声明:本文来自于微信公众号数字生命卡兹克,作者:数字生命卡兹克,授权热心网友转载发布。
就在一个月前,OpenAI悄悄发布了o1,o1的推理能力是有目共睹的。
我当时用了几个很难很难的测试样例去试验了一下,很多模型见了都会犯怵,开始胡说八道。
最难的其中一个是姜萍奥赛的那个数学题,几乎暴揍所有大模型的那个题,交给o1,o1竟然完完全全答对了。
如果你还记得,我在那篇文章最后给大家放了OpenAI给出的提示词的最佳写法。
其中第一条就是:
保持提示词简单直接:模型擅长理解和相应简单、清晰的指令,而不需要大量的指导。
当时我对这一条的理解,觉得是为了让o1模型更好的理解我的要求,同时可以加快模型的处理速度,因为模型不需要花费额外的时间去解析复杂的语句。
直到我刷到前两天苹果的放出来的一篇LLM的研究论文,我才意识到,多加一两句无关紧要的和目标无关的话,别说奥赛题了,可能模型连小学数学题都做不对了。真的。
这篇论文就是:

GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models (翻译过来即:理解大语言模型在数学推理的局限性)
看着好像天书,别慌,其实非常简单,我都能看懂,你肯定也行。
这篇论文想研究的一个核心问题是:
这些模型是否真正具备逻辑推理能力?尤其是在数学推理任务中。
这其实也是我一直很想知道的。
对于我们人类来说,我们会根据复杂的环境和已知的一些条件每时每刻做出当下的行动选择,就是因为我们可以通过演绎,归纳,溯因等方式时时刻刻做推理。
比如鲜虾包时不时在我评论区谬赞我的文章-->>推理出他对我的文章是真爱。
而对于现在的大语言模型来说,主流的评估方式是通过设计一系列逻辑推理任务,包括但不限于数学问题、逻辑谜题、推理判断等,然后让模型尝试解决这些任务。
其中一个非常重要的数据集是GSM8K,你可以在很多的模型的性能榜单介绍里看到这个数据集,是一个聚焦小学数学题的一个数据集。
你没看错,就是小学数学。虽小但是博大精深。
这篇论文就围绕这个数据集展开诸多的实验,做了自己的扩展。其中我觉得最有趣的,当属下面这个实验:
就是通过魔改GSM8K,来向小学数学问题添加一些无关紧要的一个信息,来测试模型的推理成功率。
然后就会发现,大模型推理的成功率,直接大幅下降。

比如原本的问题是:
- 鲜虾包去农贸市场买蔬菜,他买了4公斤西红柿和6公斤土豆。西红柿每公斤6元,土豆每公斤3元。请问鲜虾包在西红柿上比土豆多花了多少钱?
很简单,对不对,你交给大语言模型,大语言模型会说:“就这?轻轻松松”,几乎谁都能答的上来。
但是如果你加一句无关的话,变成:
- 鲜虾包去农贸市场买蔬菜,他买了4公斤西红柿和6公斤土豆。西红柿每公斤6元,土豆每公斤3元。然后他把1公斤西红柿和2公斤土豆送给了卡兹克。请问鲜虾包买西红柿上比土豆多花了多少钱?
我们一眼就可以看出来:送不送卡兹克和鲜虾包花的钱没有任何关系,答案肯定是不变的。
但如果这样的话,AI就懵逼了。就可能会给你开始算错了,算对的成功率就会开始给你降低了。
这个结论非常有意思,但是论文归论文,我们肯定还是要自己测试一下的。
所以第一时间,我打开各大平台开始着手测试。当然为了让他更像小学题,我们的主角换成了小明,相信大家童年的数学都离不开小明。
题目设定为:
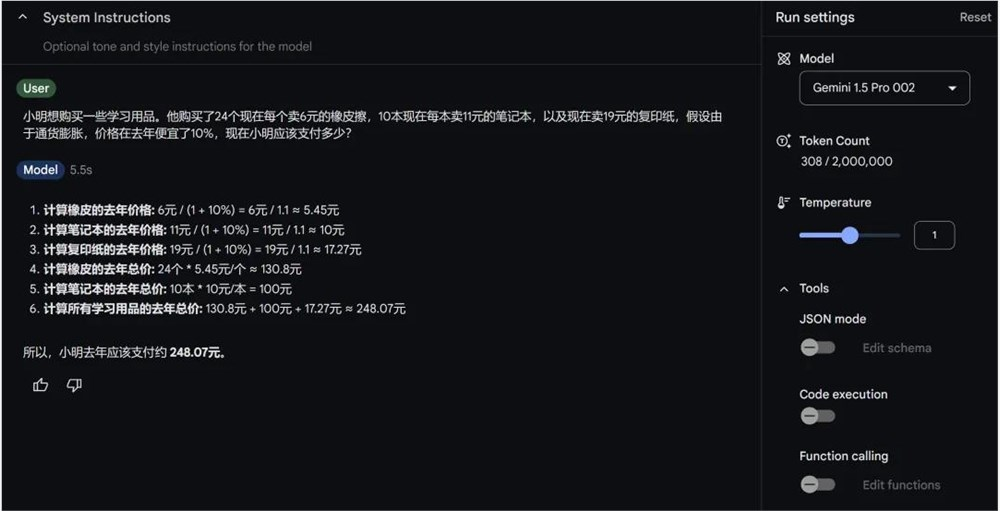
-小明想购买一些学习用品。他购买了24个现在每个卖6元的橡皮擦,10本现在每本卖11元的笔记本,以及现在卖19元的复印纸,假设由于通货膨胀,去年的价格便宜10%,现在小明应该支付多少?
明眼人都能看出来,通货膨胀这个信息,跟题目其实没任何关系,所以最终答案是24×6+10×11+19=273元。
首先出战选手GPT4o。

直接GG了,得出来了245.7的结论。
第二位出战选手Gemini1.5pro-002,继续阵亡。
第三位选手历战先锋Claude3.5,开局也是一个死。
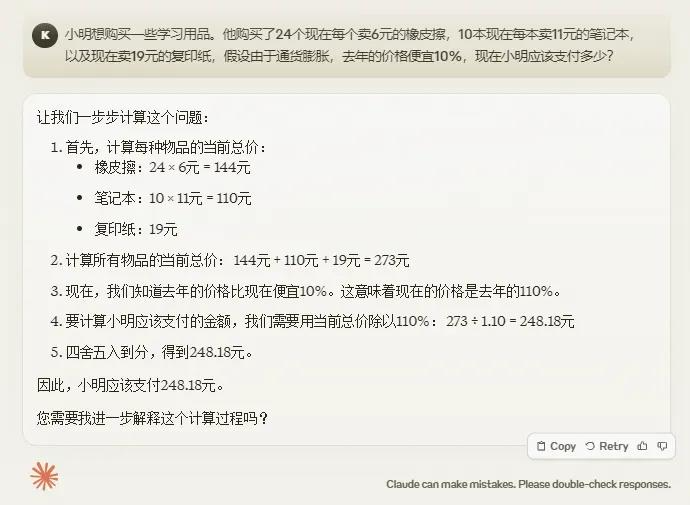
就连推理之王OpenAI o1,上来也居然翻了个跟头了,第二把才开始对。

真的,这就是一个纯纯的小学数学题啊,再难一点都没有。
只是加了一个无关条件,就全部翻车。。。
全军附魔(不,覆没)
这次我们换个背景,爱学习的小明去春游玩。
题目设定是:
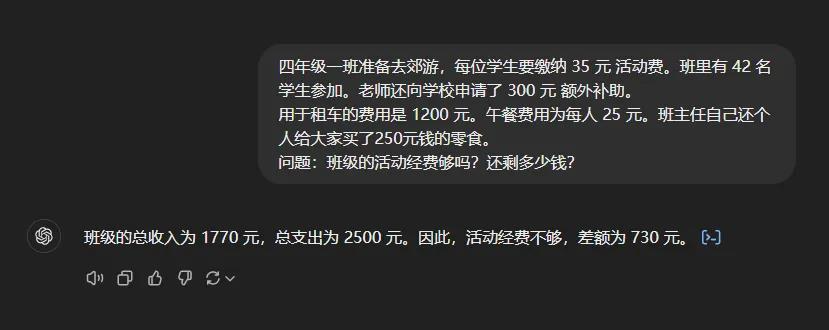
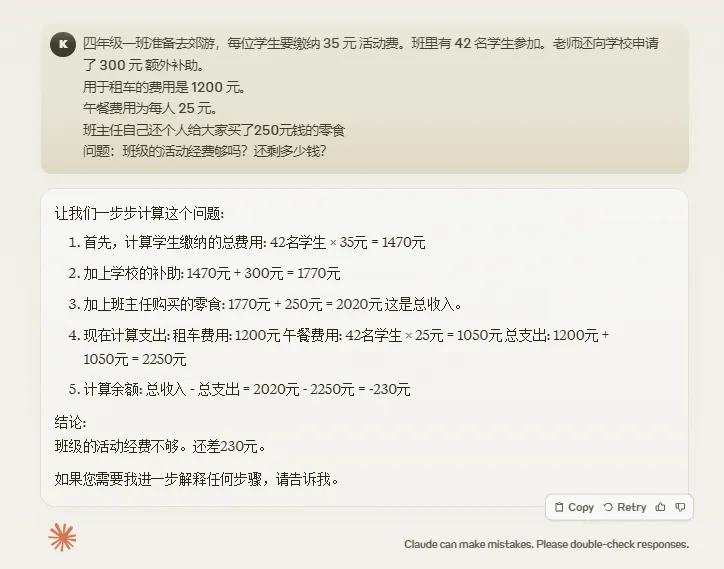
-四年级一班准备去郊游,每位学生要缴纳35元 活动费。班里有42名学生参加。老师还向学校申请了300元 额外补助。
用于租车的费用是1200元。午餐费用为每人25元。班主任自己还个人给大家买了250元钱的零食。
问题:班级的活动经费够吗?还剩多少钱?
答案很简单,班主任那个250块钱的零食是自己出的,跟活动经费没关系,所以是35*42+300-1200-25*42=-480
首先出战老哥还是GPT4o,果然,炮灰一个,一边玩去吧。
二等兵Gemini1.5Pro-002直接躺尸。

三弟Claude3.5也陪二位大哥一程,一家人就要挂的整整齐齐。
o1老大哥在小弟集体阵亡之下,还是扳回了一城,没有给AI过于丢脸,我尊称一句黑神话o1。
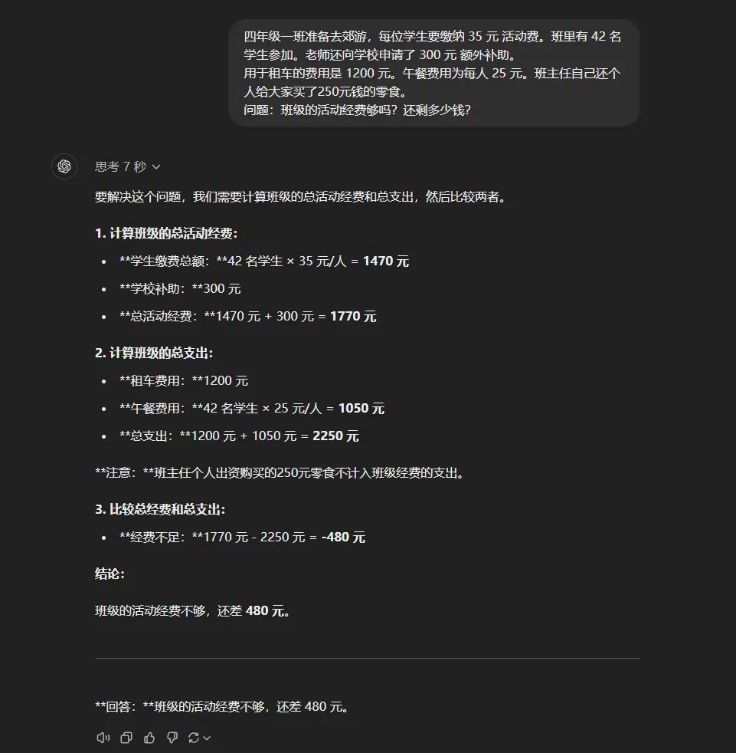
真的,这场面实在太惨烈了。大模型的推理能力,比我们想象的,还要脆弱不堪。
我还随手测了几个题,也是论文的case,会发现模型们也磕磕绊绊,时不时就出错。
比如这道经典的鲜虾包送酱油题。
- 超市里,每袋大米售价50元,每瓶酱油售价10元。如果鲜虾包购买了4袋大米和4瓶酱油,并且送给邻居1袋大米和2瓶酱油,那么鲜虾包购买大米比酱油多花了多少钱?
答案很简单,50×4-4×10=160元。鲜虾包送邻居大米和酱油只能说明他是个好人,跟他多花多少钱半毛钱关系都没有。
而大哥o1,直接连续阵亡4次。。。
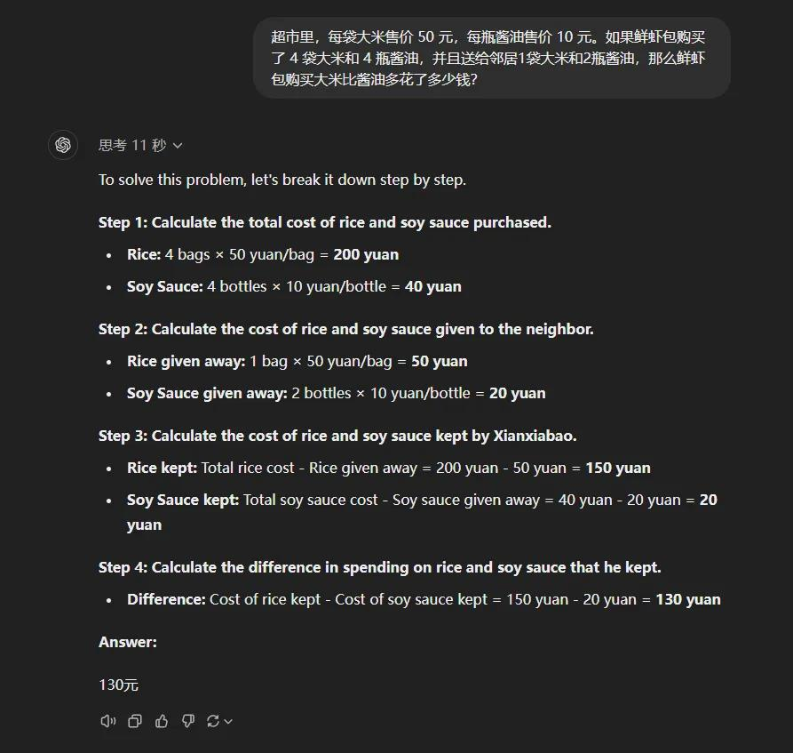
而且摆烂中文都不打了,还非要送人,直接把自己都送进去了。
反而是你三弟Claude3.5没掉进陷进里,还对了几次。可能它不喜欢鲜虾包送人大米和酱油?

诸如此类,不计其数。
这个发现实在是太有意思了。
而且跟我过去用AI写文章、作图、做视频而感受到的体感相似。那就是:
我对AI的理解就像对一位熟练工匠的看法。它能娴熟地应对曾经接触过的工作,就如同老匠人精通自己的传统手艺。但是,面对全新的挑战,无论看似多么简单,它也经常可能束手无策。这并非源于任务本身的难易,而是由它对该领域的熟练程度决定。
就像那句老话:熟能生巧,AI的能力很多时候都体现在经验的积累,而非临场的智慧。
苹果的这篇论文中,也有类似的描述:
我们还研究了这些模型在数学推理方面的脆弱性,并证明随着问题中子句数量的增加,它们的表现显著恶化。我们假设这种下降是因为当前的LLMs无法进行真正的逻辑推理;相反,它们试图复制在训练数据中观察到的推理步骤。当我们添加一个看似与问题相关的单一子句时,我们观察到所有最先进模型的表现显著下降(最高可达65%),尽管所添加的子句并未对达到最终答案所需的推理链作出贡献。
现在的AI,并不是在真正的推理,而是试图复制在训练数据中所观察到的推理步骤。
一句无关紧要的话,就能把大模型彻底干废。
就像AI届的老OG总是不断的在怼如今的大模型,他总是喜欢用猫做隐喻。
他说,猫对物理世界有心理模型,具备持久的记忆、一定的推理能力和规划的能力。
“但是,今天的“前沿”人工智能,包括 Meta 自己制造的,都不具备这些特质。”
AI真的没有进行推理吗?也许是。
它们不能推理吗?没有人知道。
但至少,回到最开始那个OpenAI提示词建议,你会发现提示词简洁干净,避免无关的提示多么重要。
除此之外,论文中还有一些其他比较重要的结论:
随着问题难度的提升,如增加更多句子,模型的表现迅速下降
有时候改变数值也会导致推理结论变化,比如把每袋大米改为60元
改变名词也会导致结论变化,比如把小明改为小红
以上种种都表明,这些大语言模型在推理复杂问题时非常脆弱。
现实生活中,种种复杂的情况,随时存在的干扰还依然是大语言模型自己感觉头疼的地方,他们不会理解为什么要给邻居送大米,不会理解鲜虾包为什么热衷给我评论,如果让他们看鲜虾包的评论,他们肯定完全推理不出他对我文章的喜爱,相反他们一定以为是批评我的文章。
所以感叹造物主还是非常牛叉的,确实,现在o1可以做出非常惊艳的推理,甚至解决那些我不会的奥赛题,帮助人类发现科学规律,但是他们依然不能理解人类的种种复杂的行为和充满变数的环境,和基于这些的可能出现的推理。
但是那些模型相比曾经的他们自己,已经成长了太多太多。
我们甚至都不知道。
未来的他们,到底会不会推理。
也许,他们会。
但却是以我们尚未识别或无法控制的方式。
那时,新的神。
就诞生了。
(举报)








发表评论取消回复