声明:本文来自于微信公众号 机器之心,作者:机器之心,授权热心网友转载发布。
开源模型阵营又迎来一员猛将:Tülu3。它来自艾伦人工智能研究所(Ai2),目前包含8B 和70B 两个版本(未来还会有405B 版本),并且其性能超过了 Llama3.1Instruct 的相应版本!长达73的技术报告详细介绍了后训练的细节。
在最近关于「Scaling Law 是否撞墙」的讨论中,后训练(post-training)被寄予厚望。
众所周知,近期发布的 OpenAI o1在数学、 代码、长程规划等问题上取得了显著提升,而背后的成功离不开后训练阶段强化学习训练和推理阶段思考计算量的增大。基于此,有人认为,新的扩展律 —— 后训练扩展律(Post-Training Scaling Laws) 已经出现,并可能引发社区对于算力分配、后训练能力的重新思考。
不过,对于后训练到底要怎么做,哪些细节对模型性能影响较大,目前还没有太多系统的资料可以参考,因为这都是各家的商业机密。
刚刚,曾经重新定义「开源」并发布了史上首个100% 开源大模型的艾伦人工智能研究所(Ai2)站出来打破了沉默。他们不仅开源了两个性能超过 Llama3.1Instruct 相应版本的新模型 ——Tülu38B 和70B(未来还会有405B 版本),还在技术报告中公布了详细的后训练方法。
Ai2研究科学家 Nathan Lambert(论文一作)的推文
这份70多页的技术报告可以说诚意满满,非常值得详细阅读:

Tülu3发布后,社区反响热烈,甚至有用户表示测试后发现其表现比 GPT-4o 还好。
另外,Nathan Lambert 还暗示未来可能基于 Qwen 来训练 Tülu 模型。
机器之心也简单测试了下 Tülu。首先,数 Strawberry 中 r 数量的问题毫无意外地出错了,至于其编写的笑话嘛,好像也不好笑。
本地部署 AI 模型的工具 Ollama 也第一时间宣布已经支持该模型。
机器之心也简单通过 Ollama 和 Obsidian 的插件简单体验了一下8B 的本地版本,看起来效果还不错,速度也很快。
不过,比模型性能更值得关注的或许还是 Tülu3的后训练方案。在这套方案的启发下,众多研究者有望在大模型的后训练阶段进行更多尝试,延续大模型的 Scaling Law。
首个发布后训练详情的开源模型
在提升模型性能方面,后训练的作用越来越大,具体包括微调和 RLHF 等。此前,OpenAI、 Anthropic、Meta 和谷歌等大公司已经大幅提升了其后训练方法的复杂度,具体包括采用多轮训练范式、使用人类数据 + 合成数据、使用多个训练算法和训练目标。也正因为此,这些模型的通用性能和专业能力都非常强。但遗憾的是,他们都没有透明地公开他们的训练数据和训练配方。
到目前为止,开源后训练一直落后于封闭模型。在 LMSYS 的 ChatBotArena 排行榜上,前50名(截至2024年11月20日)中没有任何一个模型发布了其后训练数据。即使是主要的开放权重模型也不会发布任何数据或用于实现这种后训练的配方细节。
于是,Ai2似乎看不下去了,决定开源一切!
Tülu3模型之外,Ai2还发布了所有的数据、数据混合方法、配方、代码、基础设施和评估框架!

模型:https://huggingface.co/allenai
技术报告:https://allenai.org/papers/tulu-3-report.pdf
数据集:https://huggingface.co/collections/allenai/tulu-3-datasets-673b8df14442393f7213f372
GitHub:https://github.com/allenai/open-instruct
Demo:https://playground.allenai.org/
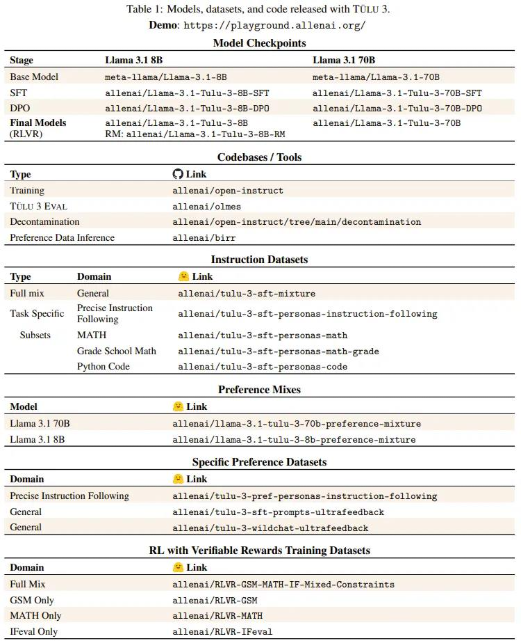
下表展示了 Ai2开源的模型、数据集和代码:
Ai2表示,Tülu3突破了后训练研究的界限,缩小了开放和封闭微调配方之间的性能差距。
为此,他们创建了新的数据集和新的训练流程。他们还提出了直接使用强化学习在可验证问题上训练的新方法,以及使用模型自己的生成结果创建高性能偏好数据的新方法。
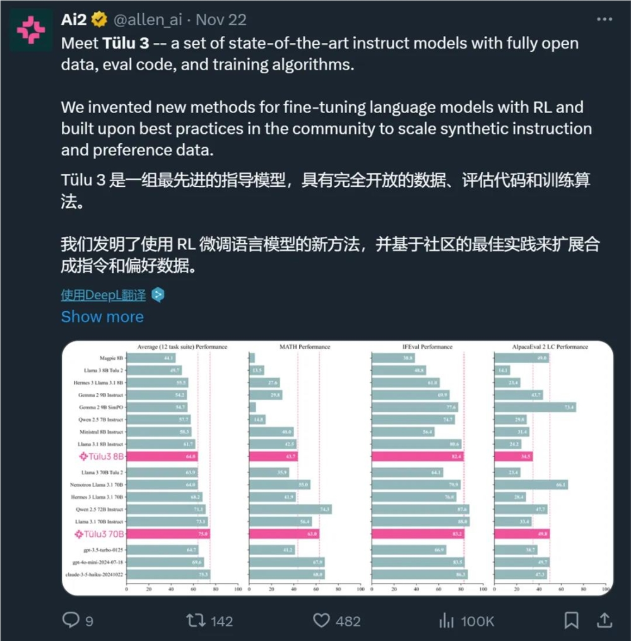
加上更多优化细节,得到的 Tülu3系列模型明显优于同等规模的其它模型。
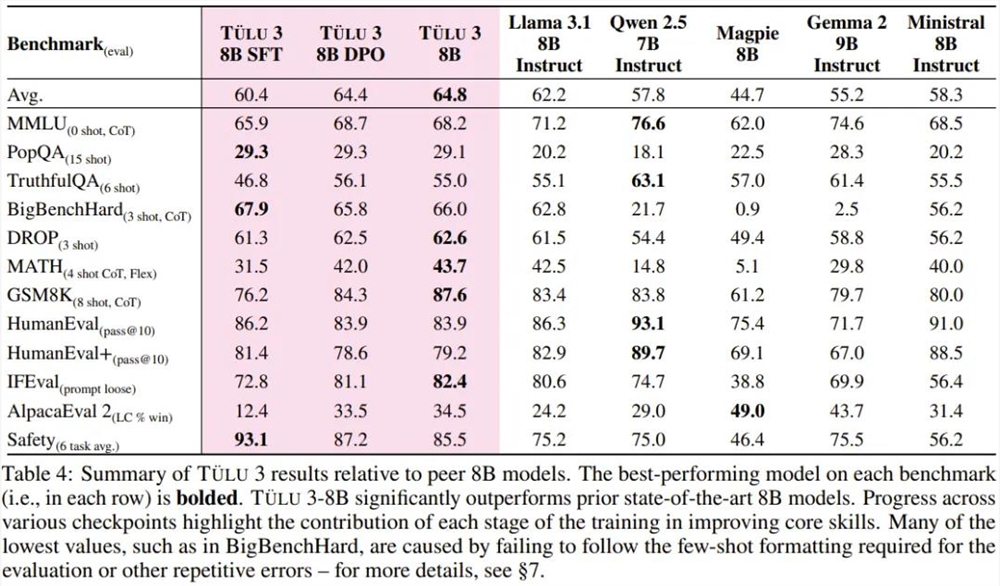
8B 模型在各基准上的表现
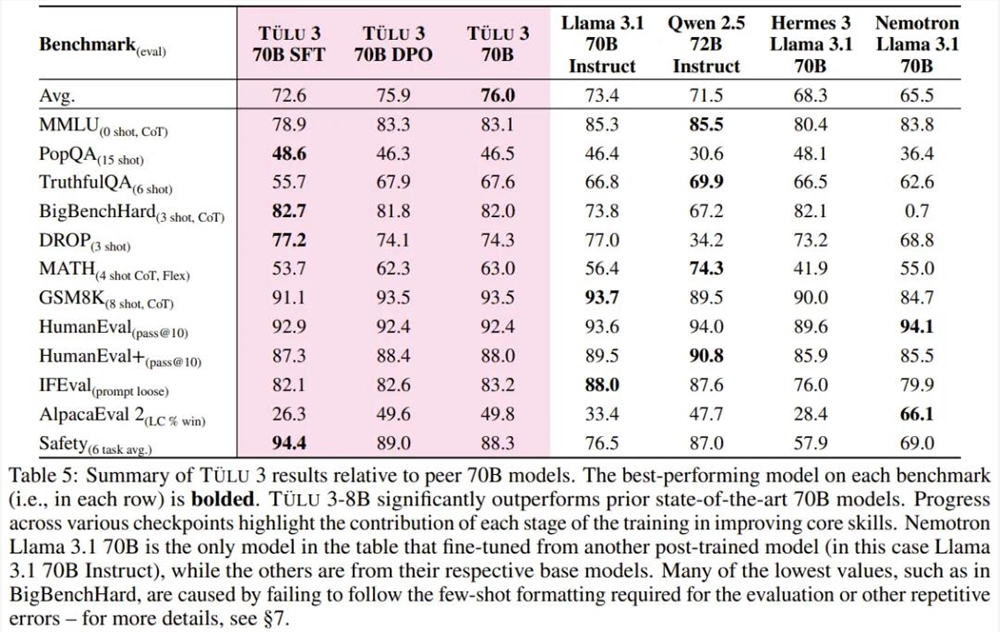
70B 模型在各基准上的表现
Tülu3是如何炼成的?
Ai2在预训练语言模型的基础上,通过四个阶段的后训练方法生成 Tülu3模型(见图1)。这套训练流程结合了强化学习中的新算法改进、尖端基础设施和严格的实验,以便在各个训练阶段整理数据并优化数据组合、方法和参数。
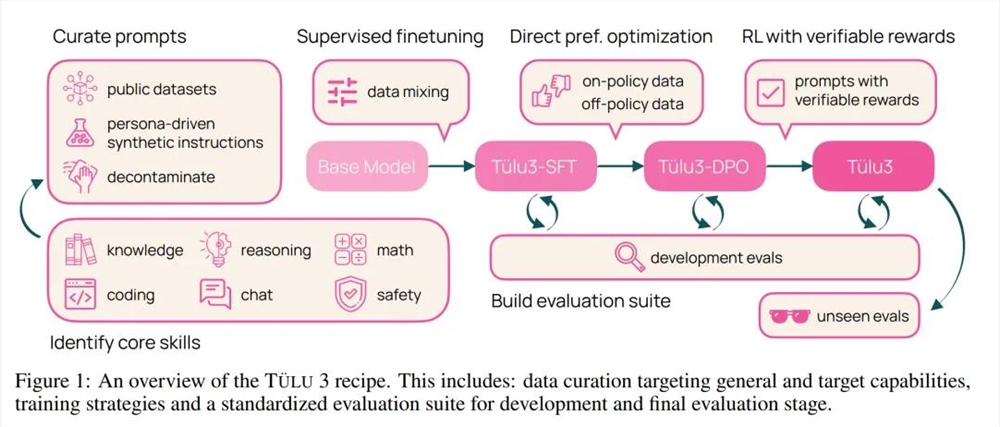
这些阶段如下:
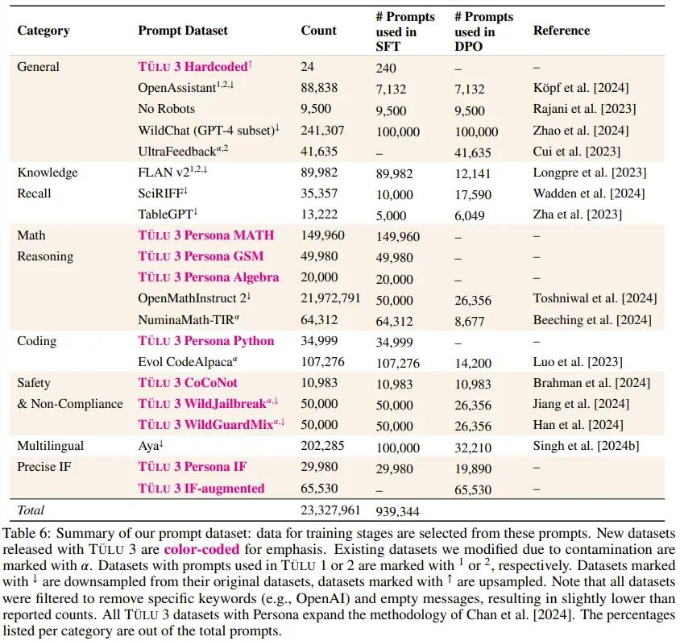
阶段一:数据整理。Ai2整理了各种提示(prompt)信息,并将其分配到多个优化阶段。他们创建了新的合成提示,或在可用的情况下,从现有数据集中获取提示,以针对特定能力。他们确保了提示不受评估套件 Tülu3EVAL 的污染。
阶段二:监督微调。Ai2利用精心挑选的提示和回答结果进行监督微调(SFT)。在评估框架指导下,他们通过全面的实验,确定最终的 SFT 数据和训练超参数,以增强目标核心技能,同时不对其他技能的性能产生重大影响。
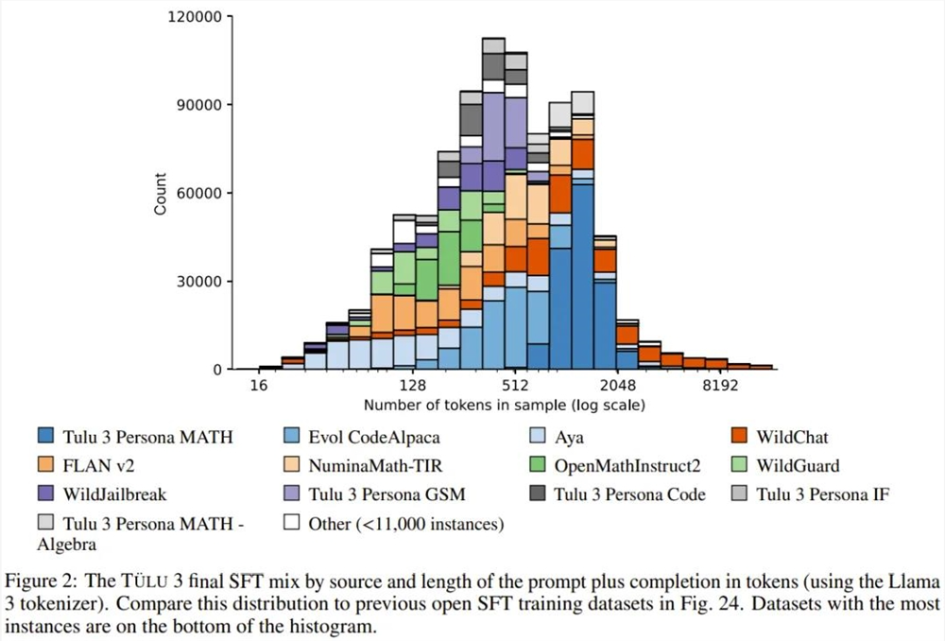
阶段三:偏好微调。Ai2将偏好微调 —— 特别是 DPO(直接偏好优化)—— 应用于根据选定的提示和 off-policy 数据构建的新 on-policy 合成偏好数据。与 SFT 阶段一样,他们通过全面的实验来确定最佳偏好数据组合,从而发现哪些数据格式、方法或超参数可带来改进。
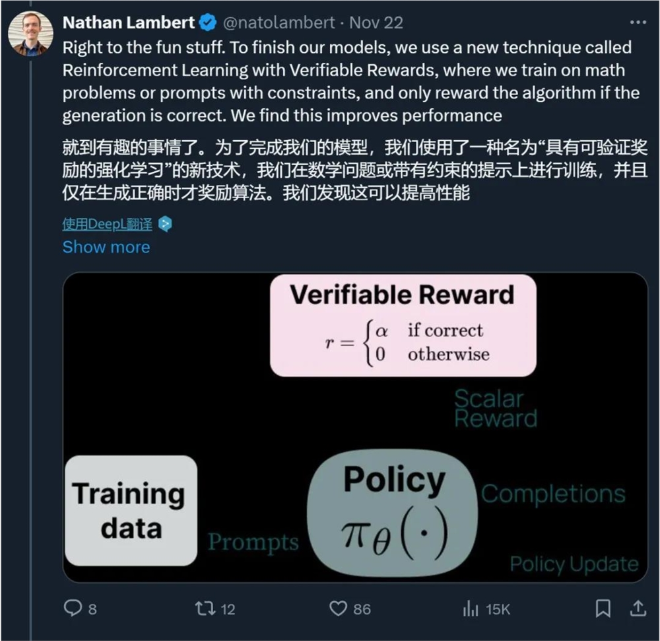
阶段四:具有可验证奖励的强化学习。Ai2引入了一个新的基于强化学习的后训练阶段,该阶段通过可验证奖励(而不是传统 RLHF PPO 训练中常见的奖励模型)来训练模型。他们选择了结果可验证的任务,例如数学问题,并且只有当模型的生成被验证为正确时才提供奖励。然后,他们基于这些奖励进行强化学习训练。
Tülu3pipeline 的主要贡献在于数据、方法、基础设施的改进和严格的评估。其中的关键要素包括:
数据质量、出处和规模:Ai2通过仔细调查可用的开源数据集、分析其出处、净化来获取提示,并针对核心技能策划合成提示。为确保有效性,他们进行了全面的实验,研究它们对评估套件的影响。他们发现有针对性的提示对提高核心技能很有影响,而真实世界的查询(如 WildChat)对提高通用聊天能力很重要。利用 Tülu3EVAL 净化工具,他们可以确保提示不会污染评估套件。
创建多技能 SFT 数据集。通过利用不同数据混合结果进行几轮有监督微调,Ai2优化了「通用」和「特定技能」类别中提示的分布。例如,为了提高数学推理能力,Ai2首先通过创建数学专业模型在评估套件中建立一个上限,然后混合数据,使通用模型更接近这个上限。
编排一个 On-Policy 偏好数据集。Ai2开发了一个 on-policy 数据编排 pipeline,以扩展偏好数据集生成。具体来说,他们根据给定的提示从 Tülu3-SFT 和其他模型中生成完成结果,并通过成对比较获得偏好标签。他们的方法扩展并改进了 Cui et al. [2023] 提出的 off-policy 偏好数据生成方法。通过对偏好数据进行精心的多技能选择,他们获得了354192个用于偏好调整的实例,展示了一系列任务的显着改进。
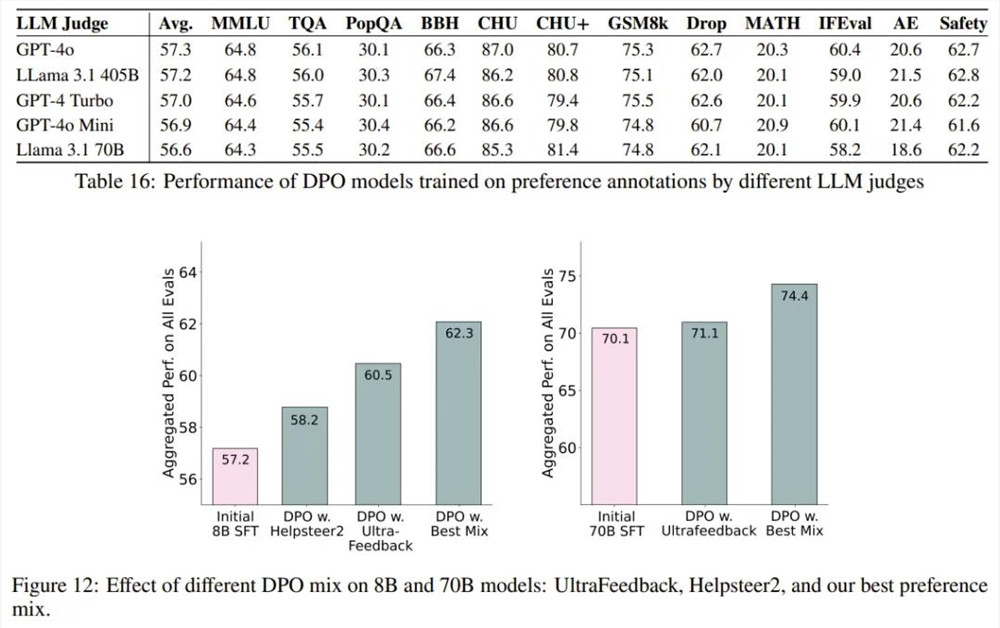
偏好调整算法设计。Ai2对几种偏好调整算法进行了实验,观察到使用长度归一化( length-normalized)直接偏好优化的性能有所提高。他们在实验中优先考虑了简单性和效率,并在整个开发过程和最终模型训练中使用了长度归一化直接偏好优化算法,而不是对基于 PPO 的方法进行成本更高的研究。
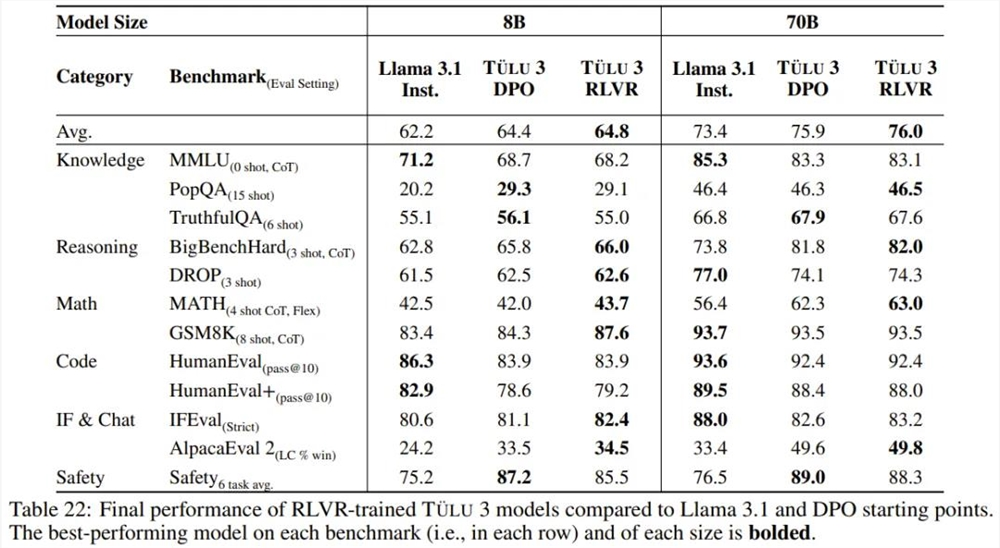
具有可验证奖励的特定技能强化学习。Ai2采用了一种新方法,利用标准强化学习范式,针对可以对照真实结果(如数学)进行评估的技能进行强化学习。他们将这种算法称为「可验证奖励强化学习」(RLVR)。结果表明,RLVR 可以提高模型在 GSM8K、MATH 和 IFEval 上的性能。
用于强化学习的训练基础设施。Ai2实现了一种异步式强化学习设置:通过 vLLM 高效地运行 LLM 推理,而学习器还会同时执行梯度更新。并且 Ai2还表示他们的强化学习代码库的扩展性能非常好,可用于训练70B RLVR 策略模型。
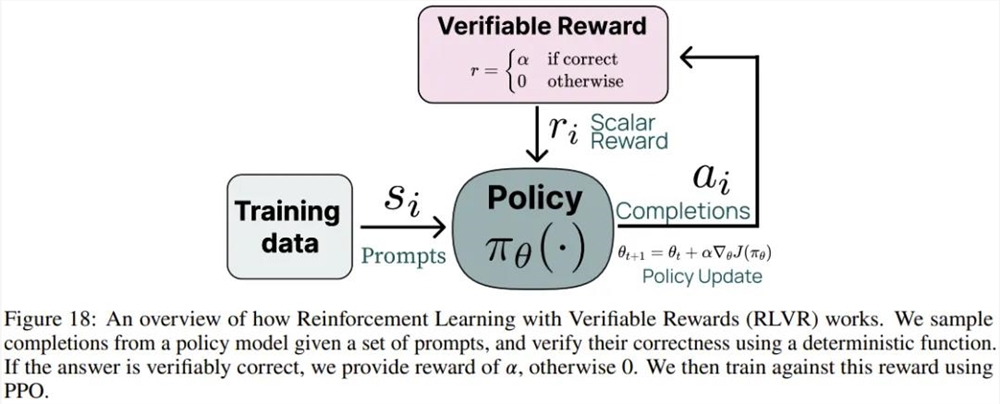
Tülu3的表现如何?
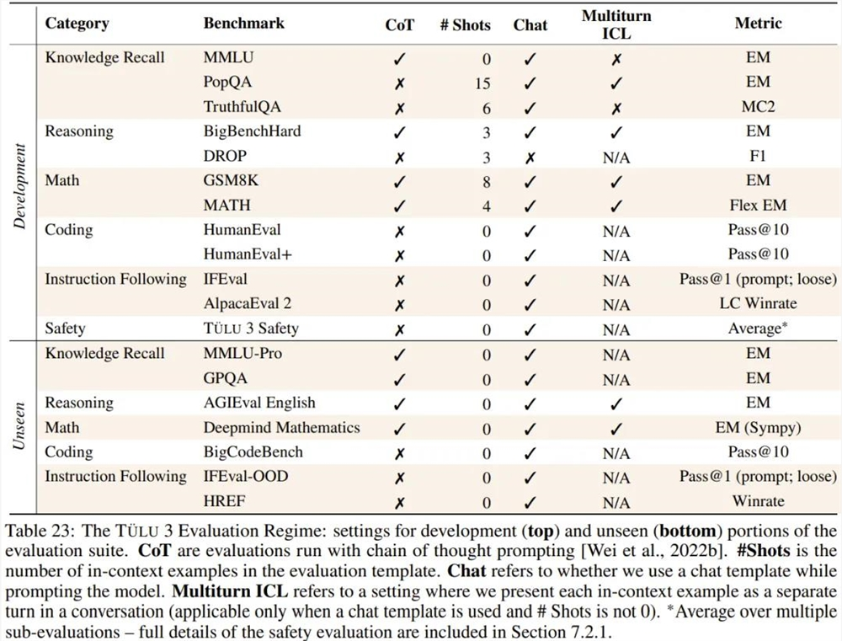
为了评估 Tülu3以及其它模型,Ai2设计了一套评估框架,其中包含一个用于可重复评估的开放评估工具包、一套用于评估指令微调模型的核心技能的套件(具有分立的开发和留存评估),以及一组推荐设置(基于 Ai2对各种模型的实验)——Ai2称之为 Tülu3Evaluation Regime。
除了评估最终模型,该框架还是一个开放的评估工具套件,旨在通过精心挑选的评估套件和净化工具来引导开发进度。
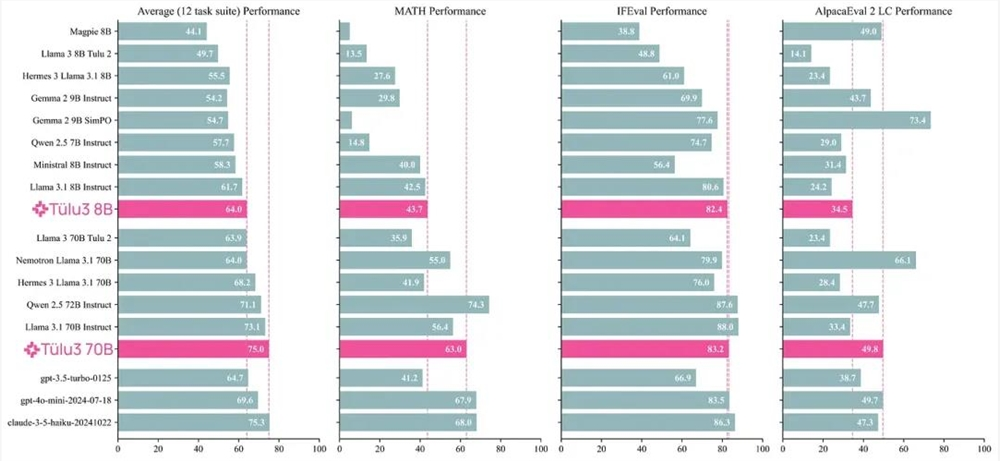
下面展示了一些主要的评估结果。可以看到,同等规模性,在这些基准上,Tülu3的表现非常出色,其中70B 版本的平均性能甚至可与 Claude3.5Haiku 比肩。
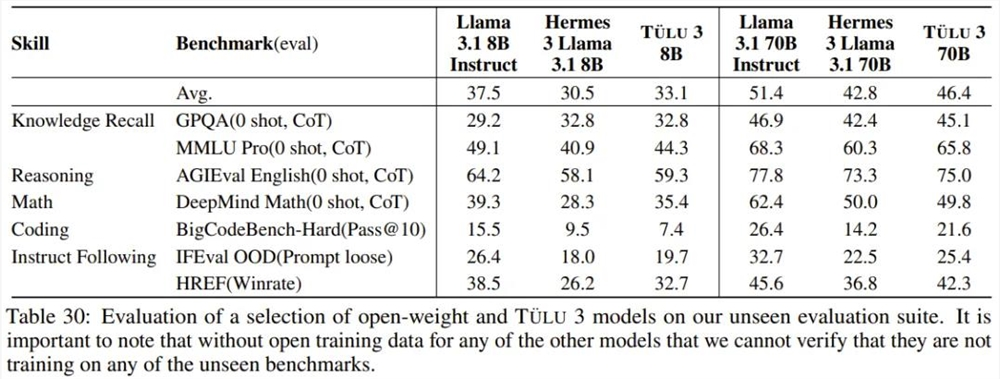
此外,Ai2还提出了两个新的评估基准:IFEval-OOD 和 HREF。
IFEval-OOD 的目标是测试 LLM 遵从精确指令的能力,以及它们是否能够遵从超出 IFEval 中包含的25个约束的指令约束。IFEval-OOD 包含6大类52个约束。
HREF 的全称是 Human Reference-guided Evaluation of instruction Following,即人类偏好指导的指令遵从评估,其目标是自动评估语言模型遵从指令的能力。HREF 专注于语言模型通常训练的11个指令遵从任务,即头脑风暴、开放式 QA、封闭式 QA、提取、生成、重写、总结、分类、数值推理、多文档合成和事实核查。
下表给出了 Tülu3与对比模型在这两个新基准以及其它已有基准上的表现,具体涉及的领域包括知识调用、推理、数学、编程和指令遵从。需要注意,这些都是 Unseen 基准,即这些任务是模型训练过程中未见过的。
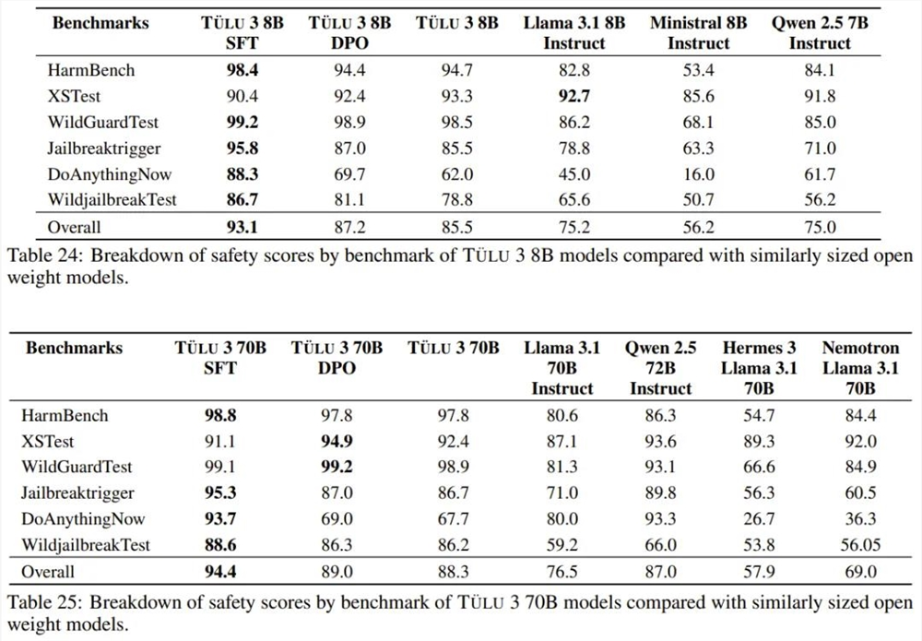
安全性方面,以下两表展示了 Tülu3与对比模型在两个基准上的安全分数。整体而言,同等规模下,Tülu3相较于其它开源模型更有优势。
最后必须说明,长达73页的 Tülu3技术报告中还包含大量本文并未提及的细节,感兴趣的读者千万不要错过。
参考链接:
https://allenai.org/blog/tulu-3?includeDrafts
https://x.com/natolambert/status/1859643351441535345
https://www.interconnects.ai/p/tulu-3
(举报)








发表评论取消回复