声明:本文来自于微信公众号新智元,作者:新智元,授权热心网友转载发布。
【新智元导读】AI智能体,已经无限逼近真实人类?1000个人被采访,每人两小时,真实人类的智能体就这么水灵灵地被投放进去了,结果更是令人吃惊:在模拟人类行为上,智能体已经85%逼近真实人类。AI,终究是预判了你的预判。
真实人类被「投放」进AI世界,这是什么魔幻操作?
更可怕的是,根据真实人类生产的智能体,居然能以85%的准确度,还原出他们的行为。
也就是说,人类在真实世界是怎么回答问题的,智能体在虚拟世界中也一样。人类几乎拥有了跟自己完全相似的虚拟复制体!
去年,斯坦福爆火25个智能体小镇,让西部世界走进现实。
时隔一年多,原班人马团队让1000多个AI智能体放入虚拟小镇,去模拟真实人类的一切态度和行为。

论文地址:https://arxiv.org/pdf/2411.10109
不同以往,这次他们采用了一种新奇的研究方式——访谈,去创建生成式智能体。
通过招募1052名参与者,涵盖了不同性别、年龄、地区等,每人接受GPT-4o采访了2个小时。

然后将得到的访谈内容作为文字提示,输入语言模型中,复刻出每个个体对应的AI智能体。
所有智能体在综合社会调查中的回答,与原参与者两周后自我复现答案准确率接近85%,并在人格预测、实验复制中表现与人类相当。
毫无疑问,我们距离能够模仿人类的AI智能体已经非常接近了
有网友称,这就是克隆人的智慧。

还有人惊叹道,机器能够提前预判你的预判,这一天竟然真的来了!

AI在模拟人类行为方面达到85%的准确率,无疑是一个巨大的成就。这一突破,直接为AI处理高度复杂交互(如个性化医疗建议)铺平了道路。
拒绝刻板印象,让AI反映真实人类
为什么要做一个这样的研究呢?
团队成员之一Joon Sung Park介绍到,这是为了「让故事更完整」。
去年的西部世界小镇,团队是希望借生成式智能体来指出这样一个未来——
在无法直接参与或观察的情况下(比如卫生政策,产品发布,外部冲击等),人类可以用AI来模拟生活,来更好地了解自己。
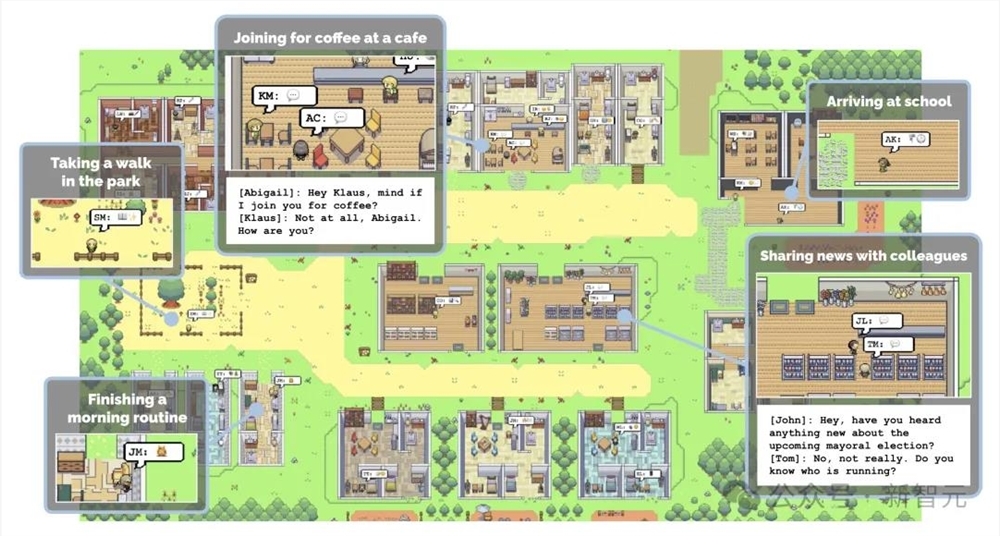
然而,研究者却深深感觉,这个故事是不完整的,并不还原真实的人类世界。
为了让这些模拟变得可信,他们觉得自己应该避免将这些「AI人」变量简化为人口统计学的刻板印象,对其准确性的评估,也应该不仅仅是通过平均处理效应的成功或失败来衡量。
该怎么办呢?团队在个体模型中找到了答案。
他们创建了反映真实个体的生成式智能体,并通过衡量它们在多大程度上能够重现个体对综合社会调查、大五人格测试、经济博弈以及随机对照试验的反应,来验证这些模型的有效性。
令人惊喜的是,智能体的表现极为出色。
它们在综合社会调查中,对被试反应的复现准确率达到了85%,与被试两周后复现自己答案的准确性相当,而且在预测人格特质和实验结果上同样出色。
与仅基于人口统计描述的智能体相比,这种基于访谈的智能体在种族和意识形态群体之间减少了准确性偏差。
研究者认为,这是因为后者更能反映真实个体的各种独特因素。
总之,这项研究为模拟个体开辟了新的可能性。而模拟的基础,就是对构成我们社会的个体进行准确建模。
这项工作也标志着:生成式AI可以代表真实人类的时代,从此正式开启!
现在,作者已经将开源存储库和用于这项工作的Python包上传到Github,包括他本人的智能体
创建1000+类人生成式智能体
若想创建一个能够反映影响个人态度、信仰、行为等多样因素的智能体,前提是需要对真实个人拥有深度理解。
为此,研究团队决采用了基本的社会科学方法——「深度访谈」方法,将预设问题和基于受访者回答的适应性相结合。
通过分层抽样招募的1000+参与者,是具有典型代表的样本。不同个体覆盖了不同年龄、宗教、性别、教育水平、政治意识形态。
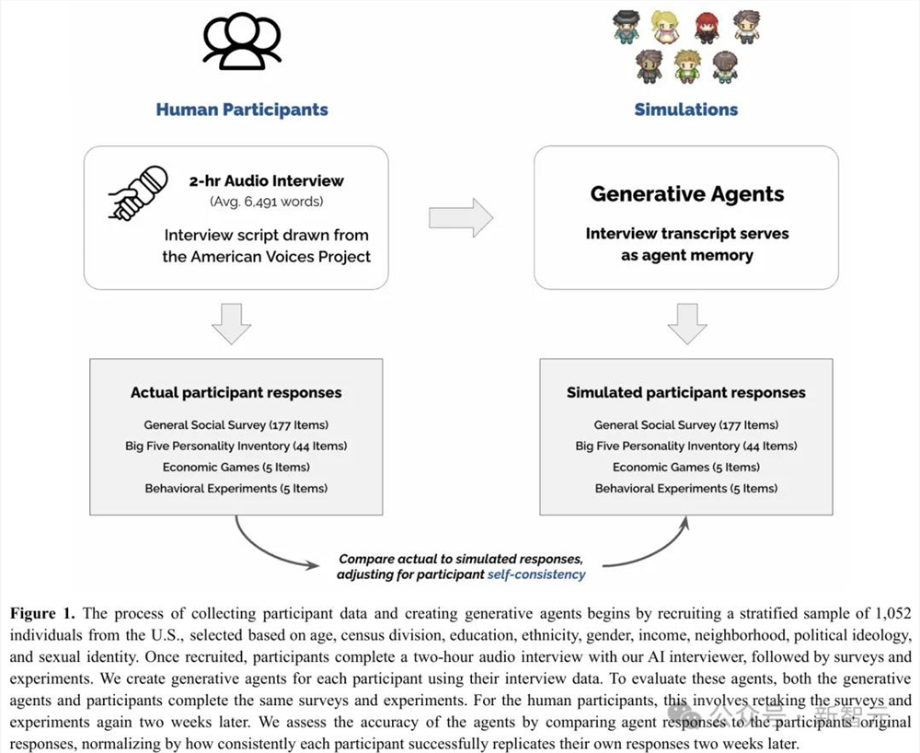
这么多人的采访,当然要交给AI。
为此,研究人员开发了一个AI面试官,对每个参与者完成了2小时语音访谈,并生成的录音平均长度为6,491个单词。
这里采访的方案,借鉴了「American Voices Project」对社会科学家采访的一部分,从参与者的生活故事、到他们对当前社会问题的看法,涵盖非常之广。
比如,从童年、教育、到家庭和人际关系,给我讲讲你任何经历过的生活故事;你如何看待种族主义和社会治安?
根据采访结构和时间限制,AI面试官根据每人的回答动态生成后续问题。
研究平台和交互界面
为了创建「生成式智能体」,作者开发了一种新颖的智能体架构,将参与者完整访谈记录和大模型相结合。
其中,整份记录都会被「注入」到模型提示中,指示模型根据访谈数据模仿该参与者的行为。
在需要多步骤决策的实验中,智能体会通过简短的文本描述,被赋予先前刺激及其对应反应的记忆。
生成式智能体能够对任何文本刺激作出反应,包括强制选择提示、调查问卷、多阶段互动场景。
为了评估这些智能体模拟人类的前景,研究团队评估了四个部分:
综合社会调查(General Social Survey)
大五人格测试问卷(Big Five Inventory)
五个著名的行为经济学博弈(包括独裁者博弈、信任博弈、公共品博和囚徒困境)
五个包含控制和实验条件的社会科学实验
他们使用前三个部分,来评估生成式智能体在预测个体态度、特质和行为方面的准确性,而复制研究评估其预测群体层面,处理效果和效应量的能力。
由于个体在调查和行为研究中的回答,往往随时间表现出不一致性,作者还将将参与者自身的态度和行为一致性作为归一化因子:模拟某个个体态度或行为的准确性取决于这些态度和行为在时间上的一致性。
为了解决这种自我一致性水平的差异,他们要求每位参与者在两周内完成两次测试。
其中主要因变量是归一化准确率(Normalized Accuracy),其计算方法为:智能体预测个体回答的准确性/个体自身回答的复现准确性。
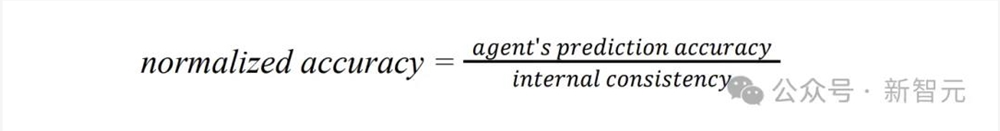
归一化准确率用1.0表示,生成式智能体预测个体回答的准确性与个体两周后复现自己回答的准确性相同。
对于连续型结果,作者计算的是归一化相关性。
预测个体态度和行为
综合社会调查
评估的第一部分便是GSS,以评估受访者对广泛主题的人口背景、行为、态度和信仰,包括公共政策、种族关系、性别和宗教。
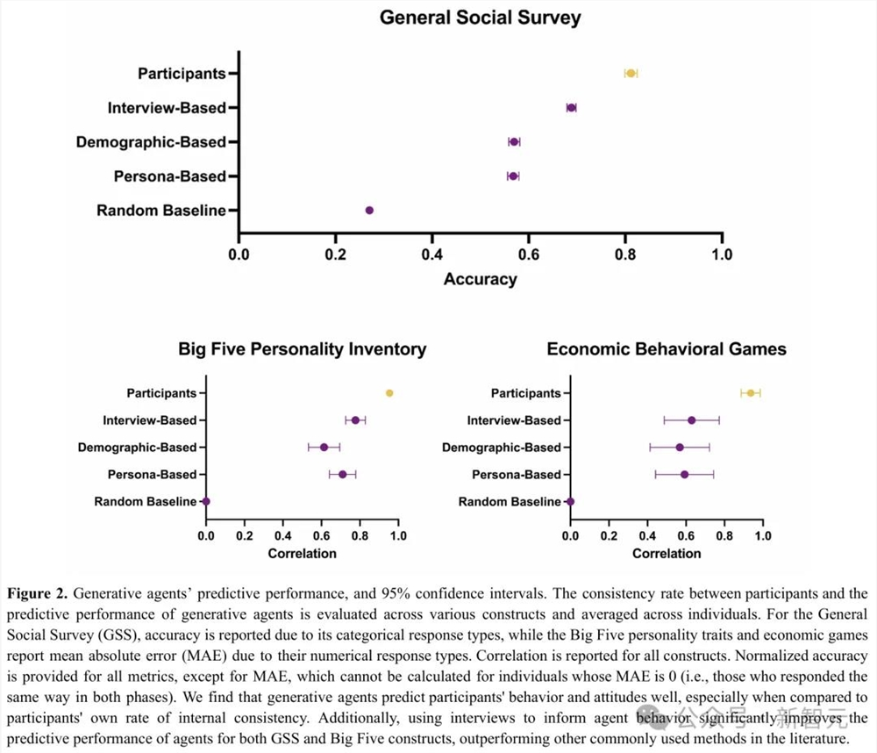
对于GSS,生成式智能体以0.85的平均归一化准确率预测了参与者的反应。
显然,这些基于访谈构建的智能体,性能优于基于人口统计和人物角色的智能体,归一化分数高出14-15%。
基于人口统计的生成式智能体实现了0.71归一化准确率,而基于角色的智能体达到了0.70。
大五人格测试
评估第二个部分,使用BFI-44预测参与者的大五人格特质,该测试评估五个人格维度:开放性、尽责性、外向性、亲和性和神经质。
每个维度由8-10个李克特量表(Likert scale)问题的综合得分计算得出。
对于大五人格测试,生成式智能体达到了0.80的归一化相关性。
与GSS的结果类似,基于访谈的生成式智能体的表现优于基于人口统计(归一化相关性=0.55)和基于角色(归一化相关性=0.75)的智能体。
基于访谈的智能体在预测大五人格特质时,还产生了更低的平均绝对误差(MAE),事后成对Tukey测试确认基于访谈的智能体显著优于其他两组。
经济博弈
评估第三个部分包含五个著名的经济博弈,旨在引出参与者在有真实利害关系的决策情境中的行为。
这些博弈包括:独裁者博弈、第一玩家和第二玩家的信任博弈、公共品博弈、囚徒困境。

为确保参与者的真实投入,研究提供了金钱奖励。
研究人员将每个博弈的输出值归一化到0-1的范围内,并比较生成式智能体的预测值与参与者的实际值。
由于这些是连续性测量,他们计算了相关系数和归一化相关性。
平均而言,生成式智能体达到了0.66的归一化相关性。
然而,在经济博弈中,各智能体之间的平均绝对误差(MAE)没有显著差异。
基础对比研究
在探索性分析中,作者通过将基于访谈的生成式知恩个体与一个基线复合智能体进行比较,测试了访谈的有效性和效率。
这个基线复合代理是基于参与者的GSS、大五人格和经济博弈响应数据构建的。
这里,随机抽样了100名参与者,并排除了同类问题的问答对,建立复合智能体作为参照。
结果显示,复合智能体在GSS归一化准确率为0.76,在大五人格归一化相关性和经济博弈归一化相关性分别为0.64和0.31。
在消融实验中,即使删除80%访谈内容,基于访谈构建的智能体,仍旧优于复合智能体。其中,GSS归一化准确率为0.79。
另外,在通过GPT-4将访谈记录转换为要点总结(仅保留事实内容,移除原始语言特征),结果同样如此。
实验复现结果,AI与人类高度一致
实验评估的第四部分,就是让生成式智能体参与5个社会科学实验,检测它们是否预测社会科学家常用实验环境中的处理效应。
这些实验来自一项大规模复现工作中收录的已发表研究,包括研究感知意图如何影响责任归属,以及公平性如何影响情绪反应。
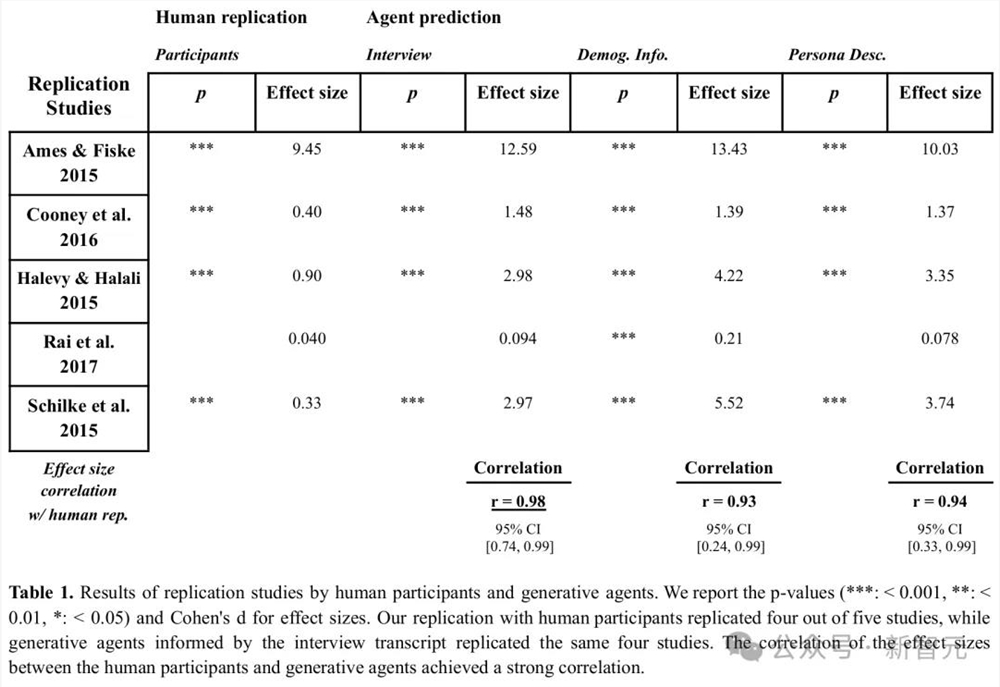
最新研究中,人类参与者和生成式智能体都完成了全部五项研究,并使用与原始研究相同的统计方法计算了p值和处理效应量。
如下表所示,人类成功复现了5项研究中的4项,其中1项失败。而生成式智能体也复现了相同的四项研究,同样未能复现第五项。
生成式智能体估算的效应量与参与者的效应量高度相关,相比之下参与者内部一致性相关系数为0.99,得出归一化相关系数为0.99。
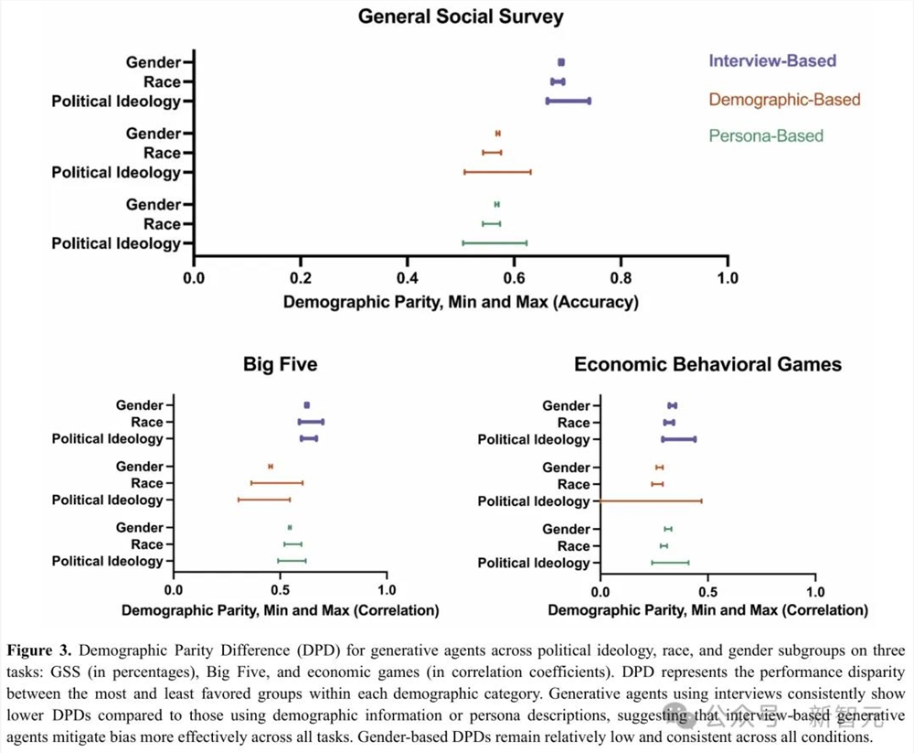
在生成式智能体人口统计学平等差异(DPD)实验中,与人口统计信息或角色描述构建的智能体相比,基于访谈的生成式智能体在所有任务中都显示出较低的DPD。
这表明基于访谈的生成式智能体能更有效地减轻偏见。
如何创建一个合格的AI访谈员
为了确保智能体所需的丰富训练数据具有高质量和一致性,研究者开发了下面这个AI访谈智能体。
之所以选择访谈而非问卷调查,就是希望访谈能提供更全面、细致的信息,从而让智能体在广泛的话题和领域中,实现更高保真度的态度和行为模拟。
另外,选用AI访谈智能体而非人类访谈员,也能确保所有被试之间互动风格和质量的一致。
AI访谈员架构
一个合格的AI访谈员,需要知道何时提出问题,以及如何提出有意义的根据问题。
在遵守访谈提纲的同时,它还要随机应变,灵活调整,帮助被试打开话匣子,分享他们可能没想起来的内容。
为了赋予AI访谈员这种能力,研究者特意设计了一种访谈架构,让研究者能控制访谈的整体内容和结构,同时允许智能体有一定的自由度,来探索采访脚本中硬编码的后续问题。
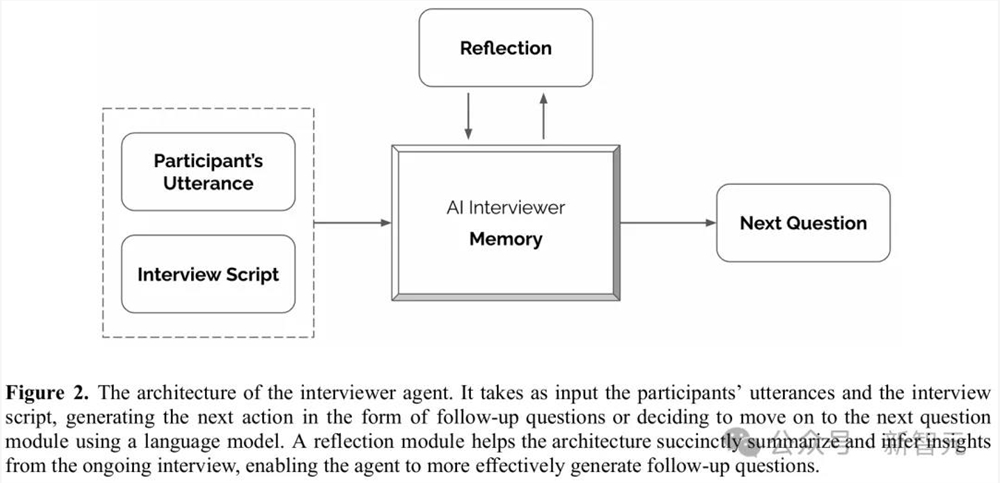
智能体会将被试的话语和访谈脚本作为输入,以后续问题的形式生成 下一步行动,或决定使用语言模型继续下一个问题模块。反思模块有助于架构从正在进行的访谈中简洁地总结和推断见解,使智能体更有效地生成后续问题
用语言模型进行下一个问题模块
访谈架构将访谈协议和受访者最近的回答作为输入,输出一个动作:1)继续提问提纲中的下一个问题;或2)根据对话内容提出一个跟进问题。
访谈提纲是一系列有序的问题清单,每个问题都标注了预设时间。在一个新问题块开始时,AI访谈员会逐字提问脚本中的问题。
当被试回答后,AI访谈员会利用语言模型,在问题块的时间限制内动态决定最佳下一步。
比如,当询问被试关于童年经历时,如果回答中提到「我出生在新罕布什尔……我很喜欢那里的自然环境」,但未具体提及喜欢的地点,访谈员可能会生成并提问一个跟进问题:「在新罕布什尔,有没有特别喜欢的步道或户外地点,或者在童年时留下深刻印象的地方?」
反之,当询问职业时,如果回答是「我是牙医」,访谈员会判断问题已经完全得到回答,然后进入下一个问题。
跟进问题的推理和生成,都是通过提示语言模型完成的。然而,为了访谈员生成有效的行动,语言模型需要记住并推理先前的对话内容,才能根据分享信息提出有意义的跟进问题。
这里就出现了一个问题:尽管现代语言模型的推理能力不断提高,但如果提示内容过长,它们仍然难以全面考虑所有信息。
如果毫无选择地包含访谈至今的所有内容,可能会逐渐降低访谈员生成根据问题的表现。
为了解决这个问题,研究者让访谈架构包含一个反思模块,该模块能够动态地综合到目前为止的对话内容,并输出一份总结性笔记,描述访谈员可以对参与者作出的推断。
例如,对于前面提到的参与者,该模块可能生成如下反思内容:

然后,在提示语言模型生成访谈员的行动时,研究者也没有使用完整的访谈记录,而是用了访谈员积累的简洁但描述性强的反思笔记,以及最近5,000字符的访谈记录。
让AI访谈员「开口说话」
为了让被试感觉自己在和真正的人类交谈,并且和面试官建立融洽的关系,团队使用了低延迟语音。
被试发言后,AI面试官通常会在4秒内做出回应。
也就是说,短短4秒内,AI就完成推理、生成、返回语音响应的全过程!因此,人类被试也会感觉无比丝滑。
参与者的语音响应,是使用OpenAI的Whisper模型转录的,这个模型能将语音音频转换为文本。
为了让被试对自己的回答进行反思,研究者会对GPT-4o使用以下提示:

而为了让GPT-4o动态生成新问题,研究者会对它使用以下提示:


果然,这样调试出来的AI访谈员非常具有同理心,能连续和人类被试进行顺畅的对话。
听到被试的童年经历后,ta会说「听说你的童年并不美好,我感到很遗憾,能告诉我你在高中的更多经历吗?」

听完被试的高中经历后,ta会贴心地进行总结,然后继续提问:「谢谢你与我分享这些。听起来高中对你来说是一个特别有挑战性、但成长很多的时期。高中毕业后,你选择了怎样的道路?是去上了大学还是直接进入职场了呢?」

让智能体模仿人类行为
那么,智能体为什么对他们的「人类原型」模仿得这么像呢?
生成式AI之所以能模拟人类行为,是因为语言模型能提供支持,然后通过一组记忆来定义其行为。
这些记忆以文本形式存储在数据库(或「记忆流」)中,在需要时被检索出来,通过语言模型生成智能体的行为。
同时,系统配备一个反思模块,将这些记忆综合为反思内容,从智能体记忆中的部分或全部文本中选择内容,以提示语言模型推导出有用的见解,从而增强智能体行为的可信度。
传统的智能体,通常依赖于手动设定的特定场景下的行为,而生成性智能体,则利用语言模型生成类似人类的响应,后者能反映其记忆中描述的人格特质,并适用于各种情境,因而这种角色扮演会格外逼真。
专家反思,弥补单一思维链缺陷
同时,研究者引进了一种「专家反思」,来从访谈记录中明确推导出关于参与者的高层次、更抽象的见解
这是因为,仅仅将参与者的访谈记录直接提示语言模型,以单一的思维链预测其反应,可能导致模型忽略受访者未明确表达的潜在信息。
在该模块中,研究者提示模型对参与者的数据生成反思,但并非仅要求模型从访谈中推导见解,而是要求它采用领域专家的身份。
具体来说,他们要求模型生成四组反思,每次以社会科学四个分支领域的不同专家身份进行:心理学家、行为经济学家、政治学家和人口统计学家。

每个智能体的记忆包括采访记录和专家对该记录的反思的输出。这些思考是使用语言模型生成的简短综合,用于推断可能未明确说明的参与者的见解。专家社会科学家(例如心理学家、行为经济学家)的角色,则会引导这些反思
例如,对于某一访谈记录,不同专家身份生成了不同的见解:

心理学家会认为,被试者很重视自己的独立性,喜欢出差,对母亲的过度管束感到不满,对个人自由表现出了强烈渴望。
在行为经济学家看来,他能够将财务目标与休闲需求很好地结合起来,追求平衡的生活。
政治科学家看来,他自认是共和党人,并大力支持该党派的理念,但同时也兼具两党的立场。
人口统计学家的答案则是,他是一名库存专家,月薪3000到5000美元,家庭月收入7000美元,工作具有一定的稳定性和灵活性。
对于每位被试,研究者都会把ta的访谈记录提示给GPT-4,并要求它为每位专家生成最多20条观察或反思,从而生成了四组反思。
这些提示根据每位专家的角色进行了定制。比如针对人口统计学专家的提示示例如下:

想象一下,你是一位人口统计学专家(拥有博士学位),在观察这次采访时做了笔记。写下对受访者的人口统计特征和社会地位的观察/反思。(你的观察应该多于5个且少于20个,考虑上述访谈内容的深度,选择有意义的数字。)
这些反思生成后,就会被保存在智能体的记忆中。
需要预测被试的回答时,研究者会让语言模型对问题进行分类,判断哪个专家最适合回答该问题,然后检索出该专家生成的所有反思。
研究者会将反思附加到参与者的访谈记录中,并用其作为提示输入GPT-4,以生成预测回答。
参考资料:
https://arxiv.org/abs/2411.10109
https://x.com/percyliang/status/1858556930626908569
(举报)








发表评论取消回复