声明:本文来自于微信公众号机器之心,授权热心网友转载发布。
最近,ByteDance Research 的第二代机器人大模型 —— GR-2,终于放出了官宣视频和技术报告。GR-2以其卓越的泛化能力和多任务通用性,预示着机器人大模型技术将爆发出巨大潜力和无限可能。
GR-2官方项目页面:
https://gr2-manipulation.github.io
初识 GR-2:百炼出真金
和许多大模型一样,GR-2的训练包括预训练和微调两个过程。
如果把机器人和人做比较,预训练过程就好像是人类的 “婴儿期”。而 GR-2的婴儿期与其他机器人截然不同。
在预训练的过程中,GR-2在互联网的海洋中遨游。
它在3800万个互联网视频片段上进行生成式训练,也因此得名 GR-2(Generative Robot2.0)。这些视频来自学术公开数据集,涵盖了人类在不同场景下(家庭、户外、办公室等)的各种日常活动。

这个过程,就像是它在经历一个快速的 “生长痛”,迅速学会了人类日常生活中的各种动态和行为模式。
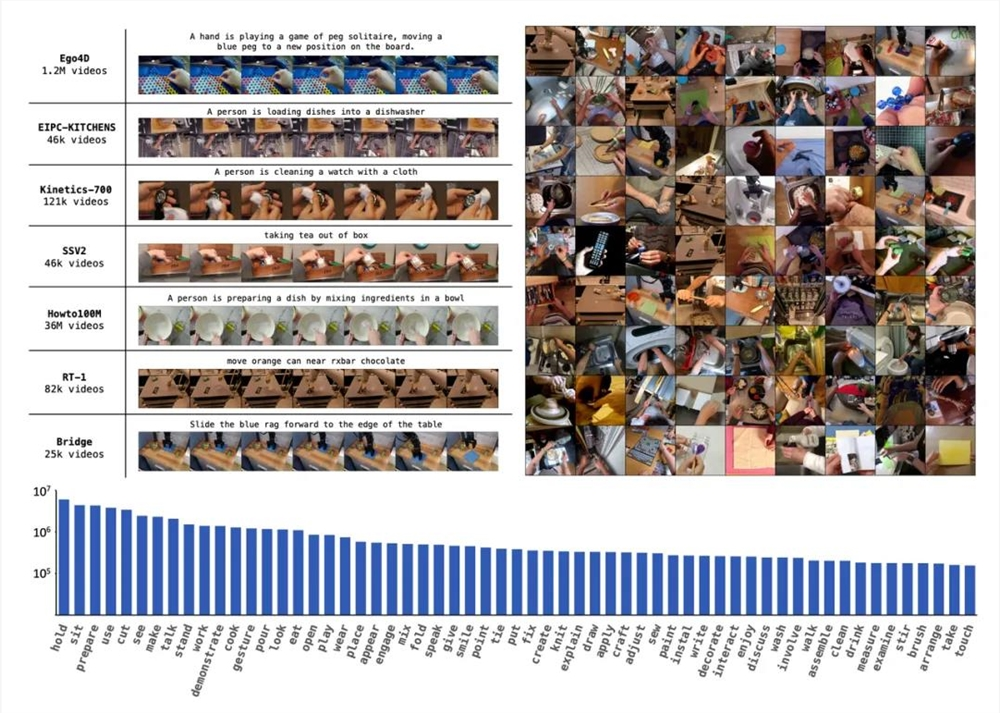
该图展示了 GR-2预训练数据中的样本视频和动词分布。下图中的 y 轴是最热门单词的对数频率。
这种预训练方式使 GR-2具备了学习多种操作任务和在多种环境中泛化的潜能。庞大的知识储备,让 GR-2拥有了对世界的深刻理解,仿佛它已经环游世界无数次。
微调的艺术:视频生成能力拔高动作准确率
据悉,GR-2的开发团队采用了一种创新的微调方法。
在经历大规模预训练后,通过在机器人轨迹数据上进行微调,GR-2能够预测动作轨迹并生成视频。
GR-2的视频生成能力,让它在动作预测方面有着天然的优势。它能够通过输入一帧图片和一句语言指令,预测未来的视频,进而生成相应的动作轨迹。
如下图所示,只需要输入一句语言指令:“pick up the fork from the left of the white plate”,就可以让 GR-2生成动作和视频。可以看到,机械臂从白盘子旁边抓起了叉子。右图中预测的视频和真机的实际运行也相差无几。

以下是几个进一步展示 GR-2视频生成能力的示例,包括把物品放进烤箱、将物品置于咖啡壶嘴下方等任务。


这种能力,不仅提升了 GR-2动作预测的准确性,也为机器人的智能决策提供了新的方向。
Scaling Law:机器人 + 大模型的要诀
在人工智能领域,Scaling Law 是一个备受瞩目的概念。它描述了模型性能与其规模之间的关系。对于 GR-2这样的机器人模型来说,这一法则尤为关键。
随着模型规模的增加,GR-2的性能呈现出显著的提升。
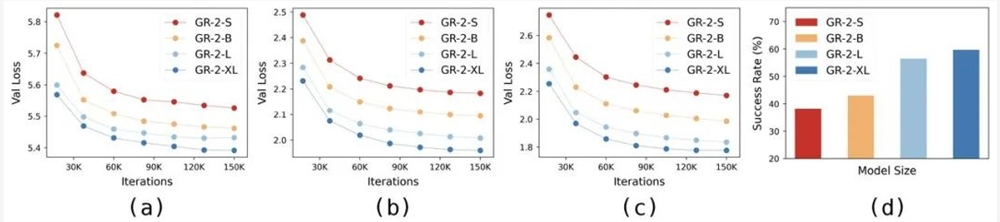
(a)(b)(c) 分别展示了不同尺寸 GR-2在 Ego4d、RT-1、GR-2三个数据集的验证集上的视频生成损失。(d) 展示了不同尺寸 GR-2在真机实验中的成功率。
在7亿参数规模的验证中,团队看到了令人鼓舞的结果:更大的模型不仅能够处理更多复杂的任务,而且在泛化到未见过的任务和场景时也表现得更加出色。
这表明,通过扩大模型规模,我们可以解锁机器人更多的潜能,使其在多任务学习和适应新环境方面更加得心应手。
多任务学习与泛化:未知场景的挑战者
在多任务学习测试中,GR-2能够完成105项不同的桌面任务,平均成功率高达97.7%。
GR-2的强大之处不仅在于它能够处理已知任务,更在于其面对未知场景和物体时的泛化能力。无论是全新的环境、物体还是任务,GR-2都能够迅速适应并找到解决问题的方法。
' fill='%23ffffff'%3e%3crect x='249' y='126' width='1' height='1'%3e%3c/rect%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
我开、我放……我眼里有活儿
更让人惊艳的是,GR-2还能够与大语言模型相结合,完成复杂的长任务,并与人类进行互动。
比如,我们想要喝一杯咖啡。GR-2会先从托盘里拿起杯子,并将其放在咖啡壶嘴下方。接着,它会按下咖啡机上的按钮来煮一杯咖啡。最后,当咖啡煮好了,机器人会把杯子放回托盘上。整个过程无需人类干预。
又如,我们早餐想要吃点东西。根据场景中的物体,机器人决定为我们制作一份烤面包。机器人首先按下烤面包机上的开关来烤制面包。然后它拿起烤好的面包,并将其放入红色的碗中。

认真工作中,勿扰
ByteDance Research 还想强调,GR-2能够鲁棒地处理环境中的干扰,并通过适应变化的环境成功完成任务。
以果蔬分类任务为例:桌子上放置着水果和蔬菜,我们需要机器人帮忙将水果和蔬菜分装到不同的盘子里。机器人能够自主识别物体的类别,并自动将它们放入正确的盘子中。
当在机器人移动的过程中移动盘子,GR-2依然能回过神来,准确找回它要放的目标盘子。

穿越“果”群,仍能找到你
工业应用中的突破:端到端的丝滑物体拣选
在实际应用中,GR-2相比前一代的一个重大突破在于能够端到端地完成两个货箱之间的物体拣选。
这个任务要求机器人从一个货箱中逐个拿起物体,并将其放入旁边的货箱。看似简单,但在实际应用中,能够实现这个需求的多模态端到端模型却难得一见。

端到端拣选任务场景
如下图所示,GR-2可以实现货箱之间丝滑且连续的物体拣选。

真 · 无情的拣选机器人
无论是透明物体、反光物体、柔软物体还是其他具有挑战性的物体,GR-2均能准确抓取。这展现了其在工业领域和真实仓储场景的巨大潜力。
除了能够处理多达100余种不同的物体,例如螺丝刀、橡胶玩具、羽毛球,乃至一串葡萄和一根辣椒,GR-2在未曾见过的场景和物体上也有着出色的表现。

拣选任务中的122个测试物品,其中只有55个物体参与训练。

GR-2可以识别透明的、可变形的或反光的物体。
话分两头,尽管 GR-2在互联网视频上接受了大规模的预训练,但也存在一些进步空间。例如,真实世界动作数据的规模和多样性仍然有限。
GR-2的故事,是关于 AI 如何推动机器人发展的故事。它不仅仅是一个机器人大模型,更是一个能够学习和适应各种任务的智能体。我们有理由相信,GR-2在实际应用中拥有巨大潜力。
GR-2的旅程,才刚刚开始。
(举报)








发表评论取消回复