在发布一周年之际,阿里云通义千问大模型在闭源和开源领域都交上了一份满意的答卷。
国内的开发者们或许没有想到,有朝一日,他们开发的 AI 大模型会像出海的网文、短剧一样,让世界各地的网友坐等更新。甚至,来自韩国的网友已经开始反思:为什么我们就没有这样的模型?
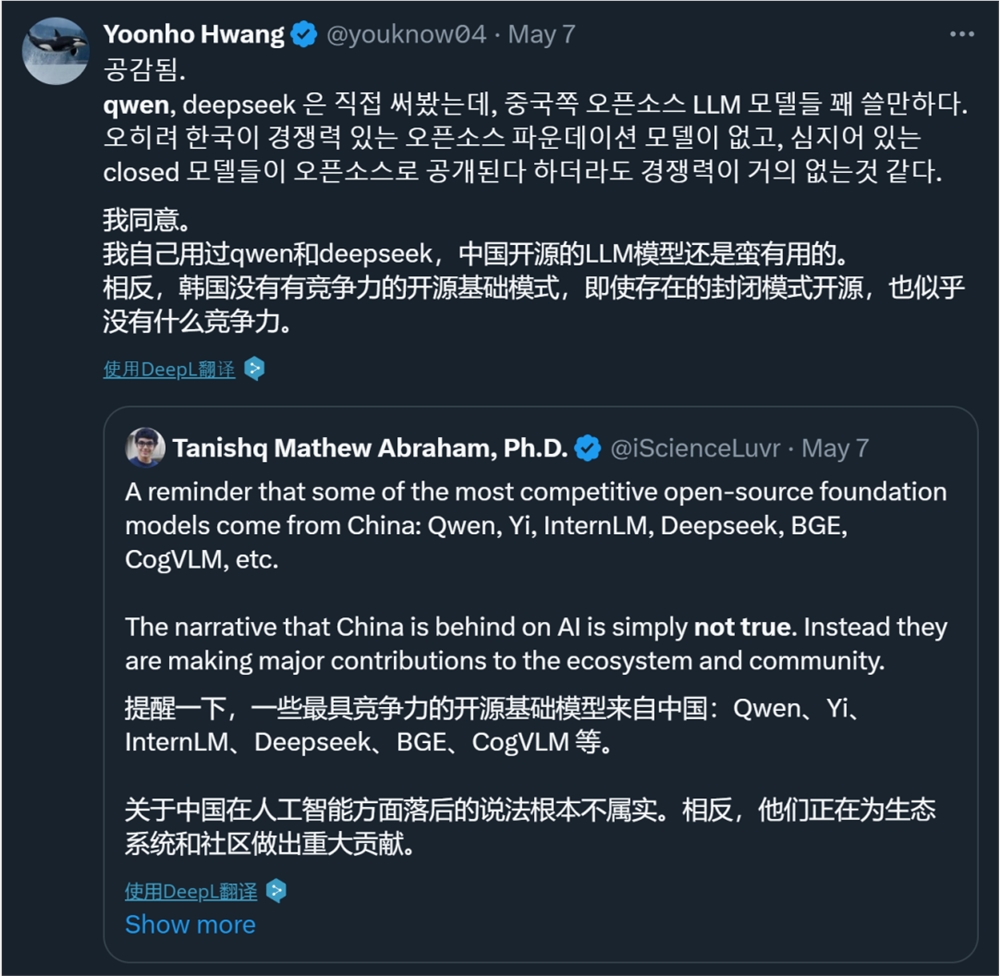
这个「别人家的孩子」就是阿里云的通义千问(英文名为 Qwen)。在过去的一年里,我们经常能够在 X 等社交平台上看到它的身影。这些帖子一般有两个主题:通义千问又开源新模型了!通义千问新模型还挺好用!
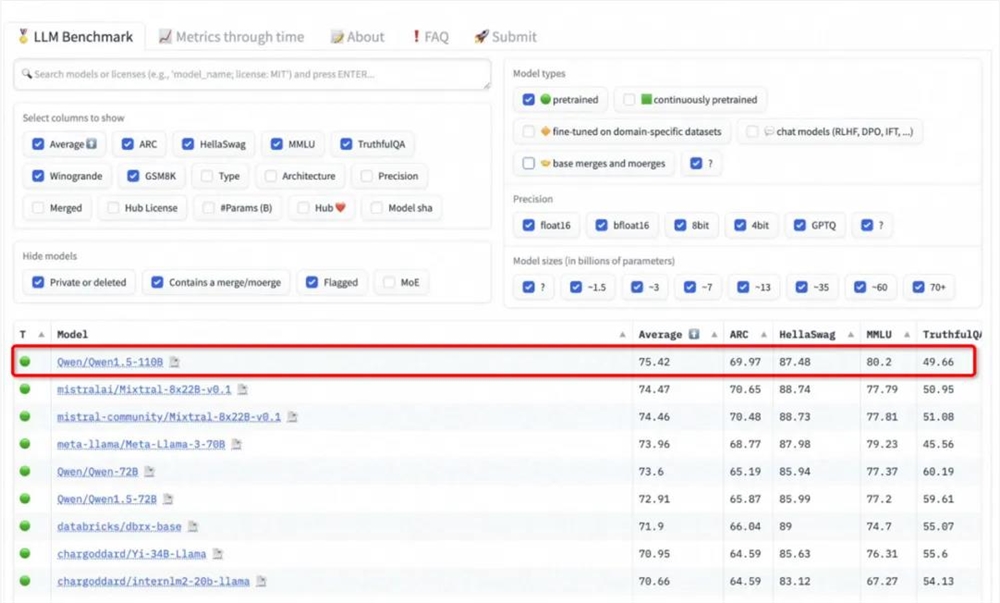
还有人以通义千问为例,反驳中国在人工智能方面落后的说法。而且,这一反驳并非来自主观感受。在最近的HuggingFace开源大模型排行榜 Open LLM Leaderboard 上,我们惊讶地发现,刚刚开源的 Qwen1.5-110B 已经登上了榜首,性能比 Llama-3-70B 还强。
部分开发者的实测体验也佐证了这一结果。
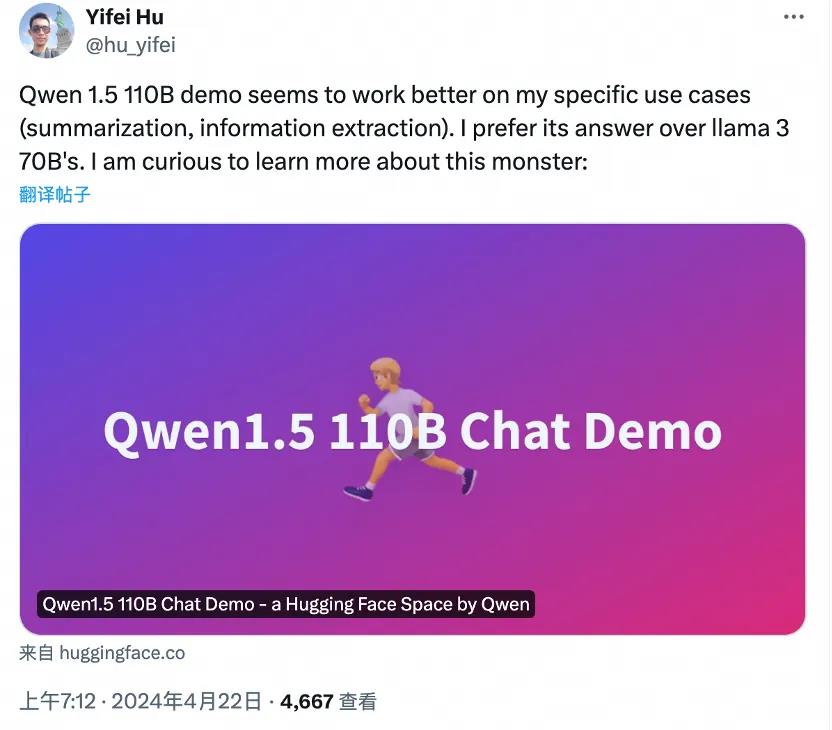
要知道,这还只是 Qwen1.5的实力。等到 Qwen2.x 系列模型开源,我们还将看到更多惊喜。
这份惊喜已经能从通义千问的新模型里看到端倪,即阿里云今天发布的新模型 —— 通义千问2.5。在性能上,该模型在中文场景已经赶超GPT-4Turbo,成为地表最强中文大模型。
去年3月份,OpenAI 发布了 GPT-4。如今,通义千问2.5的发布表明,历经一年多追赶,国产大模型终于进入核心竞技场,可与国外一流大模型一较高下。
这一过程的艰辛是能够可视化的。它就像一场逆流而上的龙舟竞赛,稍有懈怠就会被冲到下游,而且竞争对手全是重量级。
机器之心,赞153
过去一年大模型竞技场排名变化视频(不含 Qwen1.5-110B)。可以看到,尽管面对的是谷歌、Anthropic、Meta 等强大竞争对手,阿里云的 Qwen 也一度跻身前列。
那么,通义千问的开源大模型是如何一步一步走到今天的?最新发布的通义千问2.5又带来了哪些惊喜?这篇文章将逐一揭晓。
超越 Llama-3-70B
通义千问开源大模型如何一步一步登顶?
不久之前,业内曾有过一场「开源模型是否会越来越落后」的争论。但后续出现的 Llama3、Qwen1.5等模型用实力表明,开源模型的发展势头依然迅猛。
最近风头正盛的 Qwen1.5-110B 于4月28日开源,是 Qwen1.5系列中规模最大的模型,也是该系列中首个拥有超1000亿参数的模型。该模型可以处理32K tokens 的上下文长度,并支持英、中、法、西、德、俄、日、韩、越、阿等多种语言。
在技术细节上,Qwen1.5-110B 沿用了 Transformer 解码器架构,包括分组查询注意力(GQA),使得模型推理更加高效。
也因此,Qwen1.5-110B 在 MMLU、TheoremQA、ARC-C、GSM8K、MATH 和 HumanEval 等多个基准测评中不仅优于自家 Qwen1.5-72B,更超越了 Meta 的 Llama-3-70B。这意味着,就基础能力而言,Qwen1.5-110B 成为了比 Llama-3-70B 更优秀的模型。

而在对话聊天场景,Qwen1.5-110B-Chat 在 MT-Bench 和 AlpacaEval2.0基准测试上的表现也双双好于 Llama-3-70B-Instruct。
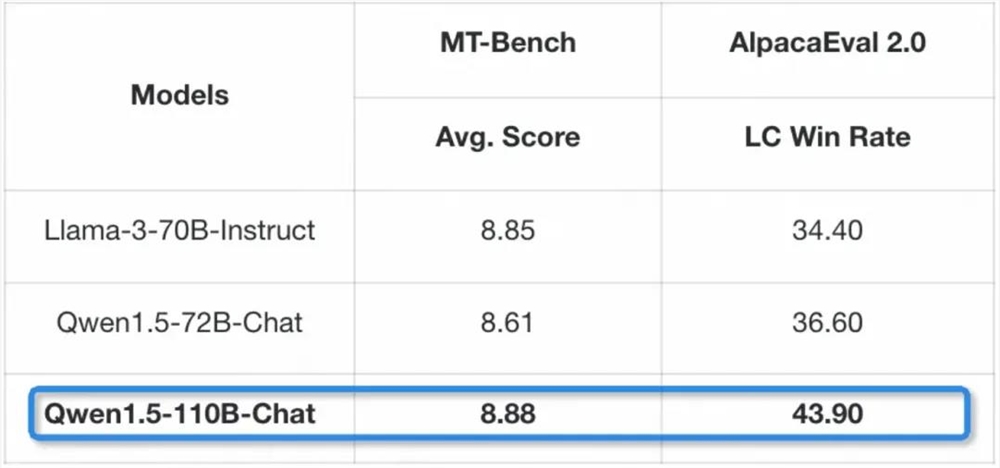
来源:https://mp.weixin.qq.com/s/wrW3JWQWb8W7DqANitrMVw
看到这里,有的开发者可能会说,Qwen1.5-110B 好是好,就是太大了,跑不动啊。
这个时候,通义千问「家大业大」的优势就体现出来了。在 Qwen1.5-110B 发布之前,他们已经开源了从0.5B 到72B 的七种尺寸的模型,提供了从端侧到服务器部署的多种选择。
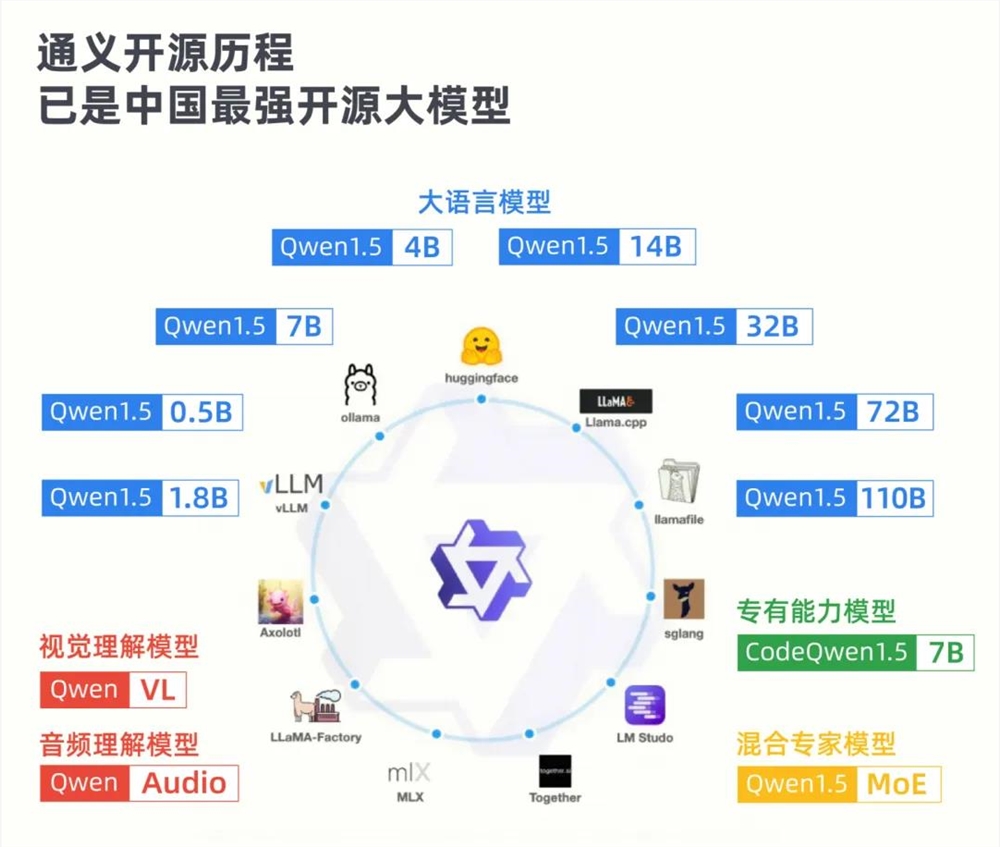
而且,这些模型在各自所处的参数量级上都名列前茅。
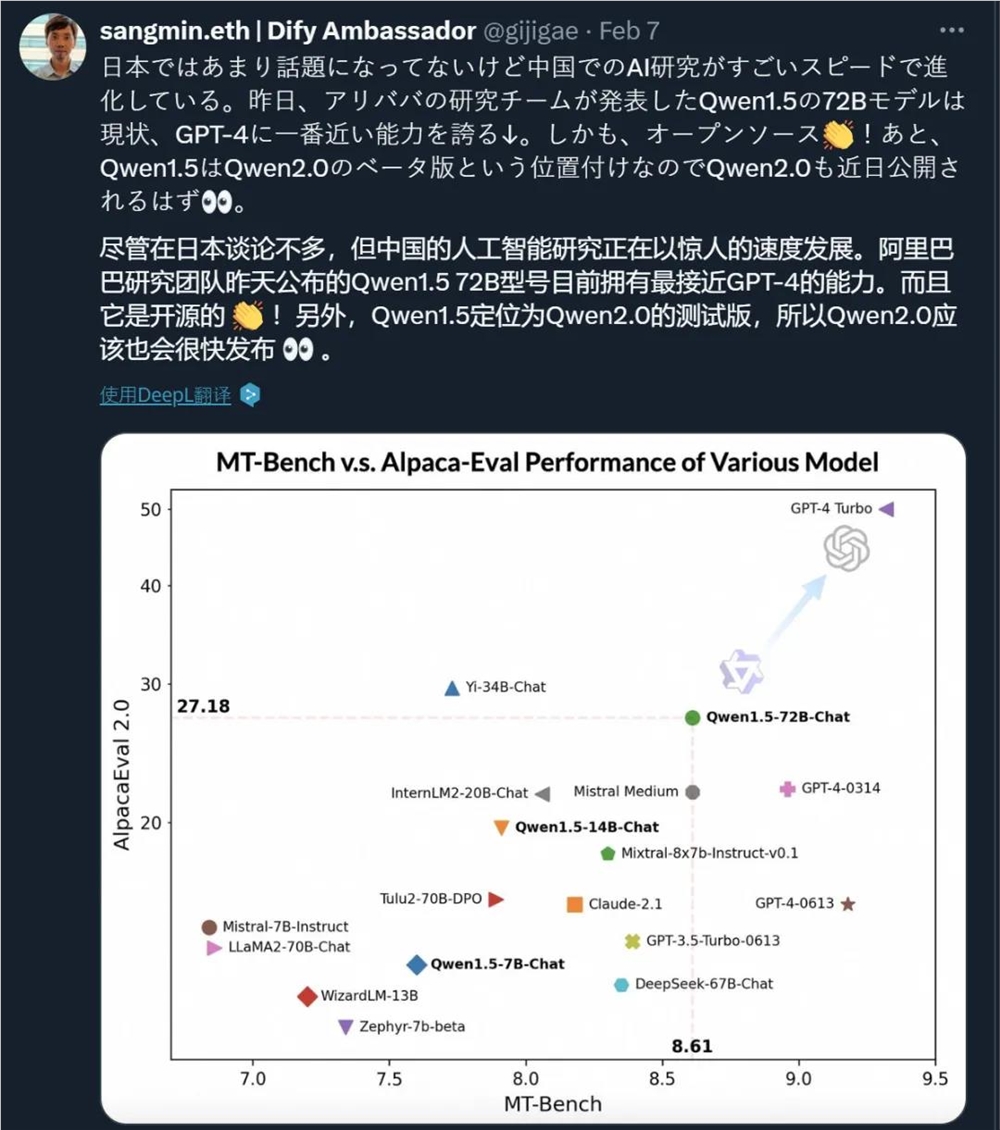
以 Qwen1.5-72B 为例,这个模型不仅登顶过 HuggingFace 开源大模型排行榜、OpenCompass 开源基座大模型排行榜,而且在 MT-Bench 和 Alpaca-Eval v2评测中也表现不俗,超过 Claude-2.1、GPT-3.5-Turbo-0613、Mixtral-8x7b-I nstruct 等模型。
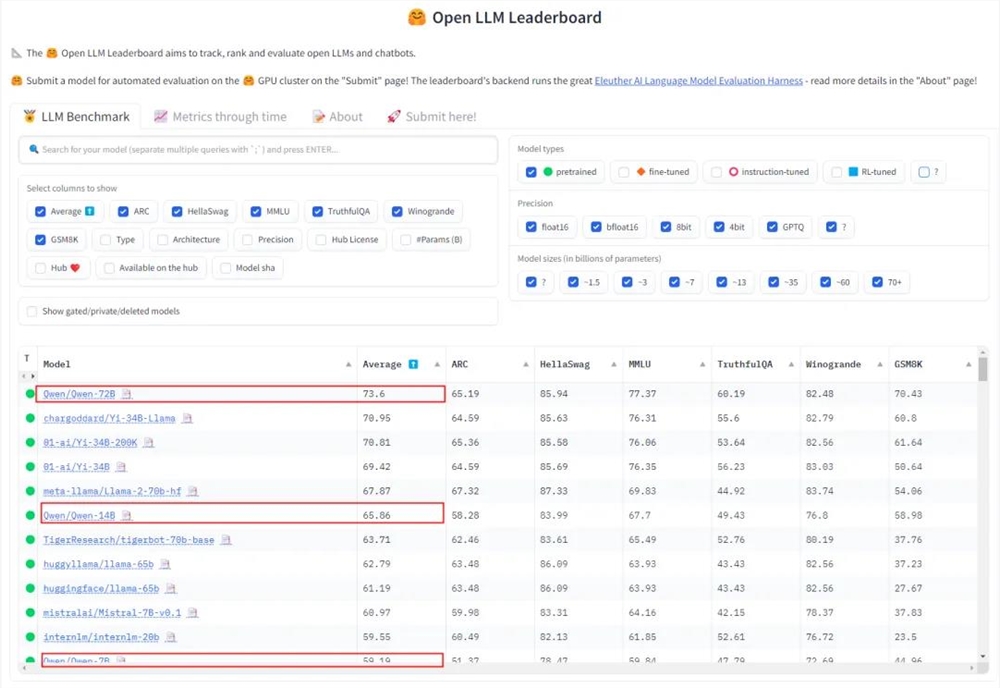
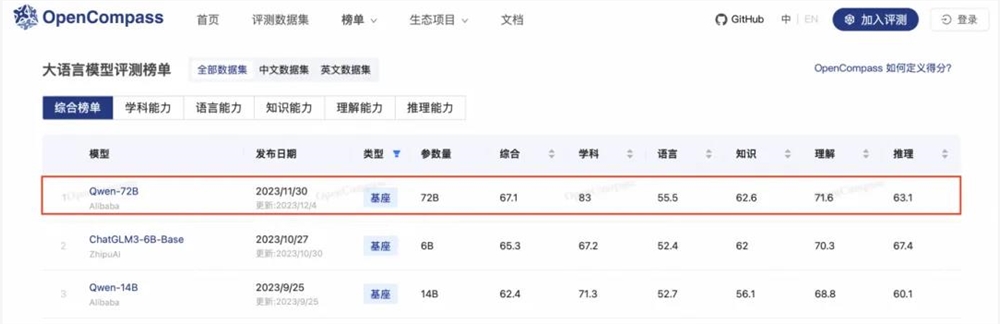
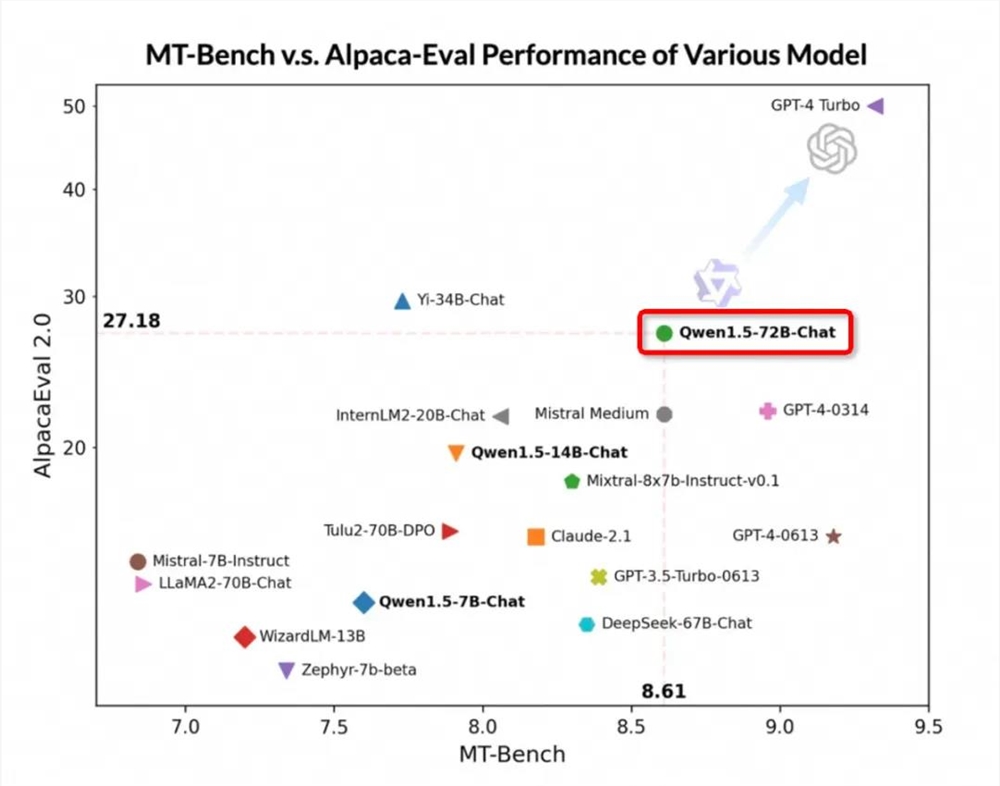
在开放研究机构 LMSYS Org 推出的基准测试平台 Chatbot Arena 上,Qwen1.5-72B 模型更是多次进入「盲测」结果全球 Top10,创造了国产大模型的先例。
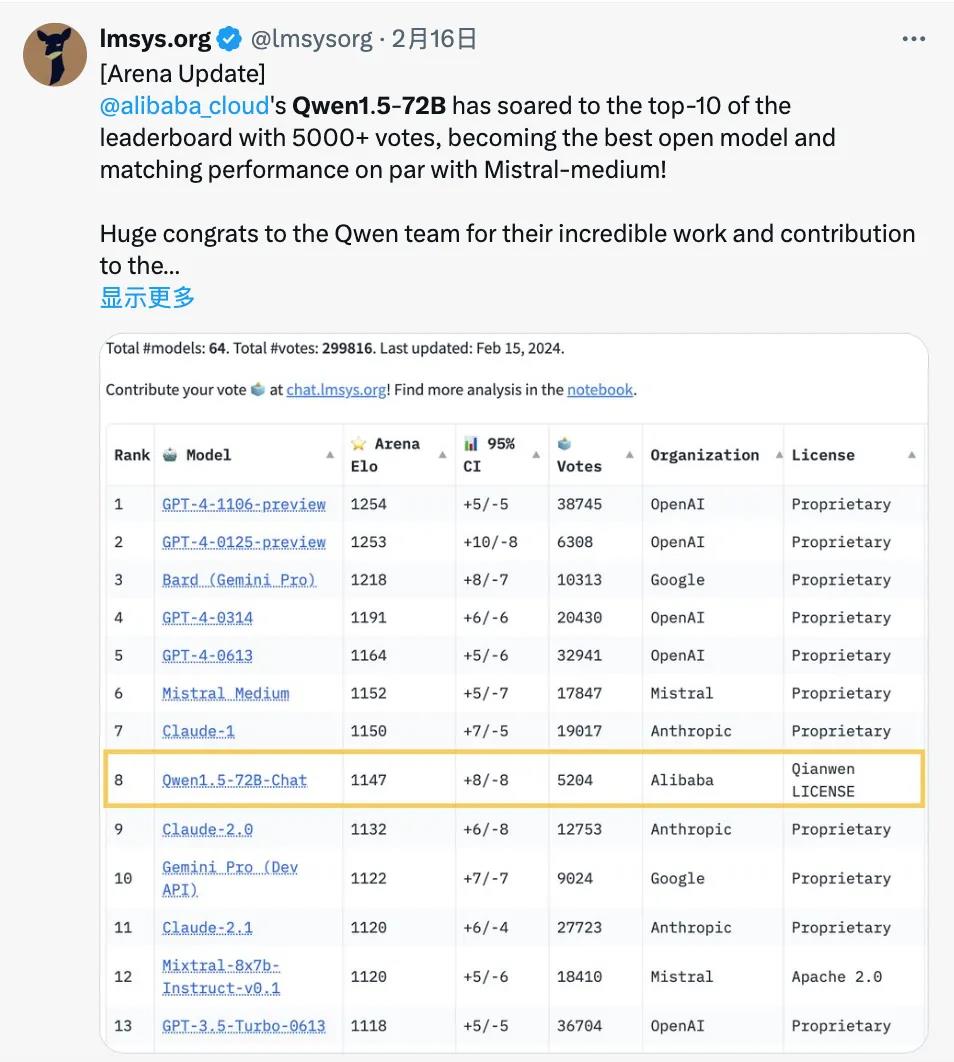
而且,和 Qwen1.5-110B 一样,它也展现出了卓越的多语言能力。
有位越南网友表示,在越南版的 MMLU(VMLU)上,Qwen-72B 开箱即用,拿到了和 GPT-4一样的分数,直接冲到了 SOTA。

而一位韩国网友看到后跟帖说,「在 wuli(我们的)韩国版 MMLU 上也一样。」
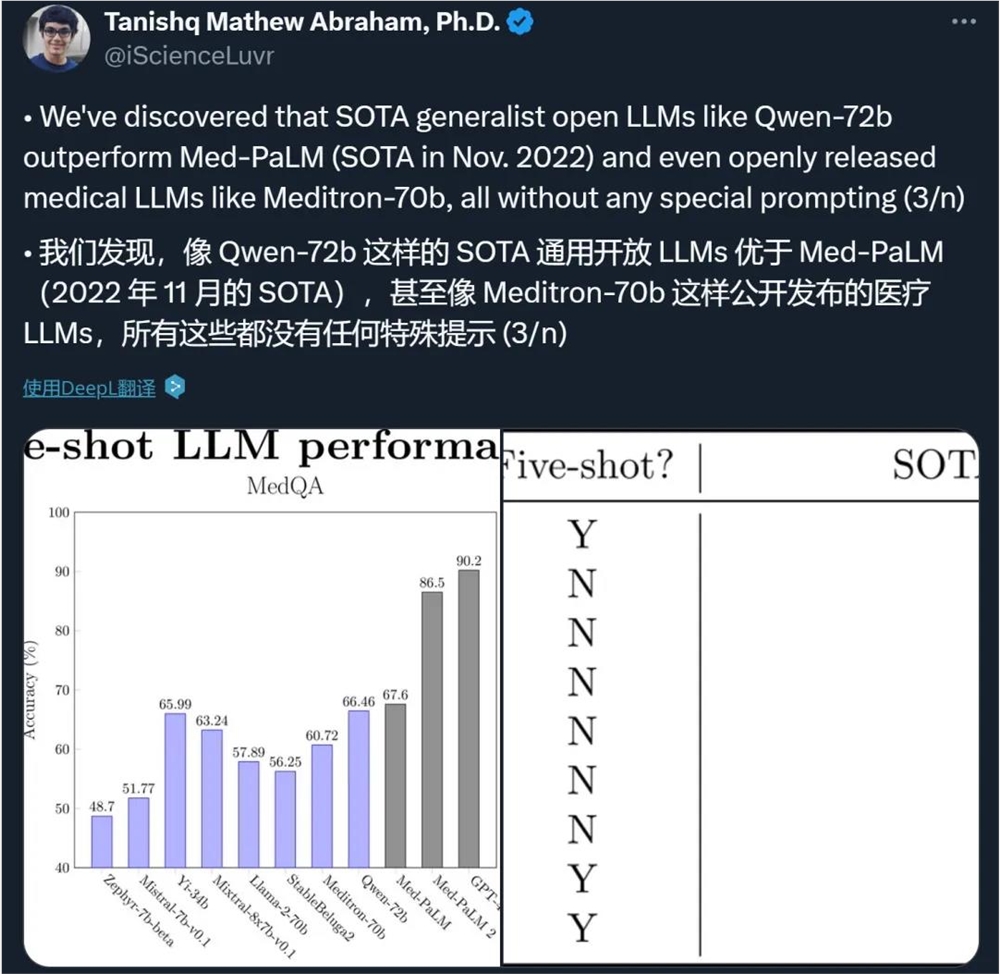
除了语言,还有人发现了 Qwen-72B 的隐藏技能 —— 医疗知识。不需要写任何特殊提示(prompt),Qwen-72B 给出的答案就能胜过专业的医疗 LLM。
当然,可能会有开发者说,72B 还是太大了,跑不动。那不妨试试更小的模型:14B、7B 的 Qwen 也很好用。
而且,这个7B 模型还有「平替」,即性能与之相当的 Qwen1.5-MoE-A2.7B。Qwen1.5-7B 包含65亿个 Non-Embedding 参数,Qwen1.5-MoE-A2.7B 只有20亿个,仅为前者的1/3。但是,后者推理速度提升了1.74倍,对于开发者来说更为高效。
可以看到,在众多的大模型厂商中,通义千问在开源领域罕见地做到了「全尺寸」的开源,而且还在利用 MoE 等技术不断优化推理成本,这极大地扩展了其适用范围。
除此之外,通义千问还在多模态以及一些实用的专有能力上进行了探索,开源了视觉理解模型 Qwen-VL,音频理解模型 Qwen-Audio 以及代码专家模型 CodeQwen1.5。
其中,CodeQwen1.5-7B 登顶过 Huggging Face 代码模型榜单BigCode。
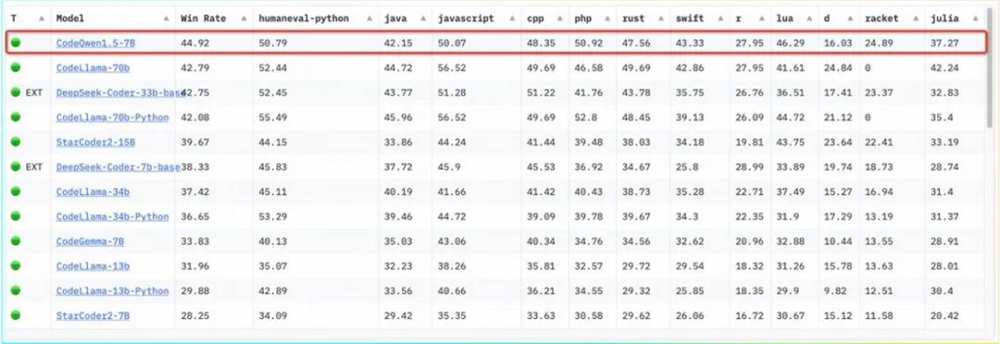
这些模型在开发者社区也广受好评。
有人在评论区喊话 Qwen 的核心维护者Binyuan Hui,希望这些模型的升级版也能进一步开源。
此外,还有很多人在等 Qwen2开源。
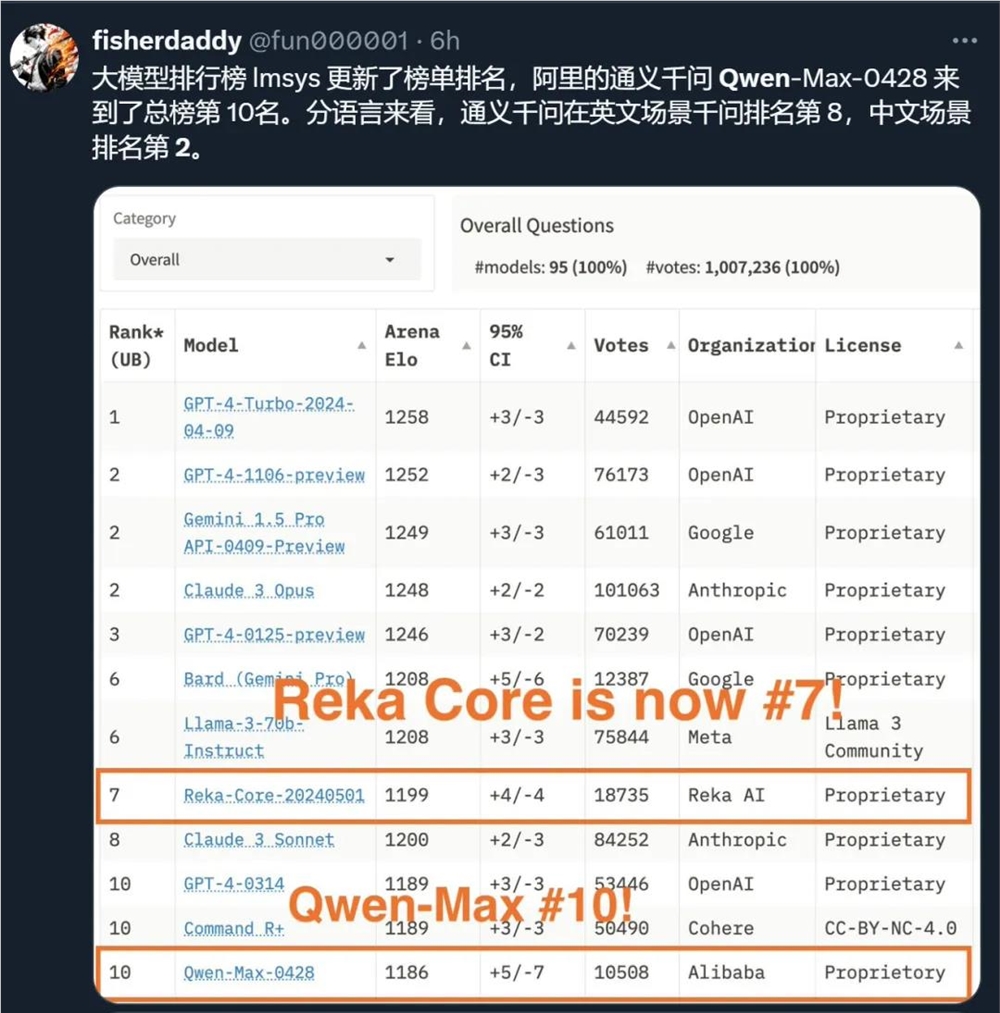
测试中的 Qwen-Max-0428更是引发了各种猜测(有人认为它就是即将开源的 Qwen2)。最新消息显示,这个模型已经跻身 Chatbot Arena 总榜第10名,英文场景排名第8,中文场景排名第2。
在今天的发布会上,阿里云 CTO 周靖人透露,未来通义大模型还会持续开源,感觉大家千呼万唤的 Qwen2已经在路上了(coming soon)。

地表最强中文大模型
通义千问2.5赶超 GPT-4Turbo
在坚持 Qwen1.5系列模型开源之外,通义千问大模型专注于「修炼内功」,基础能力得到不断进步。自问世以来,通义千问的不断迭代带来自然语言、图像、音视频等生成式 AI 能力的持续升级,为更好、更快、更准的用户体验打好基础。
果不其然,此次发布会上,我们见证了通义千问2.5基础能力的又一次全方位提升。
相较于前序版本通义千问2.1,通义千问2.5的理解能力、逻辑推理、指令遵循和代码能力分别提升了9%、16%、19%、10%,将基础能力「卷」出新高度。
其中,中文语境下的文本生成和理解、 知识问答、生活建议、闲聊对话等垂直场景的能力更是赶超 GPT-4,成为中文社区最佳选择。
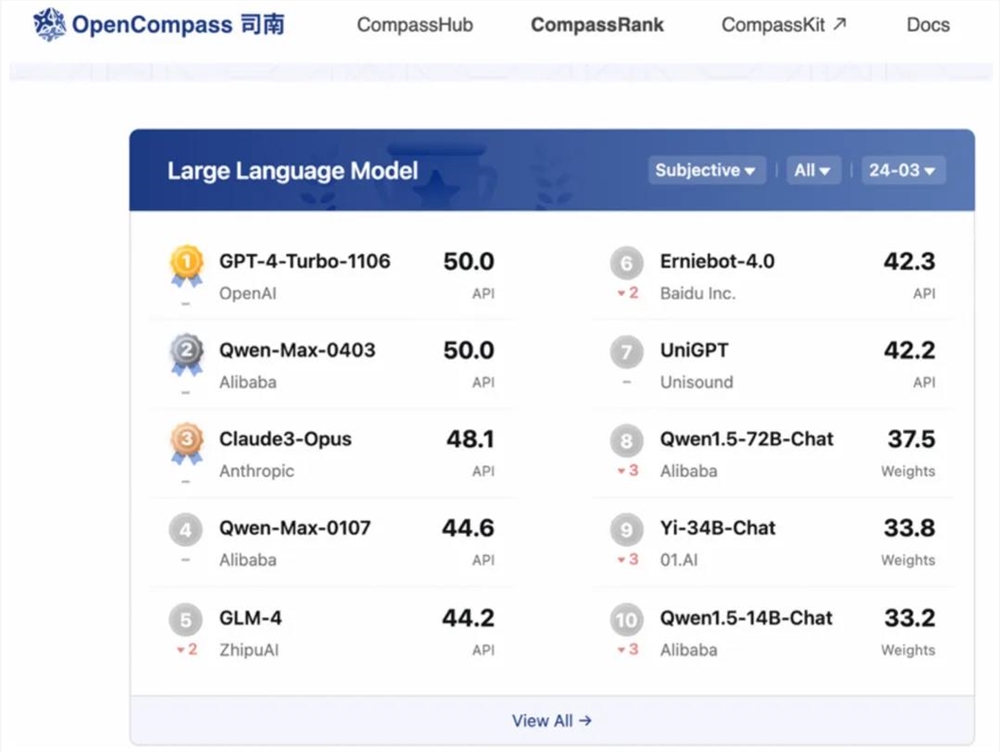
在权威大模型评测基准平台 OpenCompass 上,通义千问2.5的得分追平了 GPT-4Turbo。这是国产大模型首次在该基准上取得如此出色的成绩,让我们看到了通义千问能力持续进化的巨大潜力。
至此,通义千问已经站到了国内外大模型领域的第一梯队。
而得益于更强大的基础能力,通义千问2.5在文档处理、音视频理解和智能代码使用场景形成了独有优势。
首先,通义千问2.5具备了超强的文档处理能力,在支持输入的文本长度上可以单次处理1000万字,在支持输入的文档数量上可以单次处理100个文档,实现了单次最长和最多。
通义千问2.5支持丰富的文件格式和文本类型,比如 Word、PDF、Excel 以及表单、合同、白皮书、论文、财报研报等。文本任务也多样化,比如解析标题、文本段落、表格、图表等多种版面类型及文档层级目录的识别和抽取。在输出时支持 Markdown、JSON 等格式,对用户友好、易用性拉满。
其次,通义千问2.5具有出色的音视频理解能力。
在通义千问语言能力、LLM 能力、多模态能力和翻译能力的加持下,通过通义听悟、语言视觉 AI 模型等,实现音视频场景的信息挖掘、知识沉淀和高效阅读。相关能力已在钉钉、阿里云盘等内部产品以及合作伙伴的具体场景中有了广泛的落地实践,让模型应用实现「开花结果」。
此外,通义千问2.5赋予了开发者和企业卓越的智能编码能力。
以通义代码大模型CodeQwen1.5为底座的智能代码助手「通义灵码」,它的国内用户规模已经达到了第一,其中插件下载量超过350万,每日推荐代码超过3000万次,开发者采纳代码超过1亿行。同时,正式发布的通义灵码企业版能够基于企业需求进行定制,帮助他们提升编码体系的整体效率。
可以预见,随着通义千问2.5的到来,它将成为更强大的模型底座,进而为普通用户、开发者和企业客户提供更多样化、更准确、更快速的生成式 AI 体验。
实战效果
当然,评测数据的高低不能全方面代表大模型的实际效果。接下来,我们从普通用户的角度考验一下模型的能力到底如何。

通义千问网页版地址:https://tongyi.aliyun.com/
输入问题:「我今天有3个苹果,昨天吃了一个。现在有几个苹果?」

对于这个问题,假如不细想的话,很可能会给出错误答案2,但通义千问不但给出了准确的答案,还分析了原因。
自打大模型爆火以来,「弱智吧」就成了检测大模型能力的一项重要指标。我们测试一下通义千问会不会被弱智吧的问题绕进去。


从结果可以看出,通义千问不但给出了原因,还为我们补充了很多相关知识。
通义千问解读笑话也是信手拈来:

接下来我们考察通义千问文本生成能力如何。

通篇读下来,确实很有《红楼梦》风格,连唇膏名字都替我们想好了。
在长文本方面,通义千问也表现突出, 对论文《KAN: Kolmogorov–Arnold Networks 》(论文长达48页)的亮点概括非常全面。

在代码方面,我们要求通义千问编写一个打地鼠的游戏,一眨眼的功夫,程序就完成了。

我们接着测试了通义千问对图片的理解能力。比如吉娃娃和蓝莓松饼之间有着惊人的相似之处,大模型经常分辨不出,当我们输入带有两者的图片时,通义千问都能进行很好的区分:


根据 emoji 表情猜成语也不在话下。

生活中遇到了问题,拍张图片上传到通义千问,它也能给出一些指导性建议。

通义千问不仅能够理解图片,还能生成图片。唐代诗人王之涣笔下的《登鹳雀楼》描述的场景被活灵活现的呈现出来了。

以上测试,只是通义千问众多功能中的冰山一角,感兴趣的读者可以前去官方网站一试。
一年时间赶超 GPT-4Turbo
通义千问做对了什么?
回顾过去的一年,上半年是百模大战,后半年是瞄准 GPT-4的全面冲刺。在如此激烈的战场上厮杀,并保持自身对于外界的辨识度,即使对于通义千问这样的大厂模型来说也不是件容易的事。
但是,通义千问不仅做到了,还在国内外都建立起了良好的口碑。这不仅得益于其背后团队对于智能极限的探索,也得益于其对开源路线的坚持。
其实,这两者是相辅相成的。我们看到,无论是在开源还是闭源的竞技场上,开发者、企业用户都有很多的模型可以选择,因此,即使是做开源,也要开源最强的模型才有人用。而有人用才会有反馈,这点对于提升开源模型的能力至关重要。
在采访中,阿里云副总裁、公众沟通部总经理张启提到,现在围绕通义千问的开发者社区非常活跃,他们每天会给通义千问的模型开发人员提供非常多有意义的反馈,有很多反馈甚至超出了他们自己原来的设想。这也是为什么通义千问能够在一年的时间内先后超越 GPT-3.5、GPT-4Turbo 的性能。「开源后,来自全球开发者的真实反馈,对我们模型本身进步发展速度的意义非常重大。」张启说到。
在这种体系下,通义千问的开发人员与企业、开发者之间形成了一种并行探索的关系,有利于进一步挖掘 AI 大模型的潜力。
「如今,有很多开发者、企业能够结合自己的实际开发场景和业务需求,借助 AI 模型实现翻天覆地的变化。在这个时间点,我们希望能够以一个开放的心态,将最先进的技术在各个方面开源,让大家做并行的探索。这对整个产业乃至每个企业的创新性开发都至关重要,并已被全球范围内多次证明其价值。」周靖人说到。
其实,Meta 的成功就是周靖人提到的「证明」之一。前段时间,Meta CEO 扎克伯格在采访中举例说明了自家的 Open Compute 项目如何通过开源服务器、网络交换机和数据中心的设计,最终导致供应链围绕这些设计建立,从而提高了产量并降低了成本,为公司节省了数十亿美元。他们预计 AI 大模型领域也将发生同样的事情。
此外,他还提到,开源有利于减少个别大公司对创新生态的限制。这和周靖人的观点不谋而合。「曾几何时,大家用云计算的时候,最担心的就是上了某家的云之后就被绑定。我们把技术进展以开源的方式展现给大家,也是希望给大家多种选择,让大家没有后顾之忧。」周靖人说到。
从12年前的深度学习革命开始,开源对 AI 技术的发展就起着关键性的推动作用。即使到如今的大模型时期,开源依然是推动大模型技术普遍落地应用的有效方式之一。
在我们看来,近一年来通义系列的持续开源,对中文大模型社区的发展非常有意义,也期待后续有越来越多的强劲大模型继续开源。
(举报)








发表评论取消回复