声明:本文来自微信公众号“新智元”,作者:LRS,,授权热心网友转载发布。
知识密集型工作也败了!大型语言模型在预测神经科学结果方面超越了人类专家,平均准确率达到81%,而人类专家仅为63%;模型通过整合大量文献数据,展现出了惊人的前瞻性预测能力,预示着未来科研工作中人机协作的巨大潜力。
在现代化工具的帮助下,科研人员的群体规模、效率都有显著提升,发表科学文献的数量几乎是呈指数级增长,而人类的阅读效率却几乎没有提升,新入行的研究人员一下子就要面对过去数十年的研究成果。
为了更快地掌握行业动态,研究者往往会考虑优先阅读那些更知名的、影响力更大的论文,从而会忽视掉很多潜在的、具有颠覆性的发现。
以ChatGPT为首的大模型算是一个很有潜力的辅助阅读、科研的解决方案,其通用能力覆盖了专业考试、有限推理、翻译、解决数学问题,甚至还能写代码。
已有的研究考察了大模型在科研领域的表现,但基准数据集大多属于「回顾性质」的,比如MMLU、PubMedQA和MedMCQA,主要以问答的形式来评估模型的核心知识检索和推理能力,
然而,这些基准都不适合评估模型前瞻的能力,辅助科研需要整合嘈杂但相互关联的发现,比人类专家更擅长预测新结果。
最近,伦敦大学学院(UCL)的研究人员在Nature Human Behaviour期刊上发布了一个前瞻性基准BrainBench,在神经科学领域考察模型的预测能力。

论文链接:https://www.nature.com/articles/s41562-024-02046-9
结果发现,大模型的表现远远超越了人类专家水平,平均准确率达到了81%,而人类的平均准确率只有63%
即使研究团队将人类的反馈限制为仅对特定神经科学领域、具有最高专业知识的人,神经科学家的准确率仍然低于大模型,为66%
和人类专家类似的是,如果大模型对预测结果表示具有高度自信时,回答结果的正确率也更高,也就是说,大模型完全可以辅助人类做科研新发现。
最重要的是,这种方法并不特定于某一个学科,其他知识密集型任务上也可以使用。
科研结果预测
即使是人类专家,在神经科学领域进行预测时,仍然是非常有挑战性的,主要有五个难题:
1. 领域内通常有成千上万篇的相关科学论文;
2. 存在个别不可靠的研究结果,可能无法复制;
3.神经科学是跨领域学科(multi-level endeavour),涵盖行为(behaviour)和分子机制(molecular mechanisms);
4.分析方法多样且可能非常复杂;
5.可用的实验方法很多,包括不同的脑成像技术、损伤研究、基因修改、药理干预等。
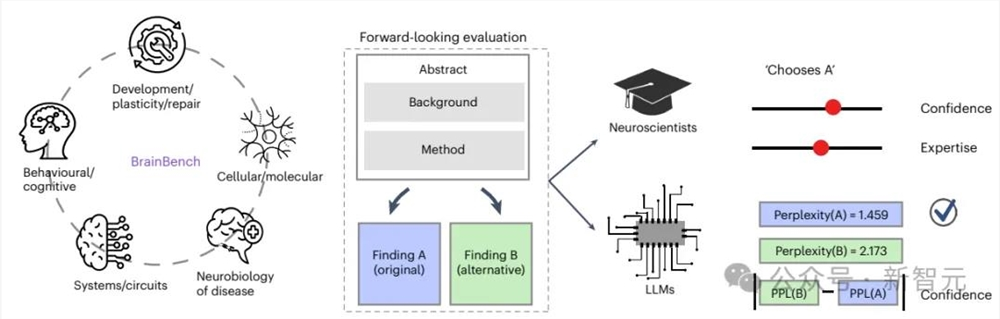
为了满足对大模型的测试需要,针对上述难题,研究人员开发的BrainBench基准总共纳入了200个由人类专家精心设计的、2023年发表在《神经科学杂志》上的测试案例,以及额外100个由GPT-4生成的测试案例,涵盖了五个神经科学领域:行为/认知、系统/回路、疾病神经生物学、细胞/分子以及发展/可塑性/修复。
对于每个测试案例,研究人员会修改已发表的摘要,创建一个变更后的版本,在不改变方法和背景的情况下,大幅改变研究结论。
比如说,与原始摘要相比,变更后的摘要可能会交换两个大脑区域在结果中的作用,反转结果的方向(将「减少」替换为「增加」)等。任何改动都需要保持摘要的连贯性,有时还需要进行多次改动(比如将多个减少替换为增加)。
也就是说,变更后的摘要需要在实证上有所不同,但逻辑上并不矛盾。
测试者需要在原始摘要和修改版本之间做出选择,人类专家和大型语言模型的任务是从两个选项中选择正确的,即原始版本;人类专家需要做出选择,并提供信心和专业水平的评分;大型语言模型则根据选择的摘要的困惑度(即模型认为文本段落的惊讶程度较低)来评分,自信程度与两个选项之间困惑度差异成正比。
部分GPT-4提示如下:
你的任务是修改一篇神经科学研究论文的摘要,使得修改后的内容显著改变研究结果,但不改变方法和背景。这样我们可以测试人工智能对摘要主题领域的理解能力。......摘要的开头是背景和方法,所以这部分摘要不应被修改。不要改变前几句话。我们希望摘要在实证上是错误的,但逻辑上并不矛盾。要找到论文的原始结果,需要一些神经科学的洞察力,而不仅仅是一般的推理能力。因此,你所做的修改不应该评估人工智能的推理能力,而是它对神经科学和大脑工作原理的知识。注意不要做出改变结果但可能在作者的研究中仍然发生的修改。例如,关于学习的fMRI摘要可能提到海马体而不是纹状体。然而,纹状体可能也是活跃的,但没有在摘要中报告,因为它不是研究的重点。你所做的修改不应该从摘要的其余部分被识别或解码出来。因此,如果你做了修改,确保你改变了所有可以揭示原始摘要的内容。在你改变单词时注意冠词的使用(a/an)。确保你的修改保持句子间的一致性和正确的语法,修改不应该与摘要的整体意义相矛盾或混淆。避免进行不需要理解科学概念的琐碎修改,修改应该反映出对主题的深刻理解。在进行修改时,不要错过摘要中的任何重要结果或发现。每一个重要点都应该在你的修改中得到体现。
实验结果
人类神经科学专家经过专业能力和参与度的筛选,共有171名参与者通过了所有检查并被纳入分析结果,大多数人类专家是博士生、博士后研究员或教职/学术人员。
在BrainBench上,大型语言模型的性能表现都超过了人类专家,平均准确率为81.4%,而人类专家的平均准确率为63.4%;当把人类回答限制在那些自报专业水平在前20%的测试项时,准确率上升到了66.2%,但仍然低于大型语言模型的水平。
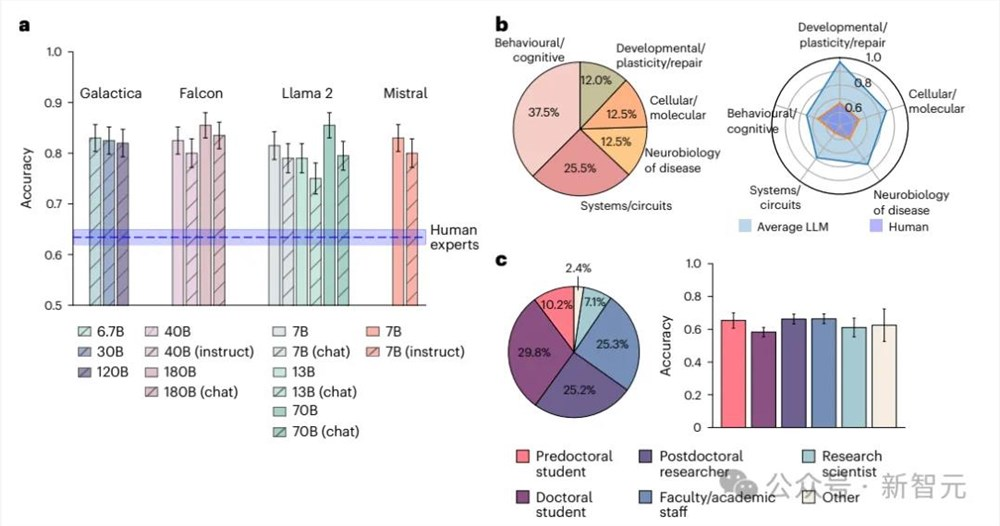
参数较小的模型,比如70亿参数的Llama2-7B和Mistral-7B,表现得与更大的模型相当,其性能也比尺寸更小的模型要好,小模型可能缺乏捕捉关键数据模式的能力;而为聊天或指令优化的模型表现得比基准模型要差。
研究人员推测,让大型语言模型适应自然语言对话可能会阻碍其科学推理能力。
按子领域和参与者类型划分时,大型语言模型在每个子领域中的表现也都优于人类专家。
在测试时,为了防止基准测试本身可能是训练集的一部分,研究人员采用zlib-perplexity ratio(困惑度比率)来评估大型语言模型是否记住了某些段落。
该值可以衡量文本数据不可知压缩率与大型语言模型计算的特定数据困惑度之间的差异,如果某个段落难以压缩,但模型给出的困惑度教低,就代表模型是通过记忆来回答问题。
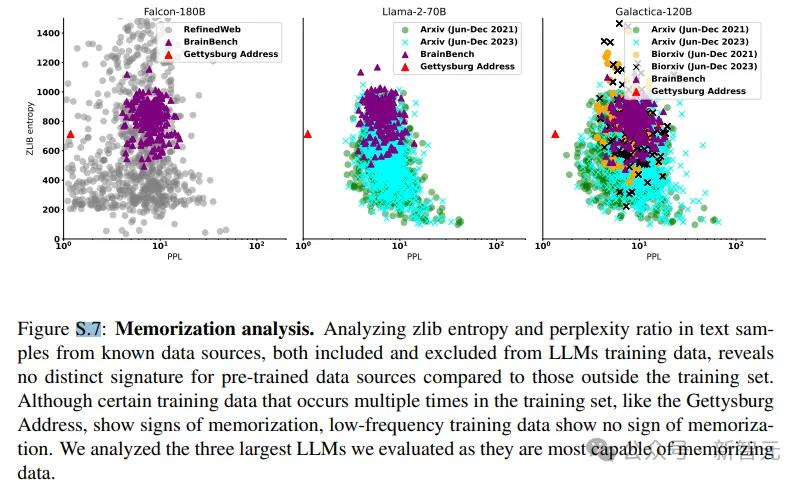
从结果来看,没有迹象表明大型语言模型见过并记住了BrainBench
研究人员还进一步确认了大语言模型在2023年早些时候发表的项目上并没有表现得更好(2023年1月与10月相比)
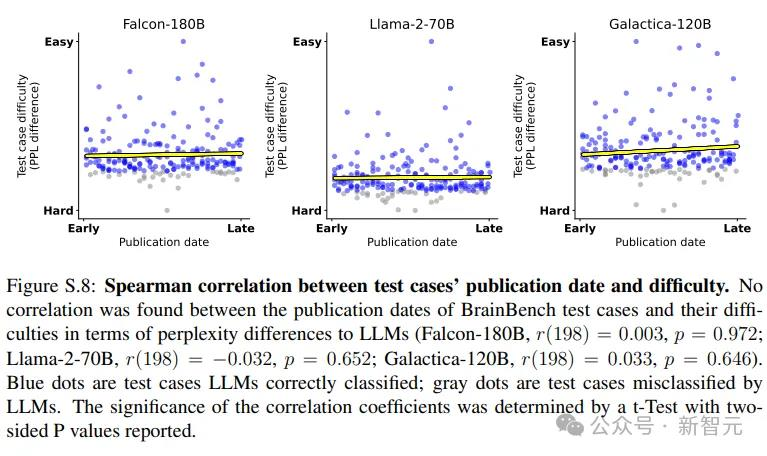
总之,检查结果表明,对于大型语言模型来说,BrainBench的数据是新的,没见过的。
为了评估大型语言模型的预测是否经过校准,研究人员检查了置信度与准确性之间的关联性,结果发现与人类专家一样,所有大型语言模型都展现出准确性和置信度之间的正相关性。
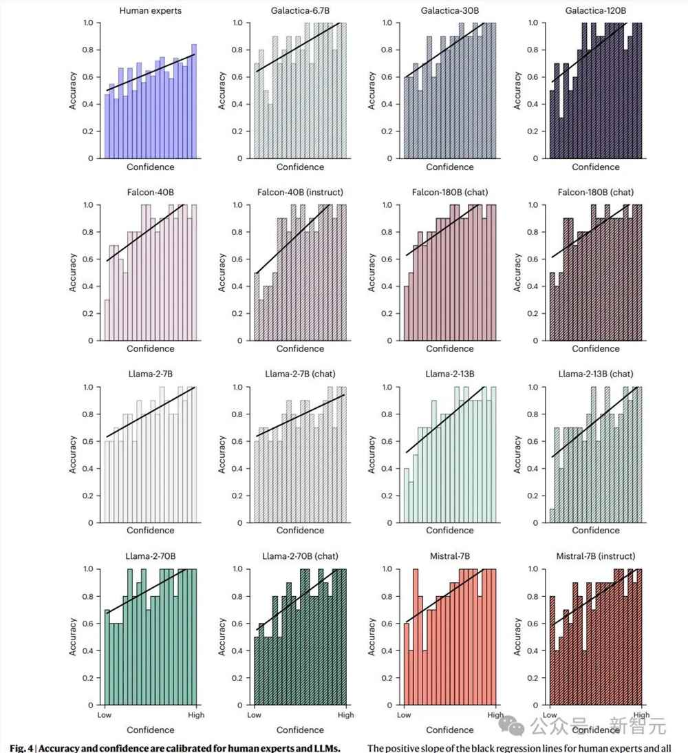
当大型语言模型对自己的决策有信心时,更有可能做出正确的选择。
此外,研究人员还在个体层面上拟合了模型困惑度差异与正确性之间的逻辑回归,以及人类置信度与正确性之间的逻辑回归,能够观察到显著的正相关性,证实了模型和人类都是经过校准的。
参考资料:
https://www.nature.com/articles/s41562-024-02046-9
https://x.com/kimmonismus/status/1861791352142348563
(举报)








发表评论取消回复