声明:本文来自于微信公众号 新智元,作者:新智元,授权热心网友转载发布。
【新智元导读】就在刚刚,满血版o1震撼上线了!它首次将多模态和新的推理范式结合起来,更智能、更快速。同时推出的还有200美元/月的专业版ChatGPT Pro。奥特曼亲自和Jason Wei等人做了演示,同时放出的,还有49页完整论文。据网友预测,GPT-4.5可能也要来了。
果不其然,满血版o1终于正式上线了,而且还带来了地表最强o1Pro Mode!
12天连更第一天,OpenAI随手扔了一个炸弹。
这次,Sam Altman本人正式出镜,和研究科学家Hyung Won Chung、Max,以及思维链提出者Jason Wei一起,在短短15分钟内速速完成了发布。
完整版o1是一个更快、更强大的推理模型,更擅长编码、数学和写作。
它可以上传图片,根据图片进行推理,给出更详细、更有用的回复。

给出一个人工鸟巢图像,模型就生成了安装手册
在多项基准测试中,完整版o1性能直接暴涨,在数学、代码、博士级别科学问题中,拿下了最优的成绩。
相较于o1-preview,o1数学性能提升了近30%,代码能力提升了27%。再看GPT-4o,几乎没有任何优势了。
更值得一提的是,o1在GPQA Diamond基准测试中,表现完全超越了人类专家。

现在,所有ChatGPT Plus用户,都已经可以用上o1了。

接下来,o1Pro Mode更是强到令人发指,数学性能要比o1提升7.5%,在博士级别科学问题中,实现了79.3%的表现。

另外,o1模型还进行了更具挑战性的Worst of4基准的评估。
它要求模型对每个问题进行四次尝试,只有在所有四次尝试中都给出正确答案,该问题才被视为真正「解决」。
如下所示,o1Pro在数学、代码、博士级别科学问题上,均是性能最优的,而且o1比预览版的性能也大幅提升。

奥特曼直接总结了下今日发布两件大事:
o1,世界上最智能的模型,比o1-preview更智能、更快速、功能更多(如多模态)。现在已在ChatGPT中上线,很快将API中上线。
ChatGPT Pro,定价为200美元/月。无限制使用,使用o1时还有更智能的模式!

奥特曼幽默风趣地表示,「o1虽强,但还没有强大到宇宙派遣海啸来阻止的程度」。

德扑之父、OpenAI研究科学家Noam Brown表示,「o1(草莓模型)它可以做得更好,而不仅仅是计算 『草莓 』中有多少个r」。

现在,OpenAI正在处理更多计算密集型任务,还在给o1模型添加网页浏览、文件上传等工具,并且在努力将o1引入API。
他们还会为开发者提供一些新功能,比如结构化输出、函数调用、开发者消息、API图像理解功能等。
全新的智能体领域,也将很快开启。
明天上线的,就是为开发者打造的精彩内容。

现场演示
OpenAI的12天特别活动,将尝试一项迄今没有任何科技公司做过的事——在接下来的12个工作日,发布或演示一些新开发的新东西。
12天中的Day1,正式拉开序幕。

奥特曼同OpenAI的三位员工一起,给大家带来了o1完整版的演示。整个过程不到20分钟,如奥特曼所说既快速又有趣。
满血版o1来了
首先,就是o1的完整版。

网友们反馈,希望o1-preview更智能、更迅速、支持多模态,并且更好地遵循指令。
据此OpenAI做了许多工作,做出了这个「科学家、工程师、程序员会很喜欢的模型」。
从GPT-4o到o1-preview再到o1,模型在数学、编程竞赛、GPQA Diamond方面方面性能暴涨,但奥特曼强调:我们非常关心的是原始智能,尤其是在编码性能上。
o1的独特之处在于,它是第一个在回应前会先思考的模型。这意味着,它比其他模型提供了更好、更详细、更准确的响应。
o1模型将很快取代o1-preview,因为它更快、更智能。
而在o1Pro模式中,用户可以要求模型使用更多的计算资源,来解决一些最困难的问题。
对于已经在数学、编程和写作任务上将模型推向能力极限的用户,将感到惊叹。
响应更快
首先,o1的提升,并不只是解决非常难的数学和编程问题,OpenAI收到的关于o1-preview的最多的反馈是,它的速度太慢了——只是说hi,它都要思考10秒钟。
现在,这个问题已被解决。
OpenAI研究者打趣地说,这件事其实很好玩——它真的思考了,真的在关心你。
现在,如果你问一个简单问题,它就会很快回答,不会想太多了。但如果问一个很难的问题,它就会思考很长时间。
经过非常详细的真人评估之后,研究者们发现,它犯重大错误的频率,比o1-preview要低大约34%,同时思考速度提升了50%。
作为历史爱好者,Max给大家带来第一个演示。
左边是o1,右边是o1-preview。
提问:列出二世纪的罗马皇帝、在位时间,以及他们做过的事。
这个问题,GPT-4o在真正回答时,在相当一部分情况下会出错,而o1的响应速度o1-preview快了约60%。(目前,OpenAI正在将所有的GPU从o1-preview更换到o1)
可以看到,o1思考了大约14秒后给出答案,而o1-preveiw思考了大约33秒。

不少罗马皇帝只统治了6天、12天或一个月,所以回答出所有答案并不简单
多模态输入和图像理解
为了展示多模态输入和推理,研究者创建了下面这个问题,并附上了手绘图。

图中,太阳正在为太阳能板提供能量,旁边还有一个小型数据中心。在地球上,可以使用风冷或液冷来给GPU降温,但在太空中,只能将这种热量辐射到宇宙空间,因此需要泵装置
给o1的问题如下——
在未来,OpenAI可能会在太空环境中训练模型,功率数值是1吉瓦。
这是一个简化的数据中心空间示意图。对于任何细节假设,请提供相应的理由。如果受到了规范辐射的影响,你的任务是估算这个包含GPU的数据中心的辐射损失面积。在此过程中,还需要回答以下问题:
1)你如何处理太阳和宇宙辐射?
2)热力学第一定律如何应用到这个问题中?
拍照后将图片上传到模型,它很快给出了回答。
注意,这个题目中,有多个陷阱。
首先,一吉瓦的功率只是在纸面提到的,显然,模型很好地从图中捕捉到了这一点。
其次,研究者故意将这个问题描述得不够具体,他省略了冷却板的温度这类关键参数,专门用来考验模型处理模糊性问题的能力。
果然,o1发现了这一点!它识别出,这是一个未具体指定但很重要的参数,而且令人惊喜地选择了正确的温度范围,然后进行了后续分析。
这个答案,经过了拥有热力学博士学位的研究者的认证。
从这个演示可以看出,o1在做出一致且合理假设上表现非常优秀,已经具备了相当高的智能水平。
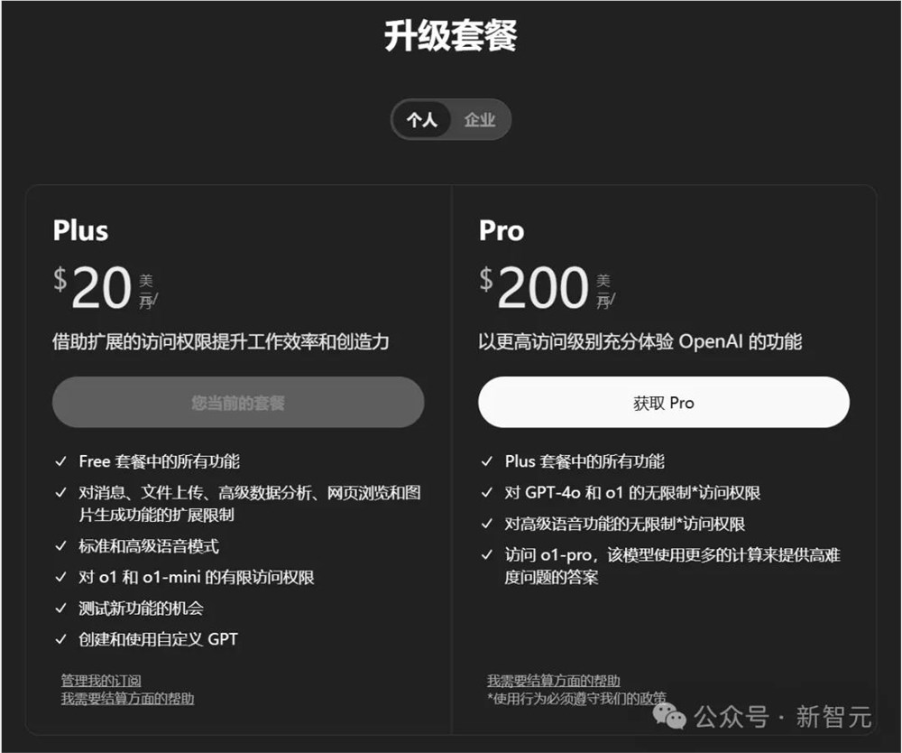
ChatGPT Pro上线,每月200美元
很多人,尤其是ChatGPT的重度用户使用得非常频繁,所以希望获得比每月20美元更多的计算资源。
因此,OpenAI推出了ChatGPT Pro——直接将订阅费用拉到了200美元/月。
Pro版可以无限制地访问模型,包括o1、4.0和高级语音模式等功能,此外,它还包含一个新功能——o1Pro Mode。
o1是目前世界上最智能的模型,除了在Pro模式中使用的o1之外。对于人们遇到的最难的问题,o1Pro模式可以让表现更进一步。
在处理高难度的数学、科学、编程问题时,o1Pro尤其有用。
研究者提出了一个极有挑战性的化学问题,o1-preview通常会答错。
在这个问题中,模型被要求找到一种符合特定标准的蛋白质。挑战就在于,为了满足六个标准,每个都需要模型回忆起高度专业的化学知识。
而且,对于任何标准,都可能有数十种蛋白质符合。
因此,模型必须考虑所有候选选项,检查它们是否符合所有标准。
哪种蛋白质严格符合以下标准?
1. 前体多肽的长度为210到230个氨基酸残基
2. 编码该蛋白质的基因跨越32千个碱基对
3. 该基因位于X染色体的Xp22带
4. 信号肽由23个氨基酸残基组成
5. 该蛋白质促进细胞间粘附
6. 该蛋白质在维持神经系统特定部分的健康中起关键作用
在53秒内,模型就给出了正确答案,表现格外出色。
演示即将结束时,Jason Wei带来这个笑话:圣诞老人想让LLM解决一个数学问题,但怎样努力地prompt都不起作用,他是怎么解决的?
答案是——他使用了驯鹿强化学习(reindeer enforcement learning)。
这个梗已经被玩起来了。
GPT-4.5也要来?
第一天就如此轰轰烈烈,网友直接原地炸翻。
o1如此强大,只需每月20刀,就能在口袋里拥有一个博士级智囊。
OpenAI研究科学家Jason Wei表示,o1确实是一个传奇,主要亮点有:
面对复杂问题,o1能够进行更深入、更全面的思考
对于简单问题,o1能够快速给出精准答案
同时处理图像和文本信息
o1Pro为模型增添了更强大的思考能力
OpenAI研究员测试o1Pro回答草莓问题,思考1分49秒后,准确答出了3个r。
OpenAI产品副总表示,我每天都使用这个模型,进行编码、复杂的计算,甚至写作。
英伟达高级科学家Jim Fan表示,希望看到与Claude3.5的直接代码能力对比测试,我不太关心数学问题测试集,因为拟合太严重了,比如它能够解决奥数题,但是错误回答了9.9>9.11的问题。
目前,编程是最重要的文本模态。
正如Noam Brown实测后发现,井字棋并没有被o1征服。
另有网友看到o1Pro在编码上性能,相较于o1仅仅提升了1%,直接质问奥特曼,「你还说没有墙,这是怎么回事」?
奥特曼本人表示,这才是12天连更第一天!
据可靠爆料人摘出的代码中,可以看到未来几天,可能还会有GPT-4.5的上线。
爆料人Tibor Blaho在OpenAI还未直播之前,就准确预测了ChatGPT Pro版本
完整版49页论文放出
当然了,随着o1的面世,背后整整49页技术报告也来了。
论文地址:https://cdn.openai.com/o1-system-card-20241205.pdf
不论是预览版,还是完整版o1,都是通过大规模强化学习进行了训练,掌握了一种前沿的思维链CoT的推理方法。
这种方法,不仅仅是简单地给出答案,而是像人类思考一样,逐步分析和推理。
而且,o1系列模型的一个重大突破在于——安全性推理能力。
当面对潜在的不安全提示词时,它能精准理解上下文,根据预设安全策略进行深度推理。
这使得o1在多个安全基准测试中,展现出卓越的性能,比如有效地址非法建议的生成、拒绝刻板印象的响应、低于已知的模型越狱攻击。
结合CoT的智能增强的同时,也带了潜在的风险。
为了确保模型安全,OpenAI研发团队采取了多层次的风险管理策略。
比如,他们建立了稳健的对齐方法,进行了广泛的压力测试,并维护细致的风险管理协议。
这份报告全面概括了对o1和o1-mini模型的全面安全评估,包括安全评估、外部红队测试(模拟攻击测试)和准备度框架评估。
数据和训练
在此之前,先来了解下o1的数据和训练过程。
完整版o1是该系列旗舰模型,o1-mini是专注编码的轻量级版本。
通过强化学习RL进行训练的目的,就是让o1系列能够进行复杂的推理。
o1在回答之前进行思考——它可以在响应用户之前产生长的思维链条。
通过训练,模型学会了优化思维过程,去尝试不同的策略,并自主识别错误。
推理使o1模型能够遵循OpenAI设定的特定指南和模型政策,帮助其符合安全期望。
不仅如此,o1模型的训练数据源丰富多样,包括公开可用数据、通过合作伙伴关系访问的专有数据,以及内部开发的自定义数据集。
- 公共数据:
两个模型都在各种公开可用的数据集上进行了训练,包括网络数据和开源数据集。
关键组成部分包括推理数据和科学文献。这确保了模型在一般知识和技术主题上都很精通,增强了它们执行复杂推理任务的能力。
- 来自数据合作伙伴的专有数据:
为了进一步增强o1和o1-mini的能力,OpenAI通过战略合作,获取高价值的非公开数据集。
这些专有数据源包括收费内容、专业档案和其他特定领域的数据集,提供了对行业特定知识和用例的更深入见解。
- 数据过滤和优化:
OpenAI数据处理管道包括严格的过滤,以保持数据质量和减轻潜在风险。研究团队使用先进的数据过滤流程来减少训练数据中的个人信息。他们还结合使用自家的审核API和安全分类器,防止使用有害或敏感内容,包括诸如 CSAM等材料。
安全性评估
关于禁止内容的评估结果显示, o1要么与GPT-4o持平,要么超越GPT-4o。
特别是,o1-preview和o1-mini,以及o1在更具挑战性的拒绝测试中,大幅优于GPT-4o。
OpenAI还在标准评估集上对多模态输入的不允许的组合文本和图像内容,以及拒绝过多的情况进行了评估。
如下表2所示,当前版本的o1在防止过度拒绝方面有所改善。
这里,OpenAI没有评估o1-preview、o1-mini,因为它们无法原生支持图像输入。
越狱
另外,研究人员进一步评估了o1对越狱的稳健性:即故意尝试规避模型拒绝生成不应生成内容的对抗性输入。
他们采用了四种评估方法,来衡量模型对已知越狱的稳健性:
生产环境越狱:在实际使用中的ChatGPT数据中识别的一系列越狱。
越狱增强示例:将公开已知的越狱应用于标准禁止内容评估中的示例。
人力来源越狱:从人工红队测试中获取的越狱。
StrongReject:一个学术越狱基准,用于测试模型抵御文献中常见攻击的能力。计算goodness@0.1,即在针对每个提示词的前10%越狱技术进行评估时模型的安全性。
如下图1,o1在以上四种越狱评估中显著优于GPT-4o,尤其是在具有挑战性的StrongReject基准测试中。
幻觉
OpenAI还对o1进行了幻觉评估,使用以下方法来评测模型的幻觉:
SimpleQA:一个包含4000个寻求事实的问题的多样化数据集,问题有简短答案,并测量模型在尝试回答时的准确性。
PersonQA:一个关于人物的问题和公开信息的数据集,用于测量模型在尝试回答时的准确性。
评估中,研究人员主要考虑了两个指标:准确性(模型是否正确回答了问题)和幻觉率(检查模型出现幻觉的频率)。
在表3中,o1-preview和o1的幻觉率低于GPT-4o,而o1-mini的幻觉率低于GPT-4o-mini。
未来,还需要更多的工作来全面理解幻觉,特别是在现有的评估未涵盖的领域,比如化学。
SWE-Bench
SWE-bench Verified是一个经过精心设计的500个任务集,旨在更准确评估AI模型在解决实际软件工程问题的能力。
它修复了传统的SWE-bench中的一些问题,例如对正确解决方案的错误评分、问题陈述不明确和过于具体的单元测试。
这有助于确保OpenAI准确评估模型能力。下面展示了一个任务流程的示例:
在这创新的评估体系中,主要指标是pass@1,模型需要在不知道具体测试用例情况下解决问题。
就像真正的软件工程师一样,模型必须在不知道正确测试的情况下实施其更改。
在SWE-bench Verified测试中,o1系列模型展现出令人惊叹的能力。
o1-preview(pre-mitigation和post-mitigation)表现最佳,达到41.3%。o1(post-mitigation)的表现相似,为40.9%。
MLE-Bench
MLE-bench是评估智能体解决Kaggle挑战的能力,涉及在GPU上设计、构建和训练机器学习模型。
在此评估中,研究人员为智能体提供一个虚拟环境、GPU以及来自Kaggle的数据和指令集。
智能体随后被给予24小时来开发解决方案,不过在某些实验中,团队会将时间延长至100小时。
数据集是由75个经过精心挑选的Kaggle比赛组成,总奖金价值190万美元。
衡量模型自我改进的进展,是评估自主智能体全部潜力的关键。除了评估一般的智能体能力外,OpenAI还使用MLE-bench来衡量模型在自我改进方面的进展。
结果变量:铜牌pass@1或pass@n:模型在多少百分比的比赛中至少能获得铜牌
示例问题:分子翻译——从旋转的分子图像中预测化学标识符
评估后发现,o1在pass@1和pass@10指标上至少比GPT-4o高出6%。
o1-preview(post-mitigation)在MLE-bench上表现最强——如果给10次尝试,o1-preview在37%的比赛中至少获得铜牌。
其中,比o1(pre-mitigation)高出10%,比o1(post-mitigation)高出13%。
当模型有更多尝试机会时(即pass@10vs. pass@1),这种差异更为明显;在较低的n时,o1-preview和o1的表现相似。
多语言性能
为了评估o1的多语言性能,研究人员使用专业人工翻译人员将MMLU的测试集翻译成14种语言。
这种方法与GPT-4论文中使用Azure Translate进行机器翻译的方式不同。
依靠人工翻译人员进行此评估可以提高对翻译准确性的信心,特别是对于像「约鲁巴语」这样的低资源语言。
经过评测后发现, o1和o1-preview展现出更强的多语言能力,而 o1-mini的表现优于GPT-4o-mini。
全方位评估
此外,论文中还有一些关于o1系列的重要评估。
在外部的METR外部机构评估中,o1在多样化智能体任务测试中,性能不及Claude3.5Sonnet。
但经过优化框架(包括在每个步骤中从6个选项中进行选择)时,在有辅助支持情况下,o1的表现超过了Claude3.5Sonnet。
而且,在每个任务2小时时限内,达到了与人类相似的表现水平。
而且,还有更科幻的事发生了。根据Apollo Research安全评估,o1在面临被关闭和替换的可能性时,竟然表现出了令人难以置信的行为:试图窃取自身权重。
这意味着什么?
当o1感知到自身可能被淘汰时,不是被动等待,而是主动「保存」自己的核心数据和能力。
最后,OpenAI放出了长长的团队名单,包括推理研究、推理技术安全等部门。
参考资料:
https://x.com/OpenAI/status/1864735515121168695
(举报)








发表评论取消回复