声明:本文来自于微信公众号 新智元,作者:新智元,授权热心网友转载发布。
【新智元导读】LLM训练速度还可以再飙升20倍!英伟达团队祭出全新架构归一化Transformer(nGPT),上下文越长,训练速度越快,还能维持原有精度。
AI的未来,或许就此改写......
最近,英伟达团队抛出的一枚重磅炸弹,提出了全新神经网络架构——归一化Transformer(nGPT),基于超球面(hypersphere)进行表示学习。
相较于Transformer架构本身,nGPT直接将LLM训练速度提升至高20倍,而且还保持了原有精度。

也就意味着,原本需要一个月完成的训练,在未来可能只需1-2天的时间就能搞定。
无疑为通向AGI终极目标,注入了一针强心剂!

论文地址:https://arxiv.org/pdf/2410.01131
在nGPT中,所有的向量(嵌入、MLP、注意力矩阵、隐藏状态),都被归一化为单位范数(unit norm)。
输入后的token在超球面表面上移动,每一层都通过「位移」来贡献最终的输出预测,其中位移量是由MLP和注意力模块进行定义的,其向量组件都位于同一个超球面上。
实验表明,nGPT达到相同精度所需的训练步骤减少了4-20倍,具体取决于序列长度:
-1k上下文,训练速度提高4倍
-4k上下文,训练速度提高10倍
-8k上下文,训练速度提高20倍
可以看出,上下文越长,训练越快。
Reddit网友表示,「我很好奇它还能扩展到多大程度。如果它能在更长的上下文中大幅扩展,这意味着像o1这样的模型将会获得显著的训练速度优势」。

还有人表示,「下一代模型将会更高效、更智能」。

nGPT全新架构,超球面上归一化
毋庸置疑,Transformer架构是现代大模型的基础。
不过,当前基于Transformer搭建的大模型都是计算密集型的,需要耗费大量的资源和时间。
为了改进其训练稳定性、推理成本、上下文长度、鲁棒性等方面,AI科学家已进行了大量的修改尝试。
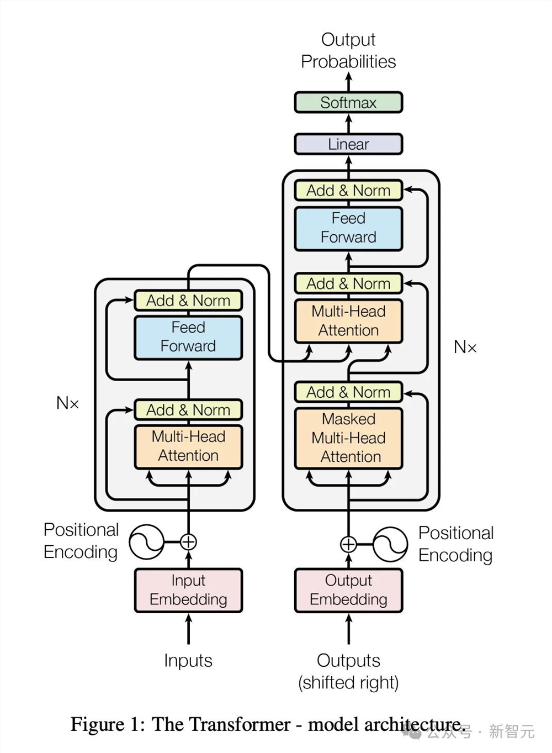
其中,最突出的发现是,归一化技术对于Transformer性能改善起着重要作用,比如LayerNorm和RMSNorm。
另一种模型归一化方法是,通过权重衰减(weight decay)控制权重范数。
不过,最新研究又对权重衰减的作用进行评估,并且转向更多地关注旋转,而非仅仅关注向量范数。
越来越多的证据表明,在超球面上进行表示学习与更稳定的训练、更大的嵌入空间可分离性以及在下游任务上的更好性能相关。
而且,还有新研究表明,Transformer隐式地执行梯度下降作为元优化器。
由此,英伟达团队提出了,在归一化Transformer新视角下,统一该领域的各种发现和观察。
这项研究的主要贡献在于:
- 在超球面上优化网络参数
建议将形成网络矩阵嵌入维度的所有向量归一化,使其位于单位范数超球面上。这种方法将矩阵-向量乘法转化为余弦相似度的计算,其范围限定在 [-1,1] 之间。而且归一化消除了对权重衰减的需求。
- 归一化Transformer作为超球面上的可变度量优化器
归一化Transformer本身在超球面上执行多步优化(每层两步),其中注意力和MLP更新的每一步,都由特征学习率控制——这些是可学习的可变度量矩阵的对角线元素。
对于输入序列中的每个token
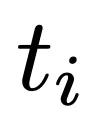
,归一化Transformer的优化路径从超球面上对应于其输入嵌入向量的点开始,移动到超球面上最能预测下一个

的嵌入向量的点。
- 更快的收敛
研究证明,归一化Transformer将达到相同精度所需的训练步骤减少了4-20倍。
Transformer演变:从GPT到nGPT
嵌入层归一化
标准的decoder-only Transformer的训练目标是根据输入序列的前序tokens来预测后面的token,在token预测时,模型会引入两个可学习的嵌入矩阵Einput和Eoutput,分别用来从输入词转为词嵌入,以及从词嵌入转为预测输出。
在模型训练期间,通常使用对应嵌入向量的点积来计算token相似度,但嵌入向量的范数(norms)不受限制的,可能会导致相似性计算存在偏差。
为了提高相似性估计的准确性,研究人员在新架构中提出,在训练算法的每一步之后,对Einput和Eoutput中的嵌入向量进行归一化。
智能体在预测文本中的下一个词时,会使用因果掩码(casual masking)来确保模型在预测token时不会「偷看」到之后的词,造成信息泄露,从而让模型能够同时预测多个词并计算预测误差,提高训练效率,同时保持了按顺序预测词的能力。
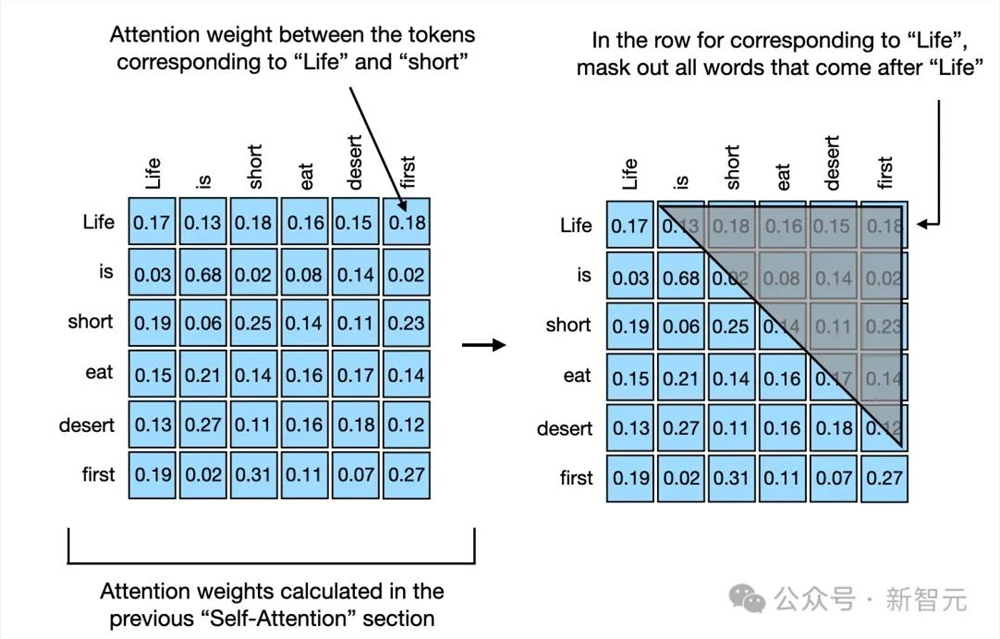
在输入词序列后,模型会在预测序列中的每个位置都生成一个输出向量,然后计算出一个logits向量zi来表示词汇表中每个词出现的可能性,可以辅助模型理解不同词在当前上下文中的重要性:
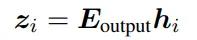
之后用softmax函数把zi转为概率值,并选取概率最高的词作为下一个词的预测。
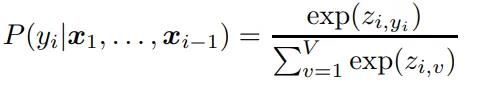
由于nGPT的嵌入矩阵已经归一化了,所以zi的值范围为[−1,1],也会限制softmax后得到的概率分布的置信度,也可以叫做温度。
为了在训练过程中调整置信度,nGPT又引入了一个可学习的缩放参数sz,通过逐元素地缩放logits,模型可以更灵活地预测的置信度,更好地学习到在不同情况下如何做出更准确的预测:
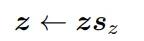
层/块归一
标准Transformer架构需要对隐藏层状态h进行L层变换,包括一个自注意力(ATTN)和多层感知机(MLP)。
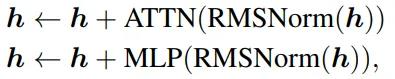
其中RMSNorm也可以替换成其他归一化(normalization)函数。
隐藏层的参数更新,其实就是在一个超平面上(维度为隐藏层的向量长度)寻找两个点(原参数和新参数)的最短距离。
1985年,Shoemake提出了球面线性插值(SLERP,Spherical Linear Interpolation),可以沿着球面上两点之间的最短路径找到中间点,研究人员发现该方法还可以通过更简单的线性插值(LERP,linear interpolation)来得到近似解,从而降低计算量:
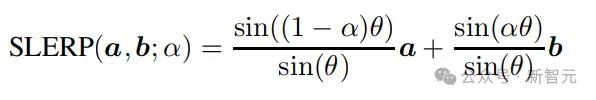
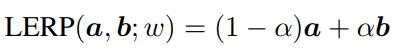
按最短路径寻找来说,参数更新过程可以描述为:
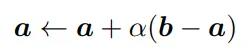
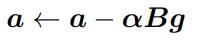
其中a和b是球面上的两个点,对应到nGPT上,a也就是隐藏层状态,b是经过注意力机制或MLP块后的状态,梯度就是g=a-b,B为可变矩阵。
在拟牛顿方法中,B可以近似于逆黑塞矩阵,当 B是一个对角线元素非负的对角矩阵时,αB就变成了一个向量,其元素对应于B的对角线元素乘以学习率α,也可以称之为特征学习率(eigen learning rates)。
eigen源自德语词,意为「自己的」(own),可以指代Transformer 的内部结构。
所以nGPT中的参数更新方程可以写为:
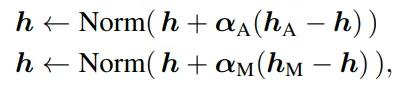
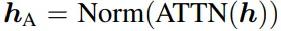
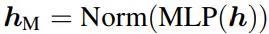
其中αA 和 αM是可学习的参数,分别用于注意力和多层感知机(MLP)模块的归一化输出 hA和 hM
与基础 Transformer 相比,在nGPT的最终层之后不需要再进行额外的归一化了。
自注意力块
注意力机制可以说是Transformer中最重要的模块,序列中的每个token都能够关注到其他所有token,从而让模型具有捕捉长距离依赖关系的能力。
模型会把处理后的信息分解成三个部分:查询(q,query)、键(k,key)和值(v,value),可以辅助确定哪些信息是重要的,以及信息之间是如何相互关联的。
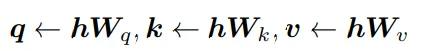
为了确保模型能够理解每个词在序列中的位置,模型中通常还会在query和key向量之间加入旋转位置嵌入(Rotary Position Embeddings,RoPE)。
然后通过计算query向量和key向量的点积、缩放、应用softmax得到注意力权重,对value向量进行加权求和,得到注意力得分。

在实践中,Transformer一般都会用到多个注意力头,其中每个头的注意力机制都是独立计算,最后再通过一个可学习的投影矩阵Wo合并所有头输出。
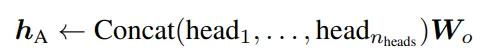
在计算注意力得分的过程中,权重矩阵没有受到太多限制,可能会导致最终得分过大或过小。
在nGPT中,研究人员对q向量和k向量进行归一化,还引入了一些可调整的参数(sqk),以确保权重矩阵在处理位置信息时不会失真,更准确地捕捉到句子中词与词之间的关系,从而做出更好的预测和决策。
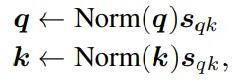
MLP块
在标准Transformer中,隐藏层收入通过RMSNorm进行归一化,然后经过两个线性投影生成中间向量(暂不考虑偏置项):
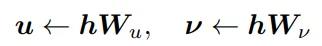
然后使用SwiGLU 门控激活函数,以及一个线性变换得到最终门控激活。
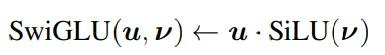
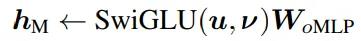
在nGPT中,研究人员提出对线性投影的权重矩阵进行归一化,并引入可学习的缩放因子,能够更充分地利用处理信息时的非线性特性,在处理复杂信息时更加灵活。
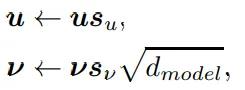
多层感知机模块的输出不会因为缩放调整而发生变化。
Adam高效学习率
Adam优化算法通过动量和梯度幅度的估计来调整每次的学习步长,同时考虑了当前及过去的梯度信息。
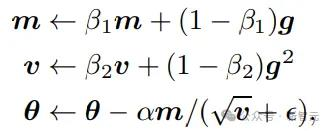
在nGPT中,研究人员同样引入了一个可训练的缩放参数向量,对特定的参数进行更精细的控制,确保每个参数都能以最适合自己的速度进行学习,从而进一步提高学习效率。
在不影响全局学习率的情况下,对特定的参数进行调整,提供了更大的灵活性和控制力。
变化总结

和基础Transformer相比,nGPT主要做了七个改变:
1、移除所有归一化层,比如RMSNorm或LayerNorm;
2、在每个训练步骤之后,沿着嵌入维度对所有矩阵,包括输入输出嵌入矩阵,以及各种权重矩阵进行归一化处理;
3、修改了隐藏层参数更新方程;
4、调整注意力机制中的softmax缩放因子,对q和k进行重新缩放和归一化;
5、对MLP块的中间状态进行重新缩放;
6、对logits进行重新缩放;
7、移除权重衰减和学习率预热步骤。
上下文越长,训练速度越快
接下来,研究人员在OpenWebText数据集上训练了基础基础Transformer(GPT)和归一化Transformer(nGPT),并在一系列标准下游任务上对其进行评估。
实验中,使用了0.5B和1B(包括嵌入)两种参数规模的模型。两种参数规模的模型0.5B和1B(包含嵌入)。

训练加速
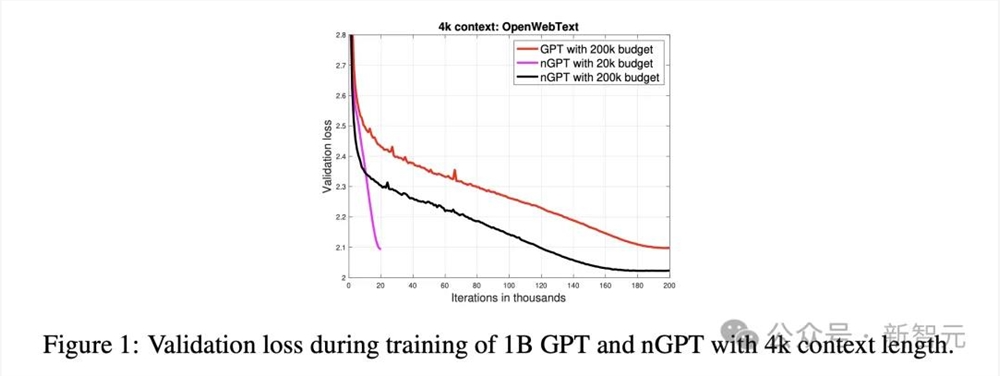
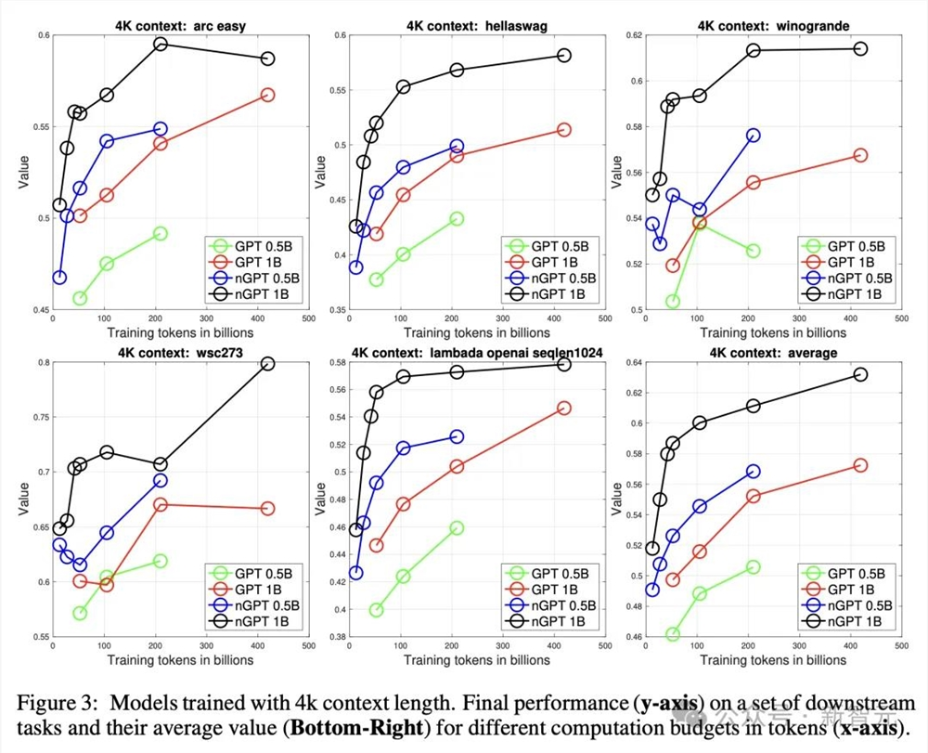
图1显示了,在训练过程中,10亿参数且样本长度为4k token的GPT和nGPT模型的验证损失。
经过2万次迭代后,nGPT达到了与GPT在20万次迭代(约4000亿个token)后,才能达到的相同验证损失。
这表明,在迭代次数和使用token数量方面,nGPT实现了10倍的加速。
再来看图2,展示了nGPT和GPT在三个方面的性能差距是如何变化的:总token数量、上下文长度、参数规模。
在1k、4k和8k token上下文中,训练0.5B和1B的nGPT模型分别约快4倍、10倍和20倍。
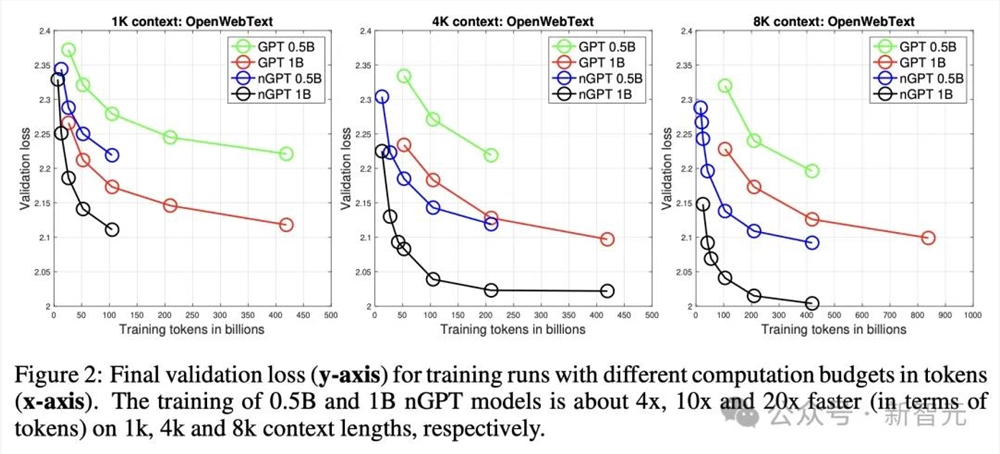
图3在下游任务中显示了类似的性能,证实加速不仅反映在困惑度上,也反映在任务表现上。
研究人员观察到,对于较长的训练运行,nGPT显示出一些饱和现象,这暗示在当前可训练参数数量下,模型容量可能已接近极限。
神经网络参数检查
图4显示,虽然nGPT保持固定的嵌入范数(这是设计使然),但GPT表现出明显的变化。
从嵌入的协方差矩阵计算得出的特征值分布(已经由其中位数归一化)显示,GPT的输入嵌入具有更高的条件数,尤其是在1B模型中。
嵌入之间的成对点积分布表明,即使在nGPT中,嵌入也并非均匀分布在超球面上(在那里点积会接近0),而是形成簇——这可能反映了语言数据中的自然模式。
由于GPT的嵌入形成了一个超椭球体(hyper-ellipsoid),如向量范数的分布所示,其点积往往具有更高的值。
GPT输入嵌入的病态性质(ill-conditioned nature)可能导致涉及这些嵌入的计算问题。

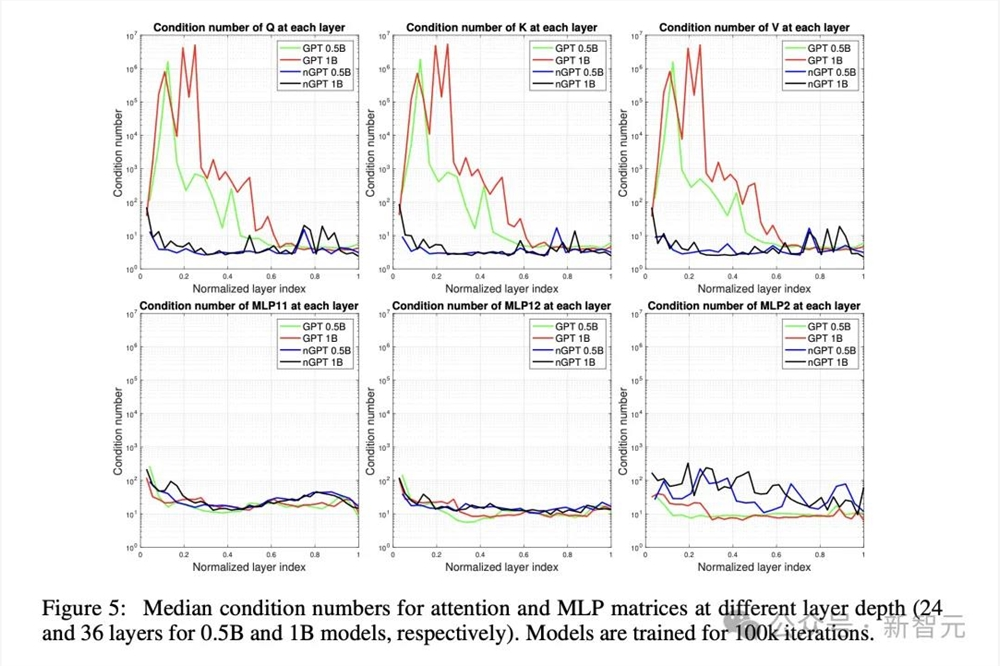
下图5展示了,注意力和MLP矩阵在不同层深度上的中位数条件数(跨多个头)——0.5B模型有24层,1B模型有36层。
与nGPT相比,GPT模型的注意力矩阵呈现显著更高的条件数。
对这些矩阵的进一步检查,GPT的注意力矩阵表现出退化为低秩矩阵的趋势,可能减少了这些块的学习容量。
下图6展示了,(左图)注意力模块和MLP模块的特征学习率,(中图)应用于MLP中间状态的缩放因子,(右图)应用于QK点积之前的缩放因子。

参考资料:
https://x.com/Marktechpost/status/1847768544777581022
https://arxiv.org/abs/2410.01131
(举报)








发表评论取消回复