声明:本文来自于微信公众号 新智元(ID:AI_era),作者:新智元,授权热心网友转载发布。
【新智元导读】面对GenAI的技术浪潮,很多人都会在不断迭代更新的技术中逐渐迷失。站在潮头的Sapphire、Emergence、Menlo等风投公司,又会如何看待这场AI变局的现状与走向?
根据Sapphire Ventures的数据,GenAI领域从2022年到2023年迎来了爆发式的增长,全球范围(不含中国)的风投资金总量从76亿美元陡增到247亿。
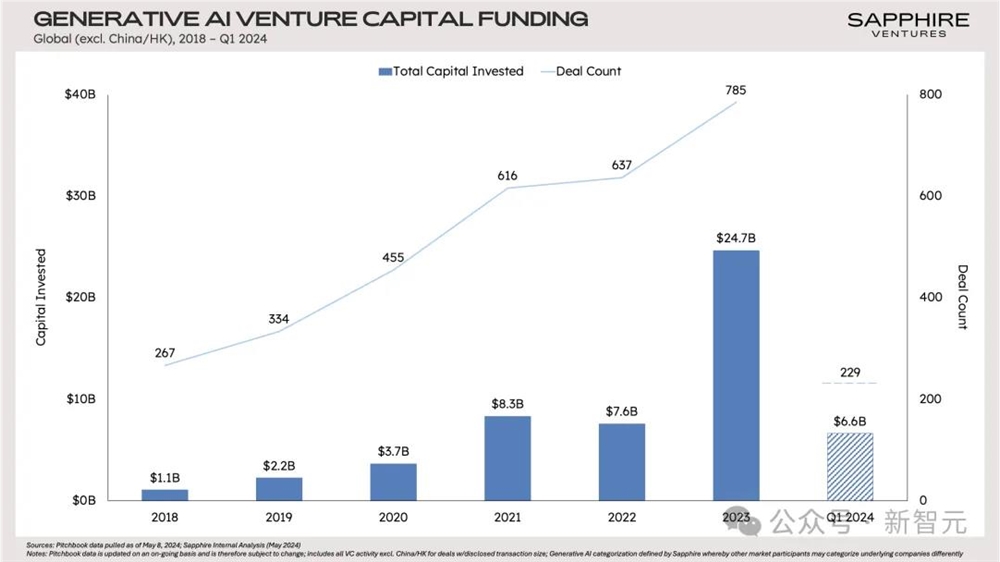
从今年第一季度的数据来看,2023年的市场热度很有可能延续下去。
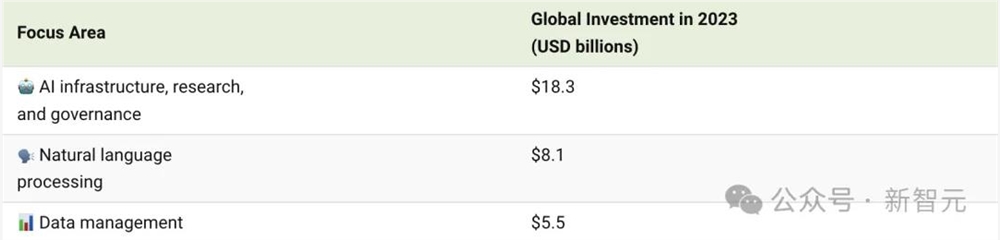
根据咨询公司Quid的统计数据,最能吸引AI方向投资的三个细分领域分别是「AI基础设施、研究和治理」、「自然语言处理」和「数据管理」。
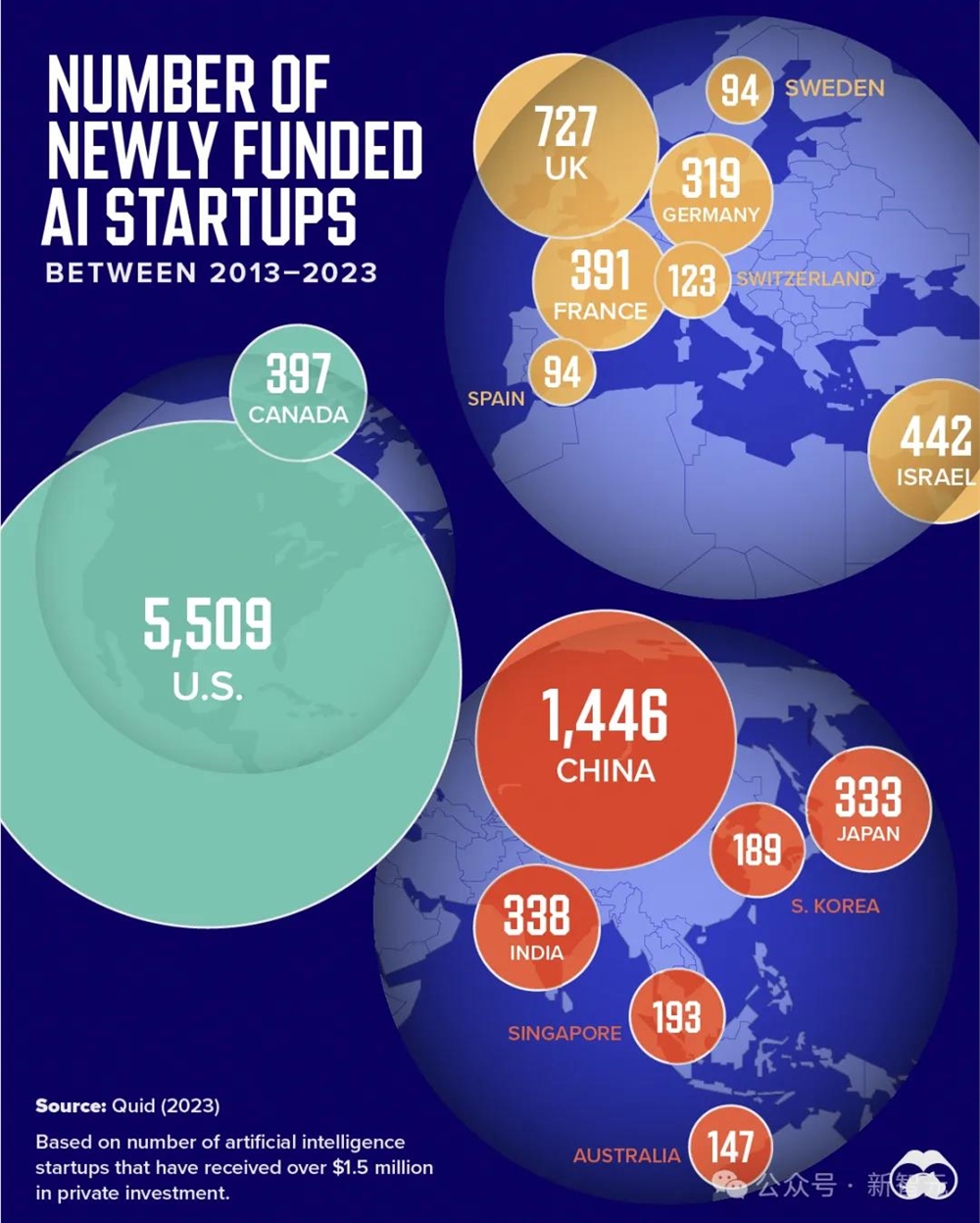
投资大量涌入,带来的直观结果就是初创公司如雨后春笋般涌现。从美国、中国到英国、以色列,都成为了AI创新的重要源头。
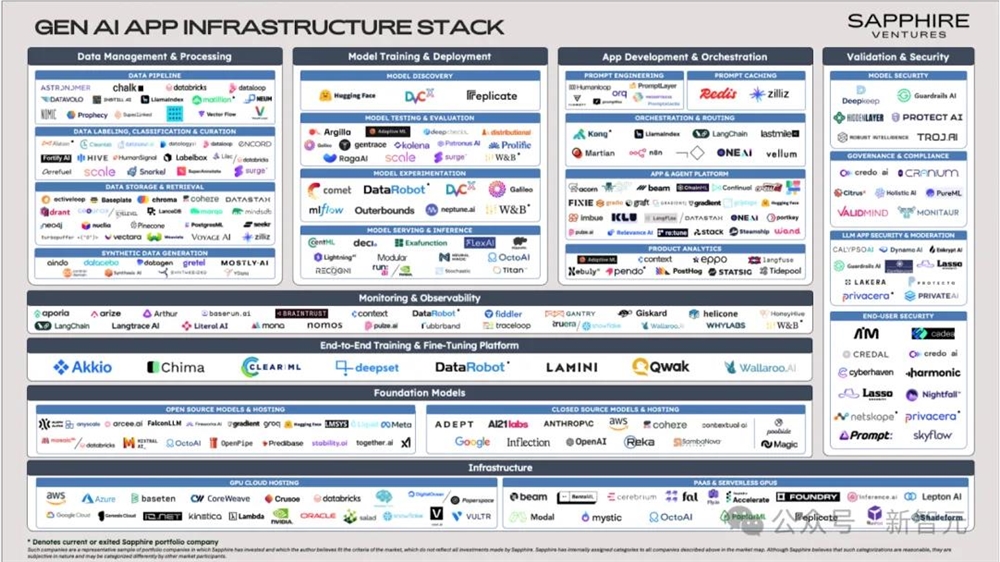
在投资大潮的催化下,GenAI领域的技术更新也达到了前所未有的迅速。
今年1月,Menlo Ventures对于现代AI技术栈的定义还是一个简洁的四层框架,从算力和基础模型开始,到数据、模型部署,以及最顶层的模型可观测性。

而短短几个月后的5月底,这个框架就已经迅速过时,取而代之的是Sapphire Ventures发布的包含200多个公司、多个领域交织在一起的复杂技术网络。
而且,GenAI的发展路径不是单纯技术创新问题,商业战略、金融、教育、政策等各方面的影响交织在一起。
数据隐私问题引起了越来越多立法者的关注,AI法规即将出台的压力挥之不去;AI行业高薪的背后是持续的人才短缺,迫使科技公司不得不在内部开发和外包工作间取得平衡。
更为重要的是,控制成本、创造盈利的压力,会与技术创新的各种原动力相违背。持续不断的开源和闭源之争就是最典型的例子。
相比传统的软件公司,推理和训练的算力支出会耗费更多资金。然而,根据Emergence Capital的统计,只有58%的GenAI公司选择通过产品营利,这就又叠加了一重商业风险。
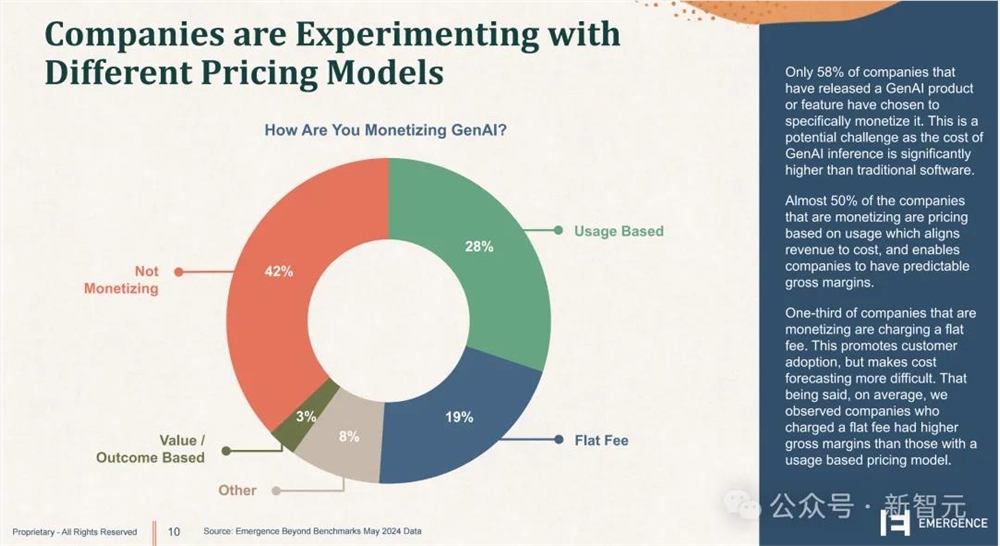
「乱花渐欲迷人眼」,投资热潮、一夜暴富的表象下,入局GenAI实质是一场高风险的技术博弈。在这个瞬息万变的场域中,今天最先进的解决方案,很可能在一夜之间就被新的技术突破取代。
要面对GenAI迷宫中的这一切,也许答案只有一个——适应性。
无论是科研、技术领域的从业者,还是公司中的决策者,都需要不断调整目标和愿景,与这个千变万化的环境一同演进,才能创造出实际的价值。
数据的「量」和「质」
如果一直上溯到深度学习方兴未艾时的ImageNet,可以发现,数据始终是AI的核心问题之一。
随着近年来GenAI和LLM的兴起,数据也和算力一样,成为AI基础设施的一部分,也是需要尽力发掘的稀缺资源。
Epoch AI曾经预言,LLM到2028年将耗尽互联网上所有的高质量文本数据,阻碍Scaling Law的「数据墙」似乎就在眼前。
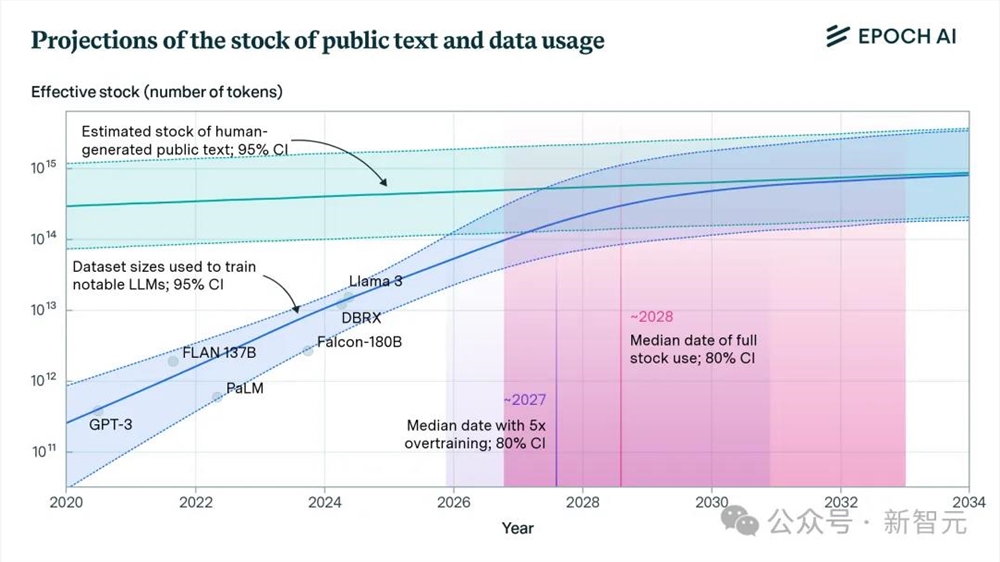
面对数据短缺的挑战,从GenAI自身给出的解决方案——合成数据,似乎是一条仍不明朗但颇有前景的道路。
早期研究曾指出,随着合成数据比例的增加,迭代出的连续几代模型的质量和多样性都会逐渐下降。
但另一方面,较少比例的合成数据和最新的现实数据混合后训练的模型,如Google最近发布的Gemma2,却能表现出显著的性能提升。
Epoch AI的创始人也曾表示,虽然我们能看到「数据耗尽」的前景,但目前还没有感到恐慌的理由。合成数据、
多模态和迁移学习等方法都有望突破「数据墙」。
除了数据量的焦虑,数据质量和数据治理也已经成为关注的焦点。
上个月HuggingFace发布15万亿token的FineWeb数据集,就着重强调了数据质量的重要性。
微软Phi-3小模型的技术报告中,也提及了一种「数据换参数」的策略。

对于企业和产品而言,数据质量的重要维度也包括语义层和数据结构(data fabrics),有望增强AI系统有效理解、使用企业数据的能力,从而带来创新的功能和用例。
初创公司Illumex就开发了一种名为「语义数据结构」(semantic data fabric)的技术,他们的CEO解释道,「data fabric有一种自动创建出来的纹理,而非预先定义好的」,可以促进更加动态、上下文感知的数据交互。
此外,AI监管和科技公司也把目光投向了数据治理领域——确保数据的使用符合伦理、安全并遵守法规。
DataBricks已经将数据治理纳入其平台的核心,被描述为「一个连续的治理体系,从数据摄取一直到GenAI的提示和响应」。
同时,Red Hat副总裁Steven Huels预测,我们会看到数据治理方面的大力推动,尤其是随着AI系统越来越多地影响关键业务决策。
端到端vs.专用解决方案
GenAI这种新兴事物显得有些复杂,有些难以理解,因此许多企业都都倾向于采用全面的端到端解决方案,这反映了决策者们希望简化AI基础设施、精简运营的愿望。
财务软件公司Intuit决定在原有的庞大生态系统中整个GenAI时,他们面临一个艰难抉择——要让数千名开发人员在现有平台的基础上构建AI吗?
最后,Intuit选择了一条更有雄心的道路:从头开始,创建一个全面的生成式AI操作系统GenOS。
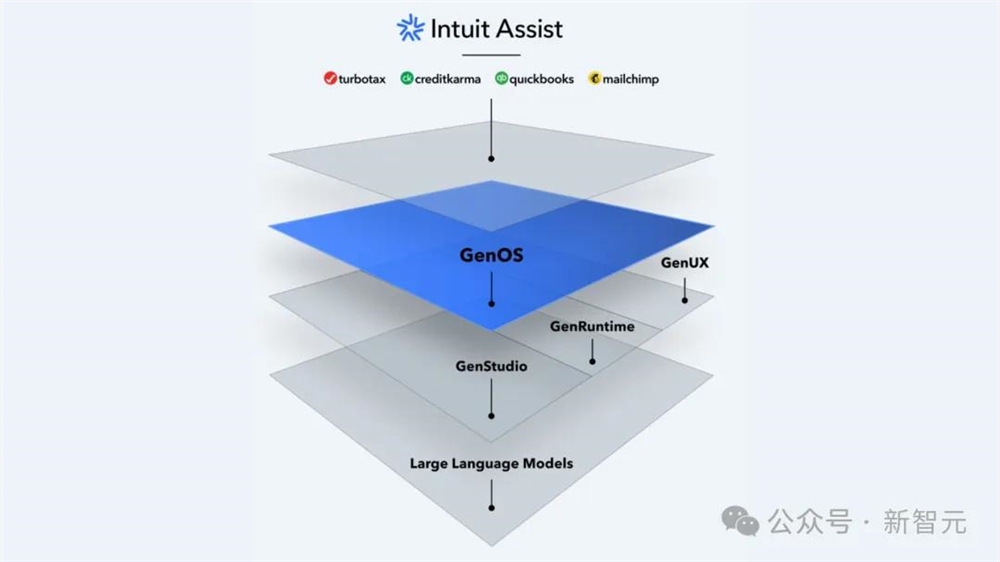
公司首席数据官Ashok Srivastava这样解释这个决定:为了加速创新并保持一致性,「我们将额外构建一层来抽象掉平台的复杂性」。相比之下,让各个团队构建定制解决方案,会导致「高复杂性、低速和技术债务」。
同样,Databricks最近对平台功能进行了扩展,新推出的Model Serving和Feature Serving工具,能简化数据科学家部署模型的流程,代表了他们正在推进更集成的AI基础设施,提供更全面的解决方案。
《Marvelous MLOps》一书的作者Maria Vechtomova指出,整个行业都需要这样的简化:「机器学习团队应该努力简化架构,并尽量减少使用的工具数量。」
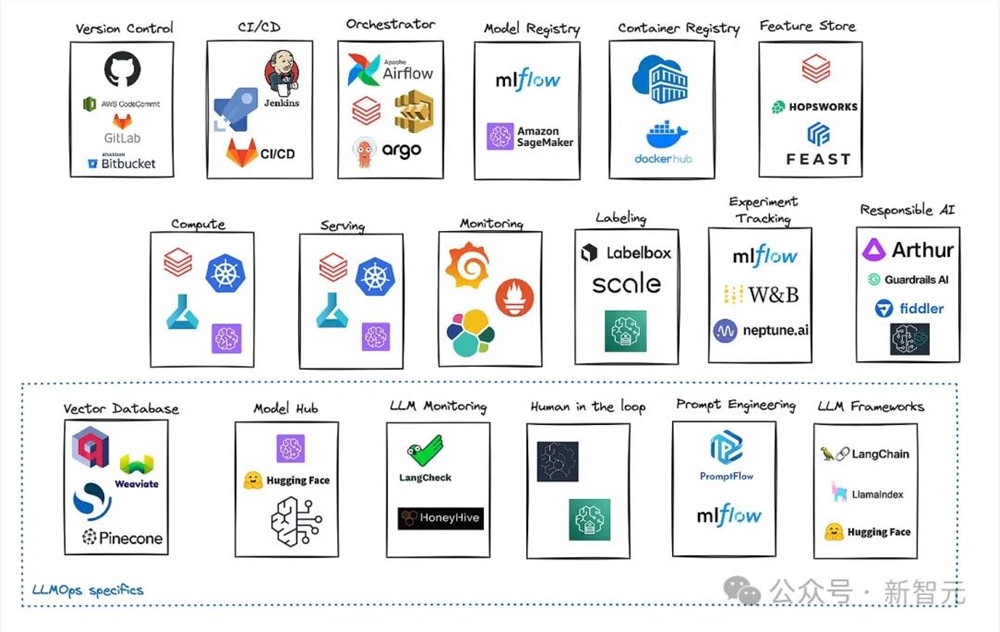
推动端到端解决方案标志着GenAI领域的成熟。企业不再满足于零散方法的拼接,而是希望高效地扩展其AI项目。
与此同时,我们还见证了一个有趣的现象——尽管端到端平台正在崛起,但专用解决方案仍在不断涌现,
通常来说,它们是对通用方案的补充,负责应对可能被忽略的复杂挑战,或者增强某些特定的功能。
专用解决方案的不断涌现表明,在解决特定AI挑战方面的创新仍然充满活力。
即使市场正在围绕少数几个主要平台进行整合,这一趋势仍在持续。
对于IT决策者来说,任务很明确:仔细评估专用工具在某些方面是否能提供比更通用解决方案更显著的优势。
开源和专有的平衡
在GenAI领域,开源和专有解决方案之间有非常活跃的相互作用。
曾经以开源Linux闻名的Red Hat公司最近宣布进入Gen AI领域,他们开发的产品Red Hat Enterprise Linux (RHEL) AI旨在让更多人能够使用LLM,并坚守自己对开源准则的承诺。

然而,开源解决方案通常需要公司内部的大量专业人才,才能有效实施并维护。对于面临人才短缺或希望快速行动的组织来说,这可能是一个挑战。
另一方面,专有解决方案通常提供更集成和支持的体验。比如Databricks在支持开源模型的同时,也专注于围绕其专有平台创建一个连贯的技术生态,能够为客户集成和管理各种AI模型。
理想的开源和专有解决方案平衡将取决于组织的具体需求、资源和风险承受能力。随着AI领域的发展,有效集成和管理这两种类型的解决方案,可能成为一个关键的竞争优势。
平衡好开源和专有方案的「潜力股」也许是最近崛起的AI新星Mistral。
Mistral推出的开源模型既在社区引起了广泛影响,得到全球开发者的支持助力,同时也吸引到了潜在客户,可供任何人检查、定制的代码加强了企业用户对技术的信任。
创始人Arthur Mensch曾表示,「在构建商业模式和坚持我们的开源价值观之间找到一个平衡点是非常微妙的。我们希望创造新的事物、新的架构,但是还想向我们的客户提供一些额外的产品和服务。」
与现有系统的集成
在企业转向GenAI的过程中,一个关键挑战是如何将新功能集成到现有的业务流程与决策框架中,建立两者之间的良好衔接和互动。
这是AI系统落地的最后一步,也直接决定着AI方面的投资能否转化为实在的商业价值。
令人惊讶的是,与顶层的产品功能相比,成功的集成反而更依赖于底层系统。实时系统、流处理、批量处理,这些「骨架」是构建AI能力不可忽视的基础。
对于许多组织来说,数据方面也存在挑战,难点在于AI系统需要连接多样化的,且常常孤立存在的数据源。初创公司Illumex就开发了一种方案,允许企业利用现有的数据资产,而无需进行大规模的重组。
安全集成是另一个关键因素。由于AI系统通常处理敏感数据并做出重要决策,它们必须被纳入现有的安全框架,并符合组织政策和监管要求。
提示工程仍然是关键技能
精确且格式良好的提示,结合相关的上下文数据,能够显著影响模型输出的质量,这种效果常常令开发者和用户感到惊讶。
尽管最初对提示的长期前景以及提示工程师这一新兴职业存在怀疑,许多公司仍在积极寻找并高薪聘请具备提示工程技能的员工。
我们相信这一趋势将持续,并将得到新兴服务的进一步支持,这些服务可以帮助公司制作、存储、测试、管理和更新提示。
智能体已来,但为时尚早
AI智能体可以使模型(或一系列模型)在用户几乎不干预的情况下完成一个或一系列动作。
智能体工作流程有望扩展模型的使用方式,并使开发者能够单独优化每个步骤,从而可能带来显著的生产力提升。
虽然如今真正的自主智能体尚未成为现实,但我们观察到越来越多的服务正在帮助用户构建轻量级的定制助手,比如微软对C o p i l o t最近的更新。
这些助手能够处理更复杂的工程工作流程(不仅限于代码辅助)、从多个来源提取和总结信息、自动标记数据等任务。
生成式人工智能的激进未来
随着GenAI快速发展,对技术栈的探索也愈发深入,从端到端解决方案到专用工具,从数据质量到治理框架。
可以肯定的是,我们正在见证企业技术的变革时刻,但这还只是个开始。
最近,AI大牛Andrej Karpathy描绘了一幅更加激进的未来图景。
他设想了一个「100%完全软件2.0计算机」,其中单个神经网络取代了所有传统软件。
其中,设备输入如音频、视频和触摸将直接输入到神经网络中,输出则通过扬声器和屏幕显示为音频和视频。
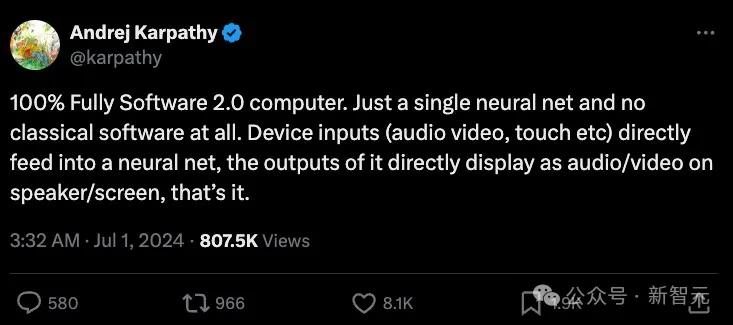
这个概念远超我们当前对操作系统、框架甚至不同类型软件之间区别的理解——应用程序之间的界限变得模糊,整个计算体验将由一个统一的AI系统来调控。
虽然这样的愿景可能显得遥远,但它强调了一点:GenAI不仅能重塑单个应用程序或业务流程,还能改变计算的基本性质。
今天在构建AI基础设施时做出的选择将为未来的创新奠定基础。灵活性、可扩展性和接受范式转变的意愿将是关键。
不论我们谈论的是端到端平台,还是AI驱动的计算环境,成功的关键在于培养适应性。
参考资料:
https://venturebeat.com/ai/ai-stack-attack-navigating-the-generative-tech-maze/
https://menlovc.com/perspective/the-modern-ai-stack-design-principles-for-the-future-of-enterprise-ai-architectures/
https://sapphireventures.com/blog/building-the-future-a-deep-dive-into-the-generative-ai-app-infrastructure-stack/#gallery-4
https://www.emcap.com/thoughts/beyond-benchmarks/
https://www.visualcapitalist.com/mapped-the-number-of-ai-startups-by-country/
(举报)








发表评论取消回复