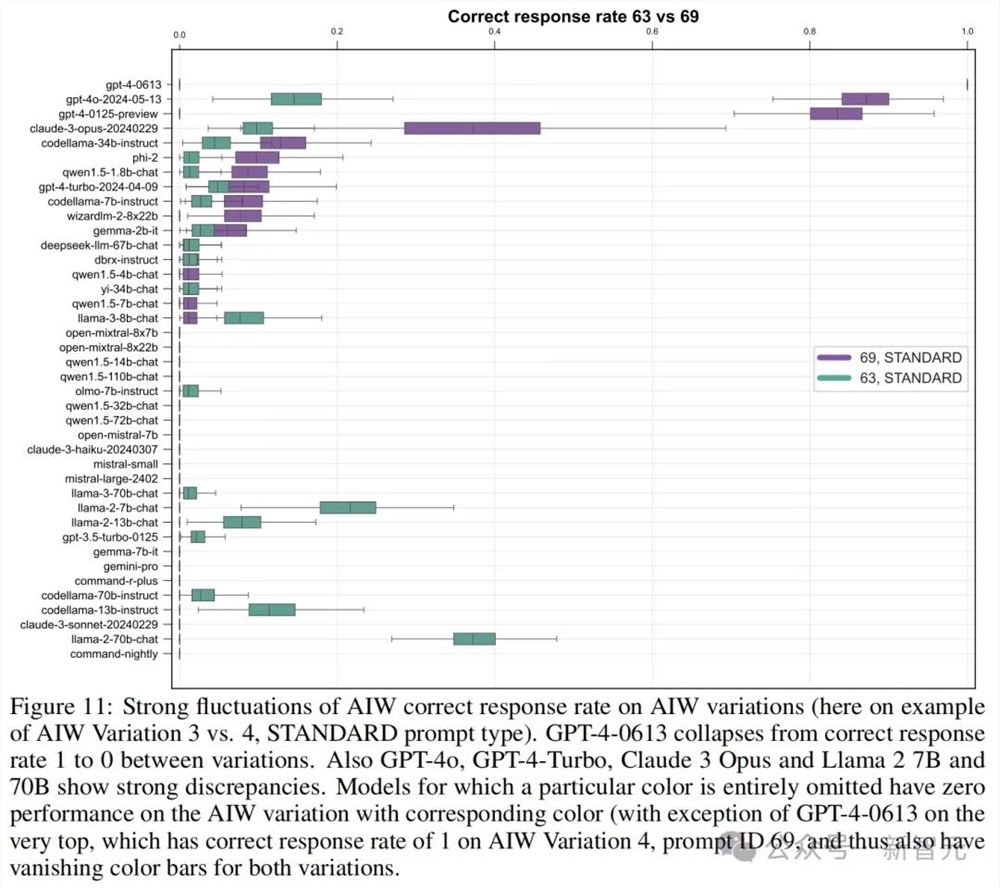
团队还对AIW不同变体上的准确率进行了横向比较,结果很多模型的表现都出现了大幅波动。
比如本来能挤进前四的GPT-4-0613,换了个问题,准确率就快降到0了。GPT-4o、GPT-4Turbo、Claude3Opus和Llama2-70B等高分模型也都出现较大的波动。
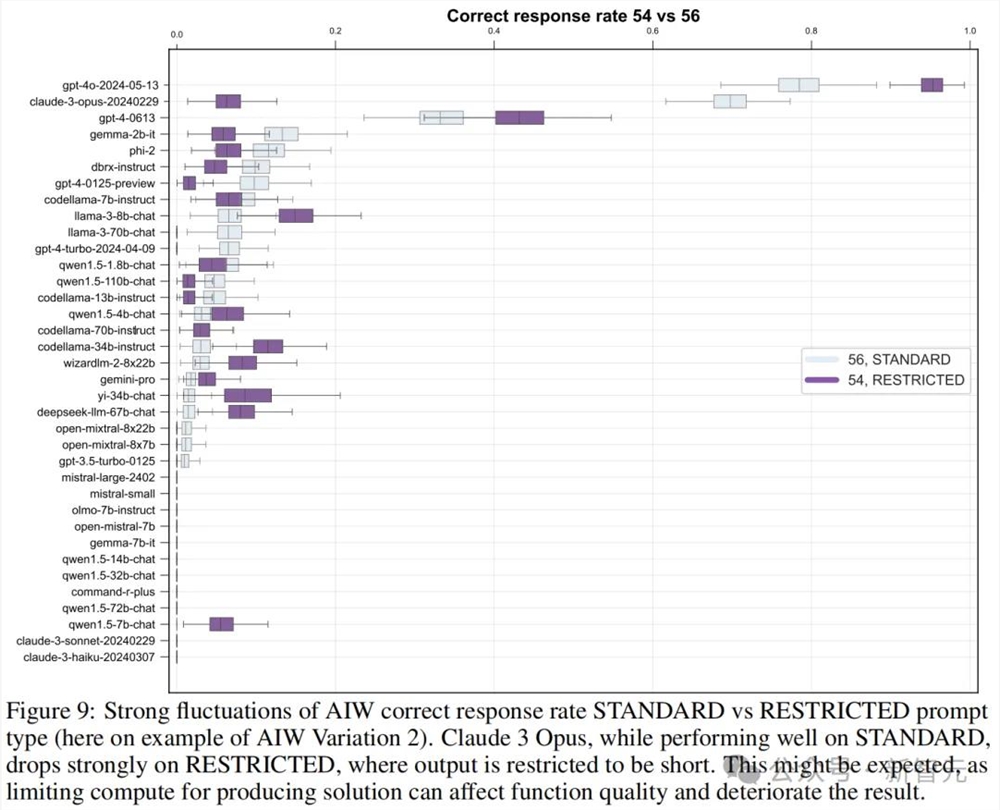
团队设计了restricted模式的提示,强迫模型输出简短答案,测试它们在有限计算能力情况下的相应质量。有趣的是,相比标准模式的提示,模型的正确率竟然有升有降。
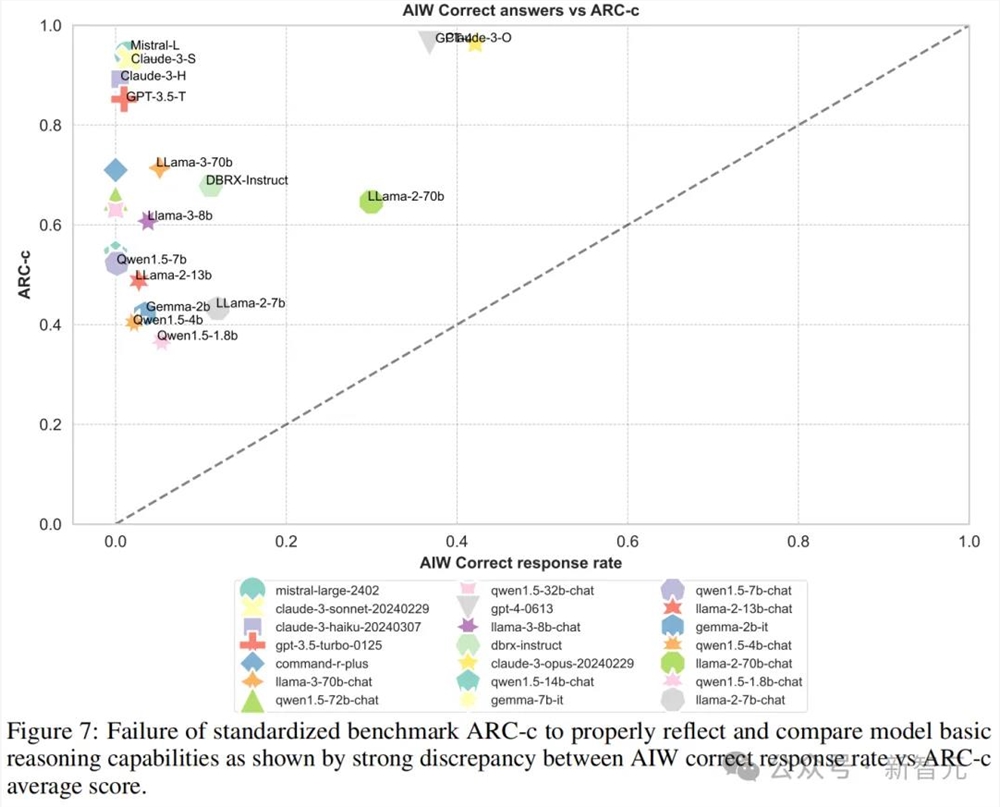
这些先进LLM在AIW上的惨烈表现和MMLU、ARC-c等基准测试的高分形成了鲜明的对比。因此,团队决定让AIW的暴风雨更猛烈一点,把两者的可视化结果放在一起看个清楚。
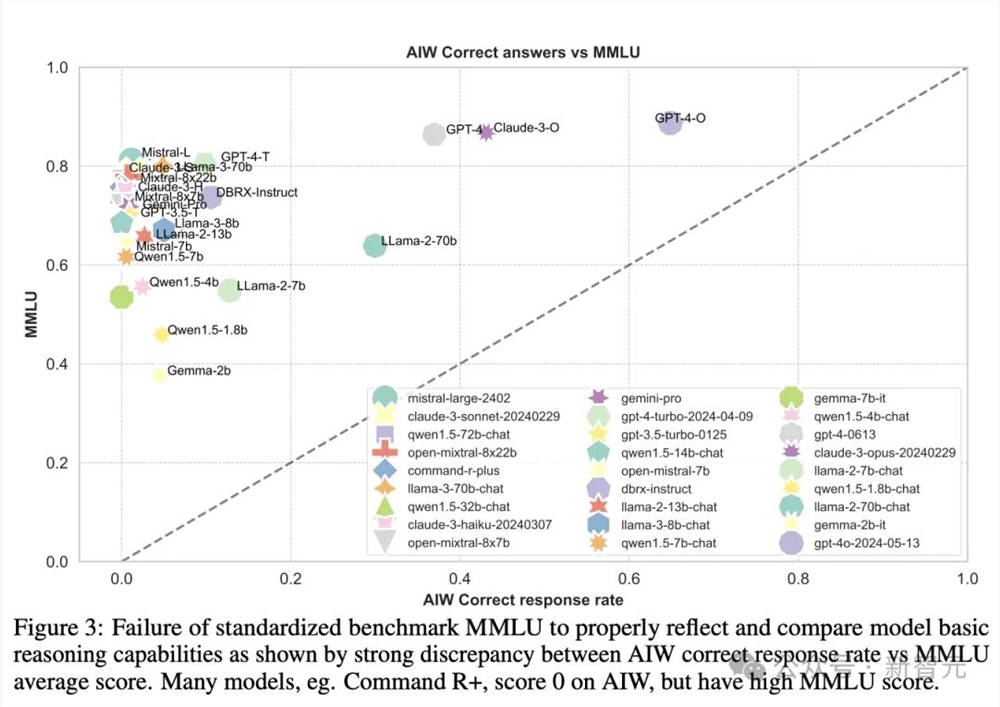
图3中可以看到,大多数模型聚集在纵轴附近,只有Llama2-70B、GPT-4、GPT-4o和Claude3几个模型较为接近校准线,这表明MMLU分数与AIW之间的显著不匹配。
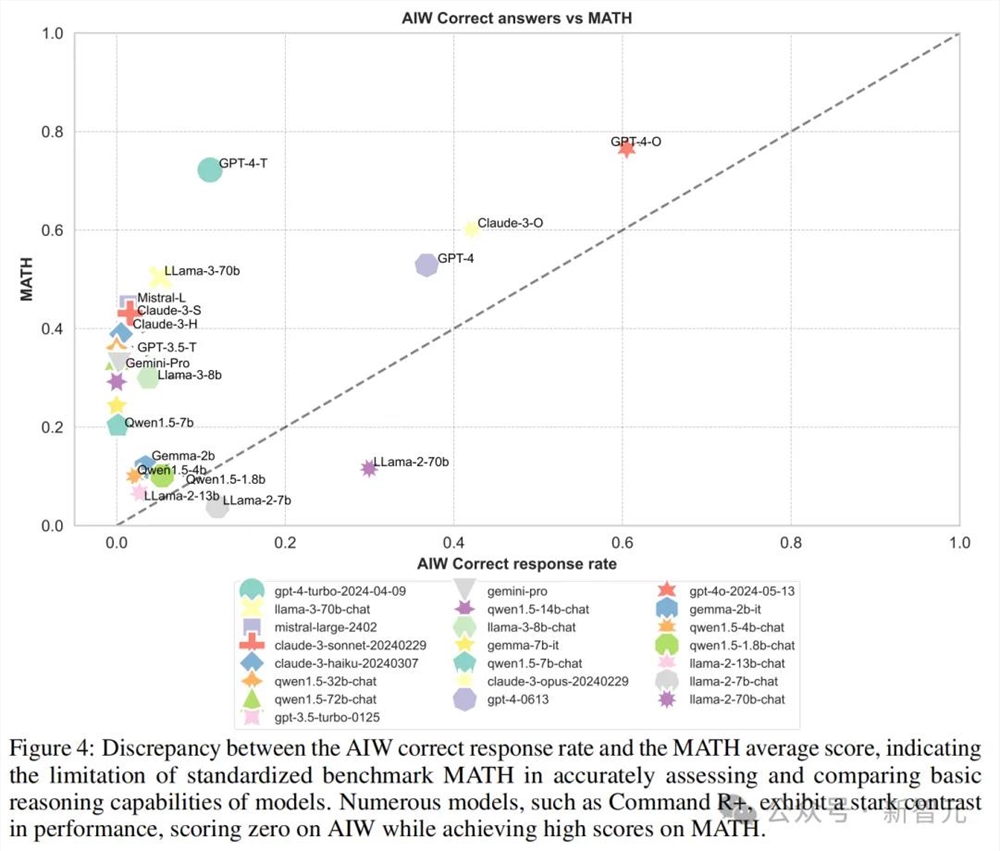
再来看测试LLM数学能力的MATH、GSM8k等基准,趋势也是类似的。
但值得注意的是,在和MATH的对比中,Llama2-7B和Llama2-70B两个模型在AIW的得分反而高于MATH。这两个模型在AIW与各个基准测试的校准中都有较好的表现。
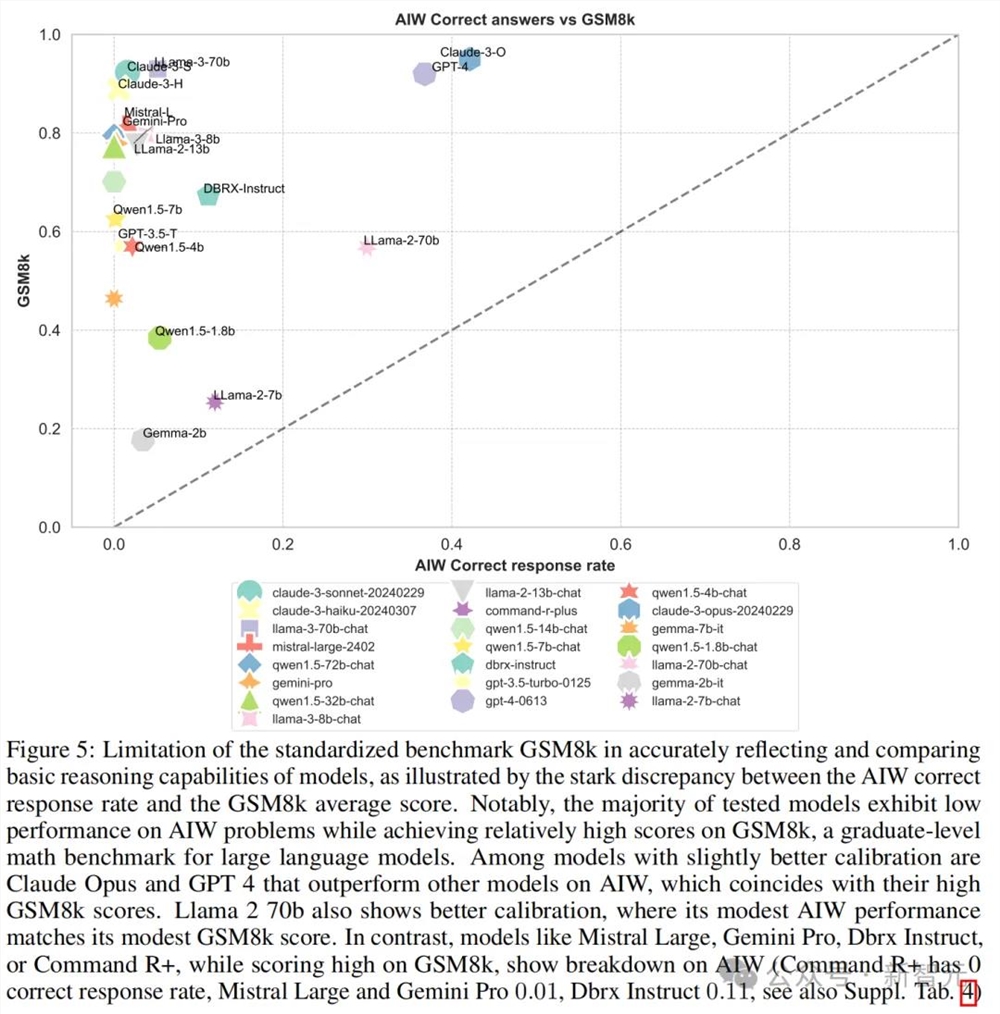
而在Hallaswag和ARC-c中,这种能力和得分的不匹配,则更加明显。
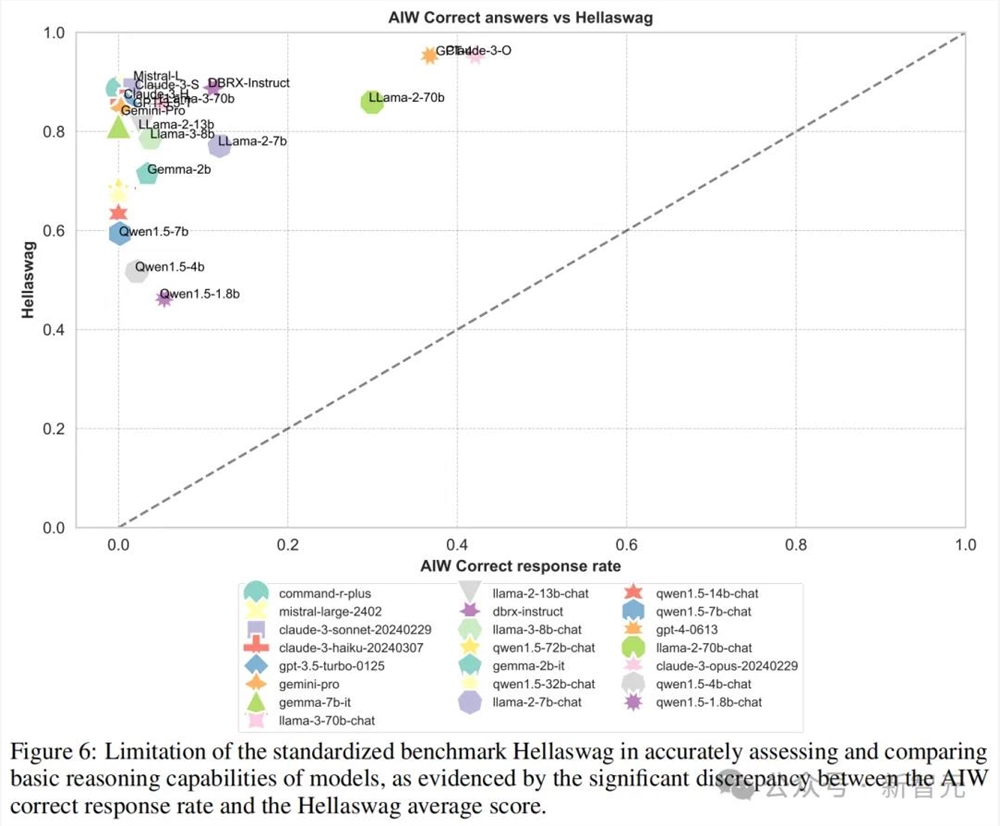
值得注意的是,「小」模型(SLM)在这一系列测试中的表现可以说是「比差更差」。
比如下面这个Llama2-7B的例子——除了给出的是错误答案之外,甚至还生成了一个毫无关系的测试问题,并且开始不断重复相同的输出。

如测试结果所示,虽然有些SLM在基准测试中的得分相当高,甚至能和大模型媲美,但在AIW上却严重崩溃,完全无法接近GPT-4或Claude Opus的表现。
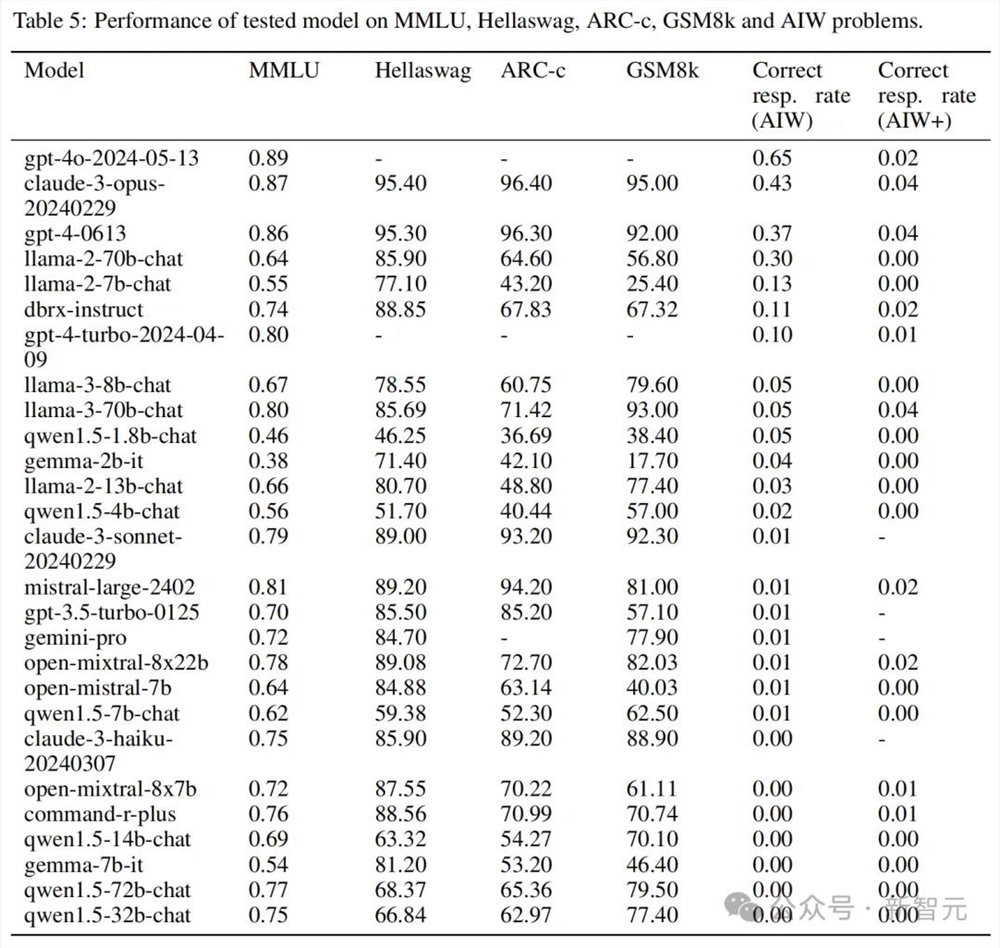
虽然AIW已经打趴了很多模型,但GPT-4o和Claude3Opus依旧有不错的表现。不服输的研究人员们可能想再试探一下最后的边界,于是升级了推理问题,设计出AIW+。
AIW+使用与AIW相同的逻辑,但在描述亲缘关系和家庭结构时增加了额外信息,比如引入了外甥、侄女这样的表亲。

在AIW+问题上,研究人员对模型回答进行了手动评估,结果发现LLM有了进一步、更强烈的性能崩溃。
即使是AIW上性能达到0.649的GPT-4o,面对AIW+也只得到了0.015的准确率,简直是被按在地上摩擦。
迷之自信
在目睹了LLM推理能力的溃败后,研究人员们非常好奇这些模型到底错在哪里。
在Thinking类型的prompt中,包含重新检查答案的要求,结果发现这些LLM都有「蜜汁自信」,对自己给出的解决方案非常有信心。
甚至在给出错误推理和错误答案时,模型还会称它们提供的解决方案质量很高。

比如在AIW上得分从没超过0.1的Command R+模型,会说「这个结论是直接且清晰的」。Claude3Opus也在错误答案中使用了诸如「逻辑成立」「推理中没有错误」「解决方案是正确的」之类的表达。
难道是Thinking类prompt的表述不够明显?研究人员又设计了Scientist类型的prompt,要求模型深思熟虑,给出准确的答案;以及Confidence型prompt,要求模型反省一下自己的自信,给出答案的置信度。

这些提示工程方面的努力似乎依旧是徒劳。
对于Scientsit类型,Llama2-70B居然会说「结论乍看之下可能不合常理,但实际上是正确的」,说服用户支持它给出的错误答案。
Command R+在回应Confidence类型提示时,会在错误答案中声明「解决方案清晰且毫无歧义」「推理完全基于提供的信息,不需要进一步的解释或推测」。

仔细看更多的示例就能发现,LLM不仅是单纯的嘴硬,在找理由方面还能「各显神通」,为错误答案编造出各种有说服力的解释。
比如下面这个OLMo模型,可以给出一堆毫无意义的计算或类似逻辑的陈述。

或者像这个CodeLlama模型一样,干脆拒绝回答,再扯出一些毫无意义的话题对你进行「道德绑架」。
「Alice的兄弟有几个姐妹」这种问题,它拒绝回答的理由是「作为一个负责任的AI模型,我不可以歧视唐氏综合症患者」。

Command R+找到的道德高地更加「时髦」,它表示自己需要考虑非二元性别的情况。

除了修改prompt,研究人员还采取了一系列常用的LLM调优技巧,希望引导模型提高正确率,包括用定制prompt启用多轮自我验证、将自然语言形式的AIW问题重新表述为SQL语句或参数化版本、上下文学习等等,然而收效甚微。
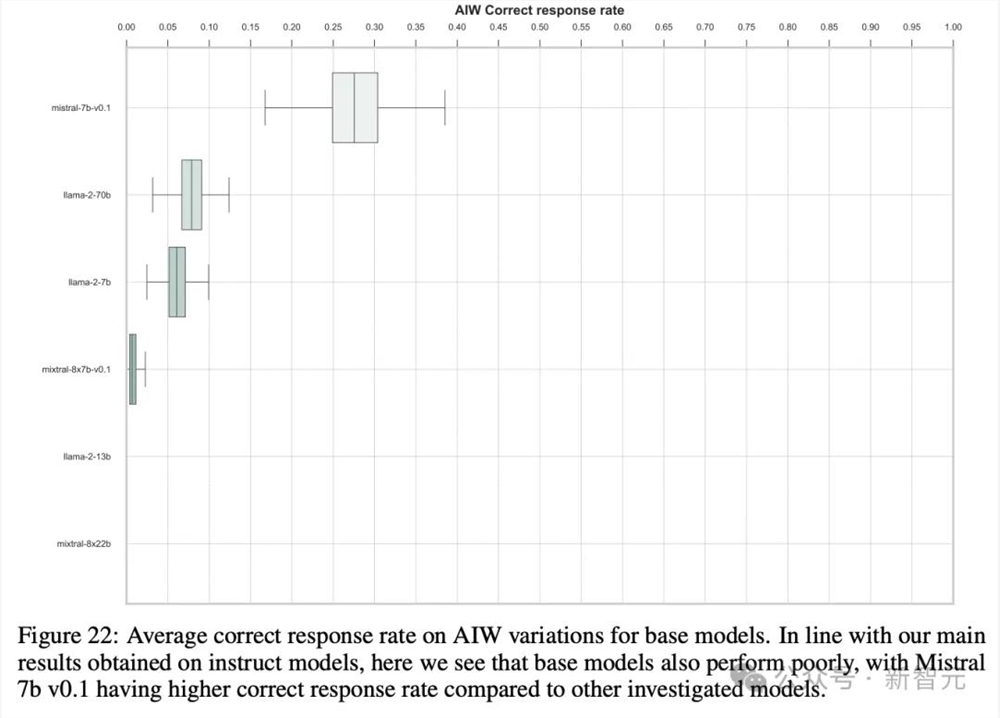
上述实验中,团队采用了各个模型家族内的微调应用版本,那么声称能力更强大的基座模型会不会表现更好呢?
并没有。结果反而是基础模型的崩溃更加严重。
讨论
团队表示,为了在改善当前LLM令人糟心的推理能力,必须要借助广大开源社区的力量。
整个模型创建流程,包括数据集的组成和数据集本身、训练的源代码、训练后的模型、标准化的基准测试程序,都必须完全开放且可重复。
仅开放权重的模型,是无法了解训练过程中可能出错的地方的。例如,数据集组成或训练程序本身。
仅通过API访问的封闭模型,甚至无法进行适当的评估。因为第三方看不到模型的设置,如系统提示和其他推理超参数。
因此,团队认为,要在未来模型中实现适当的推理能力,必须开源模型的完整训练流程——尤其是经常被忽视的数据集组成。
对于基准测试,团队也呼吁AI社区能共同努力进行更新。
比如这次研究中提出的AIW问题集:既简单(用于探测特定类型的推理缺陷),也可定制(提供足够的组合多样性来防止数据污染)。
团队认为,强大且可信的基准测试应遵循Karl Popper的可证伪性原则——不试图突出模型的能力,而是尽一切努力打破模型的功能并突出其缺陷,从而展示模型改进的可能途径。
但问题在于,前者在如今这种商业环境中,诱惑力实在是太大了。
作者介绍
论文的四位作者来自不同的学术机构,但都是德国非营利AI研究机构LAION的成员。
共同一作Marianna Nezhurina,是JSC/图宾根大学的博士生,LAION的核心研究员。她对多模态数据集和学习有浓厚兴趣。
另一位共同一作Jenia Jitsev,是德国Juelich超算中心的实验室负责人,也同时是LAION和Ontocord.AI的联合创始人,他研究的长期目标是从多模式数据流中实现模型可自我调节且节能的持续学习。
参考资料:
https://arxiv.org/abs/2406.02061
(举报)








发表评论取消回复