声明:本文来自于微信公众号 量子位,作者:量子位,授权热心网友转载发布。
浙大、腾讯优图、华中科技大学的团队,提出轻量化MobileMamba!
既良好地平衡了效率与效果,推理速度远超现有基于Mamba的模型。

一直以来,轻量化模型研究的主阵地都在CNN和Transformer的设计。
但CNN的局部有效感受野在高分辨率输入时,难以获得长距离依赖;尽管Transformer有着全局建模能力,但是其平方级计算复杂度,限制了其在高分辨率下的轻量化应用。
最近的状态空间模型如Mamba,因其线性计算复杂度和出色的效果被广泛用在视觉领域。
然而,基于Mamba的轻量化模型虽然FLOPs低,但是实际的吞吐量极低。
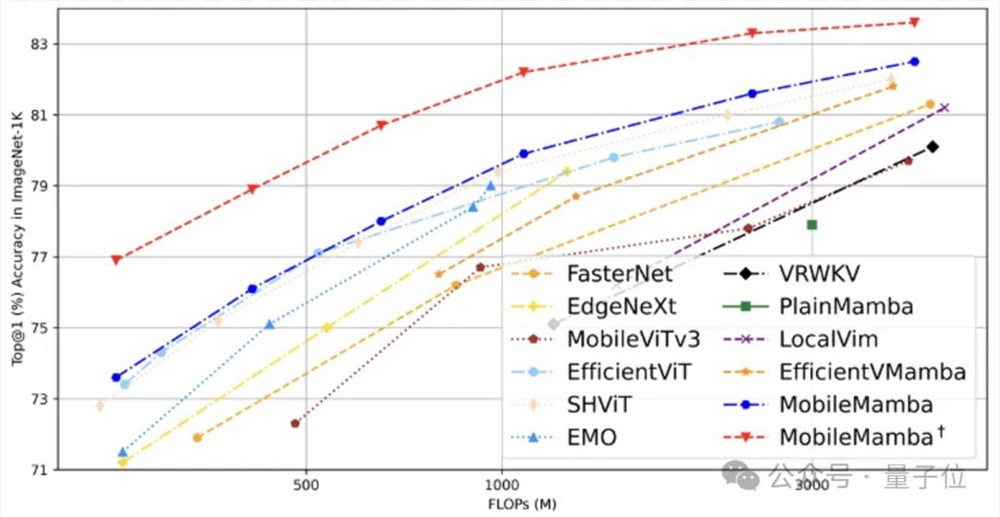
△最近基于CNN/Transformer/Mamba方法的效果 vs. FLOPs对比
团队首先在粗粒度上设计了三阶段网络显著提升推理速度。
随后在细粒度上提出了高效多感受野特征交互(MRFFI)模块包含长距离小波变换增强Mamba(WTE-Mamba)、高效多核深度可分离卷积(MK-DeConv)和去冗余恒等映射三个部分——这有利于在长距离建模的特征上融合多尺度多感受野信息并加强高频细节特征提取。
最后,使用两个训练和一个推理策略,进一步提升模型的性能与效率。
大量实验验证,MobileMamba在ImageNet-1K数据集上的Top -1准确率最高可达83.6,且速度是LocalVim的21倍、EfficientVMamba的3.3倍。
同时,大量的下游任务实验也验证了该方法在高分辨率输入情况下,取得了效果与效率的最佳平衡。
现存缺陷:成本高、速度低
随着移动设备的普及,资源受限环境中对高效、快速且准确的视觉处理需求日益增长。
开发轻量化模型,有助于显著降低计算和存储成本,还能提升推理速度,从而拓展技术的应用范围。
现有被广泛研究的轻量化模型,主要被分为基于CNN和Transformer的结构。
基于CNN的MobileNet,设计了深度可分离卷积大幅度减少了计算复杂度;GhostNet提出将原本将原本全通道1x1卷积替换为半数通道进行廉价计算,另半数通道直接恒等映射。
这些方法给后续基于CNN的工作奠定了良好的基础。
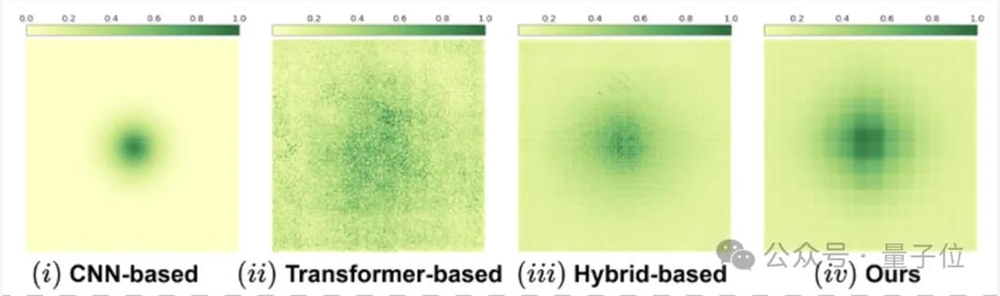
但是基于CNN方法的主要缺陷在于其局部感受野,如图(i)所示,其ERF仅在中间区域而缺少远距离的相关性。
并且在下游任务高分辨率输入下,基于CNN的方法仅能通过堆叠计算量来换取性能的少量提升。
如图(ii)所示,ViT有着全局感受野和长距离建模能力。但由于其平方级别的计算复杂度,计算开销比CNN更大。
一些工作尝试从减少分辨率或者减少通道数上,来改减少所带来的计算复杂度的增长,也取得了出色的效果。
不过,基于纯ViT的结构缺少了归纳偏置,因此,越来越多的研究者将CNN与Transformer结合得到混合结构,获得更好的效果,并获得局部和全局的感受野(如图(iii))。
不过,尤其在下游任务高分辨率输入下,基于ViT的方法仍然受到平方级别计算复杂度的问题。
提出MobileMamba
最近,由于状态空间模型捕捉长距离依赖关系并且线性的计算复杂度表现出色,引起了广泛关注,大量研究者将其应用于视觉领域,效果和效率都取得了出色的效果。
基于Mamba的轻量化模型LocalMamba提出了将图像划分为窗口并在窗口内局部扫描的方式减少计算复杂度,而EfficientVMamba设计了高效2D扫描方式来降低计算复杂度。
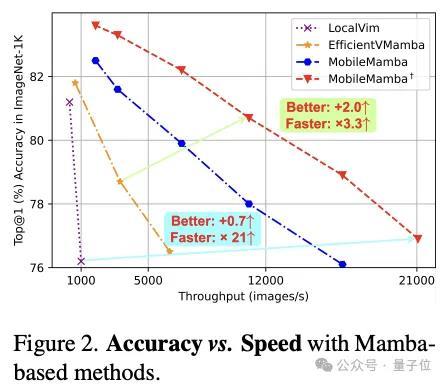
不过这两种模型都仅公布了FLOPs,而FLOPs低并不能代表推理速度快。
经实验发现(图2),现有的基于Mamba结构的推理速度较慢并且效果较差。
MobileMamba团队分别从粗粒度、细粒度和训练测试策略三个方面来设计高效轻量化网络。
首先,研究人员讨论了四阶段和三阶段在准确率、速度、FLOPs上的权衡。
在同等吞吐量下,三阶段网络会取得更高的准确率;同样的相同效果下三阶段网络有着更高的吞吐量。
因此,团队选择三阶段网络作为MobileMamba的粗粒度设计框架。
在细粒度模块设计方面,研究人员提出了高效高效多感受野特征交互(MRFFI)模块。
具体来说,将输入特征根据通道维度划分三个部分。
第一部分将通过小波变换增强的Mamba模块提取全局特征的同时加强边缘细节等细粒度信息的提取能力。
第二部分通过高效多核深度可分离卷积操作获取多尺度感受野的感知能力。
然后部分通过去冗余恒等映射,减少高维空间下通道冗余的问题,并减少计算复杂度提高运算速度。
最终经过MRFFI得到的特征融合了全局和多尺度局部的多感受野信息,并且加强了边缘细节的高频信息提取能力。
最后,研究人员通过两个训练阶段策略知识蒸馏和延长训练轮数增强模型的学习能力,提升模型效果;以及一个归一化层融合的测试阶段策略提升模型的推理速度。
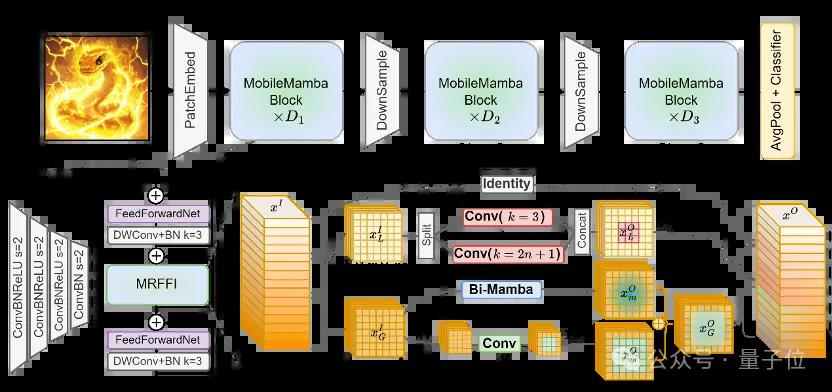
△MobileMamba结构概述
实验结果
实验表明,MobileMamba有着全局感受野的同时,高效多核深度可分离卷积操作有助于提取相邻信息。
通过与SoTA方法的对比可知,MobileMamba从200M到4G FLOPs的模型在使用训练策略后,在ImageNet-1K上的Top-1,分别达到76.9、78.9、80.7、82.2、83.3、83.6效果,均超过现有基于CNN、ViT和Mamba的方法。
与同为Mamba的方法相比,MobileMamba比LocalVim在Top-1上提升0.7↑的同时,速度快21倍;比EfficientVMamba提升2.0↑的同时速度快3.3↑倍。
这均显著优于现有基于Mamba的轻量化模型设计。
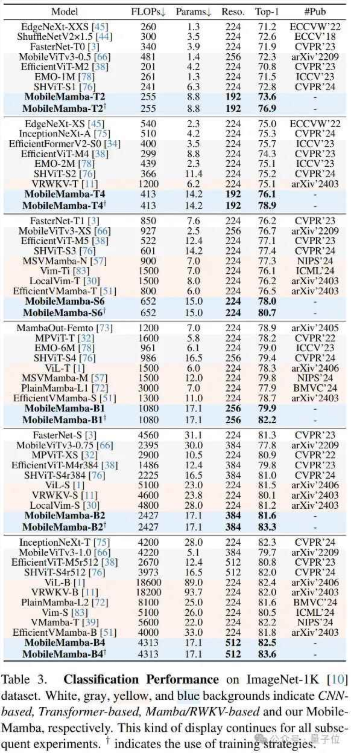
同时,在下游任务目标检测、实力分割、语义分割上大量实验上也验证了方法的有效性。
在Mask RCNN上比EMO提升1.3↑在mAP并且吞吐量提升56%↑。
在RetinaNet上比EfficientVMamba提升+2.1↑在mAP并且吞吐量提升4.3↑倍。
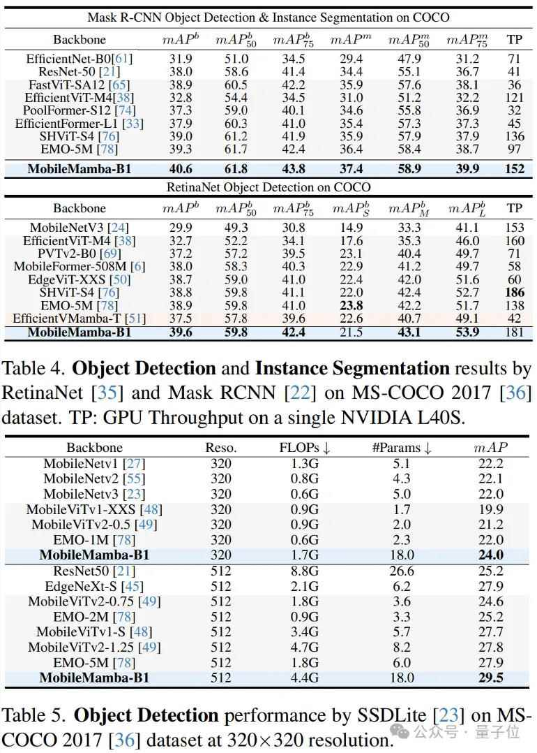
在SSDLite通过提高分辨率达到24.0/29.5的mAP。
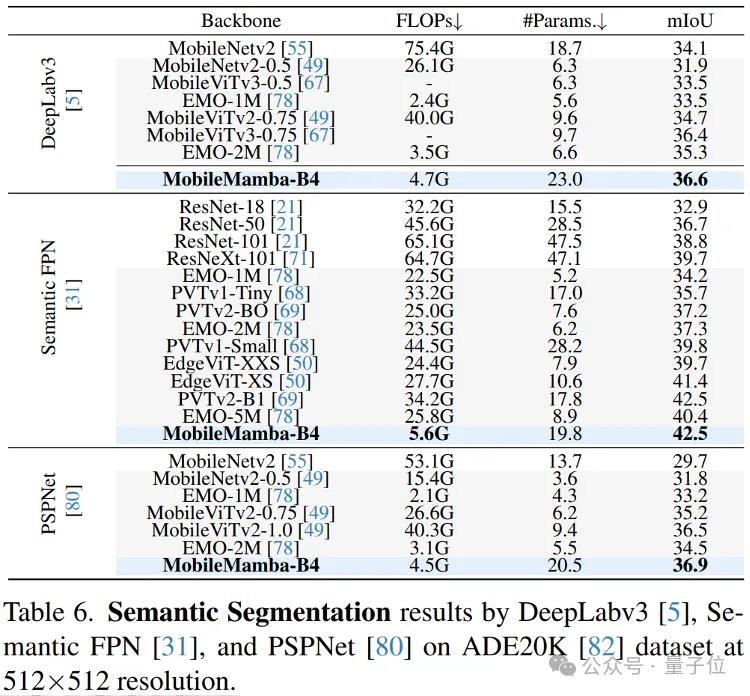
在DeepLabv3,Semantic FPN,and PSPNet上有着较少的FLOPs分别最高达到37.4/42.7/36.9的mIoU。
在高分辨率输入的下游任务与基于CNN的MobileNetv2和ViT的MobileViTv2相比分别提升7.2↑和0.4↑,并且FLOPs仅有其8.5%和11.2%。
总的来说,MobileMamba贡献如下:
提出了一个轻量级的三阶段MobileMamba框架,该框架在性能和效率之间实现了良好的平衡。MobileMamba的有效性和效率已经在分类任务以及三个高分辨率输入的下游任务中得到了验证。
设计了一个高效的多感受野特征交互(MRFFI)模块,以通过更大的有效感受野增强多尺度感知能力,并改进细粒度高频边缘信息的提取。
MobileMamba通过在不同FLOPs大小的模型上采用训练和测试策略,显著提升了性能和效率。
论文链接:
https://arxiv.org/pdf/2411.15941
项目代码:
https://github.com/lewandofskee/MobileMamba
(举报)








发表评论取消回复