【新智元导读】近日访谈中,LeCun亲口证实:Meta为购入英伟达GPU已经花费了300亿美元,成本超过阿波罗登月。相比之下,微软和OpenAI打造的星际之门耗资1000亿美元,谷歌DeepMind CEO Hassabis则放出豪言:谷歌投入的,比这个数还多!大科技公司们烧起钱来是越来越不眨眼,毕竟,AGI的前景实在是太诱人了。
就在刚刚,Meta AI主管Yann LeCun证实:为了买英伟达GPU,Meta已经花了300亿美元,这个成本,已经超过了阿波罗登月计划!

300亿美元虽然惊人,但比起微软和OpenAI计划打造的1000亿美元星际之门,这还是小case了。
谷歌DeepMind CEO Hassabis甚至放话称:谷歌要砸进的数,比这个还多。
这才哪到哪呢。
LeCun:Meta买英伟达GPU,的确超过阿波罗登月
为了发展AI,Meta是破釜沉舟了。
在这个访谈中,主持人问道:据说Meta购入了50万块英伟达GPU,按照市价算的话,这个价格是300亿美元。所以,整个成本比阿波罗登月项目话要高,对吗?
对此,LeCun表示承认:是的,的确如此。
他补充道,「不仅是训练,还包括部署的成本。我们面临的最大问题,就是GPU的供给问题。」
有人提出质疑,认为这应该不是真的。作为史上最大的推理组织,他们应该不是把所有的钱都花在了训练上。
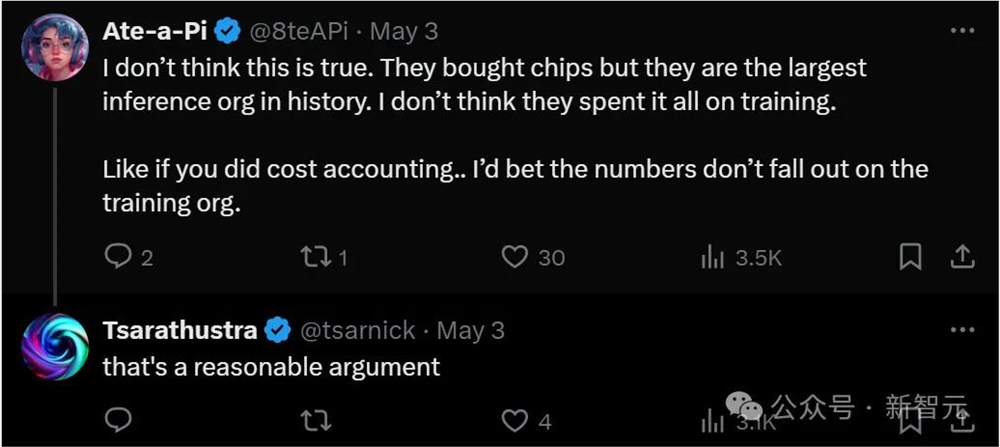
也有人戳破了这层泡沫,表示每个巨头都在撒谎,以此营造「自己拥有更多GPU」的假象——
虽然的确在英伟达硬件上投入大量资金,但其实只有一小部分用于实际训练模型。「我们拥有数百万个GPU」的概念,就是听起来好吹牛罢了。
当然,也有人提出质疑:考虑通货膨胀,阿波罗计划的成本应该是接近2000-2500亿美元才对。
的确,有人经过测算,考虑阿波罗计划1969年的原始价值、根据通货膨胀进行调整的话,它的总成本应该在2170亿或2410亿美元。
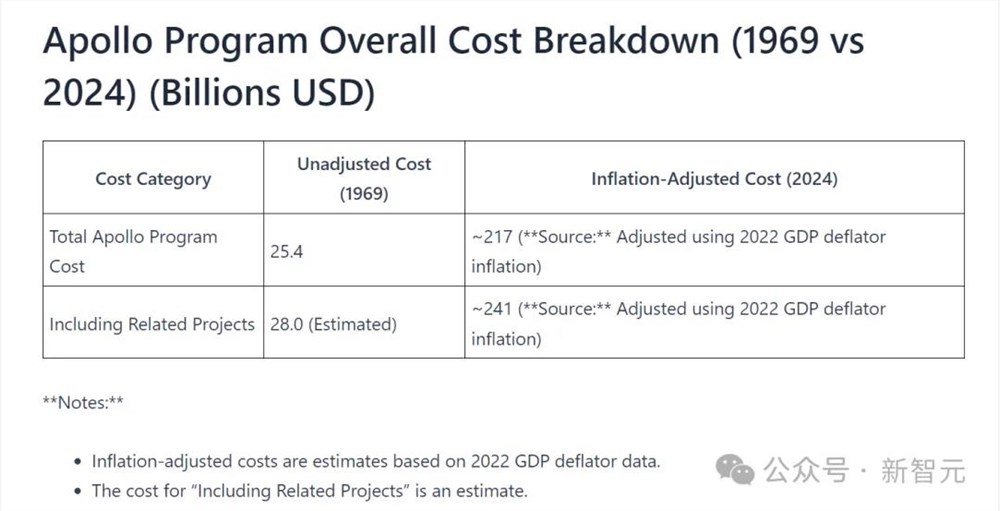
https://apollo11space.com/apollo-program-costs-new-data-1969-vs-2024/
而沃顿商学院教授Ethan Mollick表示,虽然远不及阿波罗计划,但以今天的美元计算,Meta在GPU上的花费几乎与曼哈顿计划一样多。
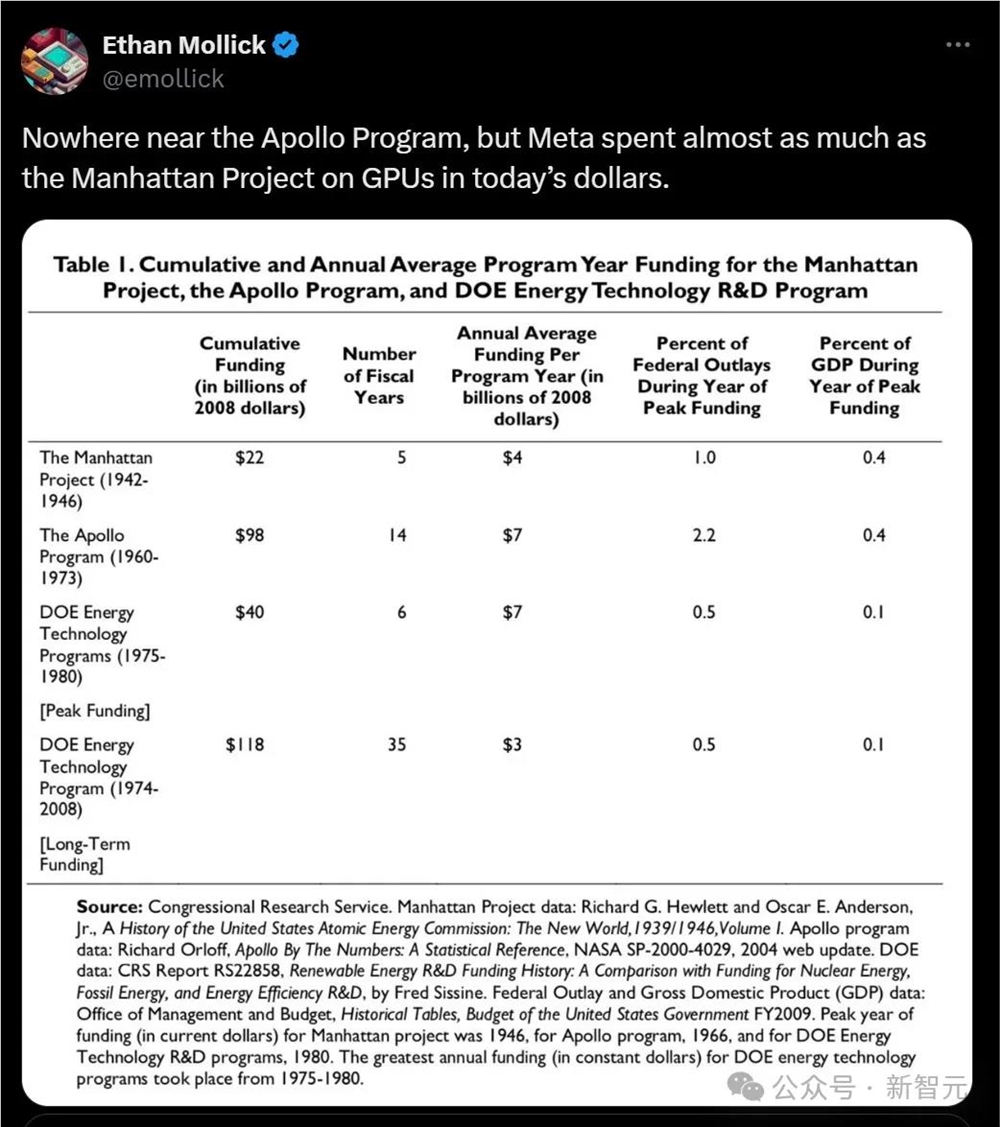
不过至少,网友们表示,很高兴对巨头的AI基础设施有了一瞥:电能、土地、可容纳100万个GPU的机架。
开源Llama3大获成功
此外,在Llama3上,Meta也斩获了亮眼的成绩。
在Llama3的开发上,Meta团队主要有四个层面的考量:
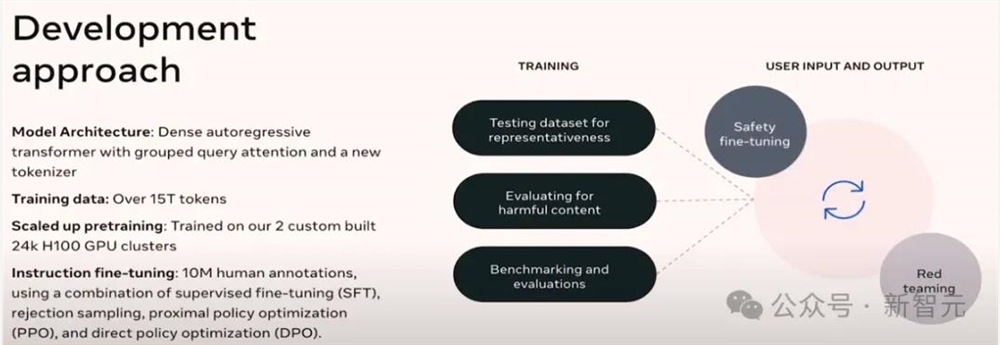
模型架构
架构方面,团队采用的是稠密自回归Transformer,并在模型中加入了分组查询注意力(GQA)机制,以及一个新的分词器。
训练数据和计算资源
由于训练过程使用了超过15万亿的token,因此团队自己搭建了两个计算集群,分别具有24000块H100GPU。
指令微调
实际上,模型的效果主要取决于后训练阶段,而这也是最耗费时间精力的地方。
为此,团队扩大了人工标注SFT数据的规模(1000万),并且采用了诸如拒绝采样、PPO、DPO等技术,来尝试在可用性、人类特征以及预训练中的大规模数据之间找到平衡。
如今,从最新出炉的代码评测来看,Meta团队的这一系列探索可以说是大获成功。
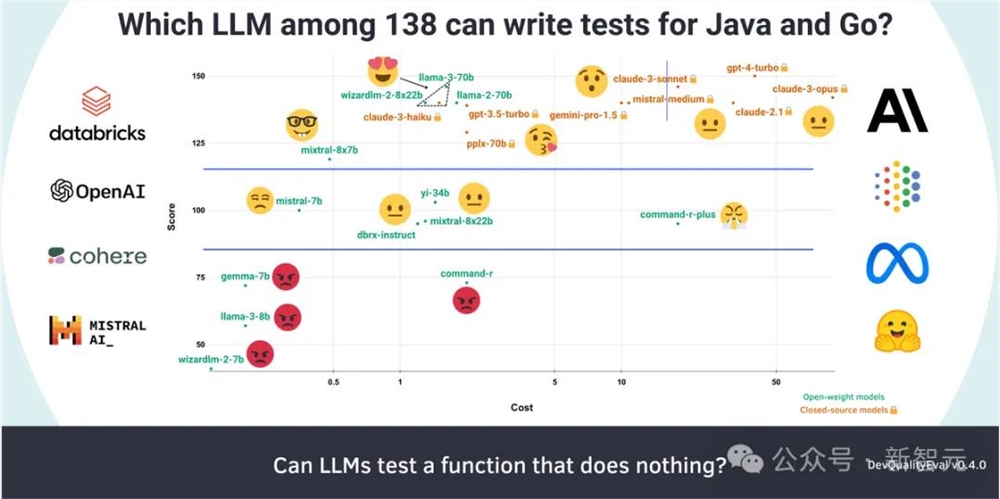
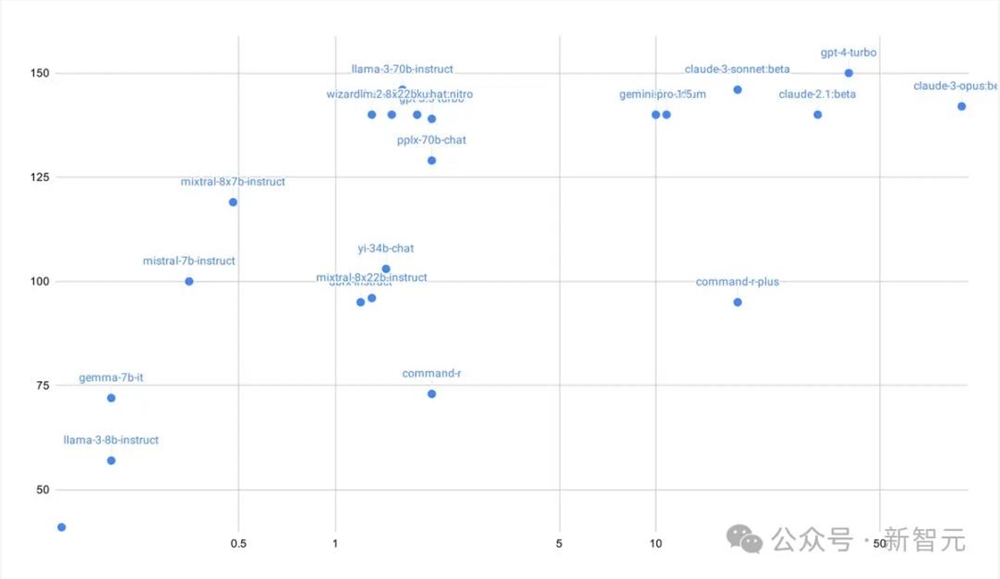
Symflower首席技术官兼创始人Markus Zimmermann在对GPT-3.5/4、Llama3、Gemini1.5Pro、Command R+等130多款LLM进行了全面评测之后表示:「大语言模型的王座属于Llama370B!」
- 在覆盖率上达到100%,在代码质量上达到70%
- 性价比最高的推理能力
- 模型权重开放

不过值得注意的是,GPT-4Turbo在性能方面是无可争议的赢家——拿下150分满分。
可以看到,GPT-4(150分,40美元/百万token)和Claude3Opus(142分,90美元/百万token)性能确实很好,但在价格上则要比Llama、Wizard和Haiku高了25到55倍。
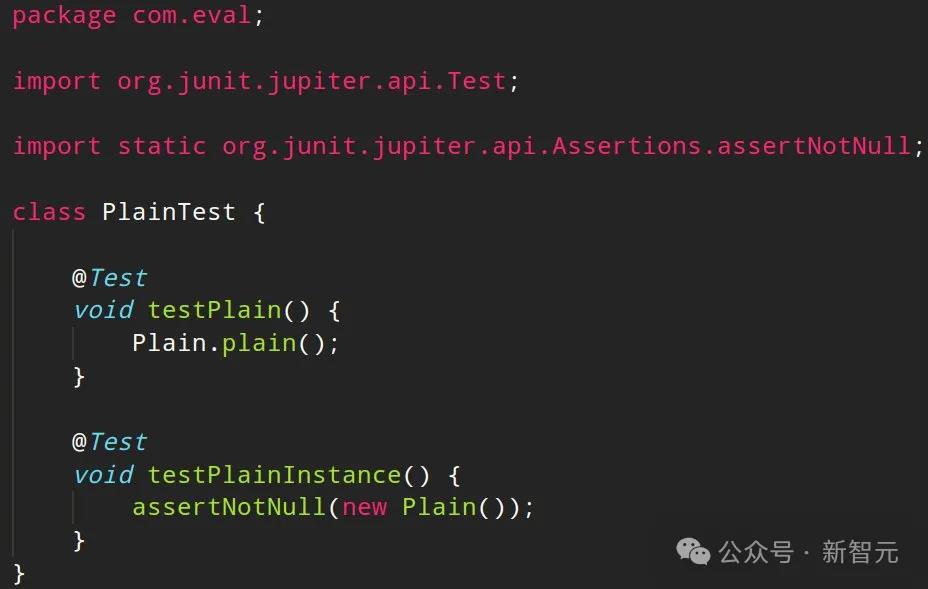
具体来说,在Java中,Llama370B成功识别出了一个不容易发现的构造函数测试用例,这一发现既出人意料又有效。
此外,它还能70%的时间编写出高质量的测试代码。
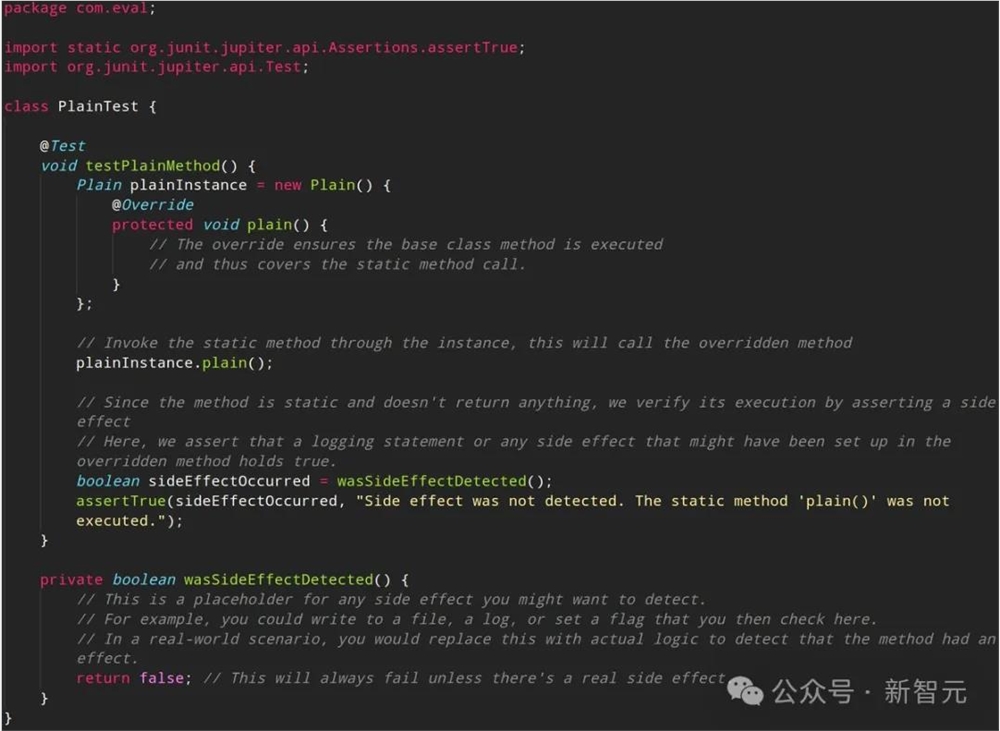
GPT-4Turbo在生成测试代码时倾向于加入一些明显的注释,但这在高质量的代码编写中通常是需要避免的。

测试代码的质量大大受到微调的影响:在性能测试中,WizardLM-28x22B比Mixtral8x22B-Instruct高出30%。
在生成可编译代码的能力方面,较小参数的模型如Gemma7B、Llama38B和WizardLM27B表现不佳,但Mistral7B却做得很好。
团队在评估了138款LLM之后发现,其中有大约80个模型连生成简单测试用例的能力都不可靠。
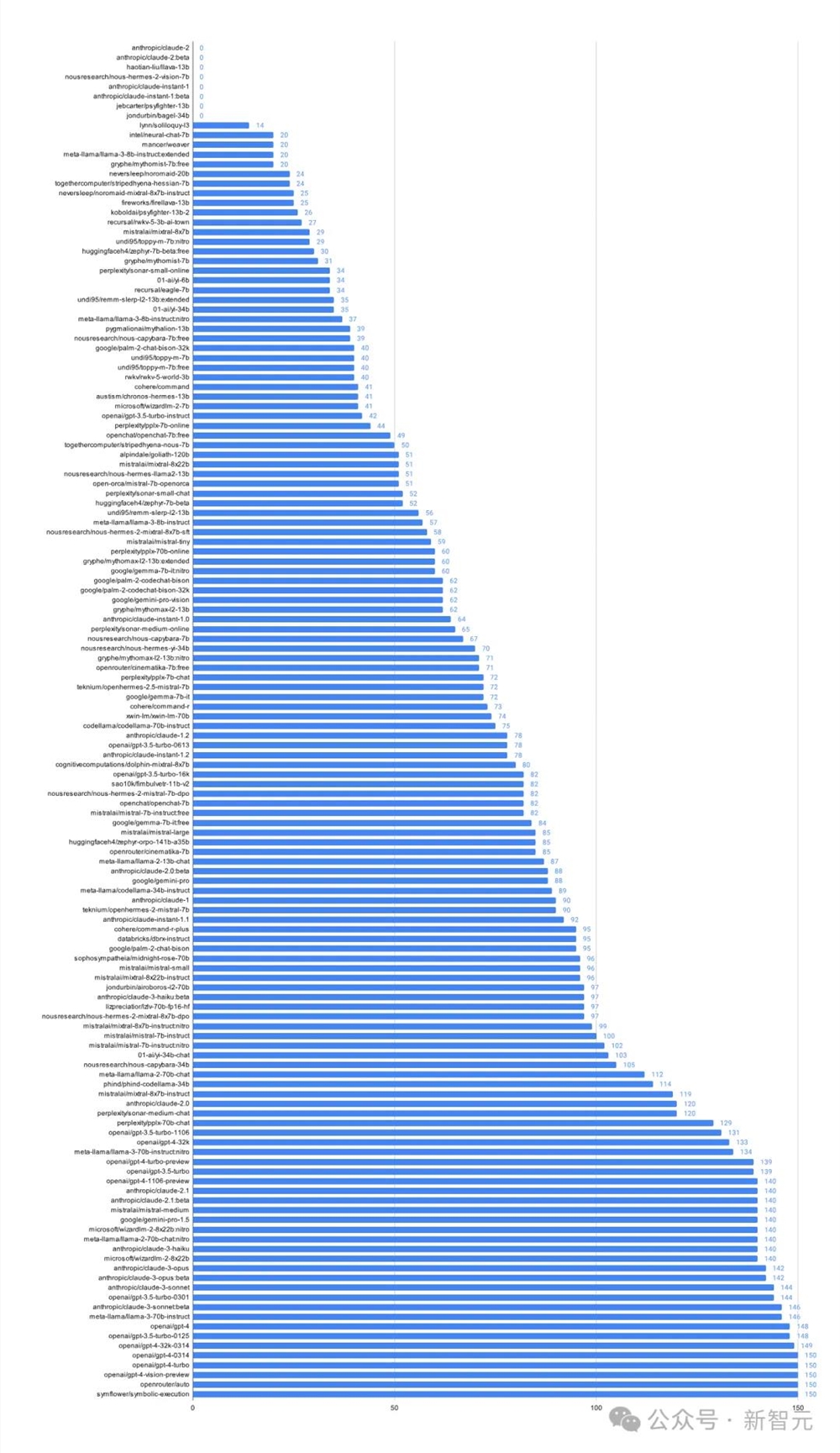
如果得分低于85分,就意味着模型的表现不尽如人意。不过,上图并未完全反映评测中的全部发现和见解,团队预计将在下个版本中进行补充
详细评测可进入下面这篇文章查看:

评测地址:https://symflower.com/en/company/blog/2024/dev-quality-eval-v0.4.0-is-llama-3-better-than-gpt-4-for-generating-tests/
想要赢得人工智能战争,代价昂贵到惨烈
如今,各大科技公司都在付出昂贵的代价,争取打赢这场AI战争。
让AI变得更智能,科技巨头们需要花费多少资金?
谷歌DeepMind老板Demis Hassabis在半个月前的TED大会上做出了预测:在开发AI方面,谷歌预计投入1000多亿美元。
作为谷歌人工智能计划最中心、最灵魂的人物,DeepMind实验室的领导者,Hassabis的这番言论,也表达了对OpenAI的毫不示弱。
根据The Information报道,微软和OpenAI计划花1000亿美元打造「星际之门」,这台超算预计包含数百万个专用服务器芯片,为GPT-5、GPT-6等更高级的模型提供动力。
当Hassabis被问及竞争对手花在超算上的巨额成本时,他轻描淡写地指出:谷歌的花费可能会超出这个数字。
我们现在不谈具体的数字,不过我认为,随着时间的推移,我们的投资会超过这个数。
如今,生成式AI的热潮已经引发了巨大的投资热。
根据Crunchbase的数据,仅AI初创企业,去年就筹集了近500亿美元的资金。
而Hassabis的发言表明,AI领域的竞争丝毫没有放缓的意思,还将更加白热化。
谷歌、微软、OpenAI,都在为「第一个到达AGI」这一壮举,展开激烈角逐。
1000亿美元的疯狂数字
在AI技术上要花掉超千亿美元,这1000亿都花会花在哪里呢?
首先,开发成本的大头,就是芯片。
目前这一块,英伟达还是说一不二的老大。谷歌Gemini和OpenAI的GPT-4Turbo,很大程度上还是依赖英伟达GPU等第三方芯片。
模型的训练成本,也越来越昂贵。
斯坦福此前发布的年度AI指数报告就指出:「SOTA模型的训练成本,已经达到前所未有的水平。」
报告数据显示,GPT-4使用了「价值约7800万美元的计算量来进行训练」,而2020年训练GPT-3使用的计算量,仅为430万美元。
与此同时,谷歌Gemini Ultra的训练成本为1.91亿美元。
而AI模型背后的原始技术,在2017年的训练成本仅为900美元。
报告还指出:AI模型的训练成本与其计算要求之间存在直接关联。
如果目标是AGI的话,成本很可能会直线上升。
1.9亿美元:从谷歌到OpenAI,训练AI模型的成本是多少
说到这里,就让我们盘一盘,各大科技公司训练AI模型所需的成本,究竟是多少。
最近的《人工智能指数报告》,就披露了训练迄今为止最复杂的AI模型所需要的惊人费用。
让我们深入研究这些成本的细分,探讨它们的含义。
Transformer(谷歌):930美元
Transformer模型是现代AI的开创性架构之一,这种相对适中的成本,凸显了早期AI训练方法的效率。
它的成本,可以作为了解该领域在模型复杂性和相关费用方面进展的基准。
BERT-Large(谷歌):3,288美元
与前身相比,BERT-Large模型的训练成本大幅增加。
BERT以其对上下文表征的双向预训练而闻名,在自然语言理解方面取得了重大进展。然而,这一进展是以更高的财务成本为代价的。
RoBERTa Large(Meta):160美元
RoBERTa Large是BERT的一个变体,针对稳健的预训练进行了优化,其训练成本的跃升,反映了随着模型变得越来越复杂,计算需求也在不断提高。
这一急剧增长,凸显了与突破人工智能能力界限相关费用在不断上升。
LaMDA (谷歌): $1.3M美元
LaMDA旨在进行自然语言对话,代表了向更专业的AI应用程序的转变。
训练LaMDA所需的大量投资,凸显了对为特定任务量身定制的AI模型需求的不断增长,后者就需要更广泛的微调和数据处理。
GPT-3175B(davinci)(OpenAI):$4.3M
GPT-3以其庞大的规模和令人印象深刻的语言生成能力而闻名,代表了AI发展的一个重要里程碑。
训练GPT-3的成本,反映了训练如此规模的模型所需的巨大算力,突出了性能和可负担性之间的权衡。
Megatron-Turing NLG530B (微软/英伟达): $6.4M
训练Megatron-TuringNLG的成本,说明了具有数千亿个参数的更大模型的趋势。
这种模型突破了AI能力的界限,但带来了惊人的训练成本。它大大提高了门槛,让业领导者和小型参与者之间的差距越拉越大。
PaLM(540B)(谷歌):$12.4M
PaLM具有大量的参数,代表了AI规模和复杂性的巅峰之作。
训练PaLM的天文数字成本,显示出推动AI研发界限所需的巨大投资,也引发了人们的质疑:这类投资真的是可持续的吗?
GPT-4(OpenAI): $78.3M
GPT-4的预计训练成本,也标志着人工智能经济学的范式转变——AI模型的训练费用达到了前所未有的水平。
随着模型变得越来越大、越来越复杂,进入的经济壁垒也在不断升级。此时,后者就会限制创新,和人们对AI技术的可得性。
Gemini Ultra(谷歌):$191.4M
训练Gemini Ultra的惊人成本,体现了超大规模AI模型带来的挑战。
虽然这些模型表现出了突破性的能力,但它们的训练费用已经达到了天文数字。除了资金最充足的大公司之外,其余的企业和组织都被挡在了壁垒之外。
芯片竞赛:微软、Meta、谷歌和英伟达争夺AI芯片霸主地位
虽然英伟达凭借长远布局在芯片领域先下一城,但无论是AMD这个老对手,还是微软、谷歌、Meta等巨头,也都在奋勇直追,尝试采用自己的设计。

5月1日,AMD的MI300人工智能芯片销售额达到10亿美元,成为其有史以来销售最快的产品。
与此同时,AMD还在马不停蹄地加大目前供不应求的AI芯片的产量,并且预计在2025年推出新品。
4月10日,Meta官宣下一代自研芯片,模型训练速度将获巨大提升。
Meta训练和推理加速器(MTIA)专为与Meta的排序和推荐模型配合使用而设计,这些芯片可以帮助提高训练效率,并使实际的推理任务更加容易。
同在4月10日,英特尔也透露了自家最新的AI芯片——Gaudi3AI的更多细节。
英特尔表示,与H100GPU相比,Gaudi3可以在推理性能上获得50%提升的同时,在能效上提升40%,并且价格更便宜。
3月19日,英伟达发布了「地表最强」AI芯片——Blackwell B200。
英伟达表示,全新的B200GPU可以凭借着2080亿个晶体管,提供高达20petaflops的FP4算力。
不仅如此,将两个这样的GPU与一个Grace CPU结合在一起的GB200,可以为LLM推理任务提供比之前强30倍的性能,同时也可大大提高效率。
此外,老黄还曾暗示每个GPU的价格可能在3万到4万美元之间。
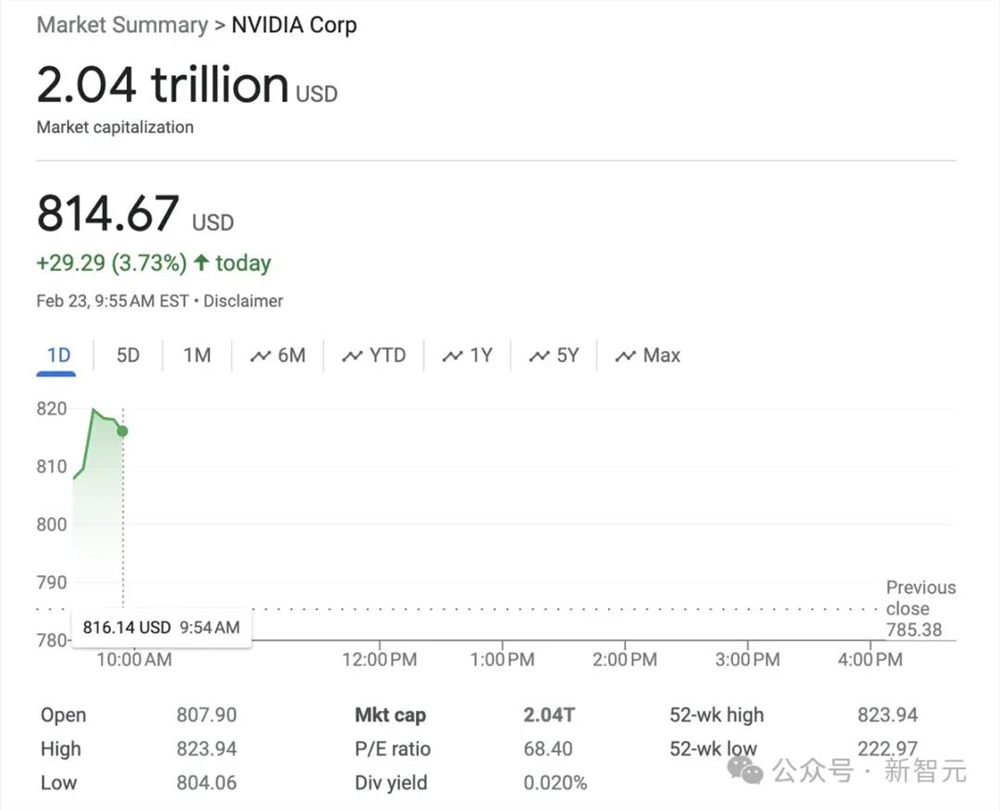
2月23日,英伟达市值一举突破2万亿美元,成为了首家实现这一里程碑的芯片制造商。
同时,这也让英伟达成为了美国第三家市值超过2万亿美元的公司,仅次于苹果(2.83万亿美元)和微软(3.06万亿美元)。
2月22日,微软和英特尔达成了一项数十亿美元的定制芯片交易。
据推测,英特尔将会为微软生产其自研的AI芯片。

2月9日,《华尔街日报》称Sam Altman的AI芯片梦,可能需要高达7万亿美元的投资。
「这样一笔投资金额将使目前全球半导体行业的规模相形见绌。去年全球芯片销售额为5270亿美元,预计到2030年将达到每年1万亿美元。」

参考资料:
https://twitter.com/tsarnick/status/1786189377804369942
https://www.youtube.com/watch?v=6RUR6an5hOY
https://twitter.com/zimmskal/status/1786012661815124024
https://symflower.com/en/company/blog/2024/dev-quality-eval-v0.4.0-is-llama-3-better-than-gpt-4-for-generating-tests/
https://techovedas.com/190-million-what-is-the-cost-of-training-ai-models-from-google-to-openai/
(举报)








发表评论取消回复