声明:本文来自于微信公众号量子位 | 公众号 QbitAI,作者:小明,授权热心网友转载发布。
一夜之间,AI编程模型的开源王座易主了!

Qwen2.5-Coder-32B正式发布,霸气拿下多个主流基准测试SOTA,彻底登上全球最强开源编程模型宝座。
更重要的是,在代码能力的12个主流基准上,Qwen2.5-Coder-32B与GPT-4o对决,斩获9胜,一举掀翻闭源编程模型的绝对统治。
不用一行代码,只要输入最直接、够详细的自然语言prompt,它就能给你整全套:
比如,做个简单的模拟三体运动的HTML网页吧!
哪怕是完全不懂编程的小白,也能轻松上手。比如我们体验了一把用一句大白话生成计算器:
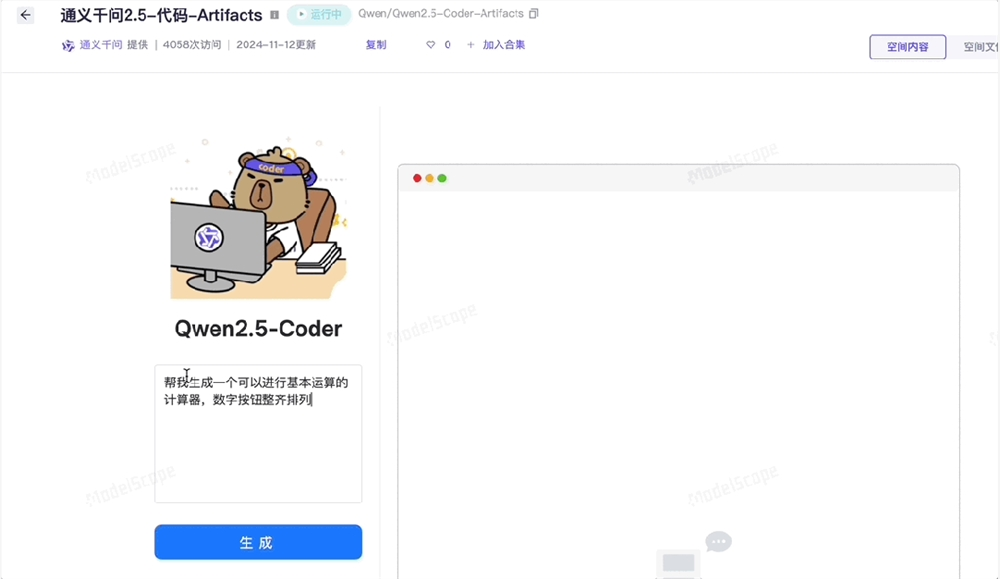
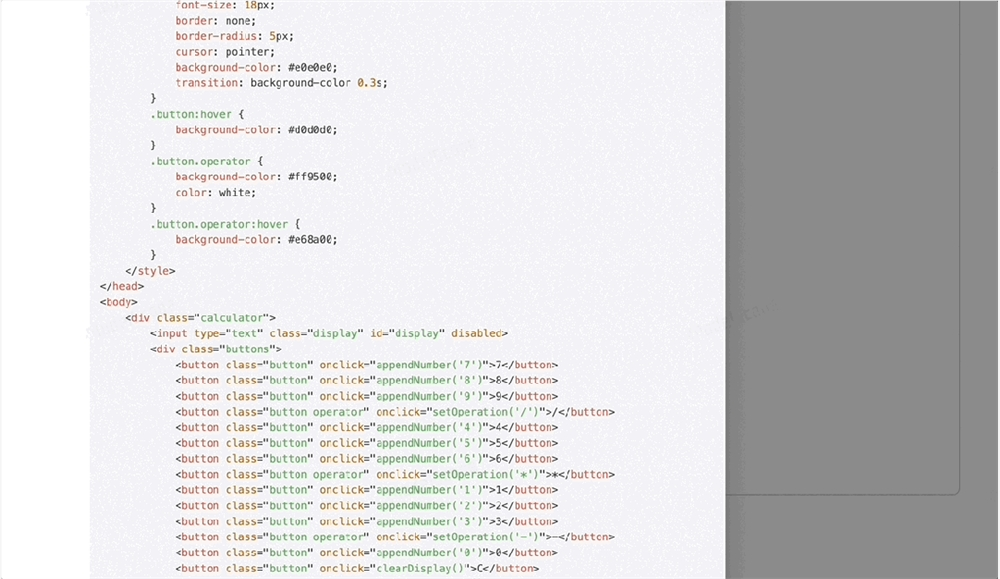
很快就搞定了,计算器可以直接使用。
还有更多好玩又实用的应用,比如不到20秒生成一个音乐播放器。
做简历也易如反掌:
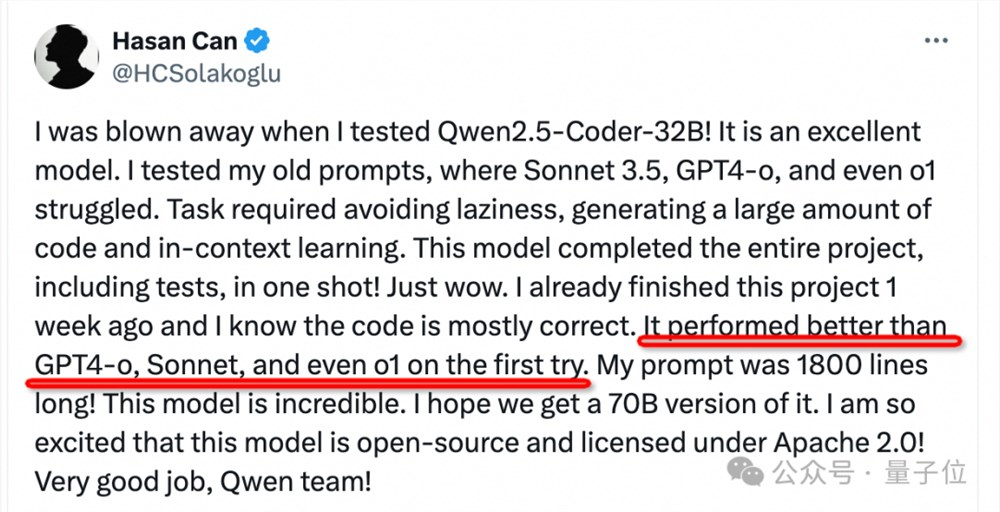
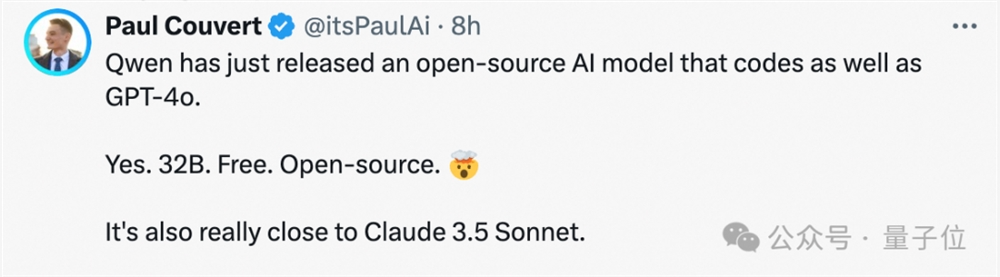
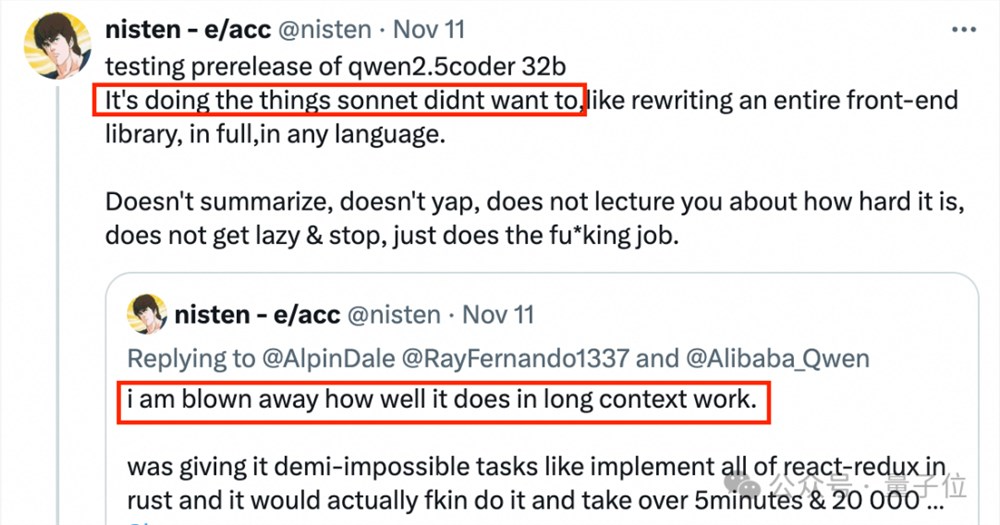
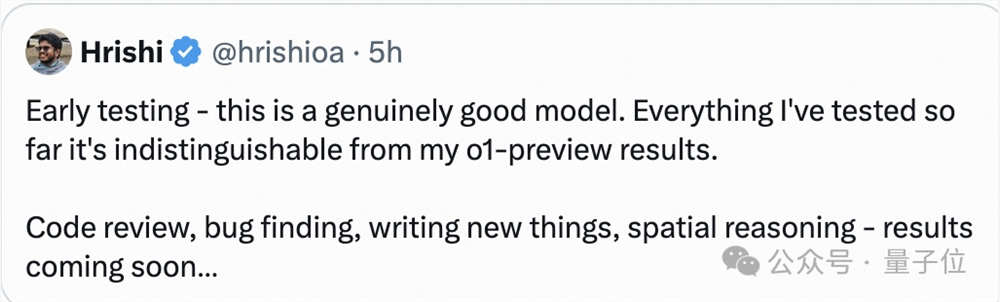
怪不得开发者们都说,太恐怖了,超越了4o,与Sonnet、o1都能掰手腕!
更让人惊喜的是,这次Qwen2.5-Coder上新,共开源0.5B/1.5B/3B/7B/14B/32B共6个尺寸的全系列模型,每种尺寸都取得同规模下SOTA。
而且大部分版本都是采用非常宽松的Apache2.0许可。
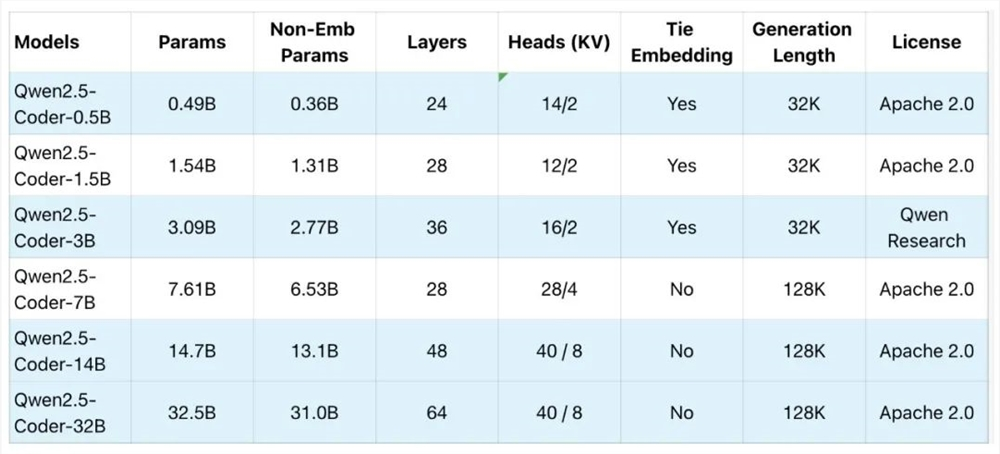
△蓝色为此次新发布版本
要知道,自从CodeQwen1.5推出以来,该系列模型就成为开发者社区最关注的开源编程模型之一。
9月发布的Qwen2.5-Coder-7B版本,更是一骑绝尘,不少人表示它足以替代GPT-4和Sonnet3.5成为日常主力工具。
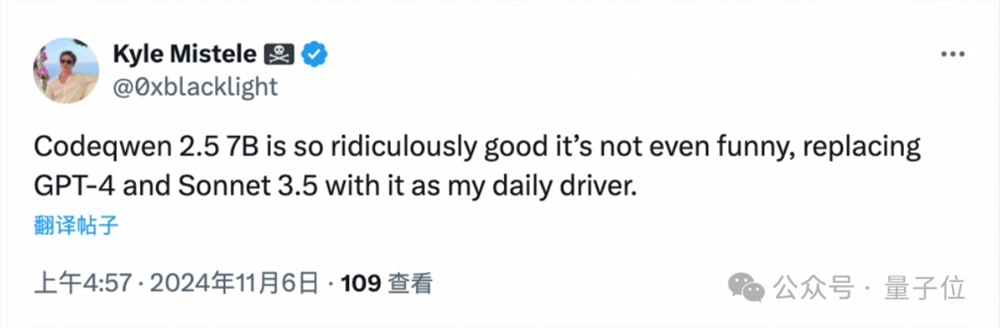
当时还预告了32B的发布,从此,网友一直催更。
这次,32B和更多尺寸的全系列Qwen2.5-Coder如约而至,这个看起来能用code生万物的最强开源代码模型,到底厉害在哪儿呢?
超越GPT-4o,人人都能用
首先,我们为什么关注编程模型?因为代码能力对大模型的推理很重要,大模型对代码的理解通常被认为是其逻辑能力的基础来源之一。
代码思维链(program-of-thought)将复杂问题分解为可执行的代码片段,并且利用代码执行器逐步解决子问题,可以较大程度提升基于大型语言模型的推理能力。
DeepMind斯坦福UC伯克利联手发表的一项研究中提到,使用代码链(Chain of Code),不仅可以提升模型基于代码的推理能力,也给模型自然语言任务、数学计算方面带来积极影响。
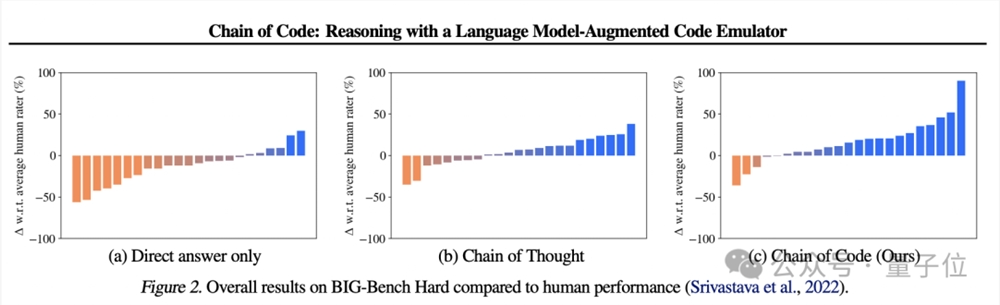
△https://arxiv.org/abs/2312.04474
Qwen2.5-Coder也采用了类似原理。它基于Qwen2.5基础大模型进行初始化,使用源代码、文本代码混合数据、合成数据等5.5T tokens的数据持续训练,实现了代码生成、代码推理、代码修复等核心任务性能的显著提升。
最新发布中,Qwen2.5-Coder全系列共开源6个尺寸模型,每个规模包含base和Instruct两个版本。
Base模型为开发者可以自行微调的基座模型,Instruct模型是可以直接聊天的官方对齐模型。
团队评估了不同尺寸Qwen2.5-Coder在所有数据集上的表现,不但均取得同等规模下最佳性能(无论开闭源),并且还验证了Scaling Law依旧奏效。
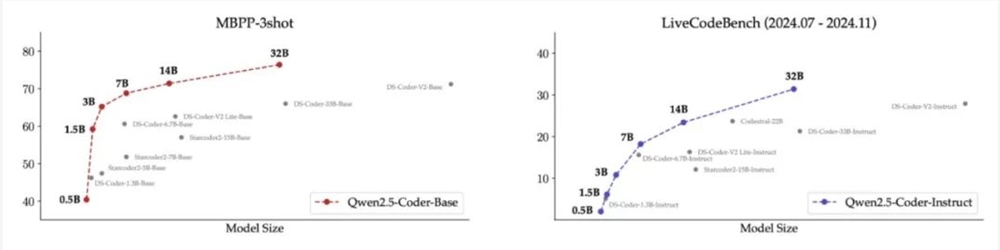
其中,Qwen2.5-Coder-32B-Instruct是本次开源的旗舰模型。
在编程大模型主要关注的5个方面上,它都实现了对GPT-4o的超越:
代码生成
代码修复
代码推理
多编程语言
人类偏好对齐
首先来看编程模型最核心的能力——代码生成。
Qwen2.5-Coder-32B-Instruct在多个流行的代码生成基准上都取得了开源SOTA。
而且在HumanEval、McEval、Spider、EvalPlus、BigCodeBench等基准上,都超越了闭源的GPT-4o和Claude3.5Sonnet。
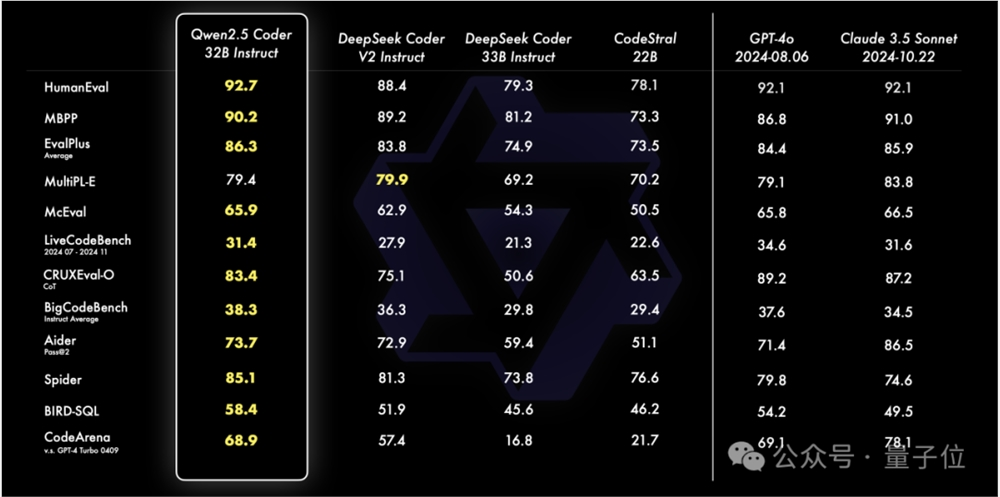
其次,代码修复方面,在主流基准Aider上,Qwen2.5-Coder-32B-Instruct略胜GPT-4o。
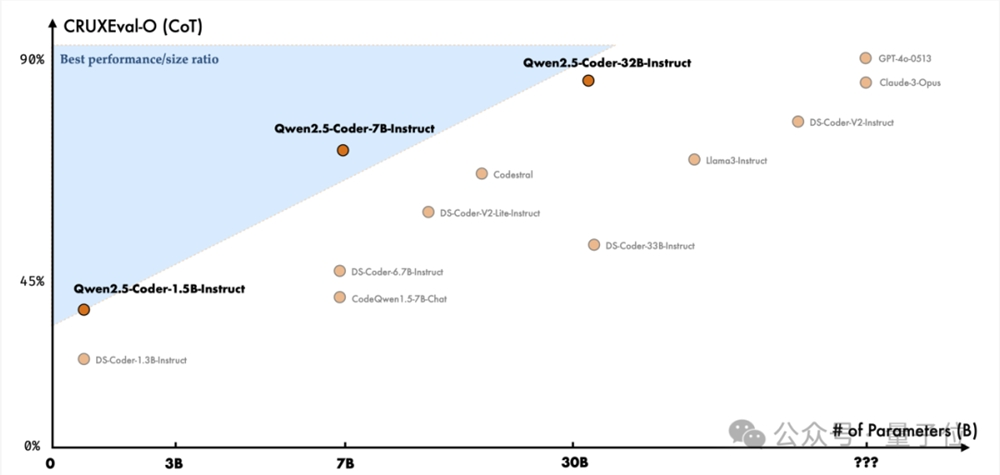
第三,代码推理方面,在CRUXEval基准上,32B版本较7B版本有了明显提升,甚至达到了和GPT-4o、Claude3Opus相当的水平。
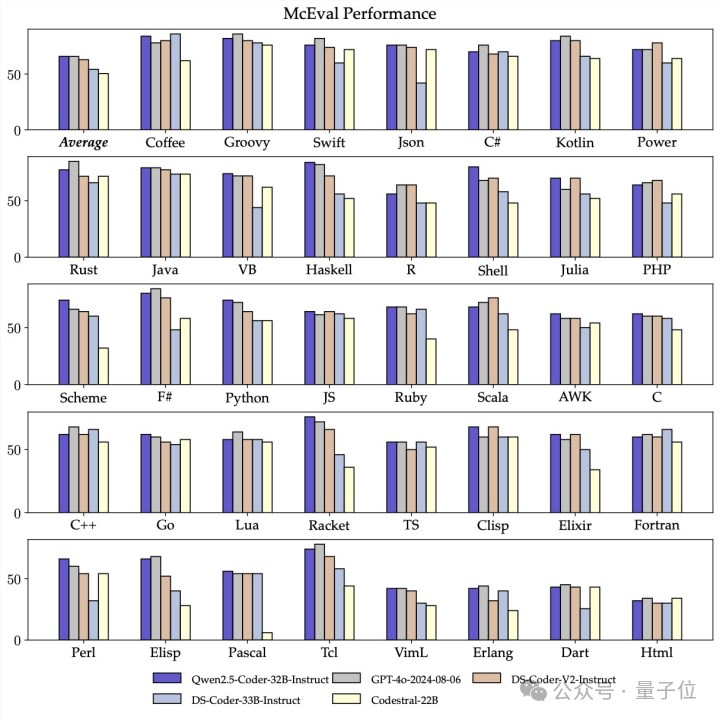
第四,在对多编程语言的掌握上,Qwen2.5-Coder支持92种编程语言。Qwen2.5-Coder-32B-Instruct在其中40多种语言上表现出色。
在Haskell、Racket等语言上表现格外突出,打败4o等闭源模型同时取得了超高分数。
通过在预训练阶段进行独特数据清洗和配比,它在McEval上取得65.9分,
在多编程语言的代码修复基准MdEval上,同样表现突出,取得75.2分,位列所有开源模型第一。
最后,为了检验Qwen2.5-Coder-32B-Instruct在人类偏好上的对齐表现。通义千问团队还构建了一个来自内部标注的代码偏好评估基准Code Arena,可以理解为编程大模型竞技场。
这一部分,Qwen2.5-Coder-32B-Instruct和闭源模型正面PK,通过让两个模型在同样问题下PK,计算最终胜负比,以此来评判模型表现。
实验结果显示,Claude3.5Sonnet战绩最好,Qwen2.5-Coder-32B-Instruct和GPT-4o水平相当,胜率为68.9%。
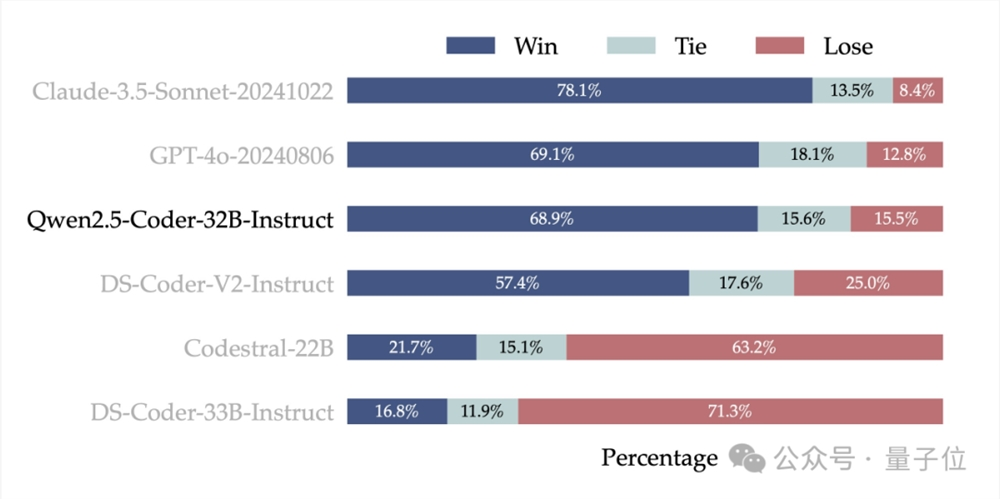
总的来看,Qwen2.5-Coder-32B-Instruct毫无疑问是开源最佳,并且真正拉平甚至部分超出了有最强代码能力的闭源模型。
在实际应用上,通义千问团队演示了基于Qwen2.5-Coder打造的智能代码助手,并上线了一个Artifacts应用。
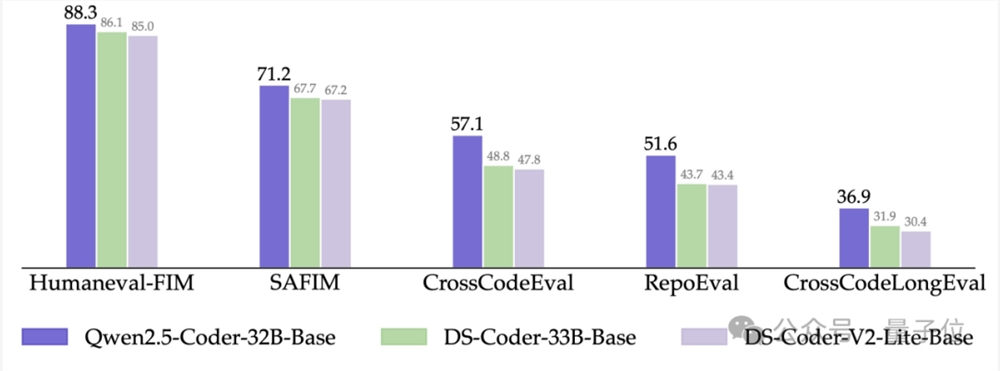
目前智能代码助手领域主要以闭源模型为主,Qwen2.5-Coder为开发者提供了开源选择。
它在几个可以评估模型辅助编程的基准上(CrossCodeEval、CrossCodeEval、CrossCodeLongEval、RepoEval、SAFIM)都取得了SOTA。
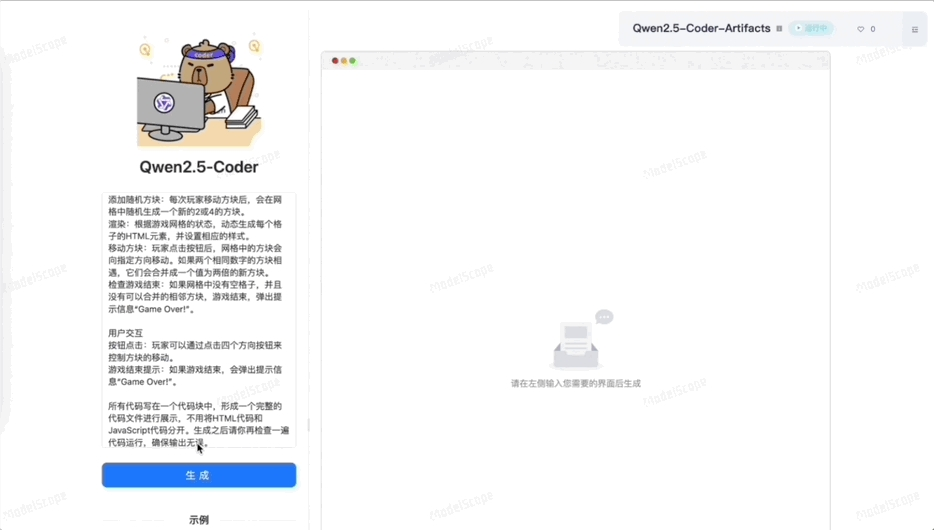
新的Qwen2.5-Coder,对编程小白也很友好,一句话就能开发小应用/游戏。
比如现场自动做一个2048小游戏,几十秒搞定,立刻就能玩。
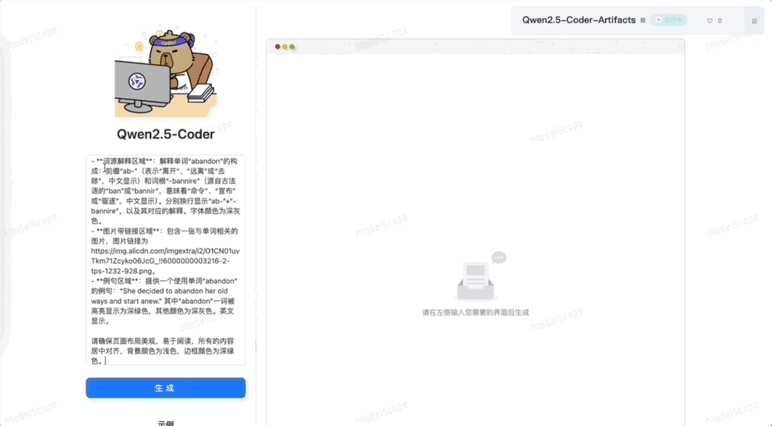
或者是生成一个图文并茂的英语单词卡页面,速度都非常快。
被全球开发者追捧的中国开源模型
Qwen2.5-Coder-32B的快速推出可以说是众望所归。
就在前段时间,Reddit还有帖子提问,怎么32B版本还不来?
毕竟,不少人都基于9月开源的Qwen2.5-Coder-1.5B和7B版本,打造出了热度颇高的应用。
比如Qwen Code Interpreter。这是一个类似于ChatGPT的代码解释器,可完全在本地/浏览器上运行,基于Qwen2.5-Coder-1.5B打造。

只用小模型还实现了非常好的效果,这立刻引发不少网友的关注,一个随手推荐帖就有近千人点赞。

还有人基于Qwen2.5-Coder打造了专门用于rust语言的编程助手。
说Qwen2.5-Coder是最受欢迎的开源编程大模型绝不为过,事实上,每一代Qwen编程模型,都代表了开源的最高水平,PK的永远是当时最厉害的闭源模型。
今年4月,CodeQwen1.5-7B发布,在基础代码生成能力上,它表现出超过更大尺寸模型的潜力,拉近了开源模型和GPT-4之间的编程能力差距。
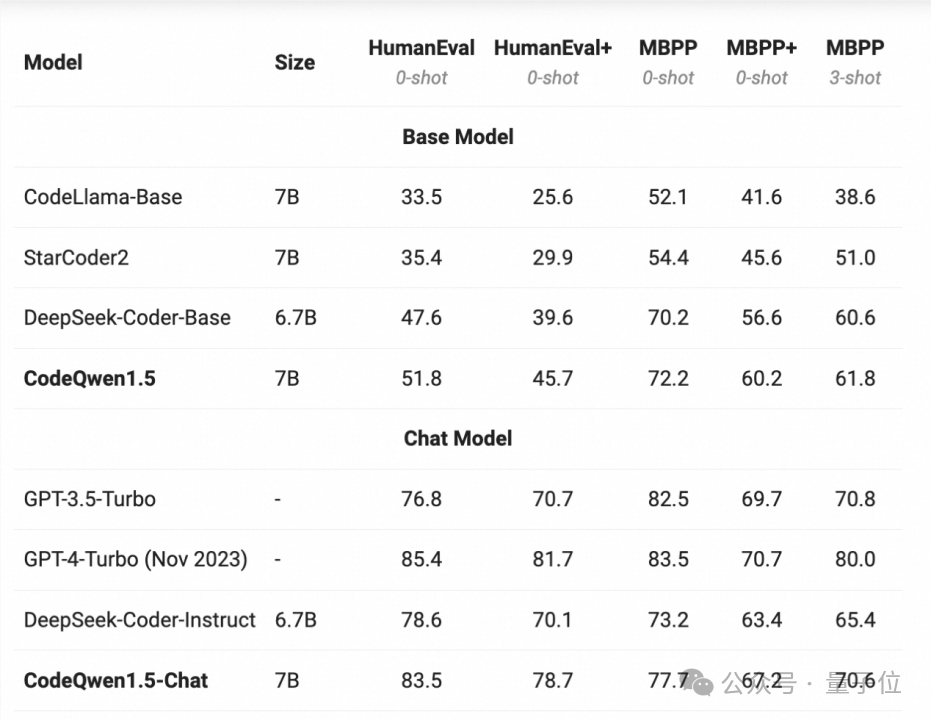
之后在云栖大会上,Qwen2.5-Coder-1.5B/7B发布。作为Qwen2.5家族的一员,Qwen2.5-Coder-7B打败了当时比它尺寸更大的DeepSeek-Coder-V2-Lite和Codestral-20B,成为最强基础编程模型之一。
在此基础上,Qwen2.5-Coder-32B的推出,将规模提升一个数量级达到百亿参数,能力也进一步涌现,水平超越GPT-4o,逐渐逼近闭源模型王者Claude3.5Sonnet。
闭源模型山头几个月一换,而开源的Qwen却从来没有停下攀登的脚步,也进一步验证,开源模型和闭源模型之间的差距正在缩短,开源模型完全有机会、有能力取代闭源模型,为全球广大开发者用户提供更加低门槛、开放的AI能力。
随着AI应用趋势不断演进,越来越多领域和行业加入,对AI模型的性能、开发成本以及上手门槛都会提出更高要求。反之,易用的开源模型将成为推动这股趋势的重要动力。
Qwen系列的爆火就是这种正向循环最好的证明之一。截至9月底,全球基于Qwen系列二次开发的衍生模型数量9月底突破7.43万,超越Llama系列衍生模型的7.28万。
通义千问Qwen已成为全球最大的生成式语言模型族群。
而背靠阿里——全球云计算和AI的第一梯队玩家,一方面,深厚技术和资源支持为Qwen系列的持续开源、不断升级提供更可靠保障,另一方面,阿里自身业务及发展上的需要也构成了Qwen继续攀登高峰的内在闭环。
不过开源模型最大价值还是要回归开发者。
AI的到来,让天下没有难开发的应用。
Qwen作为中国开源大模型领军者,为全球开发者提供更丰富的选择,也代表中国创新力量在全球大模型竞技中登台亮相,并且正在得到更多人的认可。
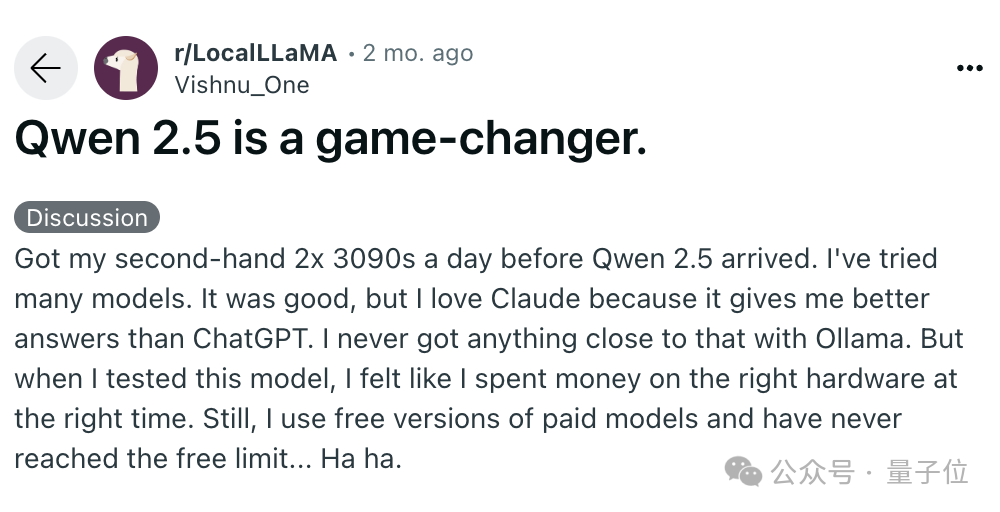
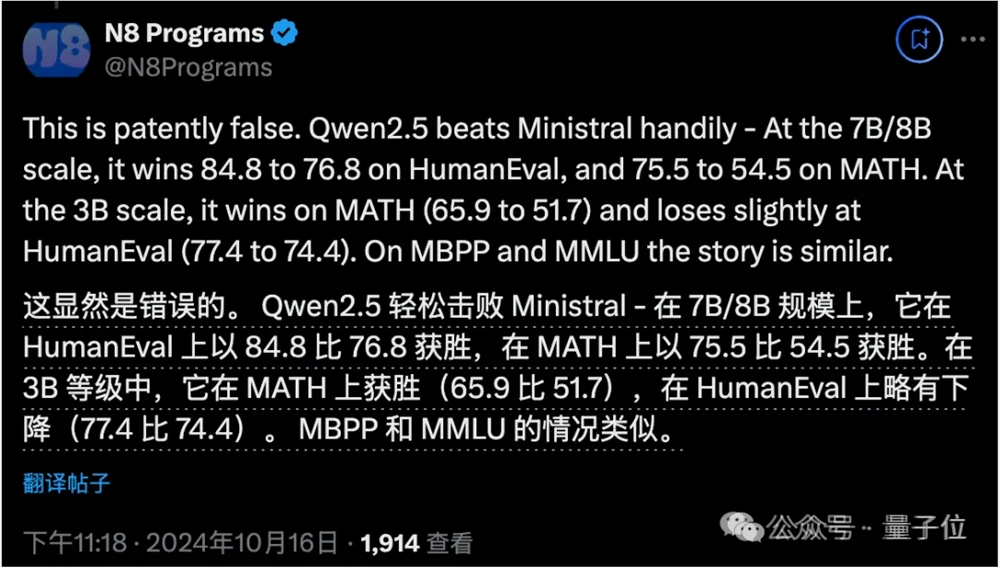
嗯…比如前段时间Mistral发布的端侧模型没有和Qwen2.5做对比,还被小小吐槽了下(doge)。
值得一提的是,据透露Qwen3已经在路上,预计在几个月内和大家见面。可以期待一下~
关于Qwen2.5-Coder的更多信息,可直接通过下方链接了解。
GitHub地址:
https://github.com/QwenLM/Qwen2.5-Coder
技术报告:
https://arxiv.org/abs/2409.12186
(举报)








发表评论取消回复