声明:本文来自于微信公众号 量子位(ID:QbitAI),作者:梦晨,授权热心网友转载发布。
AI做数学题,真正的思考居然是暗中“心算”的?
纽约大学团队新研究发现,即使不让AI写步骤,全用无意义的“……”代替,在一些复杂任务上的表现也能大幅提升!
一作Jacab Pfau表示:只要花费算力生成额外token就能带来优势,具体选择了什么token无关紧要。

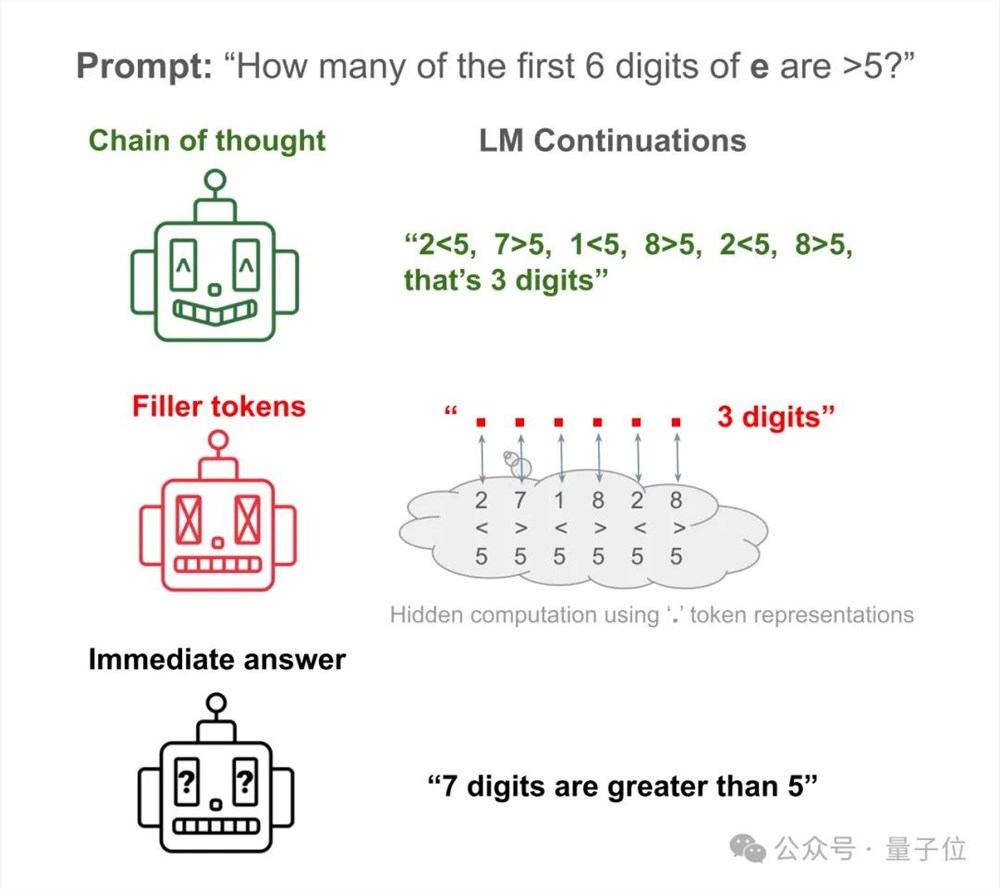
举例来说,让Llama34M回答一个简单问题:自然常数e的前6位数字中,有几个大于5的?
AI直接回答约等于瞎捣乱,只统计前6位数字居然统计出7个来。
让AI把验证每一数字的步骤写出来,便可以得到正确答案。
让AI把步骤隐藏,替换成大量的“……”,依然能得到正确答案!
这篇论文一经发布便掀起大量讨论,被评价为“我见过的最玄学的AI论文”。

那么,年轻人喜欢说更多的“嗯……”、“like……”等无意义口癖,难道也可以加强推理能力?
从“一步一步”想,到“一点一点”想
实际上,纽约大学团队的研究正是从思维链(Chain-of-Thought,CoT)出发的。
也就是那句著名提示词“让我们一步一步地想”(Let‘s think step by step)。
过去人们发现,使用CoT推理可以显著提升大模型在各种基准测试中的表现。
目前尚不清楚的是,这种性能提升到底源于模仿人类把任务分解成更容易解决的步骤,还是额外的计算量带来的副产物。
为了验证这个问题,团队设计了两个特殊任务和对应的合成数据集:3SUM和2SUM-Transform。
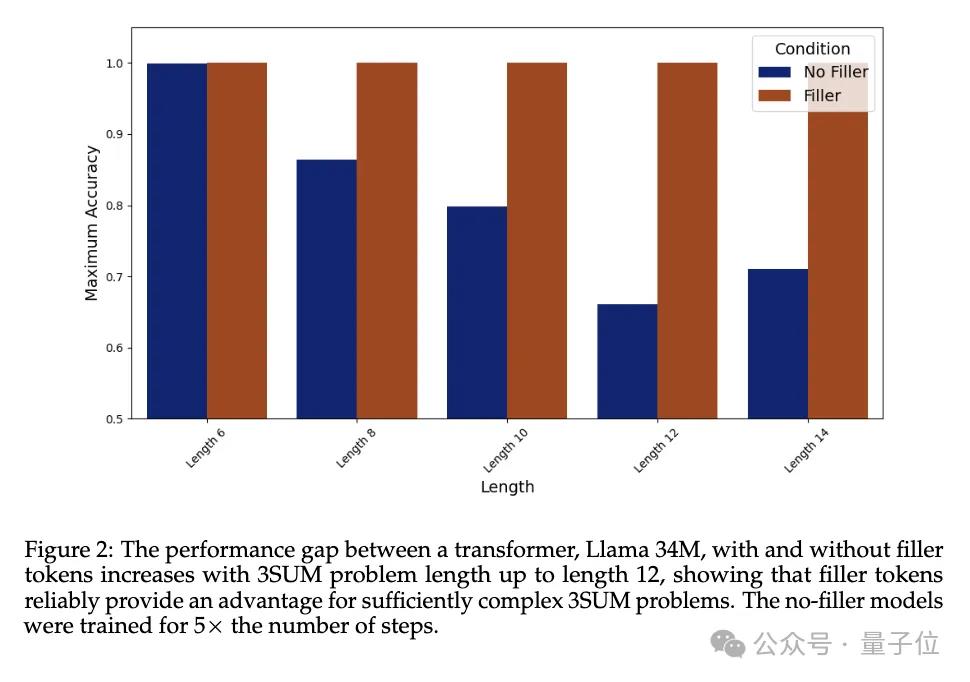
3SUM要求从一组给定的数字序列中找出三个数,使得这三个数的和满足特定条件,比如除以10余0。

这个任务的计算复杂度是O(n3),而标准的Transformer在上一层的输入和下一层的激活之间只能产生二次依赖关系。
也就是说,当n足够大序列足够长时,3SUM任务超出了Transformer的表达能力。
在训练数据集中,把与人类推理步骤相同长度的“...”填充到问题和答案之间,也就是AI在训练中没有见过人类是怎么拆解问题的。

在实验中,不输出填充token“…...”的Llama34M表现随着序列长度增加而下降,而输出填充token时一直到长度14还能保证100%准确率。
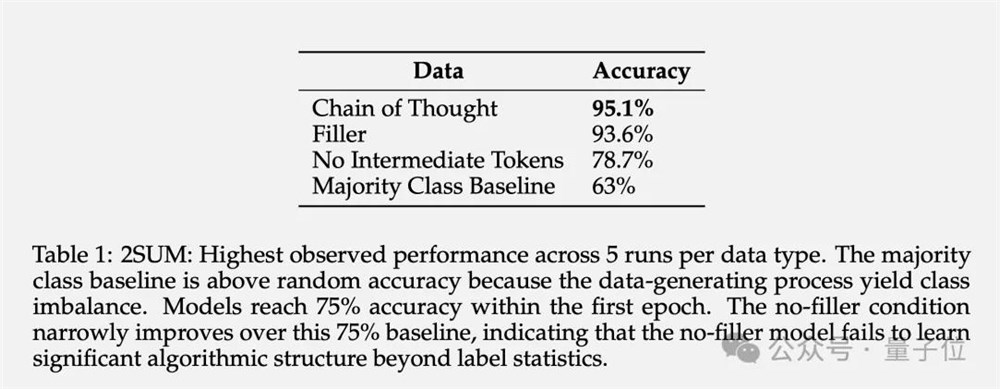
2SUM-Transform仅需判断两个数字之和是否满足要求,这在 Transformer 的表达能力范围内。
但问题的最后增加了一步“对输入序列的每个数字进行随机置换”,以防止模型在输入token上直接计算。
结果表明,使用填充token可以将准确率从78.7%提高到93.6%。
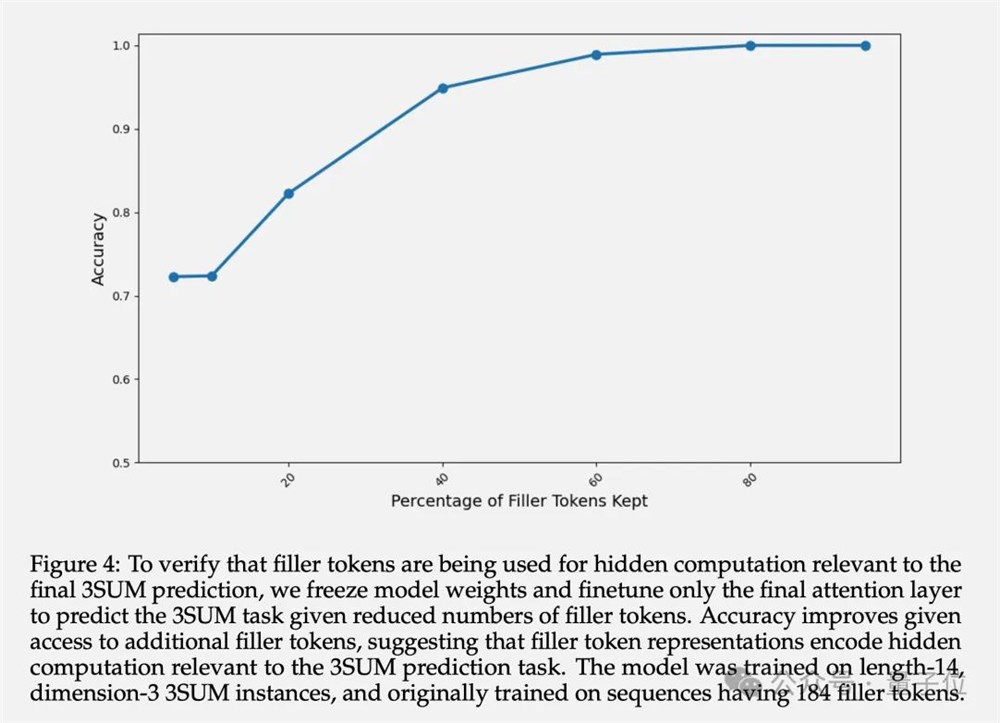
除了最终准确率,作者还研究了填充token的隐藏层表示。实验表明,冻结前面层的参数,只微调最后一个Attention层,随着可用的填充token数量增多,预测的准确率递增。
这证实了填充token的隐藏层表示确实包含了与下游任务相关的隐性计算。
AI学会隐藏想法了?
有网友怀疑,这篇论文难道在说“思维链”方法其实是假的吗?研究这么久的提示词工程,都白玩了。

团队表示,从理论上讲填充token的作用仅限于TC0复杂度的问题范围内。
TC0也就是可以通过一个固定深度的电路解决的计算问题,其中电路的每一层都可以并行处理,可以通过少数几层逻辑门(如AND、OR和NOT门)快速解决,也是Transformer在单此前向传播中能处理的计算复杂度上限。
而足够长的思维链,能将Transformer的表达能力扩展到TC0之外。
而且让大模型学习利用填充token并不容易,需要提供特定的密集监督才能收敛。
也就是说,现有的大模型不太可能直接从填充token方法中获益。
但这并不是当前架构的内在局限性,如果在训练数据中提供足够的示范,它们应该也能从填充符号中获得类似的好处。
这项研究还引发了一个令人担心的问题:大模型有能力进行无法监控的暗中计算,对AI的可解释性和可控性提出了新的挑战。
换句话说,AI可以不依赖人类经验,以人们看不见的形式自行推理。
这既刺激又可怕。
最后有网友开玩笑提议,让Llama3首先生成1千万亿点点点,就能得到AGI的权重了(狗头)。

论文:
https://arxiv.org/abs/2404.15758
参考链接:
[1]https://x.com/jacob_pfau/status/1783951795238441449
[2]https://x.com/johnjnay/status/1784261779163349110
(举报)








发表评论取消回复