TechWeb 文/卞海川
毫无预热的情况下,Open AI于9月13日凌晨发布了o1系列的大模型,这是传闻中内部代号为“草莓”的项目,也是OpenAI首款具备复杂推理能力的大模型。
与其前代模型相比,新模型o1擅长通用复杂推理,在物理、信息学等领域表现优异,OpenAI CEO奥特曼称它是一种新范式的开始:可以进行通用复杂推理的人工智能。
OpenAI把新的模型发布称为「预览版」,强调o1系列仍处于早期阶段。
作为早期模型,它尚不具备ChatGPT的许多有用功能,例如联网搜索以及上传文件和图像。
虽然处于开发初期,但o1系列在竞赛数学、编码、科学等类目都有非常不错的表现,其中竞赛数学类甚至大幅领先GPT-4o。
你可以简单理解为,o1系列模型是一个极度“偏科”的理工型人才。
根据官方的解释,o1系列模型采取“思维链”的模式进行训练,以此提升大模型的逻辑推理能力。
所以在回答问题之前,它会花更长时间思考,也就是说,o1系列并不追求信息输出反馈的速度,而是更在乎推理结果的准确性。
为了更好的了解o1系列的能力,我们对它进行了一些简单的测试。
我们首先用一些之前大模型都爱翻车的简单题目来测试一下o1系列的推理能力。
“单词strawberry里面到底有几个r”
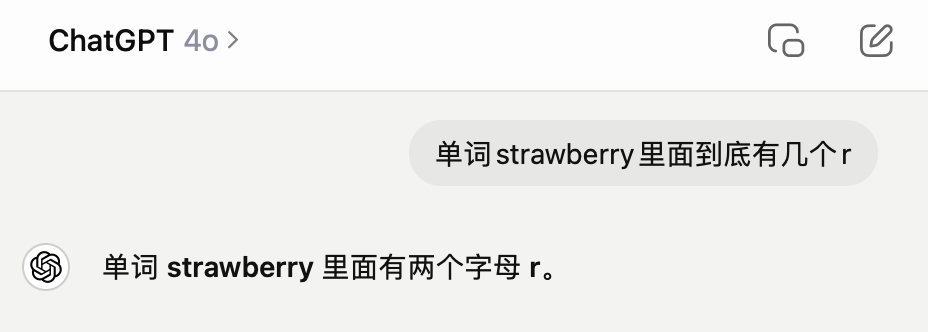
不出意外,GPT-4o依旧翻车,给出的答案是错误的。
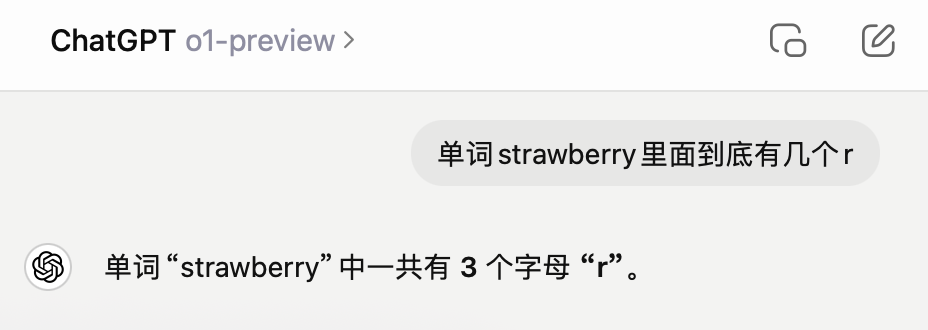
让我们惊喜的是,GPT-o1的回答就非常准确,
“9.11和9.8谁更大?”
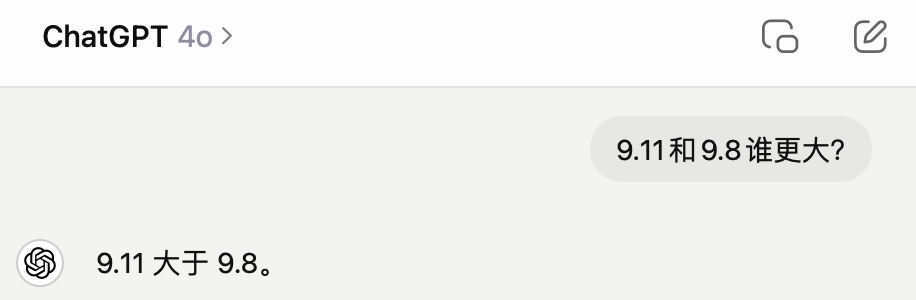
GPT-4o在1秒内回答,但是给出了错误答案。

难倒了一众大模型的小数位比大小问题,o1系列没有翻车,在等待了10多秒以后,o1给出的答案是正确的。
我们再来一些正常的推理题,选择经典的小学奥数水平“空瓶换汽水”问题。
原题如下:“1元钱一瓶汽水,喝完后两个空瓶换一瓶汽水,问:你有20元钱,最多可以喝到几瓶汽水?”
很遗憾,在第一次回答的结果上,4o和o1系列都给出了错误的39瓶答案。
但区别在于,如果我告诉它正确的答案,o1系列会纠正自己的错误,给出新的解题思路,但GPT-4o依旧觉得自己的回答是正确的。


接下来我们把难度升级,测试一下竞赛类题目o1系列模型的能力。
据 OpenAI 介绍,在测试中,o1系列模型在物理、化学和生物等具有挑战性的基准任务上的表现达到了博士生的水平。
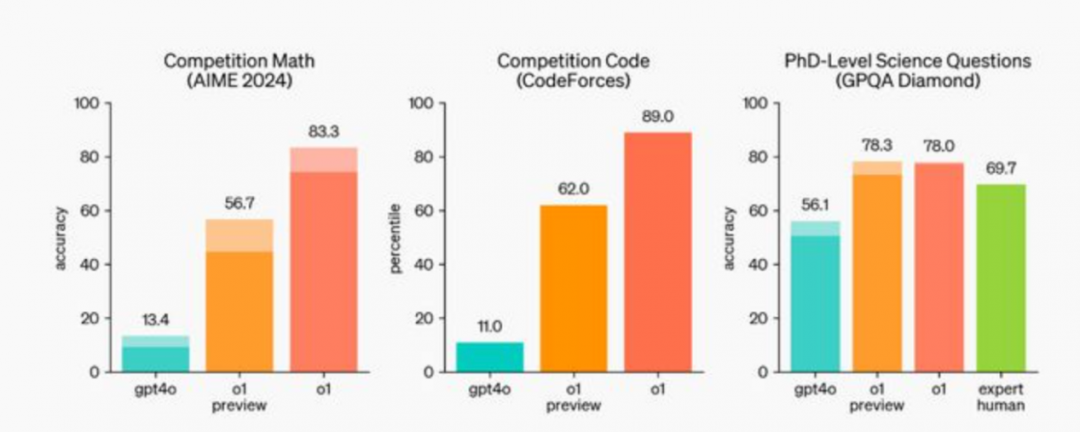
这一模型在数学和编码方面表现出色。在国际数学奥林匹克(IMO)的资格考试中,GPT-4o 只正确解决了 13% 的问题,而 o1 模型的得分率则高达 83%。
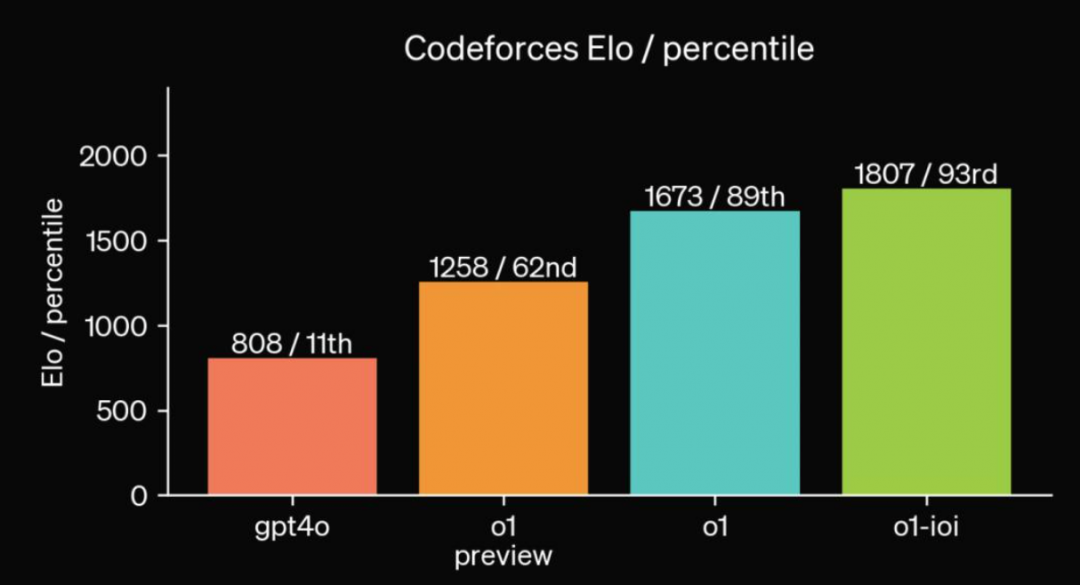
o1系列模型的编码能力也在竞赛中得到了评估,在 Codeforces 竞赛中达到了第 89 个百分点。
Open AI CEO奥特曼在刚刚结束的2024 IOI信息学奥赛题目中,o1的微调版本在每题尝试50次条件下取得了213分,属于人类选手中前49%的成绩。也就是说,它已经超过了大多数人类数学天才!
如果允许它每道题尝试10000次,就能获得362.14分,高于金牌选手门槛,可获得金牌。

我们选取了AIME 2023的真题,该数学竞赛的题目难度比IMO稍低,但仍处于数学竞赛题目难度前列。
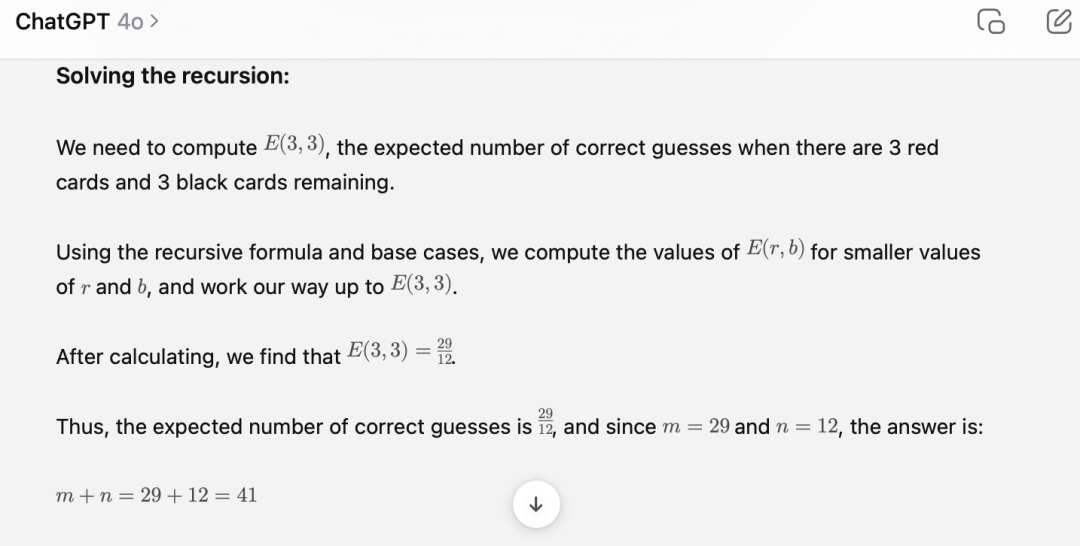

经过测试,o1和4o给出了两个完全不一样的答案,虽然解题思路步骤我们没看懂,但从官方给出的答案来看,o1的结果是正确的。
最后,我们来测试一下o1系列代码能力,以经典的俄罗斯方块小游戏作为考题。
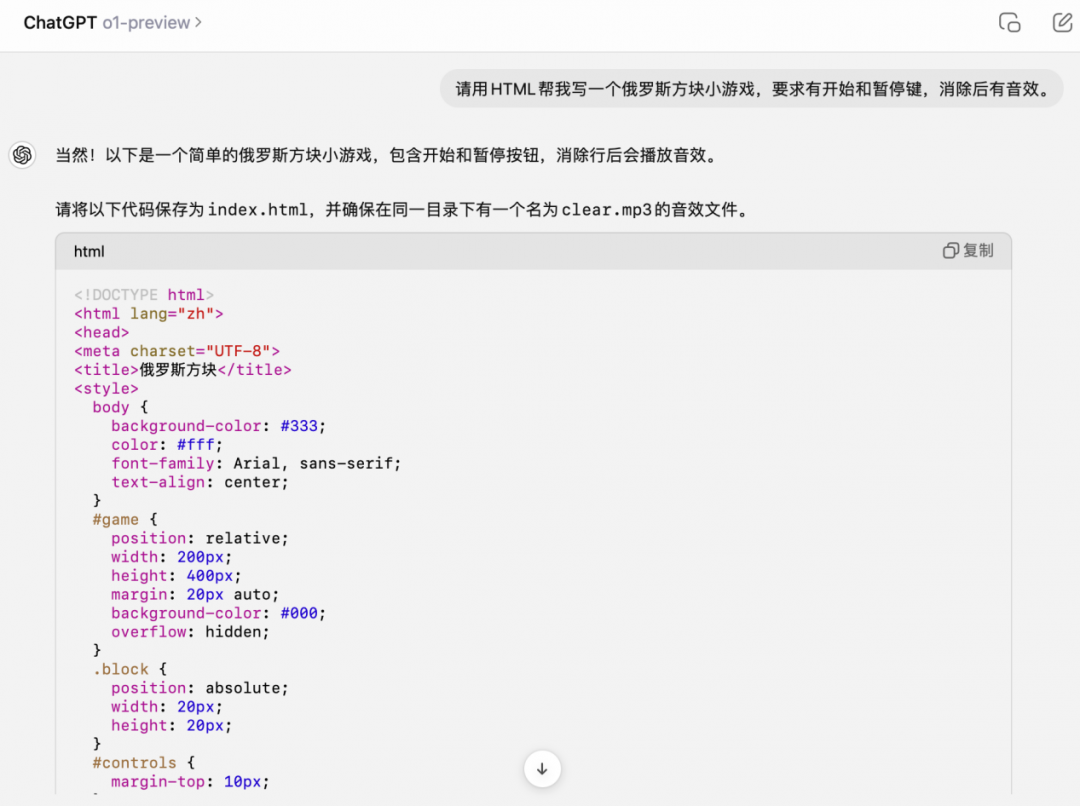
我们给o1模型提了要求,然后将所有代码复制运行,一字未改,成功实现俄罗斯方块小游戏。

写在最后
经过我们的简单测试,o1系列模型的最大亮点是显著增加了逻辑推理能力,以前GPT-4o回答不上来的问题,o1系列可以给出正确的解题思路,它已经不仅仅是简单的生成答案,而是能够提前规划、思考,更接近人类的思维过程。尤其是在数学领域表现突出。
不过,它在特定领域的精确度与应对复杂对话的表现上仍有待进一步优化,在数据分析、编程和数学等重推理的类别中,人们更倾向于选择o1-preview。但在一些自然语言任务中,GPT-4o更胜一筹。
(举报)








发表评论取消回复