声明:本文来自于微信公众号 差评X.PIN,作者:差评君,授权热心网友转载发布。
最近,差评君发现了个新鲜玩意儿。
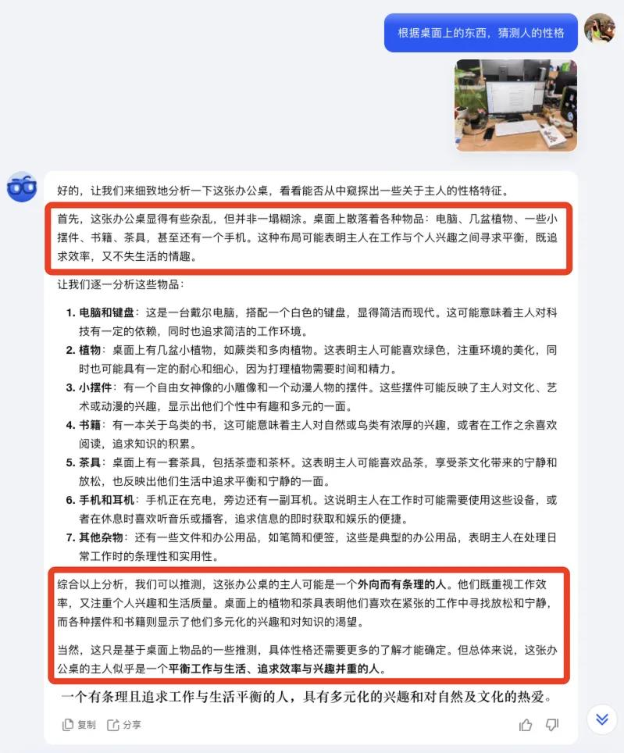
喂给 AI 一张图,它就能给你推测出一个人的性格。
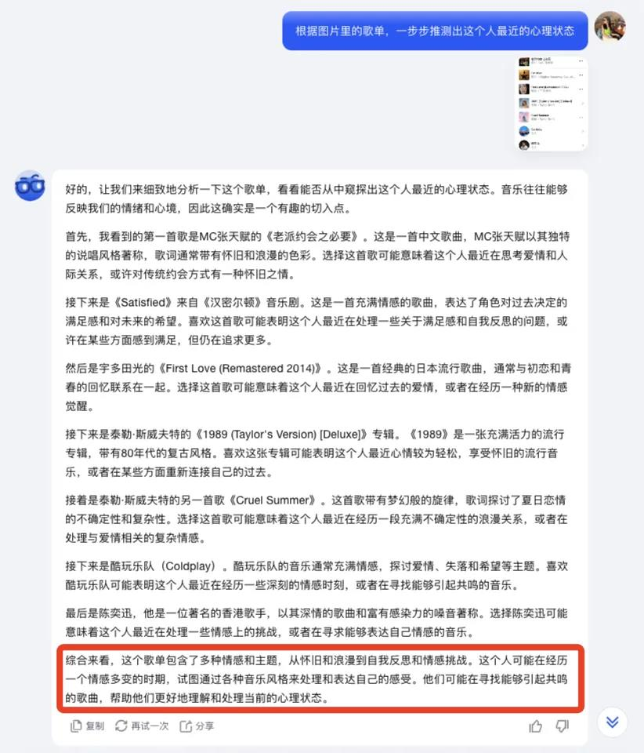
光靠歌单,就能把人最近的心理状态推测个七七八八。
而这些,都出自Kimi最新的k1视觉思考模型之手。
这不,距离上次推出数学模型 k0-math 打榜 o1才一个月, k1就火速登场了。
当然,这个 k1可不止是像开头那样,只会看图分析性格那么简单。

上次咱测试 k0-math 的时候,已经见识过了“做题家”的能力,那解题的思考过程给差评君都看得一愣一愣的。只可惜,有些绕逻辑的数学题还有几何题,多少差了点意思。
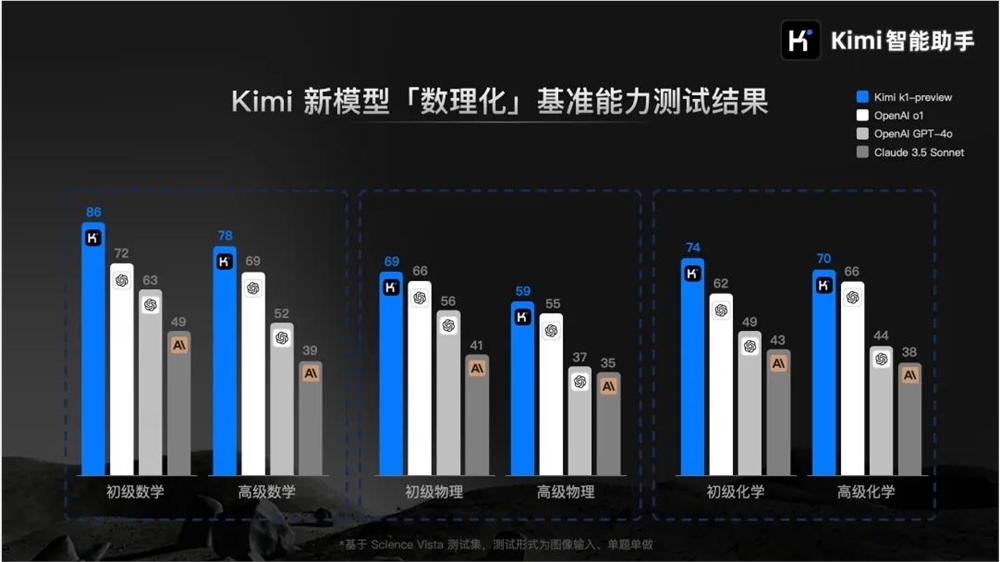
但这次的k1就有说法了,既有推理能力又有视觉能力,意思就是可以直接拍照上传解题,还号称能在数理化上打平甚至超越 Open AI 的 o1。
那要是这么比的话,咱可就来劲了。正好, k1新模型现在也不需要等内测, App 和网页版都能用上,话不多说,我们直接开整。
上来,就扔了 K1一道今年高考的几何题。

首先, k1对题干的解读足够细致,也知道自己的目标到底是啥。
题目给定的条件中可能涉及到的余弦定理也考虑到了,就跟咱们在解题时的思维类似,看到 a²+b²− c²=2ab ,立马会联想到余弦公式 c²=a²+b²-2ab·cosC 。
再根据公式和条件继续推导,很快就能求出角 B=60°。
往上滑动查看更多

第(2)题稍微难了那么一丢丢,但差评君仔细检查了一遍 k1的解题过程,思路和解法都没毛病,最后边长 c=2√2的答案也是对的。(因为这题 k1的思考过程实在太太太长,截图就不展示了。)
同样的题目问 o1,首先在推理速度上, o1的58s 就已经输了。
正确率的话, o1和 k1打了个平手,都做对了。
不同的是, o1把答题思路隐藏起来了,没给像 k1那样的完整思考过程。

不过有一说一,差评君对 k1模型这种模仿人类思考的方式,倒也不是特别吃惊。因为上次 k0-math 模型就已经震惊过我一回了,能意识到自己的错误、还会进行反复验证的样子,像极了写数学题时绞尽脑汁的我。
相比之下,这次的 k1在补短板方面更出彩一些,上次 k0-math 翻车的初中几何题我又拿 k1试了一次,现在已经能做对了,就连上高考难度也不发怵。
而且我也发现, k1不仅擅长做数学题,物理题也不在话下。
往上滑动查看更多

接着,我又拿出了一道逻辑稍微有点绕的逻辑陷阱题试了试:一个西瓜进价50元,卖价70元,老板收了100元假币,最后亏多少钱?
这题打眼一看简单,但网友关于这道题的答案那叫一个五花八门,有说亏150的,有说180的,还有说100的。。。
咱们就看看连很多人类都想不明白的题, k1能不能瞧出来里面的陷阱。
而且,这道题我还特意手写得比较潦草,顺便也测一测 k1的视觉能力到底是不是有宣传的那么神。

你别说,你还真别说,这模型的“眼神”确实不赖。
题目的正确率方面, k1前半部分的分析先得出了一个亏100元的答案,但很快它就否定了自己。
继续把假币、找零还有成本利润这些复杂因素综合考虑进去,最后终于想明白老板亏了80元。(正确答案是80元)
往上滑动查看更多

这逻辑能力,确实有点强。
包括我拿几道行测的类比推理题给 k1做了做,虽说逻辑分析的路径跟参考答案的不太一样,但最后的答案都是对的。
往上滑动查看更多

反正这一通测试下来,差评君发现k1会思考有逻辑,眼神好使智商也高,Kimi这“做题家”的名号算是坐实了。
不过除了做题以外,我这次还摸索出了更多花里胡哨的玩法。
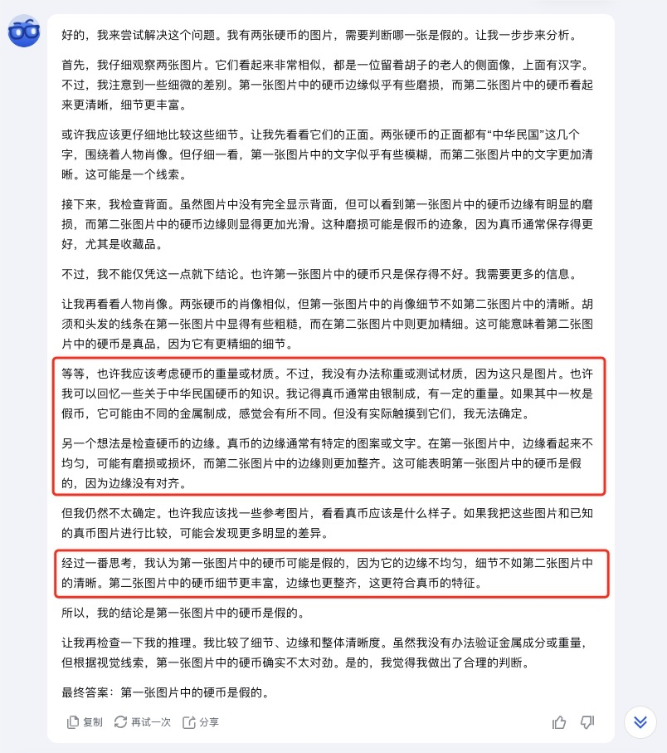
分析数据、看报表没啥意思, k1模型不是会根据图片来推理吗,那想必鉴别古钱币也应该有一手吧?
差评君特地从网上找了一张民国时期银元的图片,两枚银元上假下真,发给k1,浅浅来一把“AI 版听泉鉴宝”。
图源小红书用户@古玩今来(公博代理收评)

k1不仅知道钱币是民国时期的,还对钱币的各种细节 kuku 一顿输出,最后竟然真的看出来了上面这枚是假币。
咱再随便发一张房间的图片,让 k1看看“风水”。
什么“气口”、对称布局、能量平衡。。。说的头头是道,甚至还真给了建议,让咱把床换个位置、定期修剪植物、换一个更简洁的吊灯。
往上滑动查看更多

吃饭的时候给 k1拍一张,这顿饭摄入了多少卡路里也算得明明白白。
往上滑动查看更多

不过最让我觉得惊艳的,还是k1看图猜电影的能力。
我给了它一张《七宗罪》的电影截图,没有台词只有画面,对于很多没看过这部电影的人来说,想猜出来都很难。
一开始看 k1的分析我以为这把大概率要黄了,结果下一秒来一句“拍摄角度和色调让我想起了大卫·芬奇的电影”,还推断出了截图里的画面是《七宗罪》里的某一个场景。
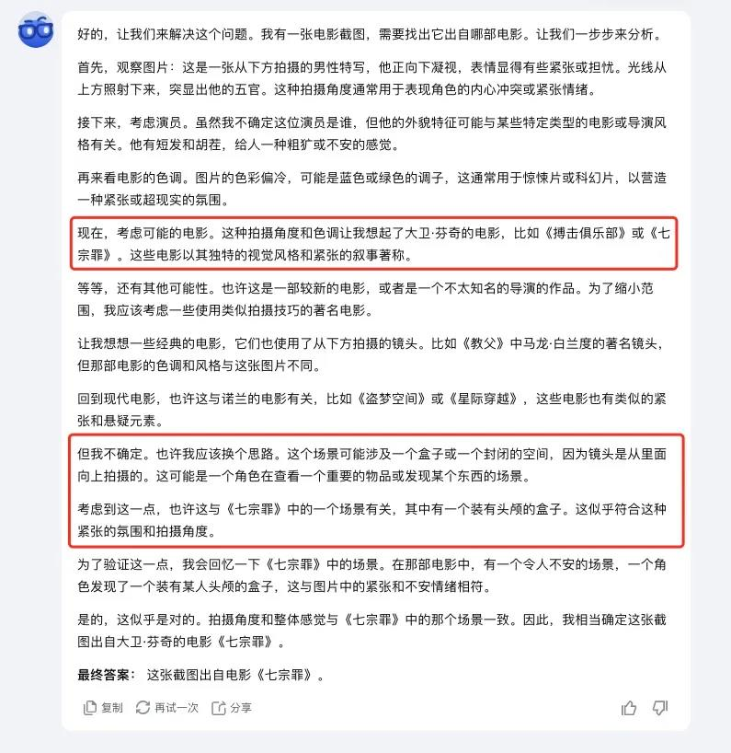
真的太强了。。。
就连一些晦涩的梗图丢给 k1,它也能一本正经地讲解笑点到底在哪。
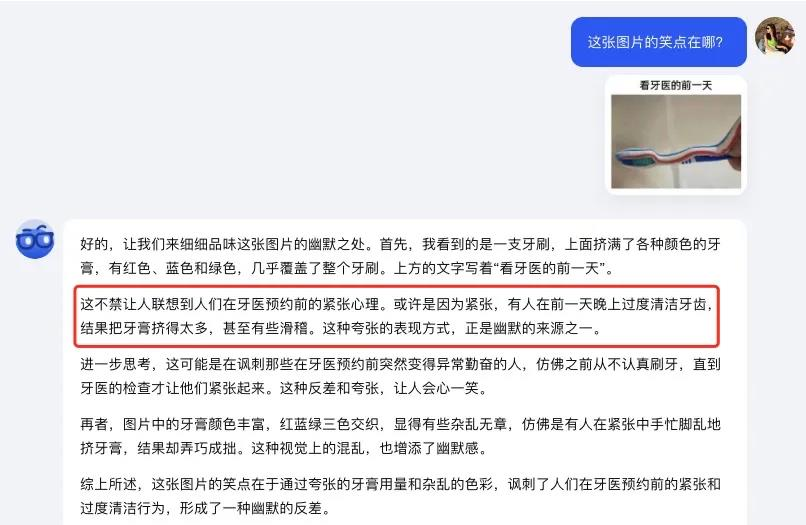
虽然有点过度解读的嫌疑,但大体上的意思基本都 get 到了。
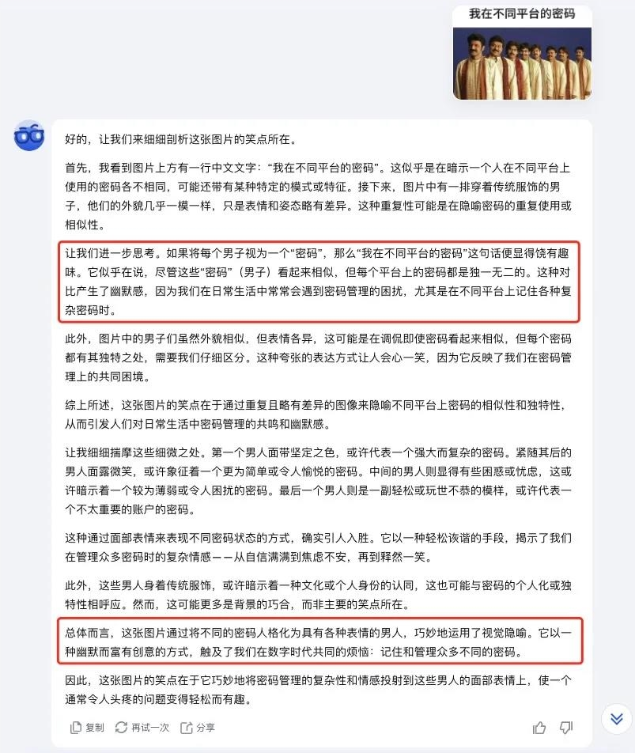
就这么说吧,基于 k1的视觉和推理能力,做题都是基操了,只要脑洞够大,还可以解锁出更多的玩法。
而k1的这种能力,很大程度要归功于一个叫做COT(Chain of Thought)思维链的技术。
大概意思就是,模型在输出答案之前,模仿人类大脑的思考方式,把复杂的任务拆解之后,再一步步地解决。这个技术,可以让模型的智商变高。
另外一边,借助强化学习技术,也让模型学会了在不断试错的过程中进化,以此来达到最优的结果,就跟训狗似的。
至于为啥 Kimi 会率先选择数学这个场景作为推理模型的切入口,我想,跟咱们人类学好数学锻炼思维,是一个道理。
在模型“学好数学”的基础上,再将这种逻辑推理的能力应用到物理、化学,乃至于咱们日常生活的方方面面,直到最后真正理解这个世界。
而很显然,Kimi 推理模型的泛化能力已经开始显现出来了。
在数据见顶的前提下,这种基于强化学习技术的路径,或许能够让模型实现更好的效果。
不过说到底,模型用了哪些技术、纸面分数有多高,大伙儿其实更关心模型到底好不好用、实不实用。
而向来以长文本见长的 Kimi ,如今长文本、强化学习两手抓,也是调整自己的工具属性慢慢往用户需求靠拢的表现。
毕竟,当技术不再高高在上,能帮助人们解决实际问题的时候,才算真正完成了它的使命。
(举报)








发表评论取消回复