声明:本文来自微信公众号“量子位”,作者:关注前沿科技,授权热心网友转载发布。
继量子芯片之后,谷歌又来抢“OpenAI双12直播”的流量了!
就在刚刚,谷歌新一代大模型Gemini2.0突然登场,再次由谷歌CEO皮猜亲自官宣。
新一代模型专为AI Agent而打造,谷歌表示目前已经将2.0版本提供给了一些开发者内测,正在迅速将其集成在Gemini和搜索等产品线中。
好消息是,Gemini2.0Flash实验版模型今天就在网页端开放,大家都能玩,移动端即将推出。
除此之外,谷歌还推出了一项名为深度研究(Deep Research)的新功能,基于高级推理和长上下文能力,它能直接帮你干研究助理的活儿——给个主题,自己出报告的那种。
目前这个新功能在Gemini Advanced版本中可用。
谷歌这一波出手,再结合Sora的不尽如人意,新一天的直播还没开始,已经有人开始唱衰OpenAI了:
OpenAI的护城河是什么?

“面向智能体时代的新AI模型”
在谷歌CEO皮猜、Google DeepMind CEO哈萨比斯,以及Google DeepMind CTO科雷(Koray Kavukcuoglu)三人共同撰写的博客文章中,官方给Gemini2.0的定位是:
面向智能体时代的AI模型。
在多模态方面的新进展,以及原生工具的使用,使我们能够构建新的AI智能体,以更接近实现通用助手的愿景。
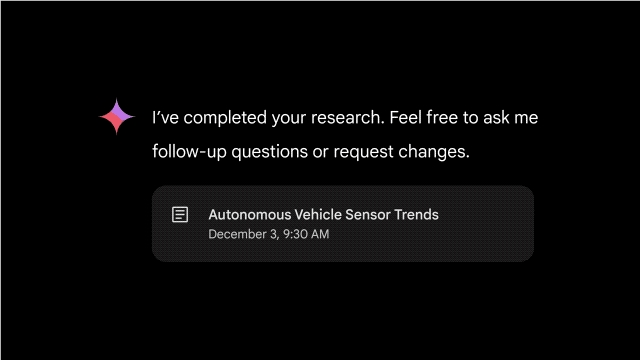
具体如何体现?在Gemini2.0Flash实验版第一时间上线的同时,谷歌还在Gemini Advanced中推出了一项名为深度研究(Deep Research)的智能体新功能。
你可以把它当成以研究助理,围绕一个复杂主题生成研究报告。有点像是个科研版AI搜索。
另外一个Gemini2.0的重点关键词是:多模态。
2.0Flash实验版除了支持图像、视频、音频多模态输入,还支持多模态输出。
不单单是简单的图文混排,可控的多语种文本到语音(TTS)输出也行,还能直接本地调用工具,比如谷歌搜索、代码工具、第三方用户定义的功能。
有ChatGPT插件那味儿了。
不过,作为实验模型,其文本到语音和原生图像生成功能目前仅提供给早期访问合作伙伴。谷歌透露2.0Flash将在1月份正式推出,会提供更多不同大小的模型。
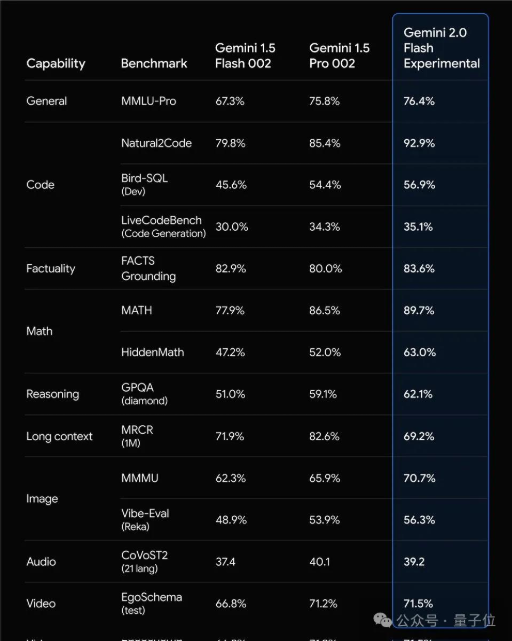
而根据谷歌发布的基准测试结果,不论是在多模态的图片、视频能力上,还是编码、数学等能力上,仅是Flash实验版的Gemini2.0表现就已几乎全面超越Gemini1.5Pro002。
而且它的速度是1.5Pro的两倍。
谷歌表示,明年年初,会将Gemini2.0扩展到更多旗下产品中,比如Project Astra。
就是I/O大会上谷歌推出来跟GPT-4o的语音功能打擂台的那个。
此次,基于Gemini2.0,Project Astra更新了以下功能
更好的对话:现在能够以多种语言和混合语言进行对话,更好地理解口音和不常见的单词。
使用新工具:Project Astra会用谷歌搜索、Lens和地图了。
更强的记忆力:Project Astra现在拥有10分钟的会话记忆,并且可以记住更多历史对话,也就说,凭借这些“记忆”,它能更懂你了。
改进延迟:Project Astra可以按正常人类对话的节奏来理解对话。
谷歌还提到,正在将Project Astra移植到眼镜等更多移动终端中。
另外,谷歌透露,他们正在和Supercell等游戏开发商合作,测试基于Gemini2.0打造的游戏智能体们的实力。
这些智能体可以根据屏幕上的动作对游戏进行推理,并与玩家实时对话提供行动建议。
玩《突击小队》、《部落冲突》、《农场日记》,场面belike:
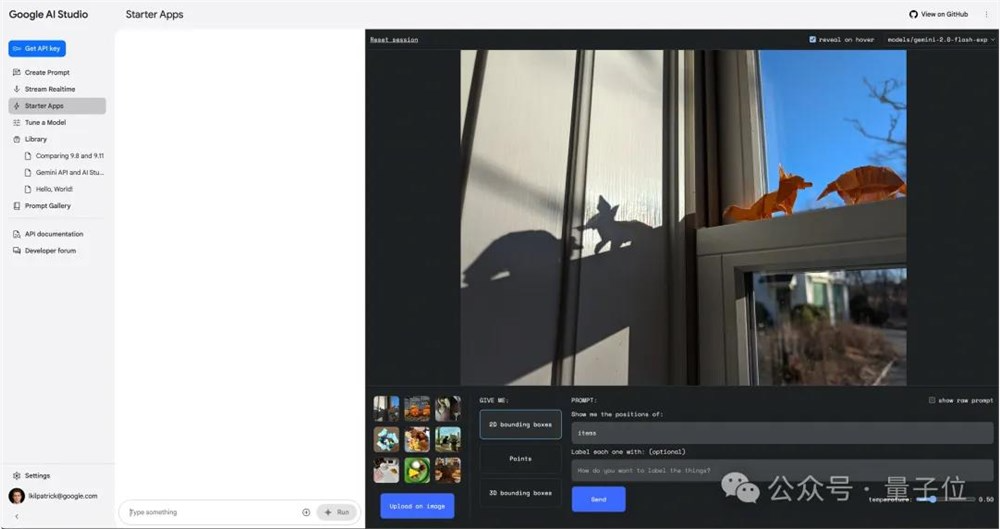
除了网页端可用,Gemini2.0Flash实验模型还通过Google AI Studio和Vertex AI的Gemini API向开发者提供。
从OpenAI跳槽到谷歌的Logan Kilpatrick表示,他们在Google AI Studio中创建了一个全新体验,展示了Gemini2.0视频理解、原生工具使用、空间理解的入门应用。
那么,你觉得这够Agent吗?
参考链接:
[1]https://x.com/GoogleDeepMind/status/1866869343570608557
[2]https://blog.google/technology/google-deepmind/google-gemini-ai-update-december-2024/#ai-game-agents
(举报)








发表评论取消回复