声明:本文来自于微信公众号量子位 | 公众号 QbitAI,作者:金磊,授权热心网友转载发布。
Meta的视频版分割一切——Segment Anything Model2(SAM2),又火了一把。
因为这一次,一个全华人团队,仅仅是用了个经典方法,就把它的能力拔到了一个新高度——
任你移动再快,AI跟丢不了一点点!
例如在电影《1917》这段画面里,主角穿梭在众多士兵之中,原先的SAM2表现是这样的:

嗯,当一大群士兵涌入画面的时候,SAM2把主角给跟丢了。
但改进版的SAM2,它的表现截然不同:

这个改进版的SAM2,名叫SAMURAI(武士),由华盛顿大学全华人研究团队提出。
一言蔽之,这项工作就是把SAM2之前存在的缺点(记忆管理方面的局限性)给填补上了。

更有意思的是,这项改进工作所用到的核心关键方法,是非常经典的卡尔曼滤波器(Kalman Filter,KF)。
并且还是无需重新训练、可以实时运行的那种!
前谷歌产品经理、国外知名博主Bilawal Sidhu在看完论文后直呼“优雅”:
有时候你不需要复杂的全新架构——只需要聪明地利用模型已知的信息,再加上一些经过验证的经典方法。
我们的“老朋友”卡尔曼滤波器,这么多年过去了,它的表现依然如此出色。有时候老派的方法就是管用。

嗯,颇有一种“姜还是老的辣”的感觉了。
黑悟空、女团舞蹈,统统都能hold住
我们先继续看下SAMURAI能力实现的更多效果。
团队在项目主页中便从多个不同维度秀了一波实力。
首先就是打斗游戏场景,例如在《只狼:影逝二度》中,即便人物都“弹出”了画面,SAMURAI也能再次把目标捕捉回来:

《黑神话:悟空》的打斗名场面,人物动作变化可以说是非常之快,而且和背景非常复杂的交织在一起。
即便如此,SAMURAI也能精准跟踪,细节到金箍棒的那种:

但毕竟这两个游戏场景的例子,所涉及到的主体还不够多,那么我们接下来继续看下更复杂的case。
例如橄榄球比赛场景,不仅人物移动的快,后来队员们都扑到了一起,SAMURAI也能hold住:

在女团舞蹈的案例中,人物在变换队形的时候都已经被其他队员挡住了,也挡不住SAMURAI的“眼神锁定你”:
很work的经典方法
在看完效果之后,我们接下来扒一扒SAMURAI的技术细节。
正如我们刚才提到的,这项工作弥补了SAM2此前存在的缺点。
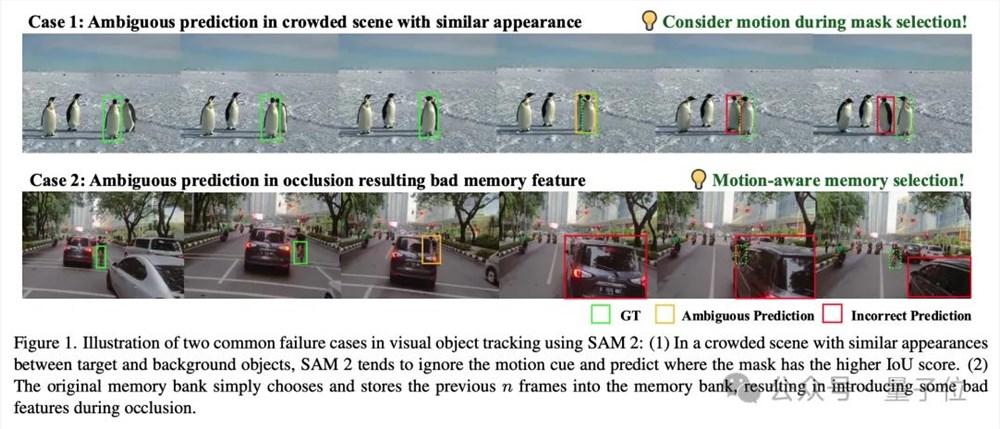
主要的问题就是处理视觉目标跟踪时,尤其是在拥挤场景中快速移动或遮挡的物体时,它会出现跟丢了的情况。
SAM2的组成部分包括图像编码器、掩码解码器、提示编码器、记忆注意力层和记忆编码器。
在视觉目标跟踪中,SAM2使用提示编码器来处理输入的提示信息,如点、框或文本,这些提示信息用于指导模型分割图像中的特定对象。
掩码解码器则负责生成预测的掩码,而记忆注意力层和记忆编码器则用于处理跨帧的上下文信息,以维持长期跟踪。
然而,SAM2在处理快速移动的对象或在拥挤场景中,往往忽视了运动线索,导致在预测后续帧的掩码时出现不准确。
特别是在遮挡发生时,SAM2倾向于优先考虑外观相似性而非空间和时间的一致性,这可能导致跟踪错误。
而SAMURATI,作为SAM2的增强版,可以说是很好地解决了此前的痛点。
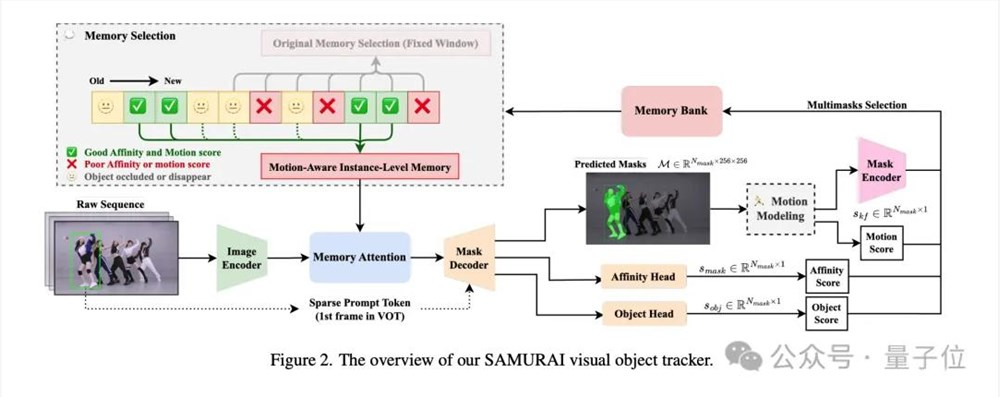
整体来看,SAMURAI主要包含两个技术关键点:
运动建模(Motion Modeling)
运动感知记忆选择(Motion-Aware Memory Selection)
让目标“动”起来
运动建模部分的目的是有效地预测目标的运动,从而在复杂场景中,如拥挤场景或目标快速移动和自遮挡的情况下,提高跟踪的准确性和鲁棒性。
而这里用到的具体方法,就是那个经典的卡尔曼滤波器,以此来增强边界框位置和尺寸的预测,从而帮助从多个候选掩码中选择最有信心的一个。
在SAMURAI中,状态向量包括目标的位置、尺寸及其变化速度;通过预测-校正循环,卡尔曼滤波器能够提供关于目标未来状态的准确估计。
目标的状态向量被定义为:
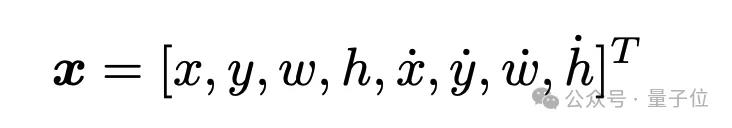
其中,x和y表示目标边界框的中心坐标;w和h表示边界框的宽度和高度;后四个变量则表示坐标与尺寸的速度。
滤波的过程则主要分为两个步骤。
第一个就是预测阶段,即根据目标的上一帧状态,预测下一帧位置:
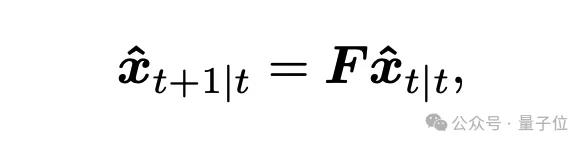
其中,F是状态转移矩阵。
第二个则是更新阶段,会结合实际测量值(目标的候选掩膜),校正预测值:
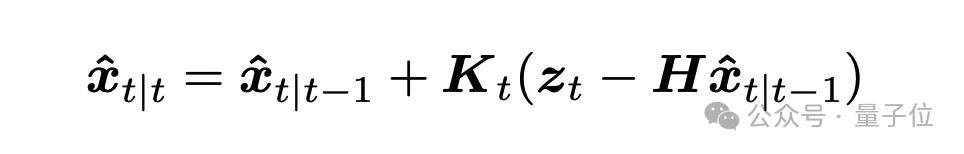
在运动建模部分,除了基于卡尔曼滤波器的运动预测之外,还涉及运动分数(Motion Score)。
主要是通过计算 Kalman 滤波器预测的边界框与候选掩膜之间的交并比(IoU),生成运动分数sKf,用以辅助掩膜选择:
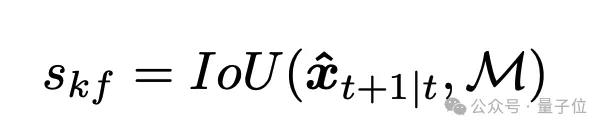
最终的掩膜选择基于运动分数与掩膜亲和分数的加权和:
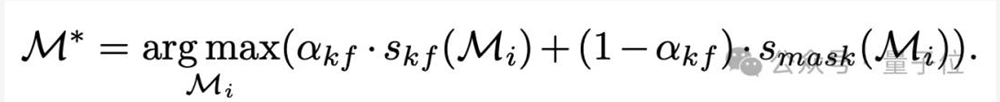
挑出最关键的记忆
SAMURAI第二个关键技术,则是运动感知记忆选择(Motion-Aware Memory Selection)。
主要是为了解决SAM2的固定窗口记忆机制容易引入错误的低质量特征,导致后续跟踪的误差传播的情况。
这部分首先涉及一个混合评分系统,包括掩膜分数、目标出现分数和运动分数三种评分,用于动态选择记忆库中最相关的帧。
掩膜分数smask:衡量掩膜的准确性。
目标出现分数 sobj:判断目标是否存在于该帧中。
运动分数 skf:预测目标位置的准确性。
其次是一个记忆选择机制——
如果某帧满足以下条件,则其特征会被保留到记忆库中:
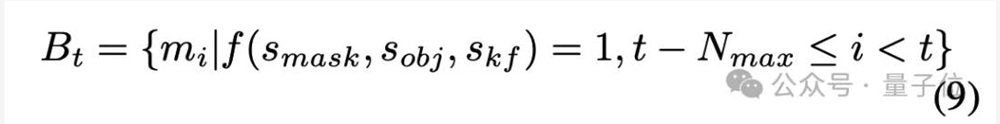
动态选择的记忆库可以跳过遮挡期间的低质量特征,从而提高后续帧的预测性能。
从实验结果来看,SAMURAI在多个视觉目标跟踪基准上表现出色,包括 LaSOT、LaSOText和GOT-10k数据集。
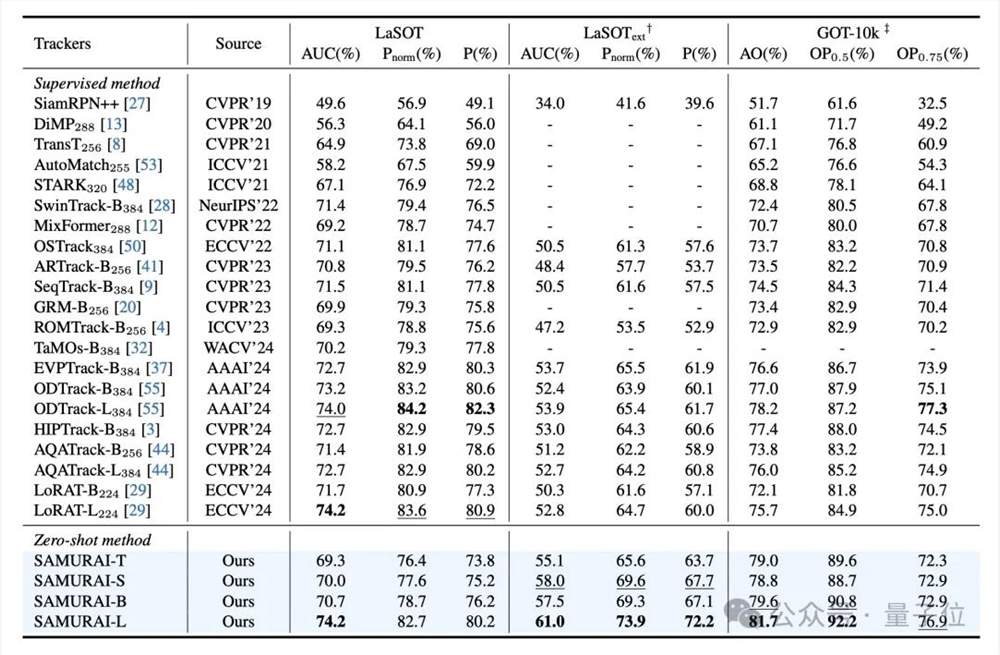
值得一提的是,SAMURAI是在无需重新训练或微调的情况下,在所有基准上都超过了SAM2,并与部分有监督方法(如 LoRAT 和 ODTrack)表现相当。
全华人团队出品
SAMURAI这项工作背后的研究团队,有一个亮点便是全华人阵容。
例如Cheng-Yen Yang,目前是华盛顿大学电气与计算机工程系的一名四年级博士生。
研究方向主要包括在复杂场景(水下,无人机,多相机系统)中的多目标跟踪(单视图,多视图,交叉视图)。

Hsiang-Wei Huang和Zhongyu Jiang也是华盛顿大学电气与计算机工程系的博士生,而Wenhao Chai目前则是攻读研究生。
他们的导师是华盛顿大学教授Jenq-Neng Hwang。
他是IEEE信号处理协会多媒体信号处理技术委员会的创始人之一,自2001年以来,黄教授一直是IEEE院士。
关于SAMURAI更多内容,可戳下方链接。
项目地址:
https://yangchris11.github.io/samurai/
论文地址:
https://arxiv.org/abs/2411.11922
参考链接:
[1]https://x.com/EHuanglu/status/1860090091269685282
[2]https://x.com/bilawalsidhu/status/1860348056916369881
(举报)








发表评论取消回复