今天凌晨2点,OpenAI开启了第9天技术分享直播,正式发布了o1模型的API,并且对实时API进行大升级支持WebRTC。
其中,o1模型的API与之前的预览版本相比,思考成本降低了60%,并且附带高级视觉功能;GPT-4o的音频成本降低60%,而mini版本价格更是暴降了10倍。
同时OpenAI还发布了全新的偏好微调方法,通过直接偏好优化算法可以让大模型更好地掌握用户的偏好风格。

o1模型API
今天发布的正式版本o1模型API还集成了很多新功能,包括函数调用、结构化输出、开发者消息以及推理工作量。
函数调用允许模型根据输入数据自动调用相应的后端服务或外部API,实现复杂任务处理能力;结构化输出支持JSON格式的数据返回,确保输出结果符合预期结构,方便后续解析与应用;
开发者消息是一种新型系统消息形式,赋予开发者更大的控制权来指导模型行为;而推理工作量参数用于调整模型思考时间,平衡性能与准确性之间的关系。
在演示环节中,OpenAI展示了一款基于高级视觉功能的应用案例,检测错误表单。通过上传填写有误的文本表格图片,o1模型成功识别出了其中存在的计算错误,并提供了详细的修正建议。
此外,对于某些需要精确执行的任务,o1模型还可以借助内置函数库与后台服务器通信,获取最新税率等信息,确保最终结果的准确性和时效性。
实时API增强、支持WebRTC,极大简化开发流程
WebRTC是一种为互联网构建的实时通信技术,主要应用于会议和低延迟视频流传输等领域。OpenAI在实时API中支持WebRTC,使开发的AI应用能够自动处理互联网变化,例如,调整比特率和回声消除,为实时语音应用带来更好的性能和稳定性。
与之前的 Websockets 集成相比,WebRTC 支持显著简化了代码。使用 Websockets 时,开发者需要处理200-250行代码来解决反压等问题。而采用 WebRTC,仅需12行代码即可实现相同功能。
例如,在实时语音聊天应用中,WebRTC 的使用使开发者能够更快速地构建功能强大的应用程序,提高开发效率。
在演示环节中,通过简单的 HTML 代码创建对等连接,实现了音频流的发送和接收,展示了 WebRTC 支持下实时语音应用开发的便捷性。开发者只需关注应用逻辑,无需处理复杂的网络通信细节,大大降低了开发难度。
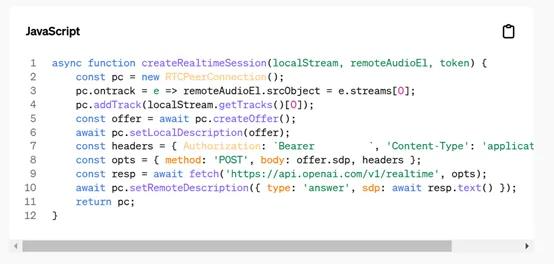
此外,为了进一步方便开发者集成实时 API,OpenAI推出了Python SDK支持,同时大幅度降低价格。
偏好微调
偏好微调与传统的监督式微调有很大的不同,采用成对样本比较学习的方式,使模型能够理解并适应特定应用场景中的细微差异。在实施偏好微调时,开发者首先需要准备一组包含两个不同版本回答的数据集,其中一个被认为是更优的选择。
然后,将这些数据送入模型进行训练,使其学会区分好坏答案之间的差异,并根据用户的反馈不断调整自己的行为准则。
偏好微调特别适合那些对回答格式、语气或者抽象特质(如友好度、创造力)有较高要求的应用场合。例如,在构建金融咨询聊天机器人时,开发团队不仅希望模型能够提供专业且准确的财务建议,还期望它能保持友好和易于理解的沟通方式。

此时就可以利用偏好微调方法,向模型展示多种不同的对话示例,直至找到最理想的表达方式为止。这种方法确实能够显著改善模型的表现,尤其是在涉及主观评价的任务上,客户服务或个性化推荐系统。
另外,偏好微调不仅仅局限于文本生成任务,同样适用于其他类型的输出,如图像生成、代码补全等。通过对大量样例的学习,模型可以逐渐形成一套稳定的行为模式,以更好地满足用户需求。更重要的是,这种微调方式允许持续迭代和改进,随着更多高质量数据的积累,模型的表现也会随之提高。
目前,这些API已经普遍可用,更详细内容可以去OpenAI开发论坛查看。
(举报)








发表评论取消回复