声明:本文来自于微信公众号 数字生命卡兹克,作者:数字生命卡兹克,授权热心网友转载发布。
就在刚刚,智谱宣布全新迭代的AI视频模型“新清影”,正式上线。
10s、4k、60帧,还能自带生成挺匹配的AI音效。
视频模型已经上线智谱清言上,人人可用。音效模型这个月也即将上线。
这个点,其实还好,就是线上模型迭代升级了一版而已。
但是最牛逼的是,他们直接宣布,把这个“新清影”背后的底层模型,也就是CogVideoX v1.5,直接开源了。。。

我觉得他们疯了,真的。
上上周发类似GPT4o那种端到端的语音对话模型也是,直接发布即开源。

真的,智谱给我整不会了。
周二才夸过腾讯混元,开源了他们参数最大的MoE模型混元Large和AI3D模型Hunyuan3D-1.0。
现在智谱直接接力,直接开源了他们内部效果最好的AI视频模型。
还是那句话,对于每一个愿意开源,让社会、让开源社区,百尺竿头更进一步的公司。我都永远报以最崇高的敬意,和最大的善意。
CogVideoX v1.5我也第一时间去测试了一下。
开源地址在此:https://github.com/thudm/cogvideo
普通用户也可以去智谱清影上玩。
我放一些我自己跑的case吧。


非常坦率的讲,智谱的新清影,跟上一代比,已经进步巨大了。
不管是审美、还是动作幅度、还是物理规律、还是稳定程度。
真的,上一代的人物变形变得我到现在都还记忆犹新。
但是如果你要把他跟业界最好的比,比如你跟豆包PixelDance比分镜比运镜,那肯定还是差了一定距离的。
毕竟这一版的新清影,在版本号上,还是一个折中的阶段,也就是CogVideoX v1.5,而且他们进步速度还是飞快的。
当时8月也是第一个把生视频全面公开让c端来玩的,说实话也勇气可嘉。
而且我问了一下内部人,参数量更大更新更强的模型正在训练,如果等过两个月CogVideoX v2.0阶段,可能又会来一波进化的飞跃。
当然,不管怎么样,智谱敢把新清影发布即开源,就凭这点,我赞智谱一声勇士。
上一次他们开源CogVideoX,直接给开源社区贡献了一波大力。
一群老外直接玩的飞起。
比如微调一个自己的视频模型。
比如微调一个室内设计的专属视频模型。
等等等等。
AI绘图的开源生态已经被玩出花了,但是AI视频的生态,确实还是非常的贫瘠,不管是配套插件,还是微调方式,还是模型数量等等,都还远远处于起步阶段。
希望这一波新清影CogVideoX v1.5的开源,能让AI视频的开源社区和生态,继续沸腾一次。
除了CogVideoX v1.5的开源之外,还有另一个东西我觉得非常值得说,虽然它还没有上线,但是在这次的demo里一窥了真容。
就是智谱的AI音效模型。
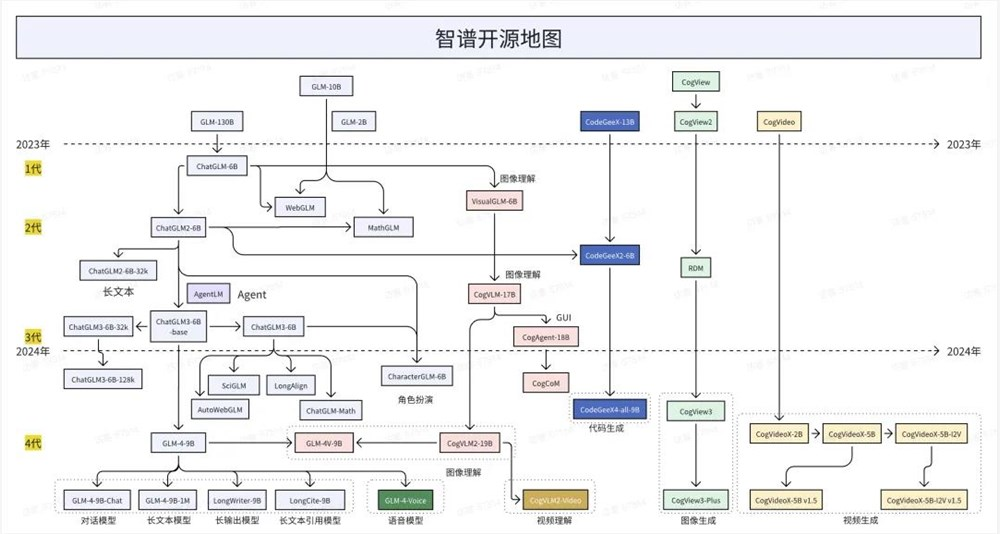
智谱可能是我知道的,唯一一个,什么模态都做的,关键,每个模特居然做的都还不错。
我真的,尊称一声模型法王。
给你们数一下。
文本生成 -GLM
图像生成 -CogView
视频生成 - CogVideoX
音效生成 - CogSound
音乐生成 - CogMusic
端对端语音 - GLM-4-Voice
自主代理 - AutoGLM
图像理解 - CogVLM
...
这些,还不包括代码生成、图片理解、视频理解等等。。。
我只能说一句佩服。
说回智谱的这个AI音效模型。
通俗的理解,就是给一段视频,配上音效。
我先放两个case,这两case都是清影生的视频,然后用他们的AI音效模型CogSound配音。
这小音效还是挺适配的。也可以传一段现有的视频素材进去。

比如这是我很喜欢的一部电影《妖猫传》里的经典镜头,而这次,整段音效,都是我把视频片段扔给智谱后,他们配的。

感觉非常好,甚至最后的烟花爆炸的声音,都跟烟花爆炸的那一刻,精准的对上了。
我之前在11Labs的AI音效评测中也说过,音效设计,一直是一个非常重要、难度极高但又容易被大家忽视的领域。
一部片子或者游戏能让你沉浸进去,你可能更多的会夸他的剧情、画面、配乐,但是很少有人会去夸他的音效,比如夸你这个关门声关的真真实等等。
但是音效,是沉浸感中绝对重要的一环,而做一个优秀的音效,有时候难度更是超高,比如《哥斯拉》里面经典的吼声。
制作团队用了很多种方法去做哥斯拉的吼,比如用干冰升华时在金属通风管道中造成的震动和尖叫制作出了哥斯拉金属质感的长啸,比如他们在抛光过的地板上用大木箱拖动,拖出了那一阵阵令人毛骨悚然的胸腔共鸣。
这才有了这史上最著名的怪兽的惊鸿一瞥。
现在,你可以用智谱的AI音效,生成一段哥斯拉的吼声。
质感上肯定跟原版那种极致的特斯拉还差了一些,但是也是极好的开头。
音效,真的很重要。而AI音效的产品,其实从今年3月,就出来了不少的。但是都有一个问题。
就是他们的AI音效设计,是直接用文字生成音频的。
比如PIKA很早的时候就做了生成的AI视频自带音效。

但是跟画面的匹配度,其实极低。因为是纯粹的文字生成音效后,再直接把这个音效音轨给你拼到视频里,至于合不合拍,那就纯靠人品,比随机还随机。
但是智谱这次的做法,非常的有趣。
他们是先把视频过一遍他们自己的视频理解模型,然后得到画面关键信息,再用画面关键信息和prompt,去生成音效模型。
这样的做法,音效和画面的匹配度,就实在是高太多太多了。
为啥别人家不这么做呢?废话,因为别人家没有视频理解模型啊...
智谱的全模态模型的生态,虽然之前都是一个一个小点,但是我有一种感觉,就是未来的某一天,这些小点会逐渐连成线,结成网,最后形成一道坚不可摧的巨大的面。
这可能,就是生态的优势吧。
穷则独善其身,达则兼济天下。
我爱每一个愿意开源的公司。
当OpenAI变成CloseAI。
智谱接过了那个Open的大旗。
然后高喊出那一句。
China,No.1!
(举报)








发表评论取消回复